- 1 GAN到Stable Diffusion的改朝换代
- 2 从DDPM到Stable Diffusion发展史
- 2.1 DDPM
- 扩散过程(正向)
- 去噪过程(反向)
- 总结
- 优化目标
- 理论推导
- 代码解析
- 2.2 Stable Diffusion
- 3 Consistency终结Diffusion
通过估计数据分布梯度进行生成建模
一文解释 Diffusion Model (一) DDPM 理论推导
1 GAN到Stable Diffusion的改朝换代
随着人工智能在图像生成,文本生成以及多模态生成等生成领域的技术不断累积,生成对抗网络(GAN)、变微分自动编码器(VAE)、normalizing flow models、自回归模型(AR)、energy-based models以及近年来大火的扩散模型(Diffusion Model)。
GAN:额外的判别器
VAE:对准后验分布
EBM基于能量的模型:处理分区函数
归一化流:施加网络约束
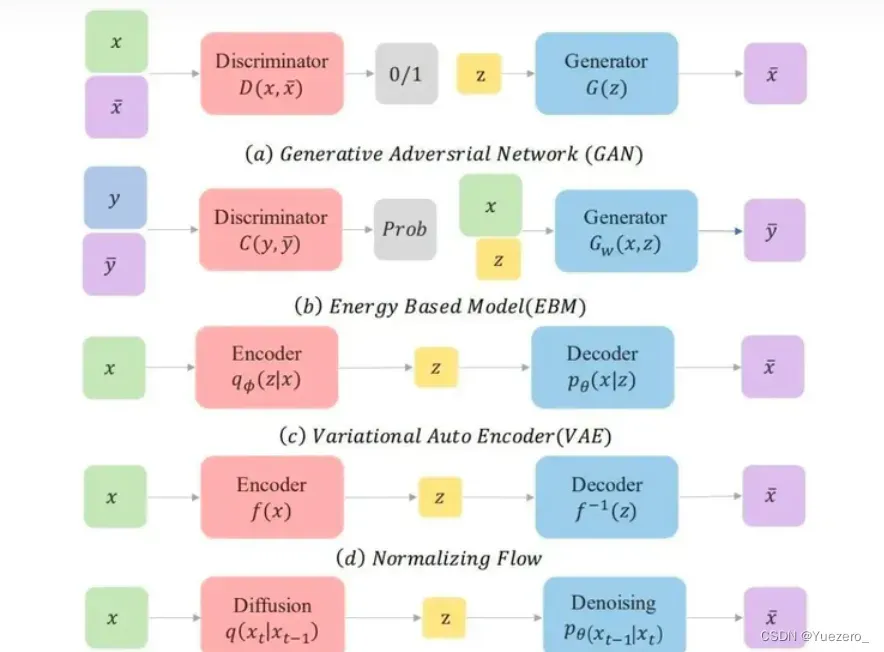
- GAN要训练俩网络,感觉难度较大,容易不收敛,而且多样性比较差,只关注能骗过判别器就得了。
