本文采用模型迁移的方法,先用凯斯西储大学的断层承载数据集训练模型,然后冻结模型底层卷积层(前三个卷积层)的参数,然后少量使用来自西交大学的轴承故障数据对模型的顶层进行微调,最后利用西安交通大学的大量轴承数据来测试模型的性能。
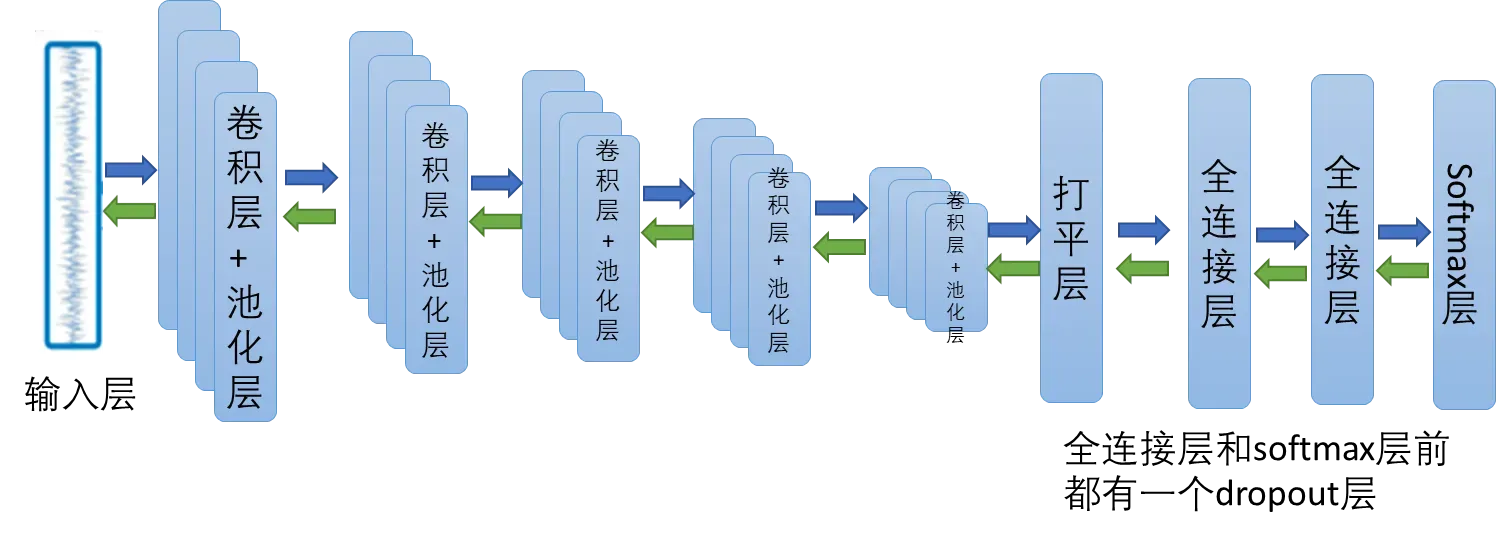
模型使用的是VGG-16框架,具体模型结构如下图:
每一个卷积层都采用4个尺寸为 15 、步长为 1 的卷积核进行等长卷积 ; 池化层采用尺寸为 2 、步长为 2 的最大值池化方式,全连接层节点数分别为 300 , 50 ; softmax 层输出 9 个结果。
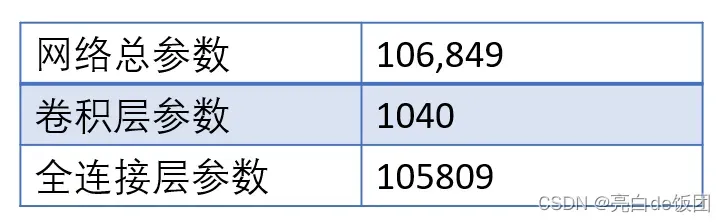
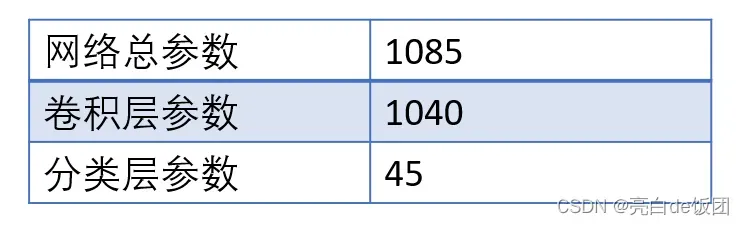
全连接层可以用全局均值池化层代替,减少过拟合,大大降低网络参数
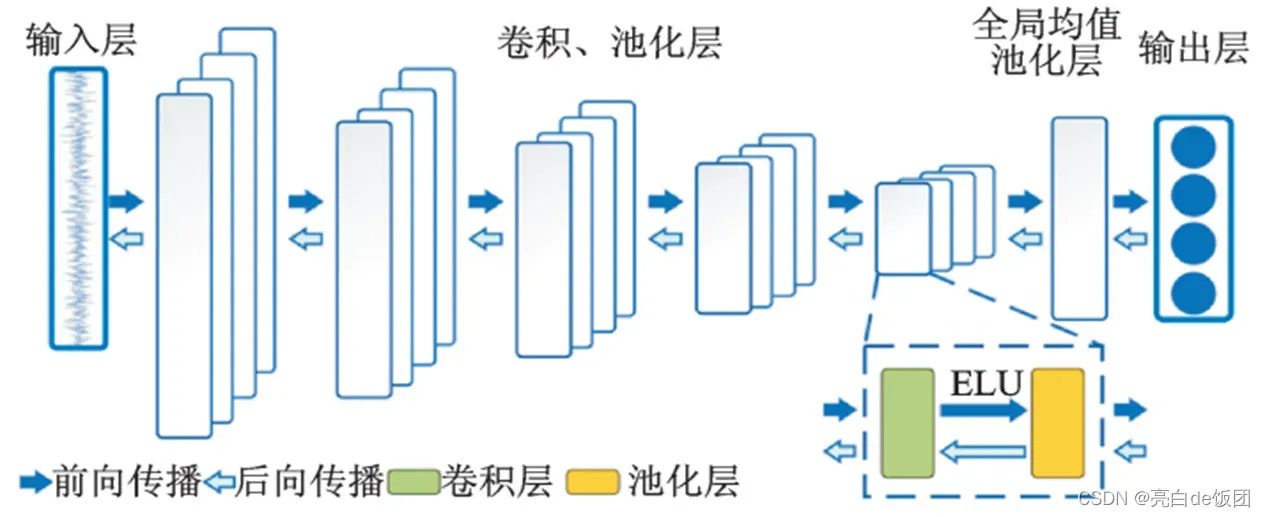
每一卷积层都采用4个尺寸为 15 、步长为 1 的卷积核进行等长卷积 ; 池化层采用尺寸为 2 、步长为 2 的最大值池化方式,卷积层输出特征经过全局均值池化后直接输出到 softmax 层。
第一步是对凯斯西储大学数据集进行预处理和标记。代码如下:
import scipy.io as sio
import numpy as np
import csv
import pandas as pd
import os
import tensorflow as tf
rom sklearn import preprocessing # 0-1编码
from sklearn.model_selection import StratifiedShuffleSplit # 随机划分,保证每一类比例相同
def awgn(x, snr, seed=7):
'''
加入高斯白噪声 Additive White Gaussian Noise
:param x: 原始信号
:param snr: 信噪比
:return: 加入噪声后的信号
'''
np.random.seed(seed) # 设置随机种子
snr = 10 ** (snr / 10.0)
xpower = np.sum(x ** 2) / len(x)
npower = xpower / snr
noise = np.random.randn(len(x)) * np.sqrt(npower)
return x + noise
def prepro(d_path, length=864, number=1000, normal=True, rate=[0.5, 0.25, 0.25], enc=True, enc_step=28,nose=False):
"""对数据进行预处理,返回train_X, train_Y, valid_X, valid_Y, test_X, test_Y样本.
