文章目录
- 前言
- 一、安装条件
- 二、安装ollama
-
- 优化存储路径(不用优化也行)
- ollama命令详解:
- 模型命令详解:
- 三、安装WebUi
-
- windows安装不了docker解决
- 测试
前言
最近看到google的gemma模型很火,因为模型较小对于但功能强大,大模型虽然很好但对于我们普通人来说过于遥远,不管是训练的token来说还是模型的复杂度,小模型都比不上,但是小模型的对于我们的训练成本没有那么高但是可以体验到不一样的感觉。
一、安装条件
最低条件:
2B版本需要2G显存
7B版本需要4G显存
7B的其他版本需要更大
7B我这里使用3050 Laptop测试可以运行但生成速度很慢
二、安装ollama
下载ollama:
https://ollama.com/download
直接安装

安装完成后启动:
使用windows键+R打开运行窗口:
ollama 或者ollama help

优化存储路径(不用优化也行)
ollama有个问题是没有选择路径,导致我们如果使用windows下载会下载到c盘中容易c盘爆满,现在来优化这个问题:设置》系统》高级系统设置》环境变量》新建系统变量



名称OLLAMA_MODELS路径给到自己创建新建文件夹:

如果打开了程序重新启动即可生效
ollama命令详解:
命令注释:
serve: 启动 ollama,用于提供模型服务。
create: 从模型文件创建一个模型。
show: 显示模型的信息。
run: 运行一个模型。
pull: 从注册表中拉取一个模型。
push: 将一个模型推送到注册中心
list: 列出模型。
cp: 复制一个模型。
rm: 删除一个模型。
help: 获取有关任何命令的帮助。
常用命令:
ollama run 模型名称:版本
ollama run gemma:2b

模型lib:https://ollama.com/library/
这里选择版本copy命令直接粘贴命令即可下载:
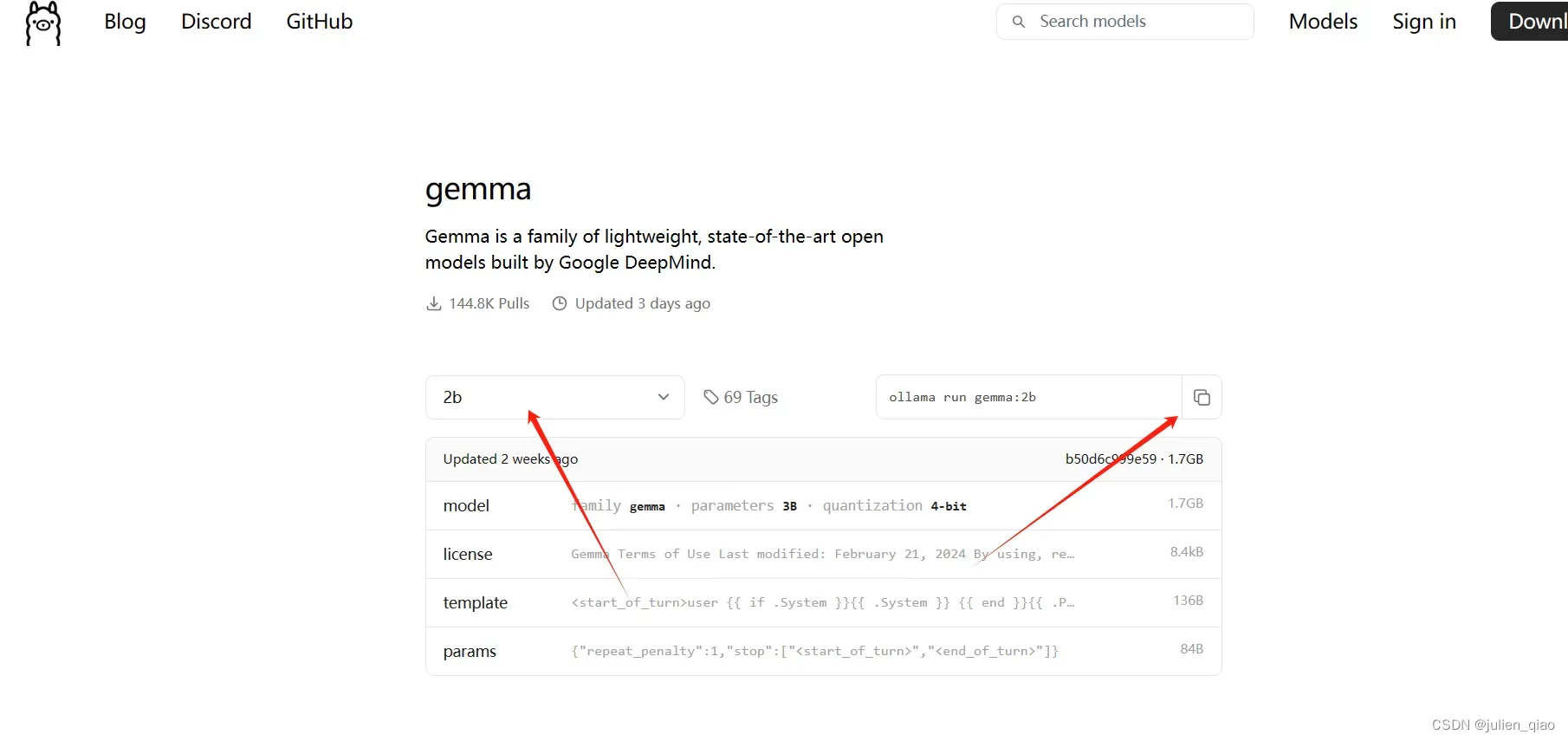
如果优化了存储路径直接可以在文件夹下看到下载的模型

