Abstract
通过将视觉跟踪任务分解为两个子问题(像素类别的分类和该像素处的边界框的回归),本文以逐像素的方式提出了全卷积Siamese网络来解决视觉跟踪问题。
该框架由两个简单的子网络组成:一个用于特征提取,另一个用于边界框预测。
Introduction
视觉目标跟踪的挑战:光照变化、尺度变化、背景杂波、严重遮挡、非刚性对象外观的显著变化…
Siamese网络将视觉追踪任务设定为了一个目标匹配问题,其目的是学习目标模版和搜索区域之间的一般相似性映射。
相关项目的发展流程为:
- Siamese网络的策略是搜索区域,进行匹配。这要在多个尺度上进行以应对尺度变化。缺点在于耗时;
- SiamRPN给SIamese连上了一个RPN,用于解决多尺度造成的时间浪费。缺点在于需要预先设定锚框,使得模型对锚框的参数比较敏感。
本文提出的SiamCAR则是anchor-free的。
分类分支旨在为每个空间位置预测一个标签,回归分支旨在将每个位置回归一个相对边界框。
Proposed Method
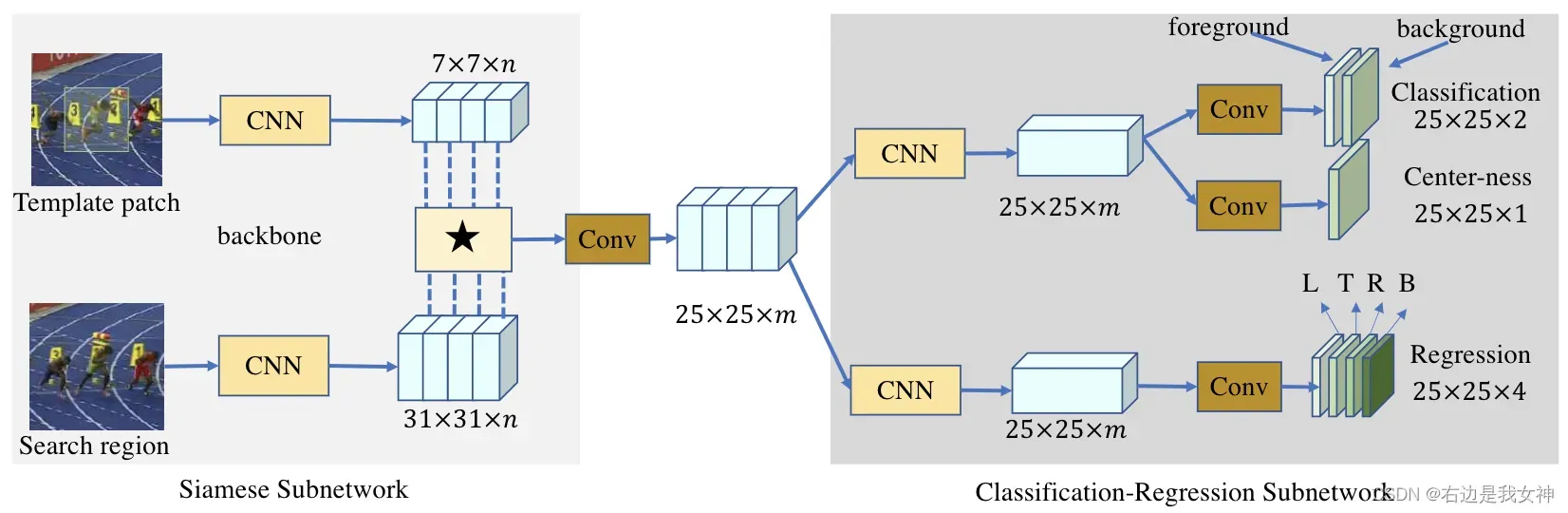
Feature Extraction
该子网络由两个分支组成,target branch的输入为template patch ;search branch的输入为search region
。
这两个分支与其主干模型共享相同的CNN结构。两者输出的feature map分别为。
本来是两个输出做互相关之后的结果。但是这一操作只能生成一个单通道的压缩响应图,缺乏有用的特征和用于跟踪的信息。
本文为了获得更多的信息,所以我们使用深度相关层来生成多个语义相似图:
