目录
一、局部最小值(Local Minima)与鞍点(Saddle Point)
1.最优化(Optimization)失败的原因——驻点(Critical Point)
4.saddle point和local minima哪个更常见?
一、局部最小值(Local Minima)与鞍点(Saddle Point)
1.最优化(Optimization)失败的原因——驻点(Critical Point)
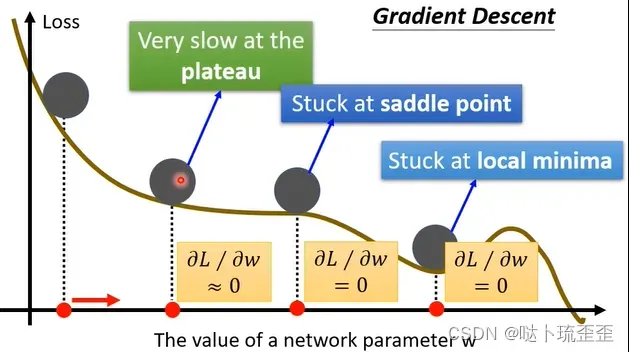
当Gradient decent走到了极值点,即局部极小值点(local minima),对参数的gradient接近于0,无法继续更新参数,此时training停止,loss也就不在下降。
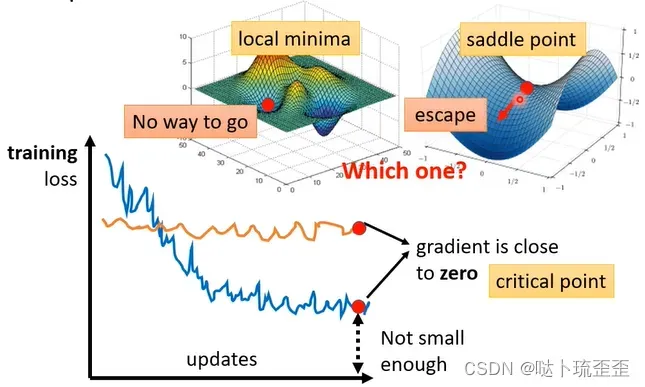
还有可能是到达了鞍点(saddle point),该点低于左右两侧但高于前后两侧(前后左右位置相对而言),此时的gradient为0,但既不是local minima,也不是local maxima。
以上两种使gradient为0的点,统称为驻点(critical point)。
当卡在local minima时就无路可走,因为四周没有比该点更低的取值;但卡在saddle point时,周围存在使loss更低的点。
2.如何鉴别极值点和鞍点?
step1:泰勒级数展开
采用泰勒级数展开的方法近似模拟损失函数 在该点附近的形状:给定一组参数
,
在
附近的表达式可写成:
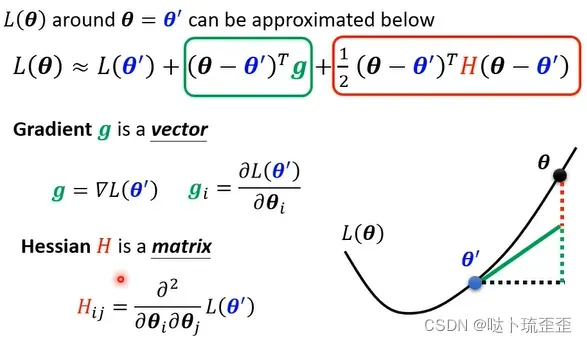
当处于驻点时,对参数的微分为0,即
为0,则第二项不存在,需要根据第三项判断
附近error surface的形状,判断此时到底是极值点还是鞍点。
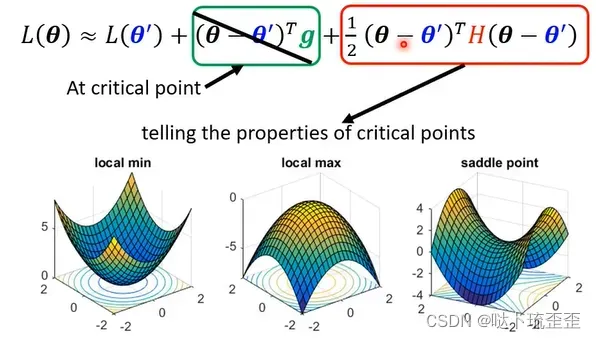
step2:根据海塞矩阵(Hessian)判断
第三项中的是海塞矩阵,这里放上一张之前听课关于海塞矩阵的公式推导部分的笔记。想要具体了解海塞矩阵的求解及相关性质,推荐大家去看Datawhale谢文睿吃瓜教程的视频。

