Paper name
LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
Paper Reading Note
Paper URL: https://arxiv.org/pdf/2303.16199.pdf
Code URL: https://github.com/ZrrSkywalker/LLaMA-Adapter
TL;DR
- 2023 上海人工智能实验室和 CUHK MMLab 出的文章。提出 LLaMA-Adapter,一种高效的微调方法,将 LLaMA 调整为指令跟随模型。对于 llama7b 模型来说,可训练参数缩小到 1.2M,只需要 1 小时即可完成 52K 数据微调 (基于 8xA100 训练),比 Alpaca 快 3 倍
Introduction
背景
- 最近,大语言模型 (LLM) 在之类跟随 (instruction-following) 模型方面取得了重大进展,比如 ChatGPT 和 GPT-3.5 (text-davinci-003)。遵循自然语言的指令或命令,这些 LLM 可以以对话的方式产生专业和基于上下文的回复
- 然而 instruction-following 的方式需要 finetune 模型带来高昂的开发成本。Alpaca 在 LLaMA 模型基础上进行了微调得到一个 instruction-following 模型,基于 175 对人工编写的指令-输出对,Alpaca 利用 GPT-3.5 来基于 self-instruct 的方式将训练数据扩充到 52K。然而 Alpaca 需要对 LLaMA 整个模型进行微调
本文方案
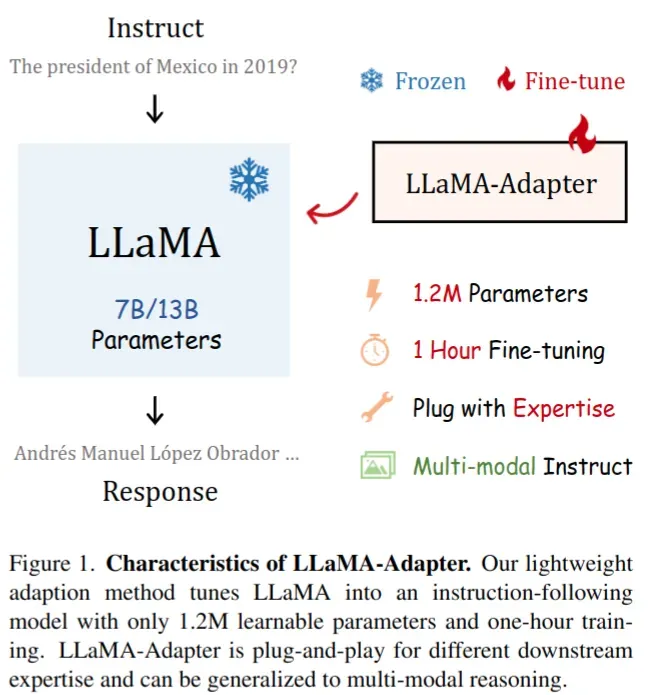
- 本文提出 LLaMA-Adapter,一种高效的微调方法,将 LLaMA 调整为指令跟随模型。对于 llama7b 模型来说,可训练参数缩小到 1.2M,只需要 1 小时即可完成 52K 数据微调 (基于 8xA100 训练),比 Alpaca 快 3 倍
- 具体来说,在 LLaMA 的更深层的 transformer 层中,将一组可学习的自适应提示作为前缀附加到输入指令 token 中。这些提示学习将新指令(条件)自适应地注入 LLaMA
- 为了避免在早期训练阶段适应提示中的噪声,将插入层的 attention 机制修改为零初始 attention,并使用可学习的门控因子。通过零向量初始化,门控可以首先保留 LLaMA 中的原始知识,并在训练过程中逐步引入指令信号