其中表示的是通道与通道间的相关计算。也就是说R的通道数和两个分支的输出的通道数一致。
原文认为低层次特征对定位来说很有帮助,高层次特征对语义属性的识别很有帮助,所以融合高低层次特征是一种很好的选择。因此,本文结合了最后三个块提取的特征进行连接。
需要注意的是两个输出都是维度的特征,最后得到R之后通过
卷积进行降维,这样可以显著减少参数数量。
最后得到的feature map 作为分类回归子网络的输入。
Bounding Box Prediction
上的每一个
可以和search region
构建起对应关系。可以认为每一个
是原图锚框的中点。
本文的模型能够直接分类回归每个位置的目标边界框。其中response map ,通过两个分支后输出分类特征图
以及回归特征图
。
对于分类特征图,二分类结果为前景和后景的分类。对于回归特征图,输出的为,表示从相应位置到输入搜索区域中边界框四边的距离。
因为目标和背景的比例不是很大,所以样本不平衡不是一个问题。所以我们简单地采用交叉熵进行分类,IOU损失进行回归。
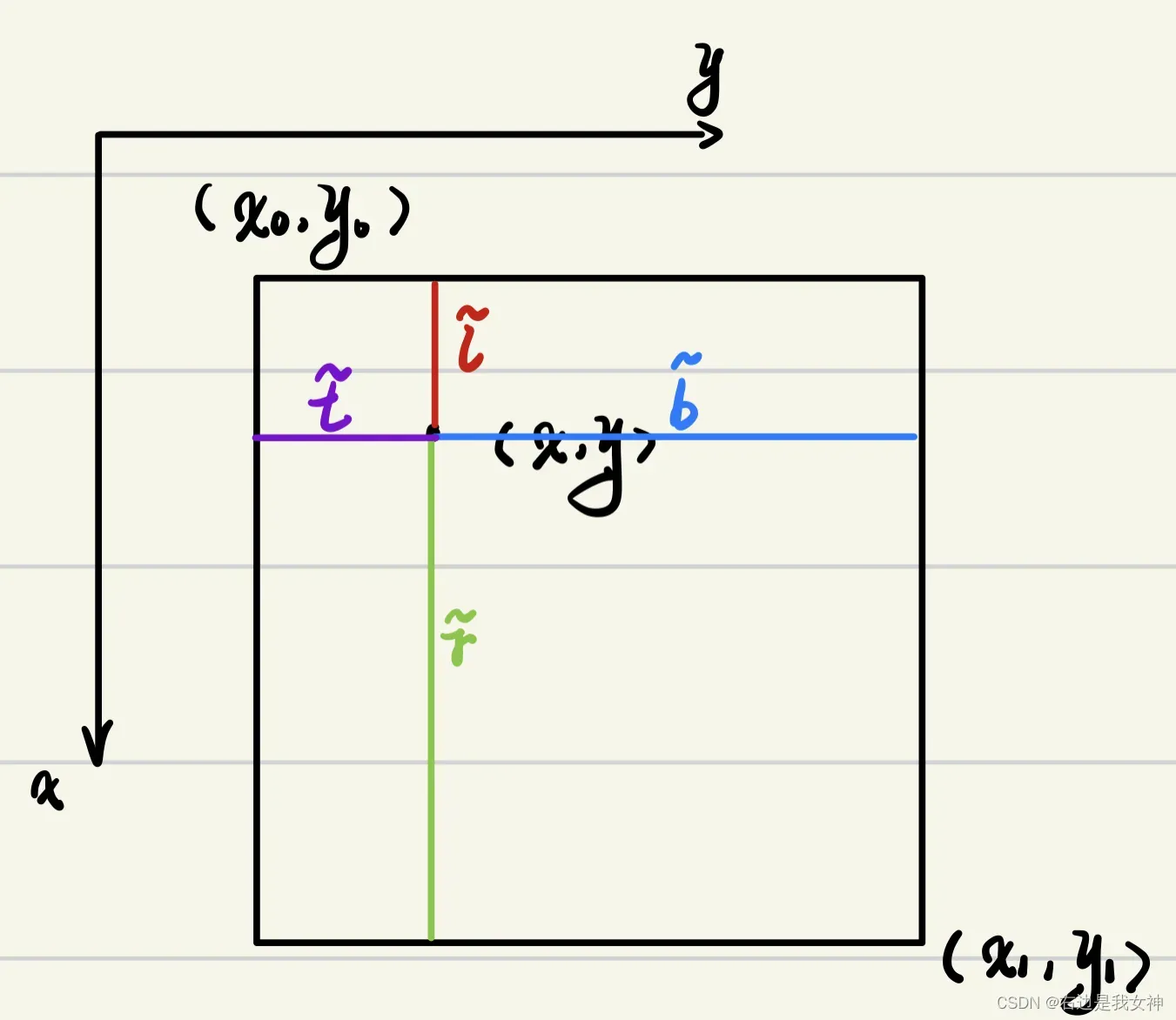
令和
为左上角和右下角的点的坐标(GT)。然后让
为
在search region上的中心点。
于是,回归的目标就能被计算得到
回归损失函数为:
保证算进损失函数的距离都是大于0的。
根据观察,远离目标中心的位置往往会产生低质量的预测边界框(单目标跟踪,离这个目标远的位置的边界预测效果不行),这会降低追踪系统的性能。因此,添加了一个与分类分支并行的centerness branch,以去除异常值。