- Diffusion Model用一种更简单的方法来诠释了生成模型该如何学习以及生成,其实感觉更简单。
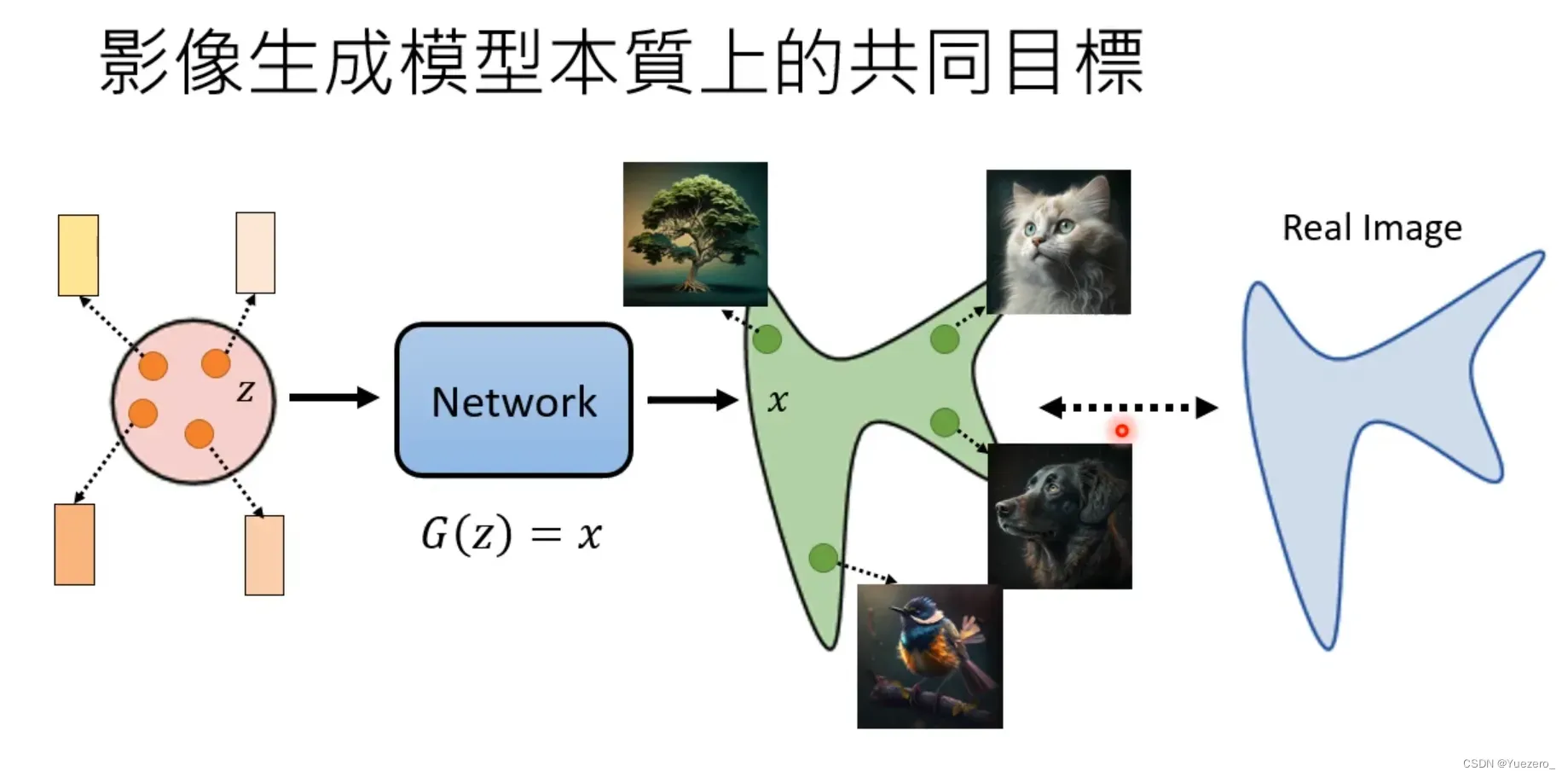
生成式模型的共同目标:
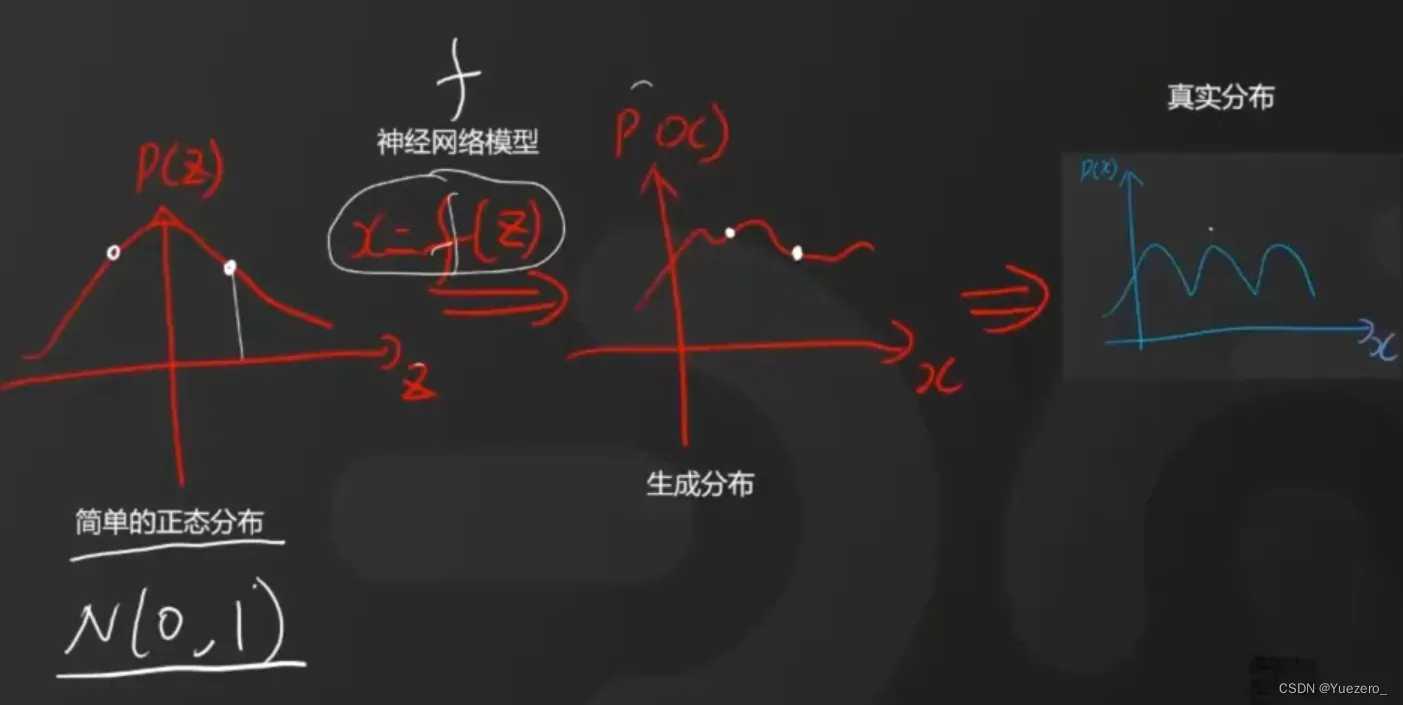
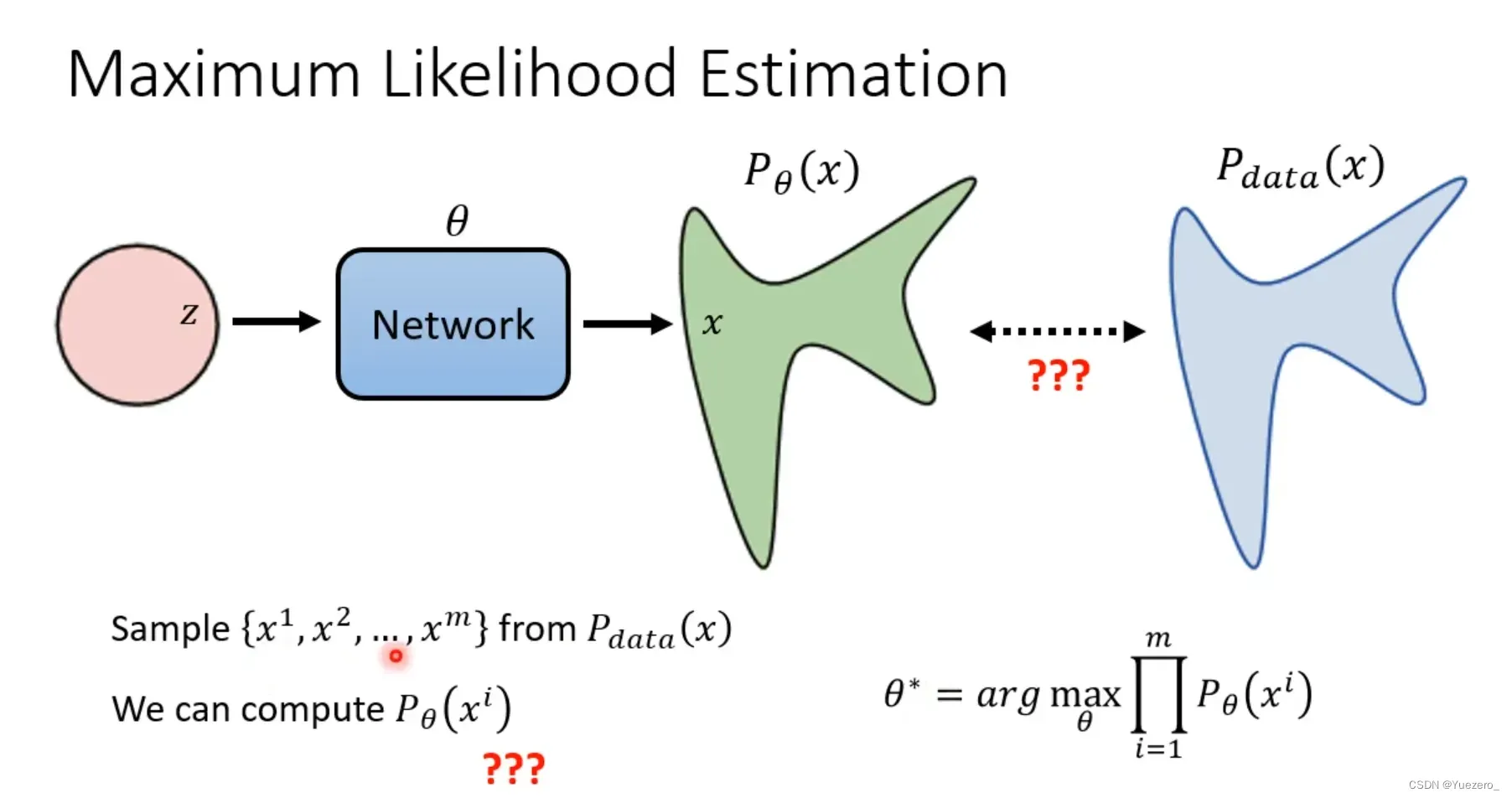
求Network的最佳参数 -> 最大似然估计(使生成图像分布
与标签图片分布
中
的概率最大)

2 从DDPM到Stable Diffusion发展史
2.1 DDPM
