目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于深度学习的防诈骗垃圾短信检测系统
项目背景
在当今数字化时代,手机短信已成为诈骗案件的重要手段之一。针对这一问题,本课题研究基于深度学习的防诈骗垃圾短信检测系统,旨在通过先进的人工智能技术,实现对垃圾短信的自动识别和分类,提高短信诈骗的防范能力,对于保障用户的财产安全具有重要的现实意义和长远的发展价值。
数据集
由于网络上没有现有的合适的防诈骗垃圾短信数据集,我决定通过网络爬虫技术收集大量的垃圾短信,制作了一个全新的数据集。这个数据集包含了各种诈骗场景的短信样本,通过网络爬取,我能够获取到真实的诈骗场景和多样的工作环境,这将为我的研究提供更准确、可靠的数据。我相信这个自制的数据集将为基于深度学习的防诈骗垃圾短信检测系统的研究提供有力的支持,并为该领域的发展做出积极贡献。
设计思路
算法理论技术
分类挖掘算法
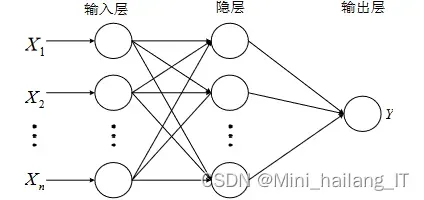
神经网络是一种模仿人脑神经元连接方式的计算模型,通过权值的动态调整实现信息的存储、传递和处理。这种网络具有强大的学习能力,能够对输入的数据进行特征提取和模式识别。根据不同的结构和算法,神经网络可以分为感知机模型、BP神经网络、RBF神经网络和SOM神经网络等。这些网络都具有非线性映射、分类识别和知识处理等智能特性,使得它们在许多领域,如图像识别、自然语言处理、人工智能等,都发挥着重要作用。神经网络是一种具有智能化特点的计算模型,其优势在于能够通过学习实现对复杂数据的处理和理解。
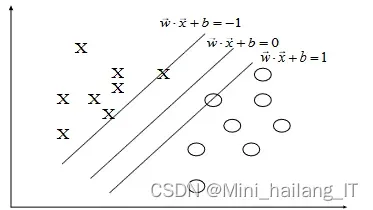
支持向量机(SVM)是一种强大的机器学习算法,特别适用于处理小样本、非线性和高维数据。SVM利用了统计学中的最小结构风险原理和VC维原理,旨在在学习精度和学习复杂度之间取得平衡,以实现最佳的模型泛化能力。SVM不仅能够处理线性可分数据,还通过使用核函数将数据映射到高维空间来处理非线性数据,从而在更高维的空间中构建最大间距的超平面来实现分类。不同的核函数会导致不同的分类函数,从而为SVM提供了灵活性和多样性。尽管这种方法可以提高模型的正确率,但也伴随着计算复杂度的增加。
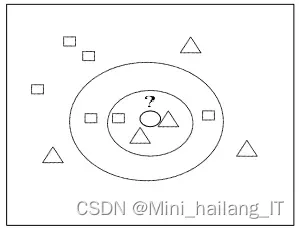
最近邻分类算法(KNN)是一种简单而有效的分类方法,其核心思想是依据待分类样本在特征空间中最近的K个邻居的类别来确定其类别。KNN算法在处理特征分布交错或重叠较多的数据时表现良好,但当样本分布不均衡时,其分类准确性可能降低。此外,KNN算法不仅限于分类,还可以用于回归,即通过计算未知样本最近的K个样本在某一属性上的平均值来预测该未知样本的属性值。为了提高预测的准确性,可以采用距离加权等改进方法。
垃圾短信检测
在构建垃圾短信客户预识别模型时,需要考虑模型的准确性和可解释性,以及指标与业务经验的匹配度。由于神经网络和支持向量机难以解释,逻辑回归在处理二值型变量上受限,KNN算法不适合样本分布极不均衡的情况,决策树算法可能过拟合且剪枝技术要求高,因此选择朴素贝叶斯算法作为建模工具。朴素贝叶斯算法假设属性之间相互独立,因此属性筛选对于模型准确性至关重要。
模型训练
数据预处理:在数据库建模前,数据预处理是一个关键步骤,旨在修正缺失值、异常值和重复样本等问题,以提高建模效果。对于缺失值,当一个记录的缺失属性超过20%时,可以考虑删除该记录;对于属性,如果一个属性只有一种值,则可能没有足够的区分度,可以删除。缺失值处理方法包括填充常数、均值、众数、中位数或预测值。异常值处理需要根据属性的特性来决定,例如,对于入网时长这种非负属性,负值显然是异常的,可以用0替代。对于连续属性的极端值,可以用均值加减三倍标准差来替代。这些预处理步骤对于确保建模数据的质量和提高模型预测准确性至关重要。
垃圾短信客户预识别建模的过程包括以下关键步骤:
- 选择建模工具:在开始建模之前,首先需要确定合适的建模工具,这对于后续的模型构建至关重要。
- 确定建模算法:明确建模的目标是分类、预测还是关联分析,并根据目的选择合适的挖掘算法。
- 数据准备:收集并整理样本数据,这些数据是建模的基础。
- 数据预处理:对原始数据进行清洗,包括去除重复值、填补缺失值和处理异常值等,以提高数据质量。
- 属性筛选:从原始数据中筛选出对目标变量有显著影响的属性,排除可能的冗余指标,以简化模型并提高效率。
- 划分训练集和测试集:将正负样本按7:3的比例分层抽样,分为建模训练集和测试集,以确保模型具有良好的泛化能力。
- 模型训练:使用筛选后的属性训练模型,生成分类规则或决策机制。
- 模型校验和评估:在测试集上验证模型的分类准确性。如果模型在训练集和测试集上的表现均达到预期标准,则可以将模型部署到实际应用中;否则,需要对模型进行进一步优化。
相关代码示例:
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 垃圾短信数据集
messages = [
("Buy now! Limited time offer!", 1),
("Congratulations! You've won a prize!", 1),
("Hello, how are you?", 0),
("Reminder: Your appointment is tomorrow", 0),
("URGENT: Reply to this message now!", 1),
]
# 将文本和标签分离
texts = [message[0] for message in messages]
labels = [message[1] for message in messages]
# 将文本数据转换为特征向量
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(texts)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.2, random_state=42)
# 创建朴素贝叶斯分类器
classifier = MultinomialNB()
# 在训练集上训练模型
classifier.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = classifier.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)海浪学长项目示例:





更多帮助
版权声明:本文为博主作者:Mini_hailang_IT原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/ASASASASASASAB/article/details/136383648