声明一下:本人现在在学习机器学习以及深度学习方面的知识,想通过CSDN平台去记录自己的学习历程,也希望可以和大家一起学习,共同进步。
1.读取数据
df = pd.read_csv(
"london_bike_sharing.csv",
parse_dates=['timestamp'],
index_col="timestamp"
)
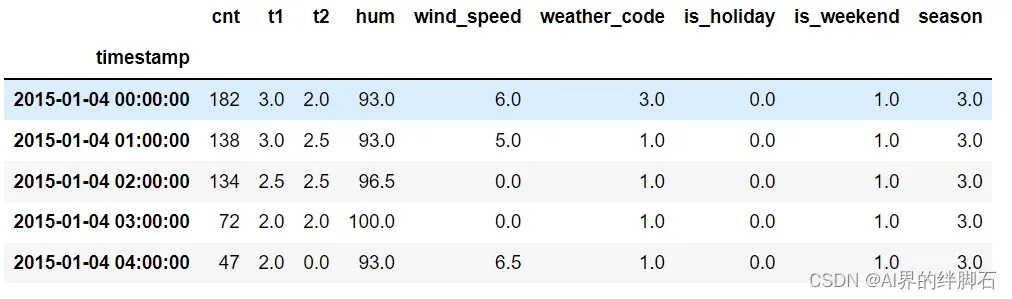
展示部分数据
2.添加特征(小时、天、月份、星期)
df['hour'] = df.index.hour
df['day_of_month'] = df.index.day
df['day_of_week'] = df.index.dayofweek
df['month'] = df.index.month
3.按月进行重新采样
df_by_month = df.resample('M').sum()#向下采样并执行聚合
4.划分训练集和测试集
train_size = int(len(df) * 0.9)
test_size = len(df) - train_size
train, test = df.iloc[0:train_size], df.iloc[train_size:len(df)]
print(len(train), len(test))
最后我们得到训练集和测试集的大小分别为15672 和1742。
5.数据预处理
拓展:我们在机器学习领域,总是看到“算法的鲁棒性”这类字眼。搜查资料发现鲁棒性可以有3个层面的概念:
1.模型具有较高的精度或有效性,这也是对于机器学习中所有学习模型的基本要求;
2.对于模型假设出现的较小偏差,只能对算法性能产生较小的影响; 主要是:噪声(noise)
3.对于模型假设出现的较大偏差,不可对算法性能产生“灾难性”的影响;主要是:离群点(outlier)
为了提高算法的鲁棒性(剔除不必要的离群点),该案例引入sklearn中的RobustScaler 函数。
RobustScaler的计算方法如下:
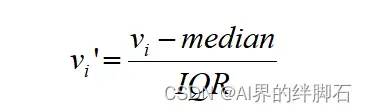
其中vi表示样本的某个值;median是样本的中位数;IQR是样本的四分位距
from sklearn.preprocessing import RobustScaler#导包
f_columns = ['t1', 't2', 'hum', 'wind_speed']#选择要处理的列
f_transformer = RobustScaler()
cnt_transformer = RobustScaler()
#fit()的作用:可以理解为一个训练过程
f_transformer = f_transformer.fit(train[f_columns].to_numpy())#这里将dataframe转化为numpy
cnt_transformer = cnt_transformer.fit(train[['cnt']])
#分别对训练集和测试集进行处理
train.loc[:, f_columns] = f_transformer.transform(train[f_columns].to_numpy())
train['cnt'] = cnt_transformer.transform(train[['cnt']])
test.loc[:, f_columns] = f_transformer.transform(test[f_columns].to_numpy())
test['cnt'] = cnt_transformer.transform(test[['cnt']])
#transfrom()的作用:在fit的基础上,进行标准化,降维,归一化等操作
拓展:
上面的代码将fit和transform分开写,其实也可以用fit_transform。
1.fit_transform是fit和transform的组合。fit_transform是将fit和transform合并,即先拟合数据,然后转化它将其转化为标准形式。
2.注意的是,训练集使用fit_transform(),而测试集使用tranform(),不再使用fit_transform();原因:必须确保两个训练集有相同的数据指标,即处理方式相同!