Diffusion扩散模型是一类生成式模型,从随机噪声直接生成图片。[DDPM: Denoising Diffusion Probabilistic Models]
扩散过程(正向)
输入原始图像,经过T步不断将高斯噪声
加入到原始图片
中,得到破坏图片
。(
扩散阶段是不含训练参数的,噪声的标准差是固定的,均值由标准差和X0决定)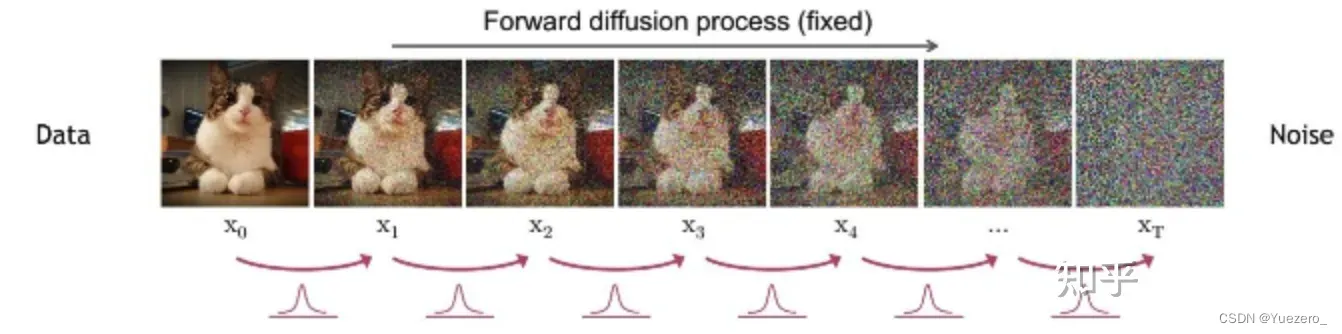

去噪过程(反向)
输入含噪图片,通过预测噪声
,将预测到的噪声从图片中去除,多次迭代逐渐将被破坏的
恢复成
