Dual-Awareness Attention forFew-Shot Object Detection阅读笔记
摘要&前言
小样本检测任务:利用n-way k-shot的数据量实现不错的效果,当然这需要一次比较好的预训练,一般是训练任务,输入为样本对,分别作为查询和支持输入,当然也有类似attention RPN的训练方式输入三张,查询和一张正样本以及一张负样本。
本文作者提出了DAnA,双重意识注意力机制:Dual-Awareness Attention。
本文提出的问题
1.之前的方法对支持特性执行全局池,以确保计算效率。然而,空间信息的缺乏将导致难以测量对象相关性。
2.卷积神经网络(CNN)在建模不同的空间分布方面的物理效率很低,因此使用基于卷积的注意的方法也会受到同样的限制。
3.此外,之前的工作将跨多个支持图像的平均特征作为类特定表示,这在很大程度上依赖于平均特征在嵌入空间中仍然具有代表性的隐式假设。
我的理解是:
1.全局池化不行。2.基于卷积的注意力模块不行。
3.将多shot的图像直接取平均作为类特征不行。
下图是作者提出三个问题的图示,abc分别对应第123个问题。 作者提出的DAnA包括两个模块,BA和CISA来解决这个问题,考虑了两个方面的问题:1)支持特征的质量,以及(2)如何更好地构建支持图像和查询图像之间的相关性。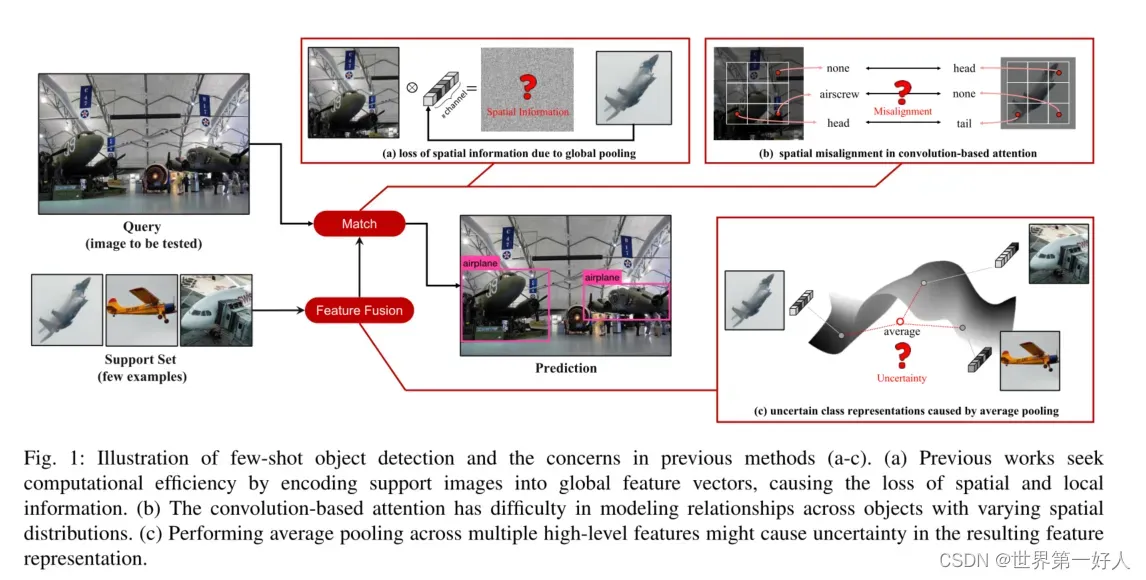
BA模块Background Attenuation Block
目的是为了背景衰减,结构图如下,其中支持图像s和查询图像I被编码到支持特征映射Y中。在BA块中,特征映射Y将通过线性可学习矩阵进行重塑和变换。我理解的就是训练一个权重参数来对每一个通道进行重加权。