3.举个简单的例子
fit_transform(train data)先根据具体转换的目的找到数据的整体指标,如均值、方差、最大值最小值…,然后对train data进行transform,从而实现数据的标准化、归一化…。根据之前fit的整体指标,对test data使用同样的均值、方差、最大最小值等指标进行transform(test data),从而保证train data和test data的处理方式相同。
原文请查看此处
6.设置时间步长(LSTM)
#定义一个设置时间步长的函数
def create_dataset(X, y, time_steps=1):
Xs, ys = [], []
for i in range(len(X) - time_steps):
v = X.iloc[i:(i + time_steps)].values
Xs.append(v)
ys.append(y.iloc[i + time_steps])
return np.array(Xs), np.array(ys)#转换为numpy数组
对训练、测试集分别调用函数
time_steps = 10#时间步长为10个小时
# reshape to [samples, time_steps, n_features]
X_train, y_train = create_dataset(train, train.cnt, time_steps)
X_test, y_test = create_dataset(test, test.cnt, time_steps)
print(X_train.shape, y_train.shape)
得到训练、测试集的大小为(15662, 10, 13) (15662,)
其中的(15662, 10, 13)可以这样理解 :
- 15662:样本数
- 10:10小时
- 13:除了训练标签以外的列数
7. 建立LSTM模型
model = keras.Sequential()#创建顺序模型
model.add(
keras.layers.Bidirectional(
keras.layers.LSTM(
units=128,
input_shape=(X_train.shape[1], X_train.shape[2])#输入层只需要给出样本的特征尺寸
)
)
)
Bidirectional:实现RNN类型神经网络的双向构造
model.add(keras.layers.Dropout(rate=0.2))
model.add(keras.layers.Dense(units=1))
model.compile(loss='mean_squared_error', optimizer='adam')#损失函数为'MSE',优化器为Adam
8.训练模型
history = model.fit(
X_train, y_train,
epochs=30,
batch_size=32,
validation_split=0.1,
shuffle=False#不打乱顺序
)
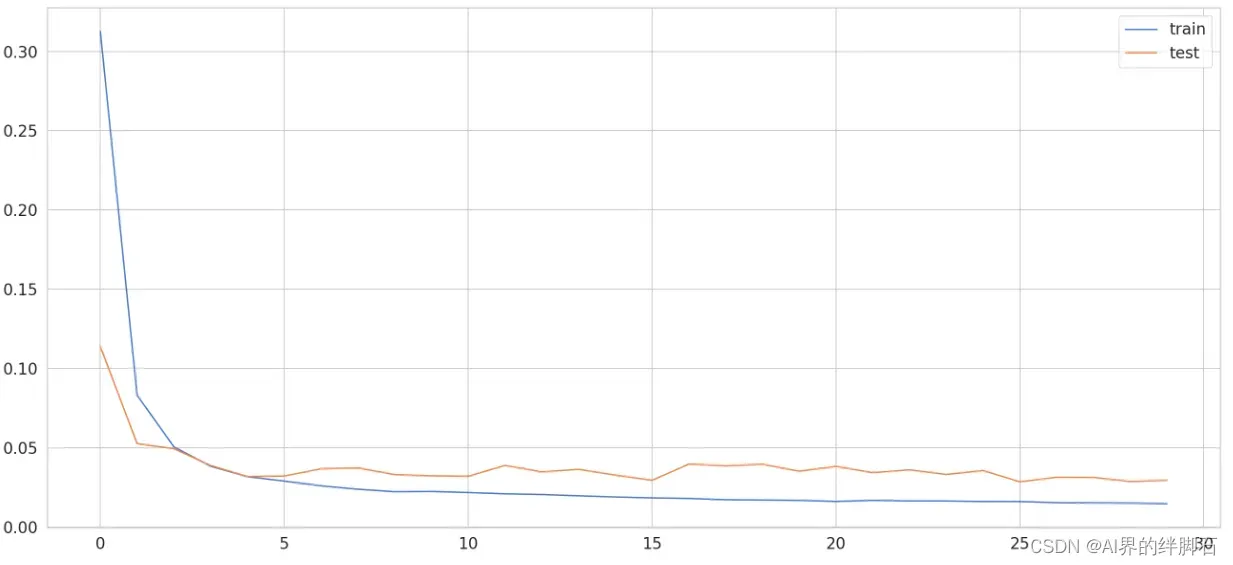
看一下训练结果
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='test')
plt.legend();
9.模型预测
y_pred = model.predict(X_test)
对标签数据进行反归一化处理(inverse_transform)
y_train_inv = cnt_transformer.inverse_transform(y_train.reshape(1, -1))
y_test_inv = cnt_transformer.inverse_transform(y_test.reshape(1, -1))
y_pred_inv = cnt_transformer.inverse_transform(y_pred)
注意还是要采取之前归一化的标准,即这里的cnt_transformer
如果归一化时的对象的shape是(n, 3),则反归一化时的 data 的shape必须是(m, 3)
10.预测结果可视化
plt.plot(y_test_inv.flatten(), marker='.', label="true")
plt.plot(y_pred_inv.flatten(), 'r', label="prediction")
plt.ylabel('Bike Count')
plt.xlabel('Time Step')
plt.legend()
plt.show();
关于flatten函数的介绍:
- 功能:将numpy数组展开为一维数组
- 默认方向是行方向,加’a’也是行方向,但是加‘f’是列方向
- flatten函数不能直接作用于列表 !
文章出处登录后可见!