:param d_path: 源数据地址
:param length: 信号长度,默认2个信号周期,864
:param number: 每种信号个数,总共10类,默认每个类别1000个数据
:param normal: 是否标准化.True,Fales.默认True
:param rate: 训练集/验证集/测试集比例.默认[0.5,0.25,0.25],相加要等于1
:param enc: 训练集、验证集是否采用数据增强.Bool,默认True
:param enc_step: 增强数据集采样顺延间隔
:return: Train_X, Train_Y, Valid_X, Valid_Y, Test_X, Test_Y
```
import preprocess.preprocess_nonoise as pre
train_X, train_Y, valid_X, valid_Y, test_X, test_Y = pre.prepro(d_path=path,
length=864,
number=1000,
normal=False,
rate=[0.5, 0.25, 0.25],
enc=True,
enc_step=28)
```
"""
# 获得该文件夹下所有.mat文件名
filenames = os.listdir(d_path)
def capture(original_path):
"""读取mat文件,返回字典
:param original_path: 读取路径
:return: 数据字典
"""
files = {}
for i in filenames:
# 文件路径
file_path = os.path.join(d_path, i)
file = sio.loadmat(file_path)
file_keys = file.keys() #获取每个mat文件中所有变量名
for key in file_keys:
if 'DE' in key: #DE应该是某一测的振动信号,大概率是电机驱动侧的
files[i] = file[key].ravel()
return files
def slice_enc(data, slice_rate=rate[1]+rate[2] ):
"""将数据切分为前面多少比例,后面多少比例.
:param data: 单挑数据
:param slice_rate: 验证集以及测试集所占的比例
:return: 切分好的数据
"""
keys = data.keys()
Train_Samples = {}
Test_Samples = {}
for i in keys:
slice_data = data[i]
if nose:
slice_data=awgn(slice_data,5)
all_lenght = len(slice_data)
end_index = int(all_lenght * (1 - slice_rate))
samp_train = int(number * (1 - slice_rate))
Train_sample = []
Test_Sample = []
if enc:
enc_time = length // enc_step
samp_step = 0 # 用来计数Train采样次数
for j in range(samp_train):
random_start = np.random.randint(low=0, high=(end_index - 2 * length))
label = 0
for h in range(enc_time):
samp_step += 1
random_start += enc_step
sample = slice_data[random_start: random_start + length]
Train_sample.append(sample)
if samp_step == samp_train:
label = 1
break
if label:
break
else:
for j in range(samp_train):
random_start = np.random.randint(low=0, high=(end_index - length))
sample = slice_data[random_start:random_start + length]
Train_sample.append(sample)
# 抓取测试数据
for h in range(number - samp_train):
random_start = np.random.randint(low=end_index, high=(all_lenght - length))
sample = slice_data[random_start:random_start + length]
Test_Sample.append(sample)
Train_Samples[i] = Train_sample
Test_Samples[i] = Test_Sample
return Train_Samples, Test_Samples
# 仅抽样完成,打标签
def add_labels(train_test):
X = []
Y = []
label = 0
for i in filenames:
x = train_test[i]
X += x
lenx = len(x)
Y += [label] * lenx
label += 1
return X, Y
# one-hot编码
def one_hot(Train_Y, Test_Y):
Train_Y = np.array(Train_Y).reshape([-1, 1])
Test_Y = np.array(Test_Y).reshape([-1, 1])
Encoder = preprocessing.OneHotEncoder()
Encoder.fit(Train_Y)
Train_Y = Encoder.transform(Train_Y).toarray()
Test_Y = Encoder.transform(Test_Y).toarray()
Train_Y = np.asarray(Train_Y, dtype=np.int32)
Test_Y = np.asarray(Test_Y, dtype=np.int32)
return Train_Y, Test_Y
def scalar_stand(Train_X, Test_X):
# 用训练集标准差标准化训练集以及测试集
scalar = preprocessing.StandardScaler().fit(Train_X)
Train_X = scalar.transform(Train_X)
Test_X = scalar.transform(Test_X)
return Train_X, Test_X
def valid_test_slice(Test_X, Test_Y):
test_size = rate[2] / (rate[1] + rate[2])
ss = StratifiedShuffleSplit(n_splits=1, test_size=test_size)
for train_index, test_index in ss.split(Test_X, Test_Y):
X_valid, X_test = Test_X[train_index], Test_X[test_index]
Y_valid, Y_test = Test_Y[train_index], Test_Y[test_index]
return X_valid, Y_valid, X_test, Y_test
# 从所有.mat文件中读取出数据的字典
data = capture(original_path=d_path)
# 将数据切分为训练集、测试集
train, test = slice_enc(data)
# 为训练集制作标签,返回X,Y
Train_X, Train_Y = add_labels(train)
# 为测试集制作标签,返回X,Y
Test_X, Test_Y = add_labels(test)
# 为训练集Y/测试集One-hot标签
Train_Y, Test_Y = one_hot(Train_Y, Test_Y)