- 这样做的一个好处和 LoRA 类似,即对于不同的场景可以在基础的 llama 模型 (7B) 上插入不同的插件小模型(1.2 M),用于处理不同场景任务,而不用对每个场景任务都准备一个 7B 的大模型
- 支持多模态输入:支持方式就是简单将图片的 tokens 加到 adaption prompts 中,在 ScienceQA 基准测试中表现出色
Dataset/Algorithm/Model/Experiment Detail
实现方式
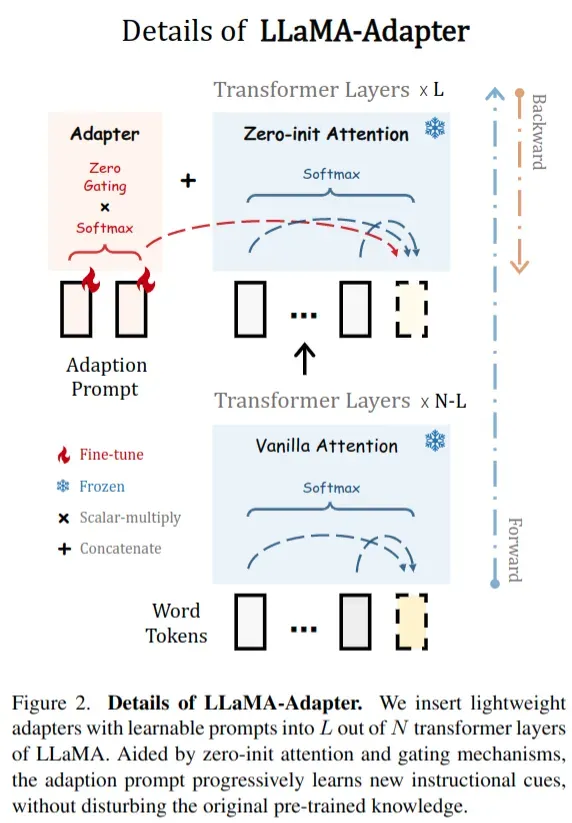
Learnable Adaption Prompts
- 给定 52K instruction-to-output 数据和一个预先训练好的 LLaMA 模型(一个N层 transformer 模型),采用了一套可学习的适应提示(adaption prompts)来指导后续的微调
- 将 L 层 transformer 的提示符记为
,其中
, K 表示每一层的提示长度,C 等于 LLaMA transformer 层的特征维数
- 只对于深层的 L 层插入 adapter,这可以更好地调整具有高级语义的语言表示
- 以第 l 个插入层为例,将长度为 M 的词 token 表示为