它返回了一个,给出了中心度分数。这个GT得分是这么定义的。
理想情况下,这个是尽量在bbox中心的,如果说这个点不在中心,我们就认为它不是这个bbox的
,所以这个得分会比较低。
值得一提的是,如果这一点被判定为背景点,损失函数中是不需要考虑它的中心度得分的。于是,中心度得分的损失函数有:
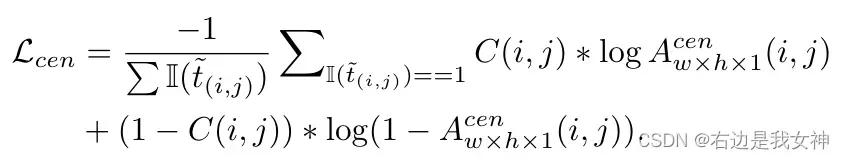
整体损失函数为:
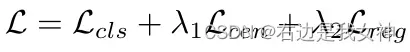
The Tracking Phase
跟踪的目的是预测当前帧中的目标的边界框。对于一个位置会产生一个6维的矢量
。
在运动过程中,边界框应该是微小变化的,所以我们施加了一个惩罚。
于是,跟踪项可以如下书写
其中是cosine window,
是平衡权重,
是有最高得分的目标像素。
因为模型以逐像素的方式解决了目标跟踪问题,因此每个位置都是相对于一个预先设定的边界框的。在实际跟踪过程中,如果只使用一个边界框作为目标框,它将在相邻帧之间抖动。
本文观察到,q周围的像素最有可能是目标像素。所以说,它找了从n个邻居中找了得分最高的k个(根据),最终的预测是这k个回归框的加权平均。
值得关注的几个问题
Q1:输入的图片大小不一?
代码中,会将其resize为255255大小的图像。同时模板大小为127127
Q2:在两者做相关性之前,如何得到特征图?
先后经历了backbone和neck两部分。
backbone通常选择为ResNet50,给出了后三层的feature map。
neck为AdjustAllLayer,通过将这三层调整为256通道。
Q3:两者的相关性计算是如何实现的?