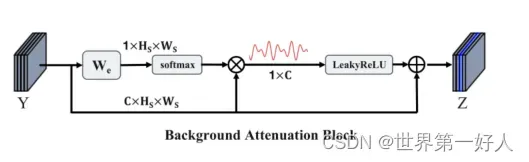
然后作者说物理学中有一个理论是两个信号相加会有两种结果,平淡或者比较突出,于是就有了后边的一部分,在经过一个参数和激活函数之后在连到了原本特征图的残差。
Z =Y +α ·LeakyReLU(G)
我理解这一部分就是通过s强化了一下查新图像i的特征图方。
CISA模块Cross-Image Spatial Attention Block
这各模块的思路我是这样理解的,跟我之前读过的一篇视频目标检测的思路有一些像,就是类间的物体也未必完全特征相同,可能某一个部分会对匹配起到非常关键的作用。
然后这个模块就是进行了一个复杂一些的注意力机制,进一步增强查询和支持之间的关系。
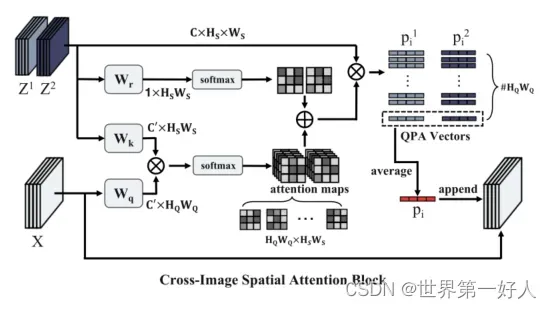
模仿了transformer中的QKV的格式,上边这一个流程图非常清晰,三个w矩阵为权重,用于乘以特征图生成K/Q,K和Q的乘再softmax的操作就是计算相似度,得到attentionmap,然后作者说觉得最终查询爷和支持集本身有很大的关系,所以又加了一个处理过的支持集信息,这两个相加的结果作为计算支持和查询相似度的完整的参数,然后相乘得到QPA也就是类特征,然后平均池化之后加到查询特征之后共同进行回归和分类。
实验
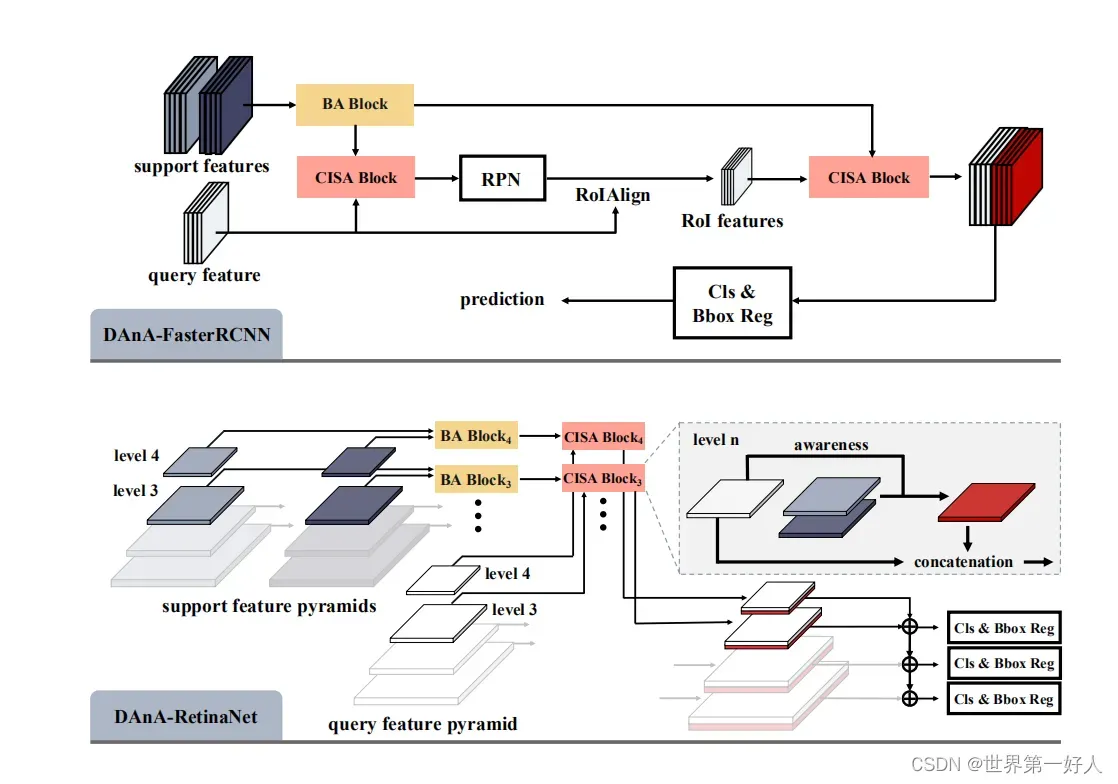
作者进行了一下实验,因为这两个部分可以理解成即插即用的模块,所以作者再Faster-RCNN和retinaNet都做了实验,这是结构图。
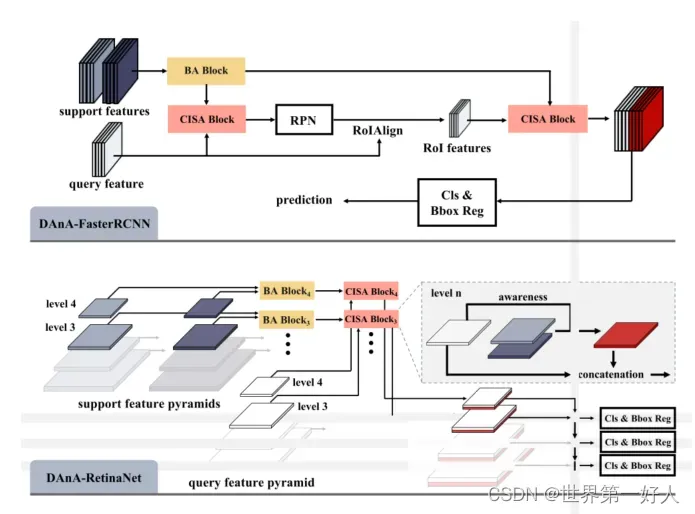

最后这两个模块作者也给出了可解释性。
文章出处登录后可见!