归根结底,是需要通过海塞矩阵特征值(eigenvalue)的正负进行判断:

举例
有一个Neural Network:,且只有x=1时label为1的data,我们希望最终的输出和1越接近越好。该函数的损失函数为
,穷举所有的
和
,算出所有的loss值进行展示,最中心的黑点及周围黑点所在的线形区域为critical point。
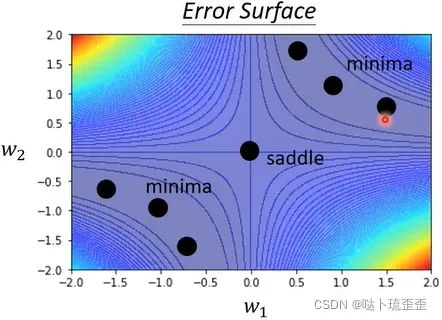
当和
的值都为0时,只求导一次无法判断遇到的是local minima还是saddle point,需要进行二次求导,即计算海塞矩阵
并求解其特征值。本例中
的特征值出现一正一负的情况,则卡住的地方为saddle point。

3.处在鞍点时应如何操作?
卡在saddle point时无需担心无法求解,通过海塞矩阵可以得知参数接下来更新的方向,即在
处沿着
的方向做参数更新,就可以使loss继续下降。

具体操作:找出海塞矩阵负的eigenvalue
及其对应的eigenvector
,用
加上
即为下一次更新的参数
。本例中
,则参数应该朝着1这个方向更新。但由于计算量过大,实际操作中该方法很少用到。

4.saddle point和local minima哪个更常见?
当跳脱出问题所在维度时,如处在二维中的local minima在三维空间中可能是saddle point,而saddle point在更高维的空间中是否依然是saddle point并不确定。训练network时候,参数往往动辄百万千万以上,参数有多少就代表error surface的维度有多少。既然维度这么高,会不会其实存在非常多的路可以走?也就是说会不会local minima根本就很少呢?
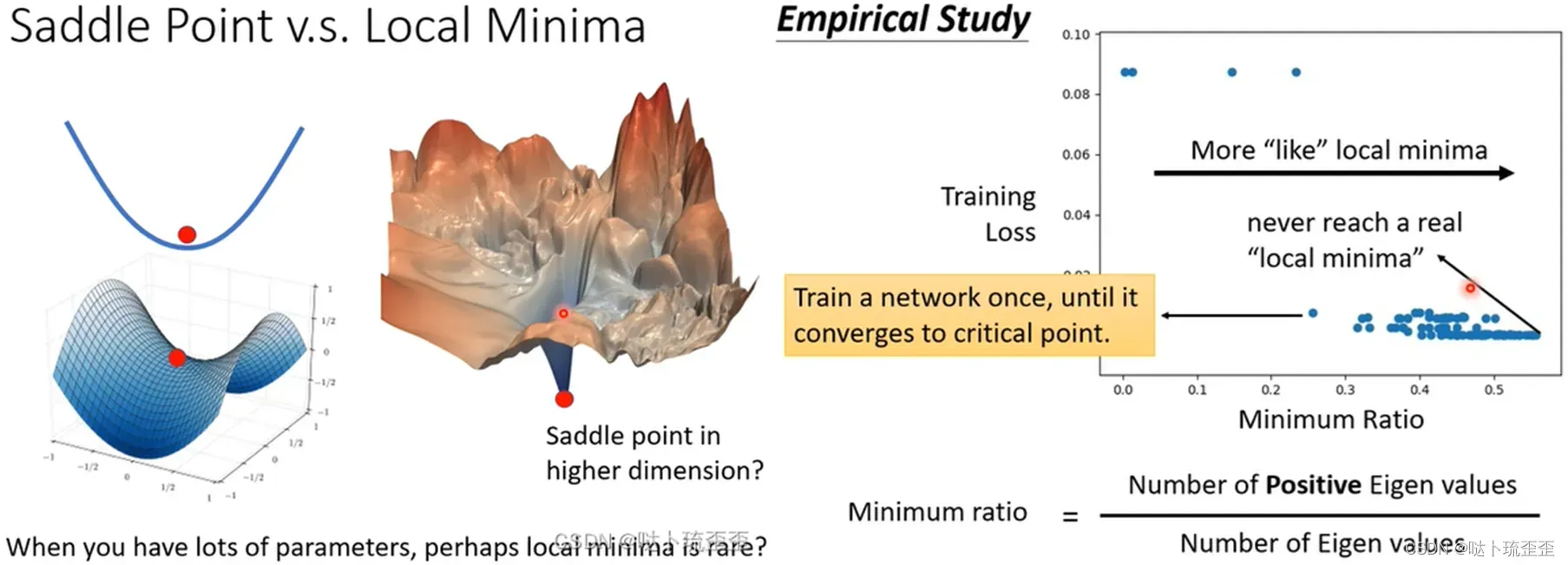
右图中的minima ratio表示正特征值在所有特征值中的比重。由图知几乎一半的eigenvalue为正,没有真正到达local minima,即local minima并没有那么常见,多数情况下遇到的还是saddle point。那么在所有维度中,有几乎一半的可能性能使得loss下降。