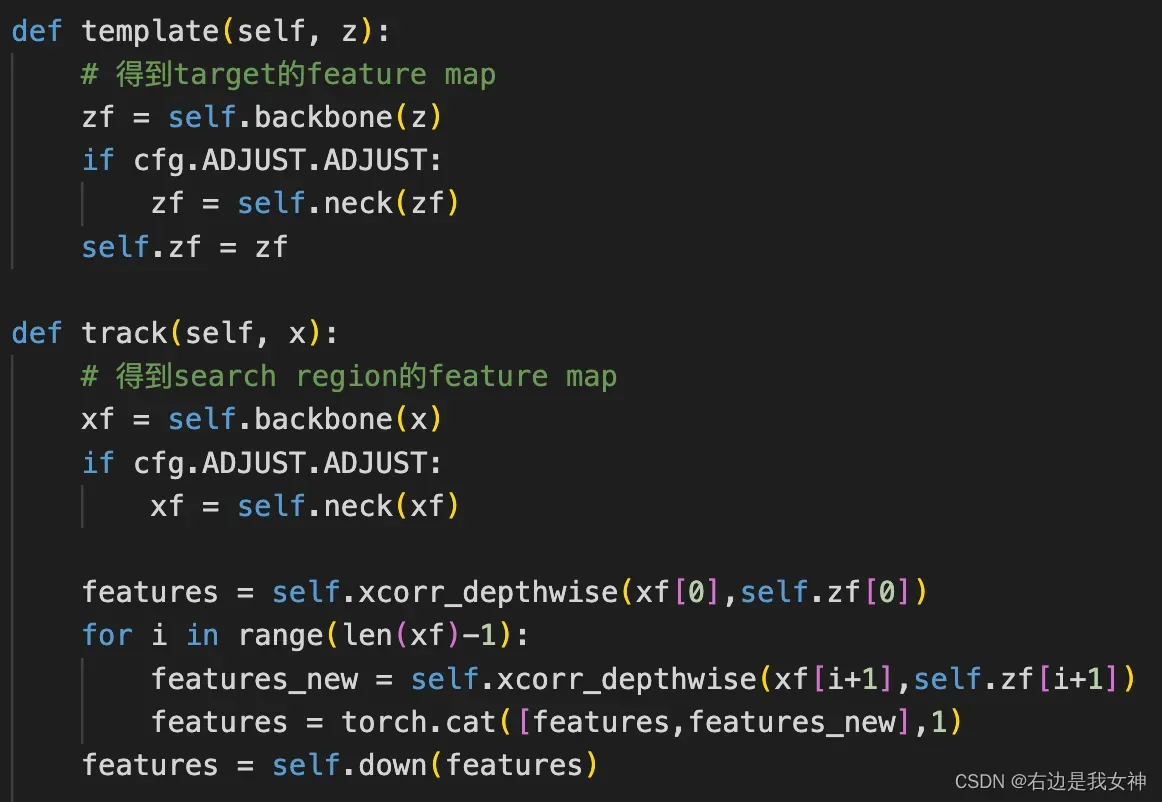
然后用卷积降维。