# 训练数据/测试数据 是否标准化.
if normal:
Train_X, Test_X = scalar_stand(Train_X, Test_X)
else:
# 需要做一个数据转换,转换成np格式.
Train_X = np.asarray(Train_X)
Test_X = np.asarray(Test_X)
# 将测试集切分为验证集合和测试集.
Valid_X, Valid_Y, Test_X, Test_Y = valid_test_slice(Test_X, Test_Y)
return Train_X, Train_Y, Test_X, Test_Y,Valid_X, Valid_Y
if __name__ == "__main__":
path = r'E:\SWJ\test_0'
train_X, train_Y, valid_X,valid_Y,test_X, test_Y = prepro(d_path=path,
length=2400,
number=1000,
normal=True,
rate=[0.05,0.05,0.9],
enc=True,
enc_step=28)
train_X = tf.expand_dims(train_X, axis=2)
#train_Y = tf.expand_dims(train_Y, axis=2)
test_X = tf.expand_dims(test_X, axis=2)
#test_Y = tf.expand_dims(test_Y, axis=2)
valid_X = tf.expand_dims(valid_X,axis=2)
print(train_X.shape,train_Y.shape)
print(test_X.shape,test_Y.shape)
print(valid_X.shape,valid_Y.shape)第二部分,将西储大学的数据发送到模型中,训练模型
import pandas as pd
from matplotlib import pyplot as plt
import dataprocess
import tensorflow as tf
from tensorflow.keras.layers import *
from tensorflow.keras import losses,layers,optimizers,Sequential,backend,regularizers
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ReduceLROnPlateau,ModelCheckpoint
import XJTUdataprocess
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
# 设置 GPU 显存占用为按需分配,增长式
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
except RuntimeError as e:
# 异常处理
print(e)
#导入数据库
path = r'E:\SWJ\test_0'
train_X, train_Y, valid_X,valid_Y,test_X, test_Y=dataprocess.prepro(
d_path=path,
length=2048,
number=2000,
normal=True,
rate=[0.6,0.2,0.2],
enc=True,
enc_step=28)
train_X = tf.expand_dims(train_X,axis=2)
#train_Y = tf.expand_dims(train_Y,axis=2)
test_X = tf.expand_dims(test_X,axis=2)
#test_Y = tf.expand_dims(test_Y,axis=2)
#搭建卷积神经网络模型
cnn_network = Sequential()
cnn_network.add(Conv1D(4,kernel_size=15,strides=1,padding='same',activation='relu',input_shape=(2048,1),kernel_regularizer=regularizers.l2(0.01)))