二、批次(Batch)与动量(Momentum)
1.Batch
概念
将所有的data分成一个个的batch,每次update参数就用一个batch的资料算loss,所有的batch看过一遍叫一个epoch。
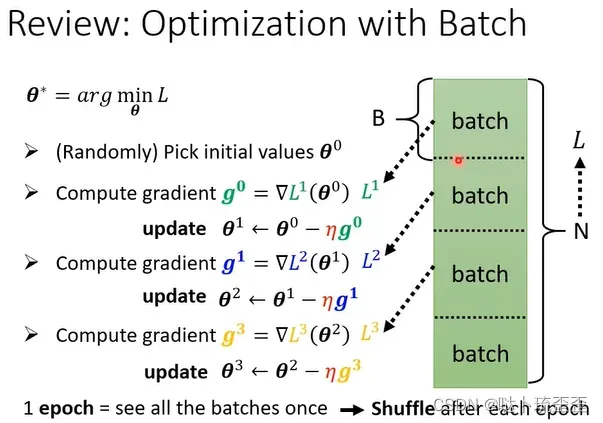
将data分成一个个batch的过程叫做shuffle(洗牌),常见的做法是在每一次epoch开始之前会分一次batch,每一个epoch的batch都不一样。
意义
左边是没有用batch的,batch size=N,右边的batch size=1,下面比较这两种极端情况。

左边由于没有用到batch,所以要把所有data都看过一遍才能对参数进行一次update,这种方式“蓄力时间即技能冷却时间较长”,但这一步更新是稳的(powerful)。而右边的batch size=1,即每看一个资料参数就更新一次,在一个epoch里面参数会更新20次,但同时它“技能冷却快”,比较不准,gradient的方向是比较noisy的,即每一步走的不稳,整个参数update的方向较为曲折。
Small Batch v.s. Large Batch
事实上,考虑到GPU的平行运算,large batch size所用的时间不一定比small batch size时间长:
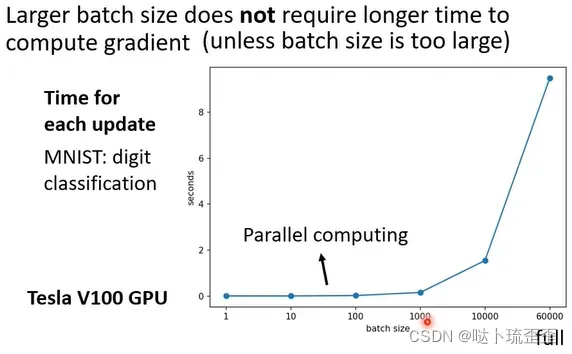
以MNIST数据集(手写数字辨识)为例,给模型一个batch,计算出gradient就能update参数的时间到底有多久?由上图可知,batch size从1到1000所耗费的时间几乎是一样的。因为有GPU的平行运算,这1000B资料是平行处理的,时间并不是1B资料的1000倍。但超过GPU算力时,计算时间依然会随着batch size的增加而增长(但看起来还是很快的)。
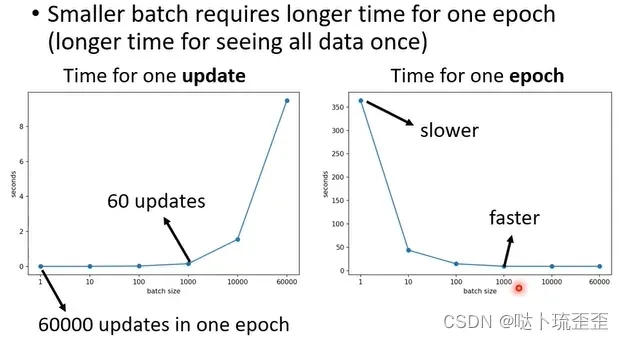
