–neozng1@hnu.edu.cn
5.5.3. local-distribution方法
考虑到global-distribution的缺点如没有局部旋转不变性和平移不变性、对背景信息的处理也做得不够好,那我们就从局部统计入手,图片划分成数个不同的区域进行统计。
5.5.3.1. gradient histogram
一种直观的改进思路将全图划分成数个网格,在网格内分别统计梯度直方图,然后将统计得到的向量拼接成高维向量(相当于得到了一个全局描述子/全局特征),或利用集成的方法对每个向量训练一个分类器(boost、stacking、bag都是可用的)。这样就能在获取一些不变性,利用固定位置的局部信息组合来替代全局统计信息。当然,网格不宜太细否则容易受到噪声或个体特征的影响,使得分类器过拟合,太粗则和全局统计特征差别不大,也达不到效果:
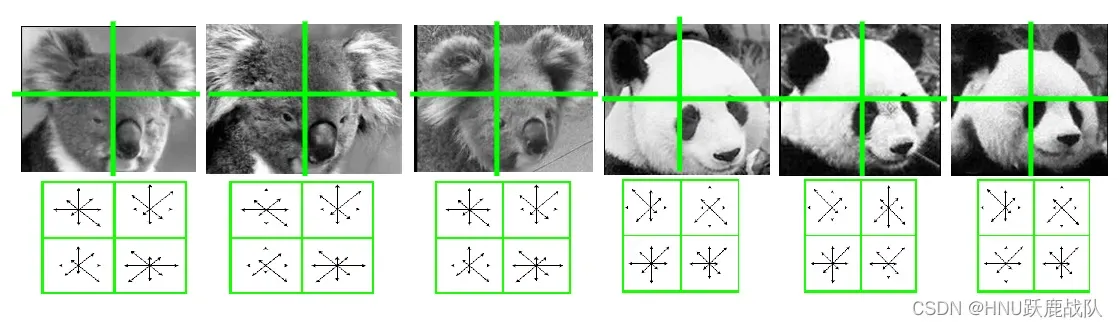
还是前面的例子,每个网格中不同向量的长度代表在该方向bin内的累加值的大小
加入了网格之后,分类器对于局部旋转和位移的敏感性将会降低。既然可以用微分算子作为滤波器提取边缘,自然可以用其他的滤波器模板以产生更丰富的特征响应,下面就介绍使用了多种卷积核的GIST。
注意,local-distribution方法虽然使用了局部信息,但是最后生成的特征向量仍然是一个全局特征,因为这个特征描述的是整幅图像而非图像中的某个物体或目标。
5.5.3.2. GIST
gist意为要旨,要领,原文提出该方法的初衷就是进行场景分类,如森林、沙滩、街道、室内等。这样的方法显然需要一些全局特征对场景进行恰当地表示,同时为了保证特征更加鲁棒,采用局部信息聚合到全局的方式进行处理:
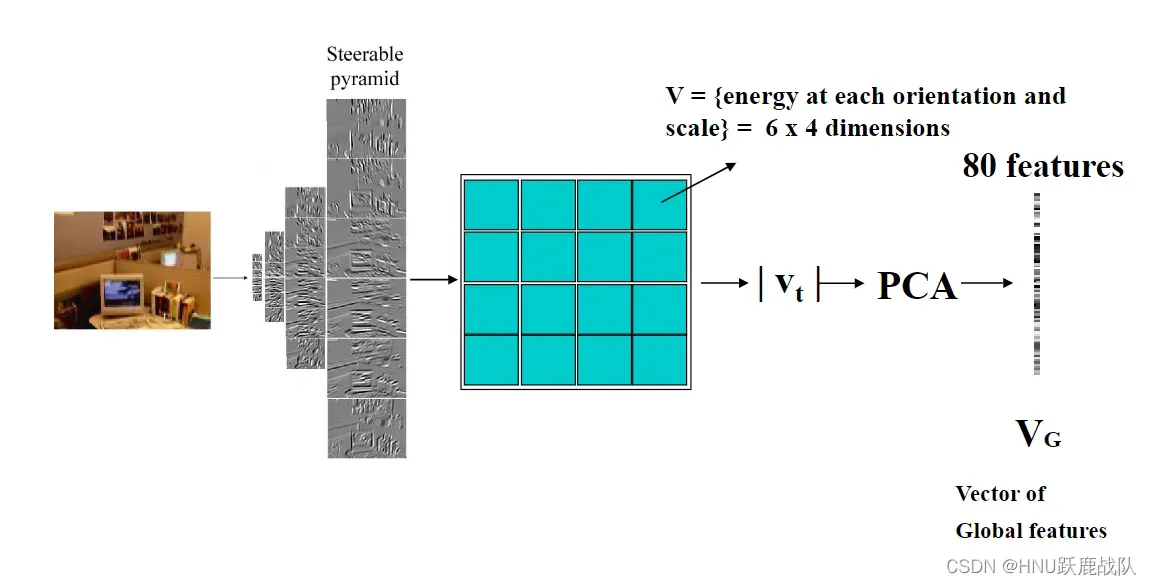
gist的图示
首先生成图像金字塔,原文选择的是4层;然后在每一层上都分别从六个方向应用Gabor滤波器,生成共24张响应图。对于每张相应图,都切割成4×4的网格,将网格内的响应值取平均,最终得到4*6*16(尺度*方向*网格)个维度的向量。对此向量运行PCA得到80维的全局特征表示。后处理我们都很熟悉了,用此特征训练一个分类器或直接计算和anchor vector的距离进行分类。
Gabor滤波器是一种小波滤波器,小波分析是傅里叶分析的进阶,同样在频域处理信号,在继承Fourier Transform优点的同时,其强大的局部分析建模能力和对非平稳信号的兼容性使得它大放异彩。这方面的内容需要较多的泛函分析、数值分析知识,有兴趣的同学可以自行查找资料。