cnn_network.add(MaxPool1D(pool_size=2,strides=2))
cnn_network.add(Conv1D(4,kernel_size=15,strides=1,padding='same',activation='relu',kernel_regularizer=regularizers.l2(0.01)))
cnn_network.add(MaxPool1D(pool_size=2,strides=2))
cnn_network.add(Conv1D(4,kernel_size=15,strides=1,padding='same',activation='relu',kernel_regularizer=regularizers.l2(0.01)))
cnn_network.add(MaxPool1D(pool_size=2,strides=2))
cnn_network.add(Conv1D(4,kernel_size=15,strides=1,padding='same',activation='relu',kernel_regularizer=regularizers.l2(0.01)))
cnn_network.add(MaxPool1D(pool_size=2,strides=2))
cnn_network.add(Conv1D(4,kernel_size=15,strides=1,padding='same',activation='relu',kernel_regularizer=regularizers.l2(0.01)))
cnn_network.add(MaxPool1D(pool_size=2,strides=2))
cnn_network.add(Flatten())
cnn_network.add(Dropout(0.5))
cnn_network.add(Dense(128,activation='relu',kernel_regularizer=regularizers.l2(0.01)))
cnn_network.add(Dropout(0.5))
cnn_network.add(Dense(64,activation='relu',kernel_regularizer=regularizers.l2(0.01)))
cnn_network.add(Dropout(0.5))
# cnn_network.add(GlobalAveragePooling1D())
cnn_network.add(Dense(9,activation='softmax'))
#优化器和损失函数
opt=Adam(lr=0.01,beta_1=0.9,beta_2=0.99,epsilon=1e-08,decay=0.0)
'''
lr:float> = 0.学习率
beta_1:float,0 <beta <1。一般接近1。一阶矩估计的指数衰减率
beta_2:float,0 <beta <1。一般接近1。二阶矩估计的指数衰减率
epsilon:float> = 0,模糊因子。如果None,默认为K.epsilon()。该参数是非常小的数,其为了防止在实现中除以零
decay:float> = 0,每次更新时学习率下降
'''
cnn_network.compile(
optimizers=opt,
#loss=tf.keras.losses.CategoricalCrossentropy,#损失函数
loss='categorical_crossentropy',
metrics=['accuracy'])# 评价函数,比较真实标签值和模型预测值
# 设置动态学习率
reduce_lr = ReduceLROnPlateau(monitor='val_accuracy',factor=0.1,patience=10,verbose=1,mode='max',epsilon=0.0001)
# 保存最佳模型
filepath = 'weights.best.hdf5'