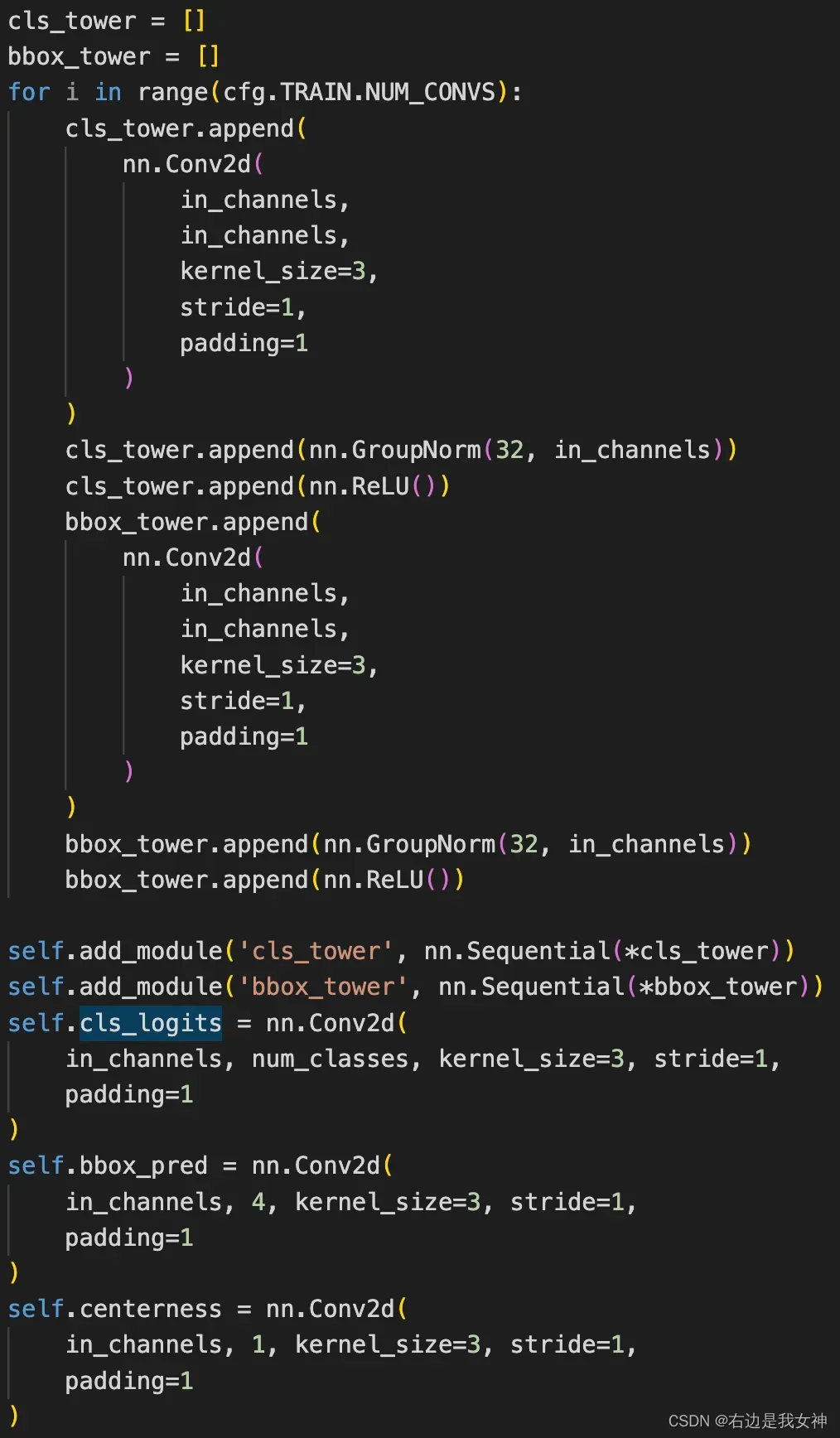
Q4: R*送入的网络是什么样的?