完成后直接可以对话了:

这里运行的2b(版本来看应该是3B)的模型,因为我显卡比较垃圾返回速度比较慢:

模型命令详解:
/set: 设置会话变量。
/show: 显示模型信息。
/load : 加载一个会话或模型。
/save : 保存当前会话。
/bye: 退出。
/?, /help: 获取命令的帮助。
/? shortcuts: 获取键盘快捷键的帮助。
这里的命令会/bye退出就行
到这里模型已经可以正常运行和返回了
三、安装WebUi
项目地址:https://github.com/open-webui/open-webui
使用docker安装:
docker run -d -p 8080:8080 -e OLLAMA_API_BASE_URL=http://127.0.0.1:11434/api -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
这里我已经拉取过镜像了如果没拉取这里也会直接拉取的:
 启动后访问:http://127.0.0.1:8080/auth/
启动后访问:http://127.0.0.1:8080/auth/
windows安装不了docker解决
如果windows没有安装docker可以使用虚拟机Linux安装只需要在调用的时候将API换成本地的地址即可OLLAMA_API_BASE_URL=http://192.168.10.1:11434/api

我这里是windows已经有docker了直接访问本地:

随便注册一个号:

注册完成后直接登录:

这里选择下载的模型:


测试
这里的测试不是严格意义上准确:
在运行2b时花费接近2G显存,回复速度很快,但明显有一些问题如理解问题能力不够:

在运行3B时花费2.5G显存回复速度很慢:回答效果还行


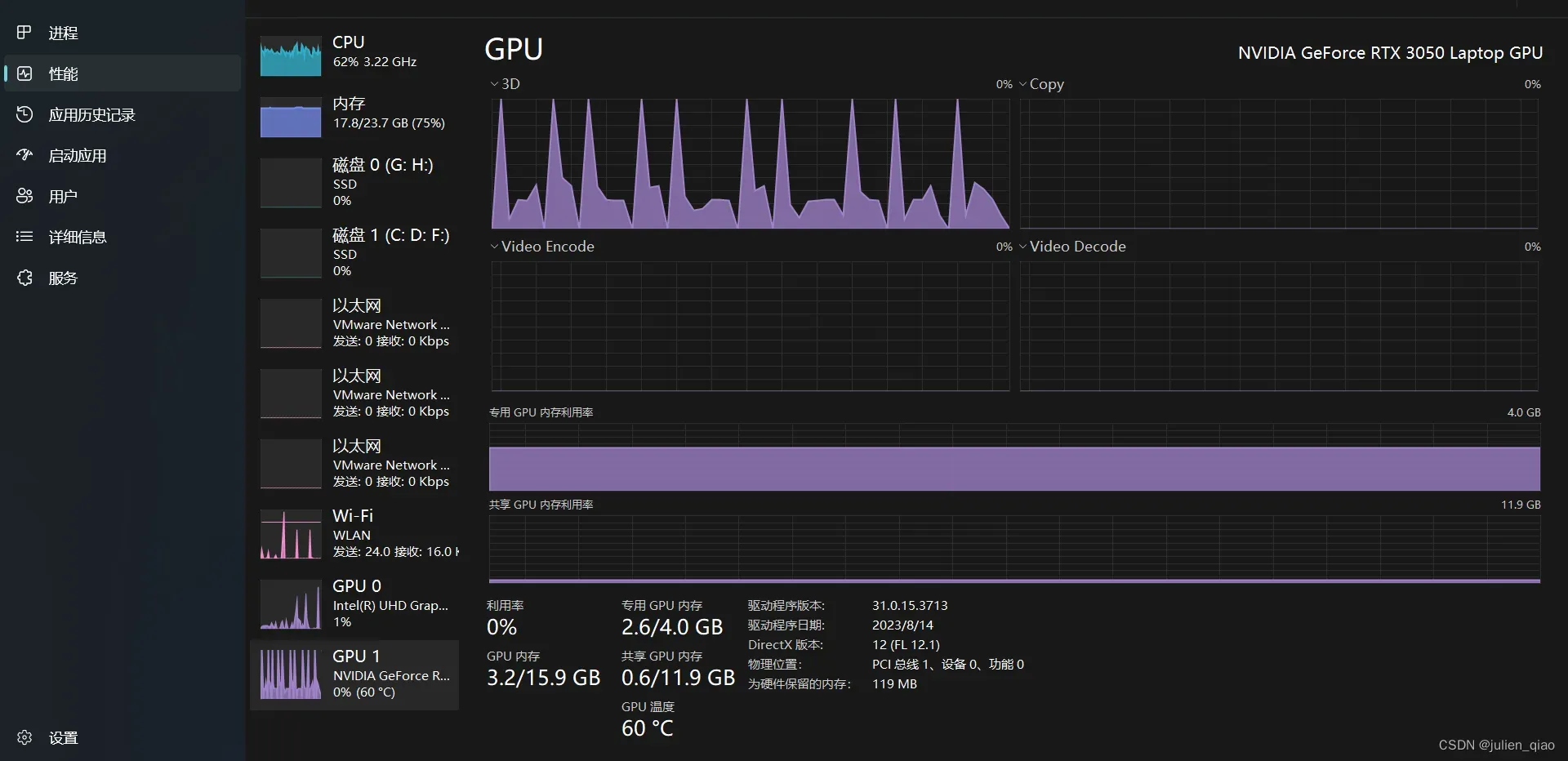
7B版本


版权声明:本文为博主作者:julien_qiao原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_39583774/article/details/136592951