checkpoint = ModelCheckpoint(filepath,monitor='val_accuracy',verbose=1,save_best_only=True,mode='max')
callbacks_list = [reduce_lr,checkpoint]
#显示网络参数
cnn_network.summary()#打印神经网络结构,统计参数数目
# 训练集和验证集送入模型框架,进行训练。
# fit函数会返回每一个epoch后的训练集准确率、损失和验证集准确率和损失,并保存在history中,具体代码如下
history = cnn_network.fit(train_X,
train_Y,
batch_size=32,#批大小
epochs=150,#迭代数
validation_data=(test_X, test_Y),#用来评估损失,以及在每轮结束时的任何模型度量指标
shuffle=True,
verbose=1,
callbacks=callbacks_list
)
# 保存模型
# cnn_network.save('1dDCNNmodel.h5')
#将测试集和训练集准确率和损失放入data字典中。
data = {}
data['accuracy']=history.history['accuracy']
data['val_accuracy']=history.history['val_accuracy']
data['loss']=history.history['loss']
data['val_loss']=history.history['val_loss']
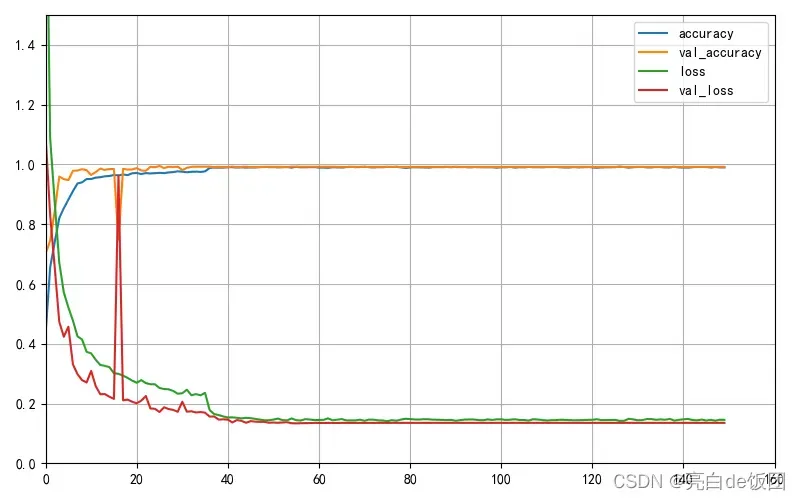
pd.DataFrame(data).plot(figsize=(8, 5))#图片大小(宽,高)
plt.grid(True)#图片是否有网格
plt.axis([0, 50, 0, 1.5])
plt.show()结果如下:
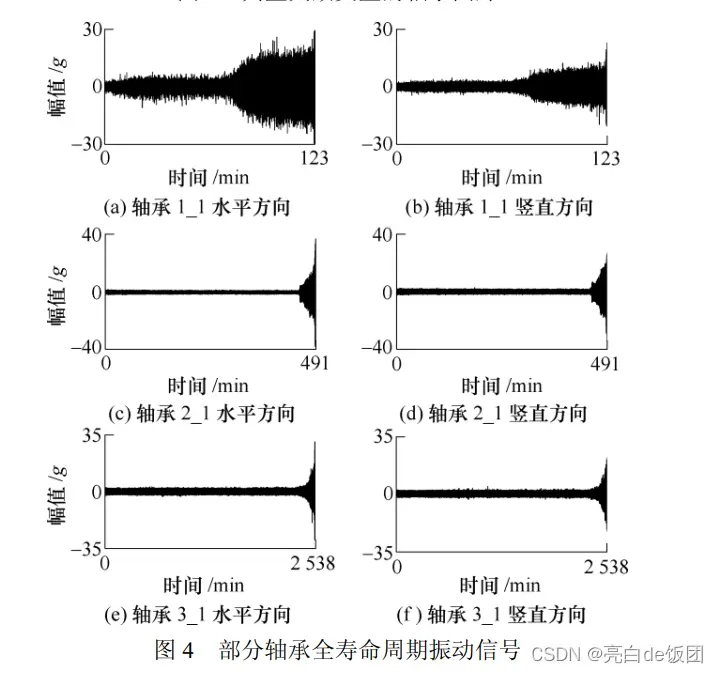
第三步,对西安交通大学的数据集进行预处理并标注。西安交通大学数据集更适合做寿命预测。如果要对其进行分类,可以选择以下五个数据文件夹:
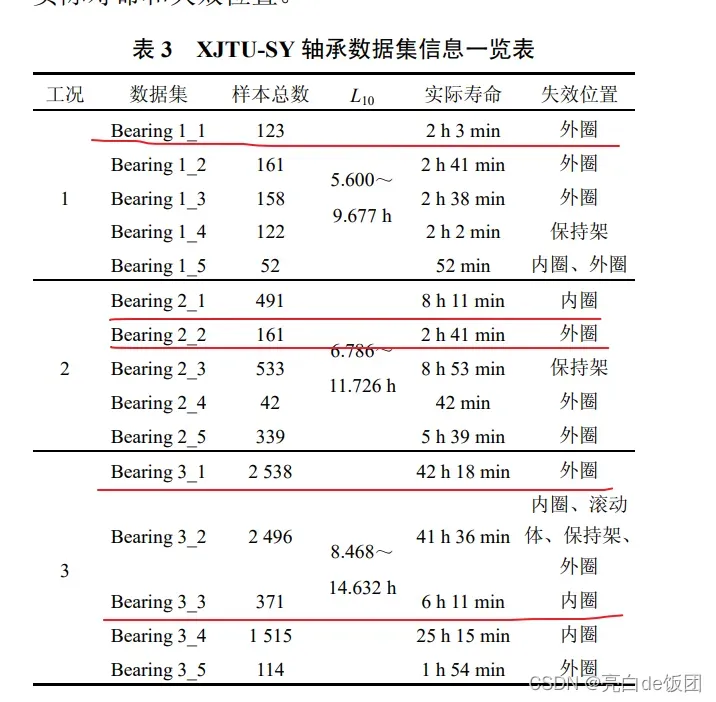
此外,西交大的数据是轴承全寿命数据,数据集里正常信号和故障信号都有,所以我们要分类就要截取故障信号。博主计算的5个数据集的故障段为
35hz bearing1-1 83-104 失效
37.5hz bearing2-1 468-491 失效
37.5hz bearing2-2 32-99 失效
40hz bearing3-1 2424-2538 失效
40hz bearing3-3 348-371 失效
因为西交大的数据集是CSV格式的,西储大学的数据集是matlab格式的,所以只要把dataprocess中的函数capture替换成csv_read即可,具体代码如下:
def csv_read(CSV_data, CSV_number, begin, end):
data_csv = []
data_H = []
data_L = []
# CSV = [[123, 161, 158, 122, 52], [491, 161, 533, 42, 339], [2538, 2496, 371, 1515, 114]]
CSV_path = ["", "35Hz12kN", "37.5Hz11kN", "40Hz10kN"]
# 35Hz12kN 1 1-123 2-161 3-158 4-122 5-52
# 37.5Hz11kN 2 1-491 2-161 3-533 4-42 5-339
# 40Hz10kN 3 1-2538 2-2496 3-371 4-1515 5-114
path = "E://公共数据集//西交大轴承数据集//XJTU-SY_Bearing_Datasets//" + CSV_path[
CSV_data] + "//Bearing" + str(CSV_data) + "_" + str(CSV_number) + "//"
# print(path)
for i in range(begin, end):