就是Conv+GroupNorm+ReLU的结构,最后用Conv进行分类。其中centerness和cls共享模型
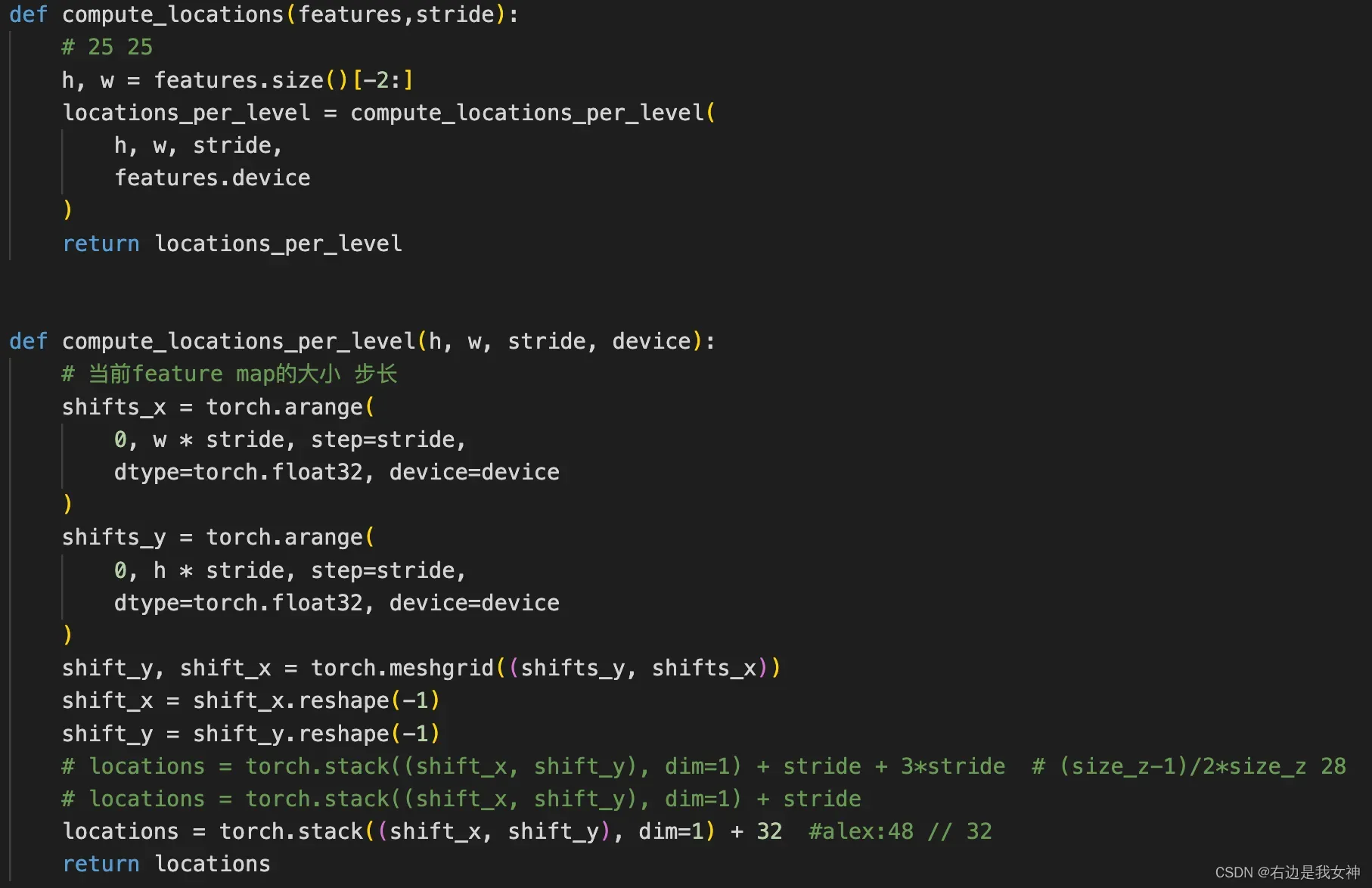
Q5:映射关系?
输入图像被resize为255*255,stride为8,输出shape为25*25。最后对应的坐标从
Q6:惩罚项?
这个惩罚项是从另一篇论文中提出的,在那篇文章中,目的是为了使一次性检测框架适用于跟踪任务,所以需要提出一种策略来选择候选框。
使用余弦窗口和尺度变化惩罚对候选进行排序。
其中是超参数,
代表着候选框高度和宽度的比例,
代表最后一帧的比例。
分别代表着候选框和最后一帧的规模,此处的规模如下定义
,是padding。
然后与分类结果相乘就能得到排序的依据。
文章出处登录后可见!