但对于一个epoch而言,small batch所需要的时间比large batch所需的时间长,神奇的是noisy的gradient反而可以帮助training,下图横轴为batch size,纵轴为模型的accuracy,当batch size很大时,accuracy表现越差。
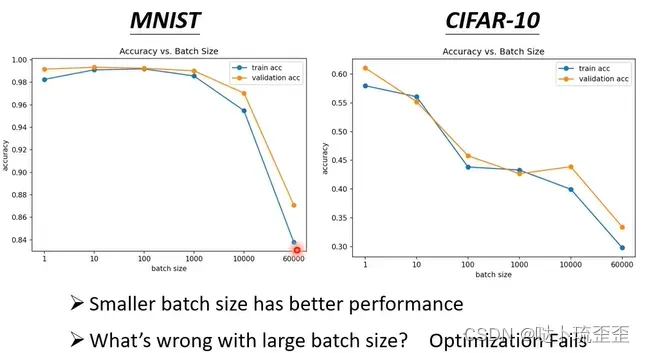
为什么small batch size在training set上有较好的结果?为什么noisy的update在training时有较好的结果?由于使用的是同样的model,所以问题并不在model bias上,而是optimization可能有问题。
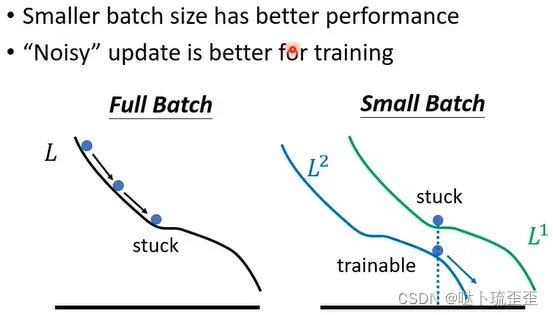
一个可能解释是:假设是full batch,那就是沿着loss function来update参数,当走到local minima时显然就停下来了。但如果是small batch,每次挑一个batch出来算loss相当于每次update参数时所用的loss function都是略有差异的:选到第一个batch时用计算gradient ,选到第二个batch时用
计算gradient。假设用
算gradient时发现是0卡住了,但
的function与
又不一样,
卡住了,
不一定会卡住,所以
卡住没关系,换下一个batch来,
再接着算gradient,还是能够继续training model,还是有办法使loss变小。
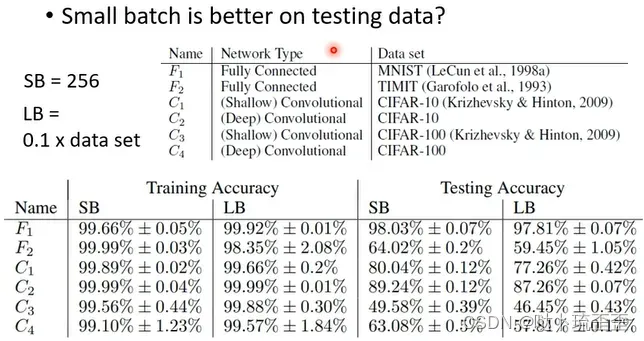
另一个更神奇的事情是small batch也对testing有帮助。假设不管large batch还是small batch都能training到一样好,结果会发现small batch居然在testing时会是比较好的(详见On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima)。但testing时若large batch表现差,则代表over fitting。原因如下:
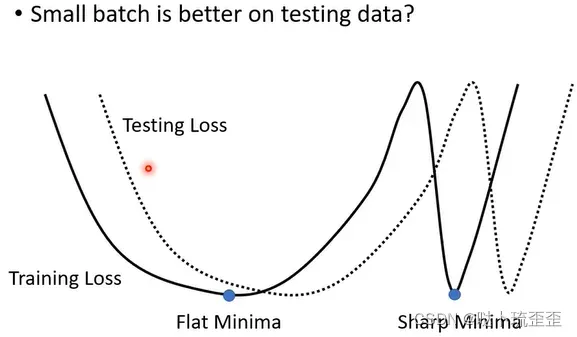
training loss上可能有很多local minima,但local minima有好有坏:如果local minima在峡谷中,就是坏的;在平原上,就是好的。因为training和testing之间会有差距,对“平原minima”来说,两者差的不会太多;而“峡谷minima”就会差很多。Small batch size会倾向于走到盆地,因为small batch size每次update的方向都不太一样,可能一不小心就会跳出峡谷来到平原(一个未证实的说法)。

small batch和large batch各自擅长之处如左图所示,如何选择合适batch的相关paper如右图所示。
2.动量(Momentum)
将小球视为参数,斜坡视为loss,物理上,小球从斜坡上滚下来,可能由于惯性冲过最低点继续向前。即从物理的视角来看,小球并不会被卡住。
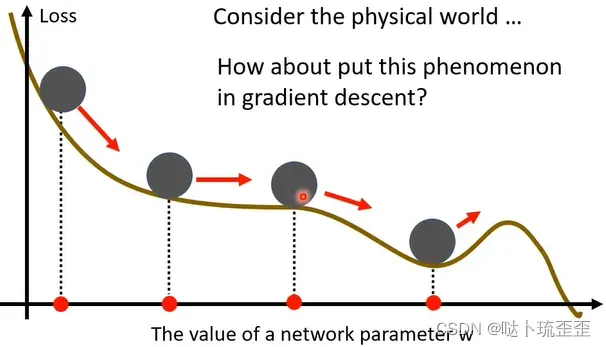
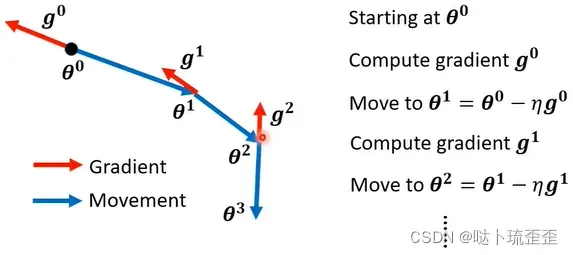
一般的(vanilla)gradient descent:计算初始的参数的gradient
,计算完后往gradient的反方向update参数,一直继续下去:
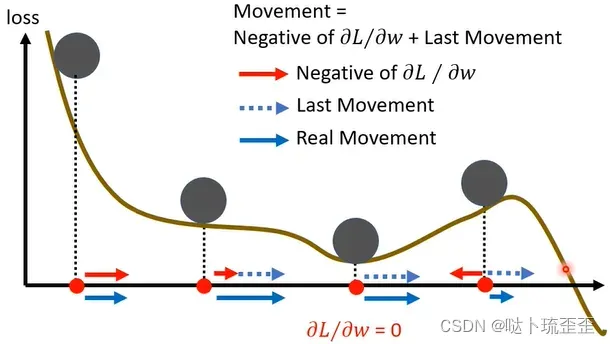
gradient descent+momentum: 计算初始的参数的gradient
,下一步是gradient的方向加上前一步的方向:

我认为这样update可以保证即使当gradient为0时,由于惯性即前一步方向的存在,还能够继续向前update:
版权声明:本文为博主哒卜琉歪歪原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_40857571/article/details/122569062