csv_data = csv.reader(open(path + "%d.csv" % i, "r"))
for list in csv_data:
data_csv.append(list)
for j in range(1, len(data_csv)):
data_H.append(float(data_csv[j][1]))
data_L.append(float(data_csv[j][0]))
data_csv = []
return data_H, data_L
data1_1_1_H, data1_1_1_L = csv_read(1, 1, 84, 92)
data2_2_1_H, data2_2_1_L = csv_read(2, 1, 469, 477)
data2_2_2_H, data2_2_2_L = csv_read(2, 1, 53, 61)
data3_3_1_H, data3_3_1_L = csv_read(3, 1, 2425, 2433)
data3_3_3_H, data3_3_3_L = csv_read(3, 1, 349, 357)
filenames = {
'data1': data1_1_1_H,
'data2': data2_2_1_H,
'data3': data2_2_2_H,
'data4': data3_3_1_H,
'data5': data3_3_3_H
}第四步,用西交大数据集微调模型
import XJTUdataprocess
import tensorflow as tf
from tensorflow.keras import models
from tensorflow.keras.layers import *
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import ReduceLROnPlateau,ModelCheckpoint
import pandas as pd
from matplotlib import pyplot as plt
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
# 设置 GPU 显存占用为按需分配,增长式
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
except RuntimeError as e:
# 异常处理
print(e)
train_X, train_Y, valid_X,valid_Y,test_X, test_Y=XJTUdataprocess.prepro(
# d_path=path,
length=2048,
number=2000,
normal=True,
rate=[0.2,0.4,0.4],
enc=True,
enc_step=28)
train_X = tf.expand_dims(train_X,axis=2)
test_X = tf.expand_dims(test_X,axis=2)
valid_X = tf.expand_dims(valid_X,axis=2)
model = models.load_model('weights.best.hdf5')
model.summary()
model.pop()
model.add(Dense(5,activation='softmax',name='dense_output'))
model.summary()
# # 测试正确率
# loss,accuracy = model.evaluate(test_X,test_Y)
# print('\ntest loss',loss)
# print('accuracy',accuracy)
冻结微调
model.trainable = True
fine_tune_at = 6
for layer in model.layers[:fine_tune_at]:
layer.trainable = False
pass
opt=Adam(lr=0.01,beta_1=0.9,beta_2=0.99,epsilon=1e-08,decay=0.0)