。然后,将自适应提示符按照 token 维度作为前缀与
连接,表达式为:
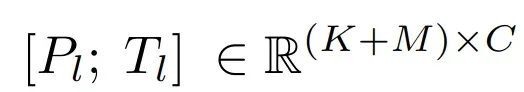
- 将 L 层 transformer 的提示符记为
Zero-init Attention
- 如果适应提示是随机初始化的,可能会在训练开始时对词 token 带来干扰,不利于调优的稳定性和有效性。考虑到这一点,修改了最后 L 个 transformer 层的传统注意机制为零初始注意
- 假设模型基于
信息,在生成第 (M + 1)-th 个单词,将对应的 (M + 1)-th 个词表示为
, attention 首先基于如下 linear 层对 qkv 进行计算
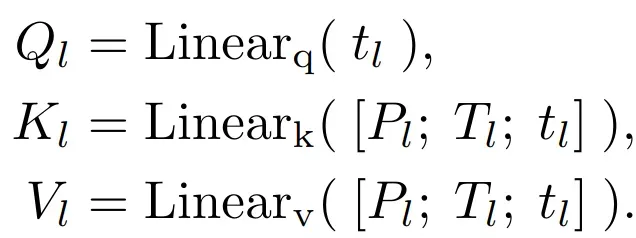
- 为此,采用一种可学习的门控因子
,自适应控制关注中
的重要性
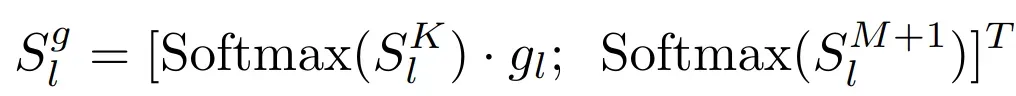
- 假设模型基于
Multi-modal Reasoning
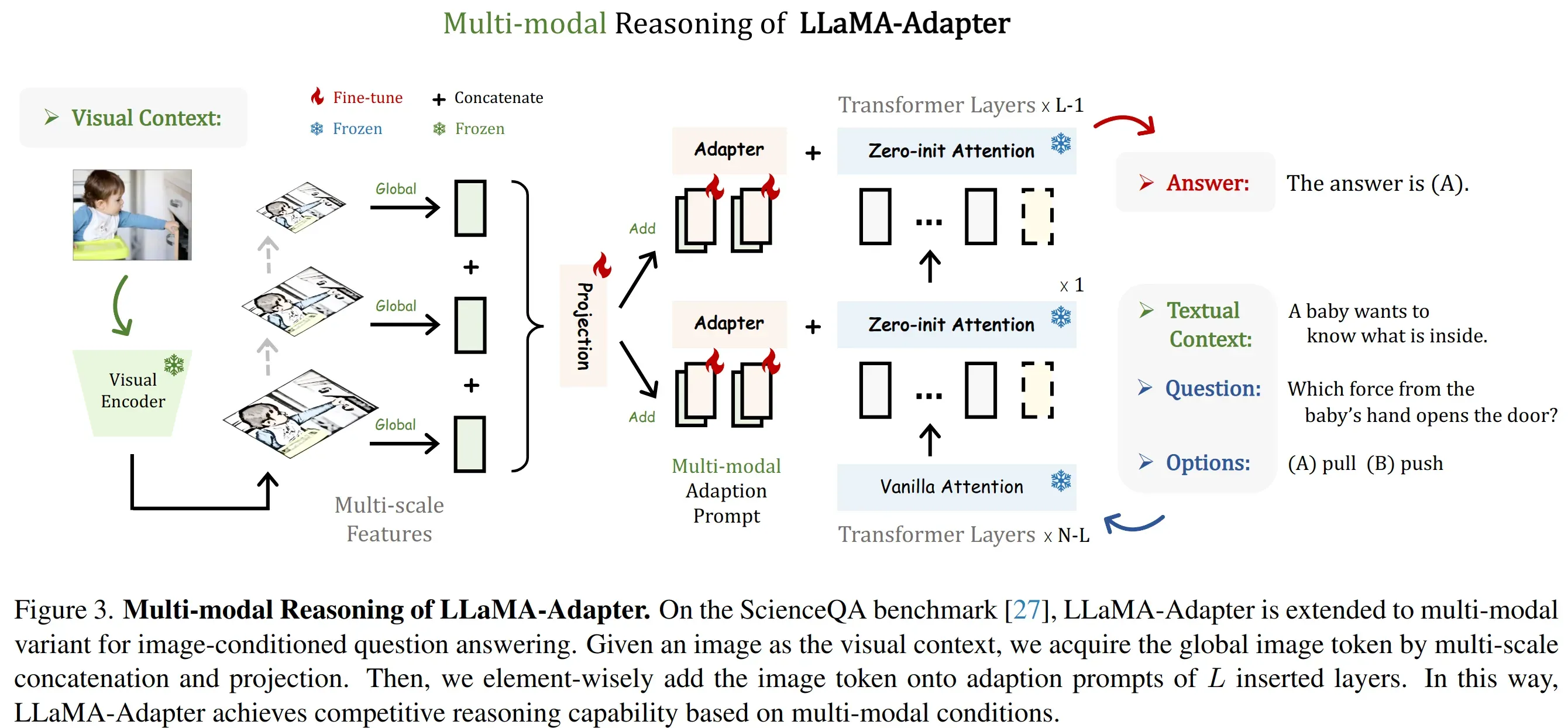
- LLaMA-Adapter 不局限于文本指令,能够根据其他模态输入来回答问题,为语言模型增加了丰富的跨模态信息