在这里我们直接将Gabor滤波器视作和常见的卷积核一样即可,只不过它的特殊设计使他具有一些优秀的性质。对应到卷积神经网络,就相当于我们通过FPN生成了4个尺度的输出,并且每个尺度的feature map都有6个通道(使用了6组卷积核);而取平均的操作也非常的熟悉,这不就是average pooling吗!可见ConvNet的架构设计并非是无中生有从石头里蹦出来的,而是从这些传统的算法中扩展得到的。当然,在聚合特征的时候你也可以使用其他方法,比如之前介绍的直方图统计等,这都是对算法效率和精度的权衡。我们从特征工程的角度思考,采用直方图可以更好地建模局部信息,但稳定性会下降;采用窗口平均则可以拥有更好地抗噪性能,但是对局部信息的保留,就没有前者来得多了。
到这里,CNN似乎已经初具雏形,接下来要介绍的非常经典的HOG算法则更有卷积神经网络的影子(虽然它提出的时间比LeNet-5来得更迟),或者说,cv的发展都是同根同源的吧。
5.5.3.3. HOG
HOG的全称是Histogram of Oriental Gradients,即有向梯度直方图,论文发表时用于进行行人检测,直接上pipeline:

直接按照流程进行介绍。
-
先对输入进行gamma和RGB通道的归一化,5.1 中已经介绍过这种方法了。一方面可以减少噪声的干扰,另一方面提供一定的光照和颜色不变性。
-
梯度计算,用一种微分算子处理全图得到响应。若要加速可以使用分离的1*3和3*1算子。
-
获取梯度直方图。这里和前面介绍的gradient histogram一样,将图像划分为数个网格,原文选用的是8*8的像素为一个cell,对每个cell进行梯度直方图统计。这里HOG对梯度直方图进行了一个小的改进,原本是当某个梯度方向落在一个区间内,就将其统计到这个bin里,而HOG则是将直方图划分为9个方向(0-180,分度为20°,不考虑梯度的正负,因为作者发现考虑正负效果更差而且还更慢,就是这么耿直),若梯度落在两个刻度之间,就计算它在两个方向上的投影(是不是比之前直接丢到bin里合理多了)。
-
直方图归一化。以2×2的cell为一个block,对block内的直方图进行归一化,直接看下图:
计算示意图,绿色的为一个cell,蓝色为一个block;图源https://zhuanlan.zhihu.com/p/85829145
在提取了梯度特征后再次对局部的输出进行标准化,这不就是现在NN架构中常用的Instance Norm吗!因为梯度对局部对比度和亮度变化非常敏感,因此我们不仅在输入进行标准化,在得到梯度直方图后选择再进行一次标准化。同时,选取的block大小为2×2的cell(至于为什么选取2×2的cell作为一个block而不是其他值?作者尝试了2×2,3×3,4×4,5×5最后发现2×2的效果最好,有爆调参数那味了~),在一定程度上像是在进行特征聚合或特征交互,在此过程中,相邻cell的信息将会相互传递。
其实这个标准化应该叫做”conv instance norm“,常见的BN、LN、GN、IN的图示如下:
H,W这个维度就是一个输入,而上述的标准化又只在一个实例的局部进行,因此笔者个人认为这个名字取得应该还算比较合理。HOG采用的这种方法在AlexNet上被采用,但是由于后续推出的BN效果远超这样的conv instance norm,因此这种方法在今天已经销声匿迹。
5. 收集HOG特征。直接把上一步的normalized slide window后得到的值全部拼接在一起(一个block里面4个cell,一个cell有9个bin,normalized window在滑动的时候不加padding),以上图为例,将整幅图像划分成cell的个数为 8×16,就是横向有 8个cell,纵向有 16个cell。每个 block有2×2个 cell的话,那么cell的个数为:(16-1)x(8-1)=105。即有 7个水平block和 15个竖直block。再将这 105个block合并,就得到了整个图像的特征描述符,长度为 105×36=3780(斜体来自和图源相同的知乎文章)。
6.利用训练集中产生的所有HOG特征向量(如上一步中得到的3780维向量)训练二分类SVM判断是否是行人。
再次利用批判性的思维审视一下HOG,可以发现它的架构比起GIST与ConvNet更加相似,并且还好巧不巧用上了一些后来才提出的trick。它也充分考虑了局部信息,利用gradient这个局部信息采集各个位置的特征逐步聚合,最后得到一个用于分类的向量。不过从第五和第六步就可以发现,要利用SVM进行分类,其窗口大小必须是一致的,要检测一幅图像中不同位置和尺度的目标,就要对应地使用不同尺度地滑窗进行逐位置检测,时空开销都非常大。而且,由于采用了微分算子提取特征,其对于前景和背景一视同仁,还是没有办法将他们分离,因此会产生非常多对于我们的分类任务来说是无用的特征。
有效利用背景信息的例子:
通过视角和几何这些上下文/背景缩小搜索空间的大小
使用概率的方法建模人出现的概率,对于没有任何约束的情况(左上),图中的每一个区域都需要搜索,对于使用了几何信息的情况(右上),因为行人一般拥有固定的宽高比,只需要关注那些呈现一定形状的区域(怎么判断这些“区域”?通过聚合纹理和轮廓可得边缘,或者显示的建模,如KNN进行分割和合并);加入视角作为约束条件(左下),就可以排除图像上方的检测框,人不可能飞在天上,并且还可以通过街景和道路的方向以及视角效应(在远处收敛)布置近大远小的windows;最后,在使用了视角和几何约束后,可以看见我们只需要布置少量的anchor即可。
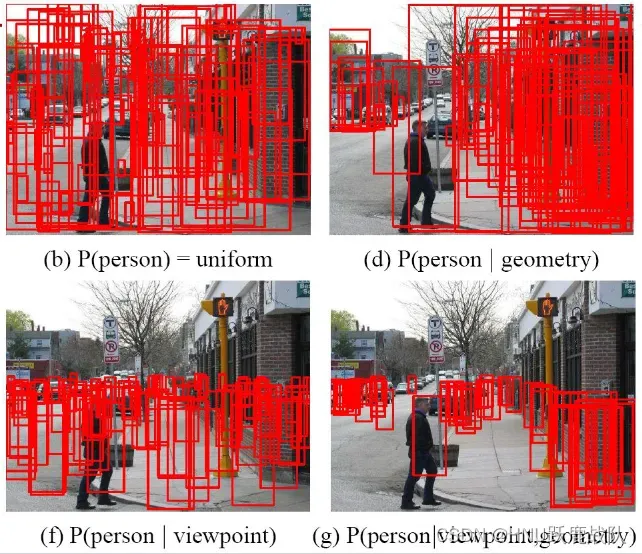
在 5.5.4 中,我们将会提及解决无用特征的方法,利用位于物体上的有效局部信息建模我们要检测的目标,而不是像前面这些方法一样对整张图片或窗口进行建模。
文章出处登录后可见!