reduce_lr = ReduceLROnPlateau(monitor='val_accuracy',factor=0.5,patience=10,verbose=1,mode='max',epsilon=0.0001)
filepath = 'fine_tune_CNN model.h5'
checkpoint = ModelCheckpoint(filepath,monitor='val_accuracy',verbose=1,save_best_only=True,mode='max')
callbacks_list = [reduce_lr,checkpoint]
model.compile(
optimizers=opt,
loss='categorical_crossentropy',
metrics=['accuracy'])# 评价函数,比较真实标签值和模型预测值
history = model.fit(
train_X,
train_Y,
batch_size=32,
epochs=150,
validation_data=(valid_X,valid_Y),
shuffle=True,
verbose=1,
callbacks=callbacks_list
)
model.summary()
model.save('fine_tune_CNN model.h5')
data = {}
data['accuracy']=history.history['accuracy']
data['val_accuracy']=history.history['val_accuracy']
data['loss']=history.history['loss']
data['val_loss']=history.history['val_loss']
pd.DataFrame(data).plot(figsize=(8, 5))#图片大小(宽,高)
plt.grid(True)#图片是否有网格
plt.axis([0, 150, 0, 1.5])
plt.show()微调结果:
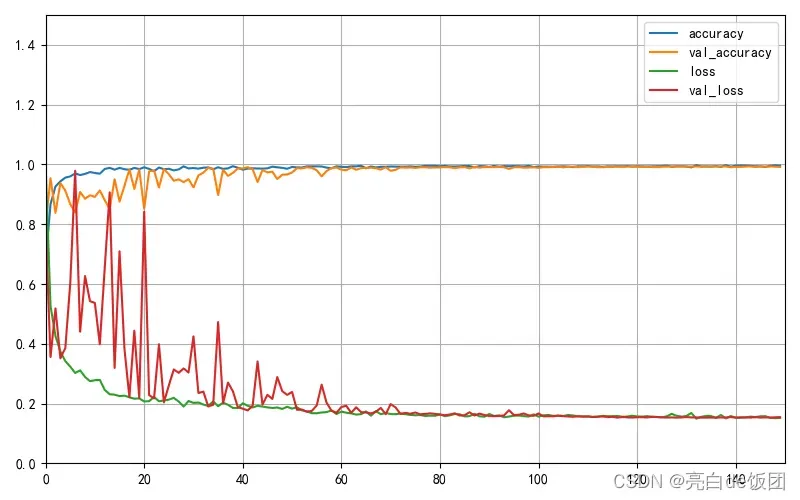
我们可以看到使用迁移学习的模型收敛速度非常快,模型表现良好。
第五步,用西安交通大学的大数据集测试fine-tuned模型的分类准确率。
import XJTUdataprocess
import tensorflow as tf
from tensorflow.keras import models
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
# 设置 GPU 显存占用为按需分配,增长式
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
except RuntimeError as e:
# 异常处理
print(e)
train_X, train_Y, valid_X,valid_Y,test_X, test_Y=XJTUdataprocess.prepro(
# d_path=path,
length=2048,
number=2000,
normal=True,
rate=[0.05,0.05,0.9],
enc=True,
enc_step=28)
train_X = tf.expand_dims(train_X,axis=2)
test_X = tf.expand_dims(test_X,axis=2)
valid_X = tf.expand_dims(valid_X,axis=2)
fine_tune_model = models.load_model('fine_tune_CNN model.h5')
fine_tune_model.summary()
loss,accuracy = fine_tune_model.evaluate(test_X,test_Y)
print('\ntest loss',loss)
print('accuracy',accuracy)正确的验证率是:
test loss 0.15763859033584596
accuracy 0.99
文章出处登录后可见!