- 对于图片输入,使用 CLIP 提取多尺度的全局特征,然后将这些多尺度特征 concat 起来,经过一个投影层得到全局的信息表征
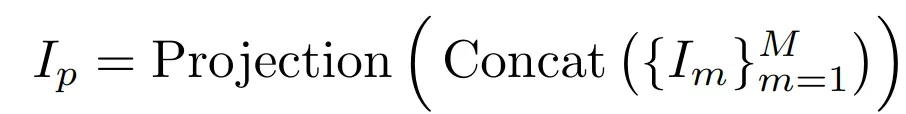
- 对于图片输入,使用 CLIP 提取多尺度的全局特征,然后将这些多尺度特征 concat 起来,经过一个投影层得到全局的信息表征
实验结果
实施细节
- Stanford Alphaca 的 52K instruction-following 数据作为训练集
- {instruction}是任务的描述,{input}是任务的上下文,{output}是 GPT-3.5 生成的答案
- 其中 40% 的数据有 {input} 信息
- 8xA100 进行训练 5 个 epoch
- 在 llama 7B 上做实验,transformer 层数 N=32,对于深层的 30 层都插入 adapter layer,提示符长度 K = 10
instruction follow 效果对比
- 由于还缺乏严格的评估指标,简单地展示了一些响应示例进行比较。仅对 1.2M 参数进行微调,本文的方法产生了与完全微调的 Alpaca 和大规模 GPT-3 模型相当的合理响应

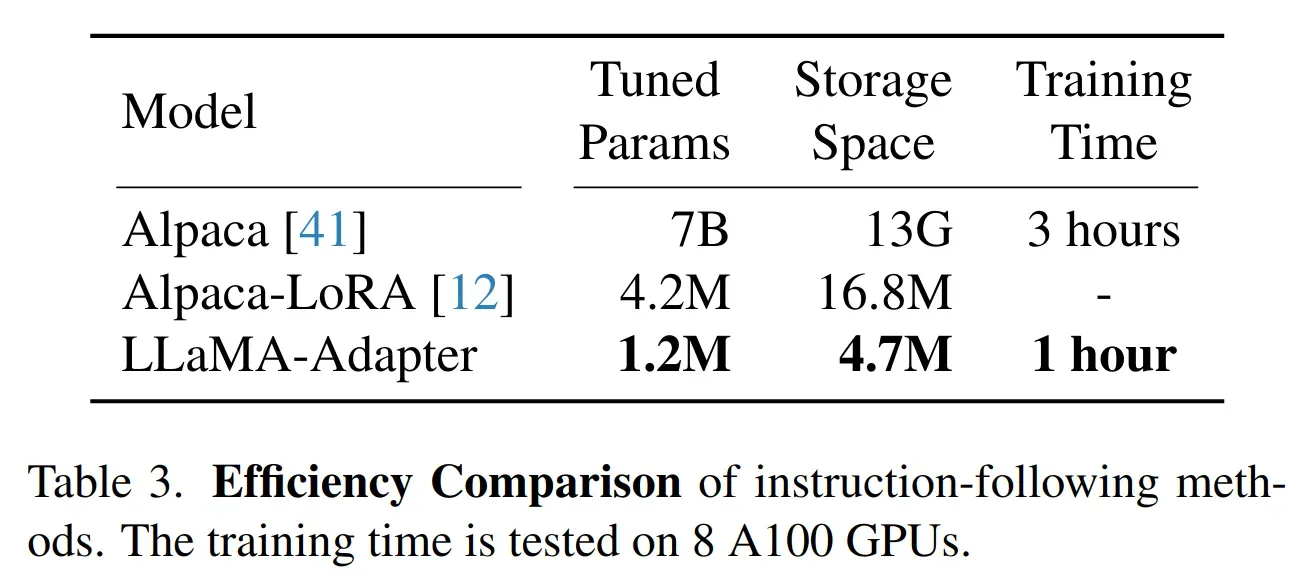
训练效率对比
- 可训练参数比 lora 还少,训练时间相比于原始 alpaca-llama 降低 3 倍
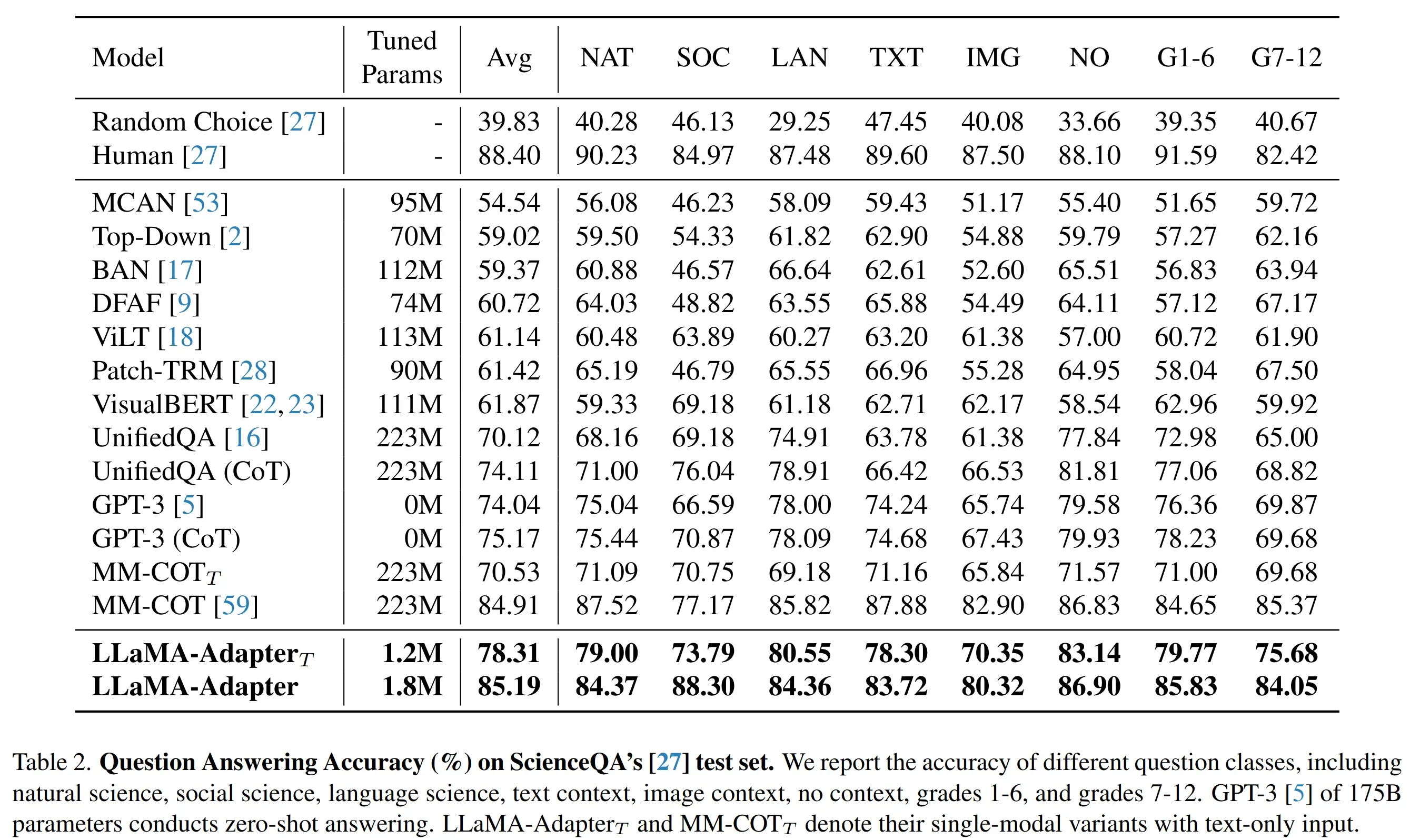
多模态输入效果
- 在 ScienceQA 上进行训练,测试结果是 SOTA。其中
是纯文本输入,可以看到和带图片输入的差距很大
Ablation Study
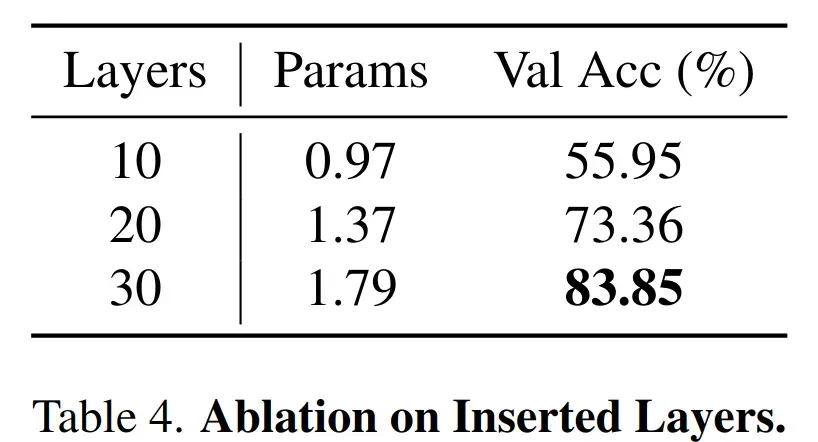
-
增加 adapter 的训练层数,可以看到增加更多训练层的精度会更好
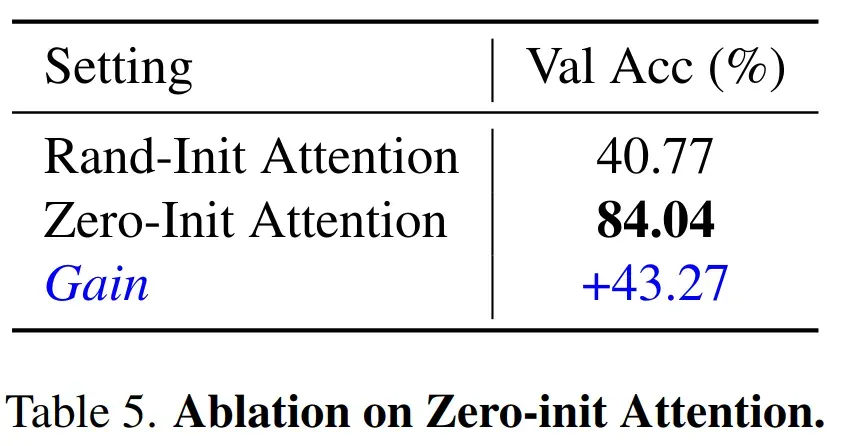
-
零初始化的提升也很明显
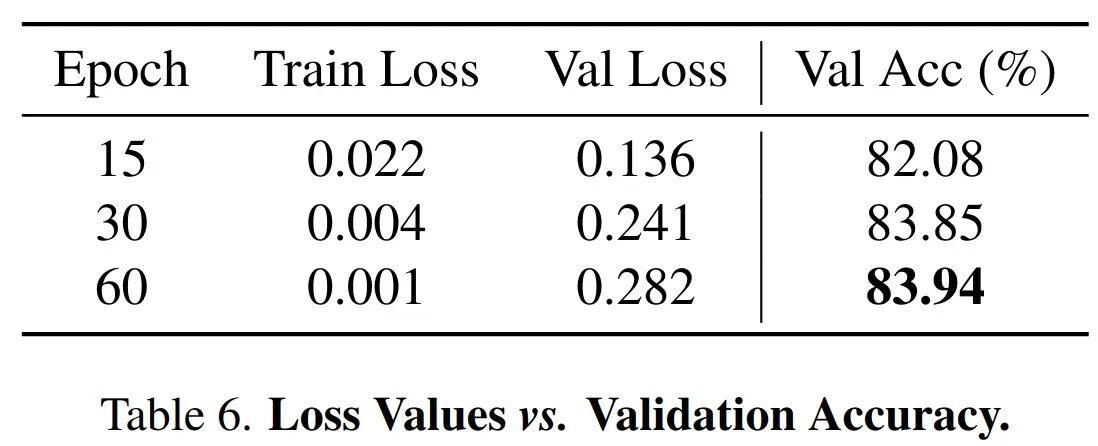
-
方法对过拟合问题较为鲁棒,训练 60 epoch 情况下 acc 是最高的
Thoughts
- 很直观的做 llm 微调的实现思路,加一些可学习的 prompt 思路和 Visual Prompt Tuning 很像
- 与比 LoRA 的缺点看起来是增加了一定推理计算量,本文中和 LoRA 等方法的对比还不够详细
文章出处登录后可见!
已经登录?立即刷新