,实现还原成图片。训练一个噪声预测模型,并将输入随机噪声还原成图片,
其中噪声就是标签,还原的时候,模型根据噪声生成对应的图像。
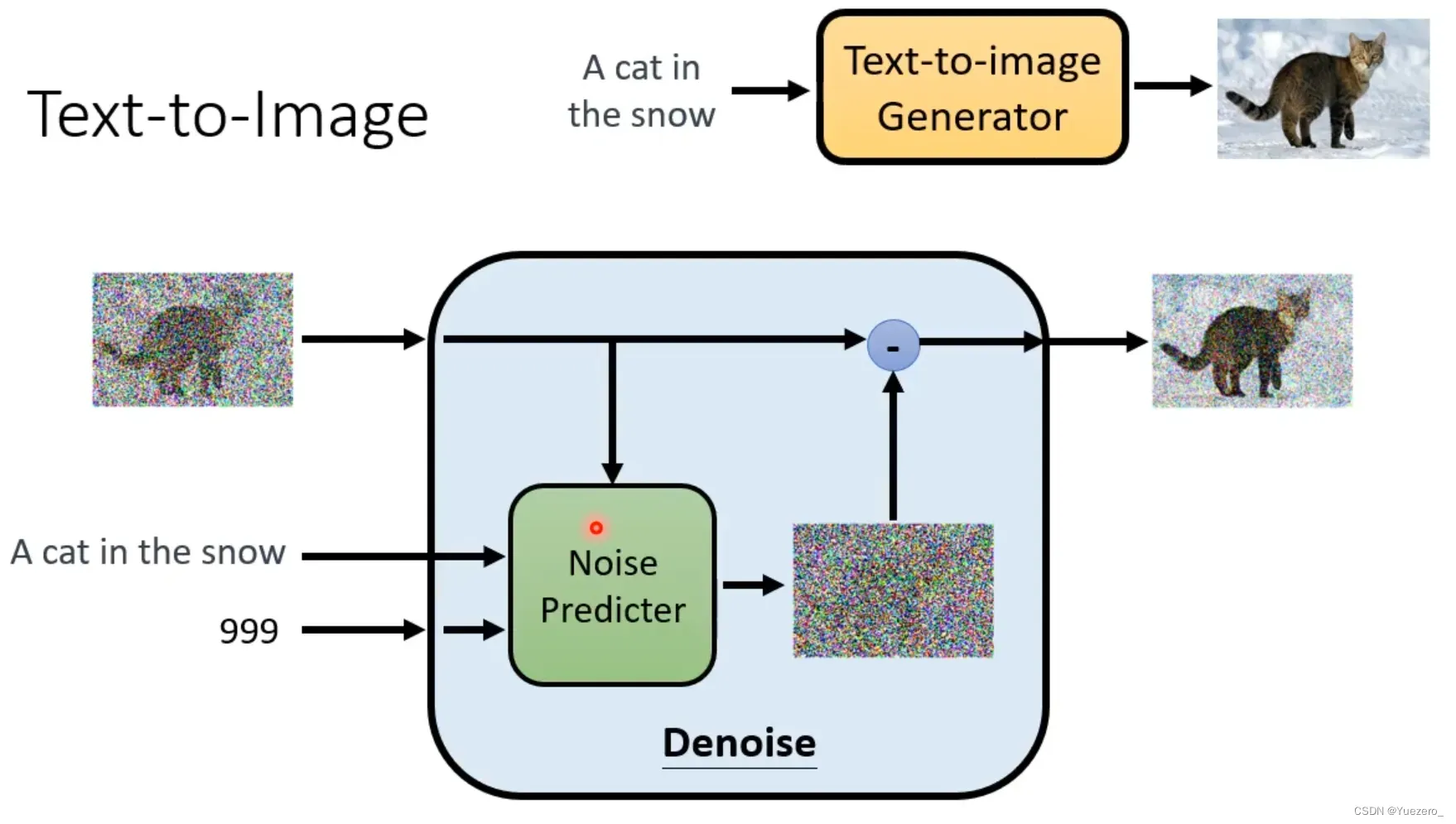
但为什么不直接取mean呢?(为什么需要保持随机性:在denoise时,加点随机性,效果会更好,保证了生成多样性)
DDPM的关键在于去噪过程 :训练一个 (根据 含噪图片 和 轮次
来)
噪声估计模型 ,其中
就是模型的训练参数, 使模型
预测的噪声
与真实用于破坏图片的噪声标签
的L2 Loss更小。在DDPM中,使用U-Net作为预测噪声的模型。
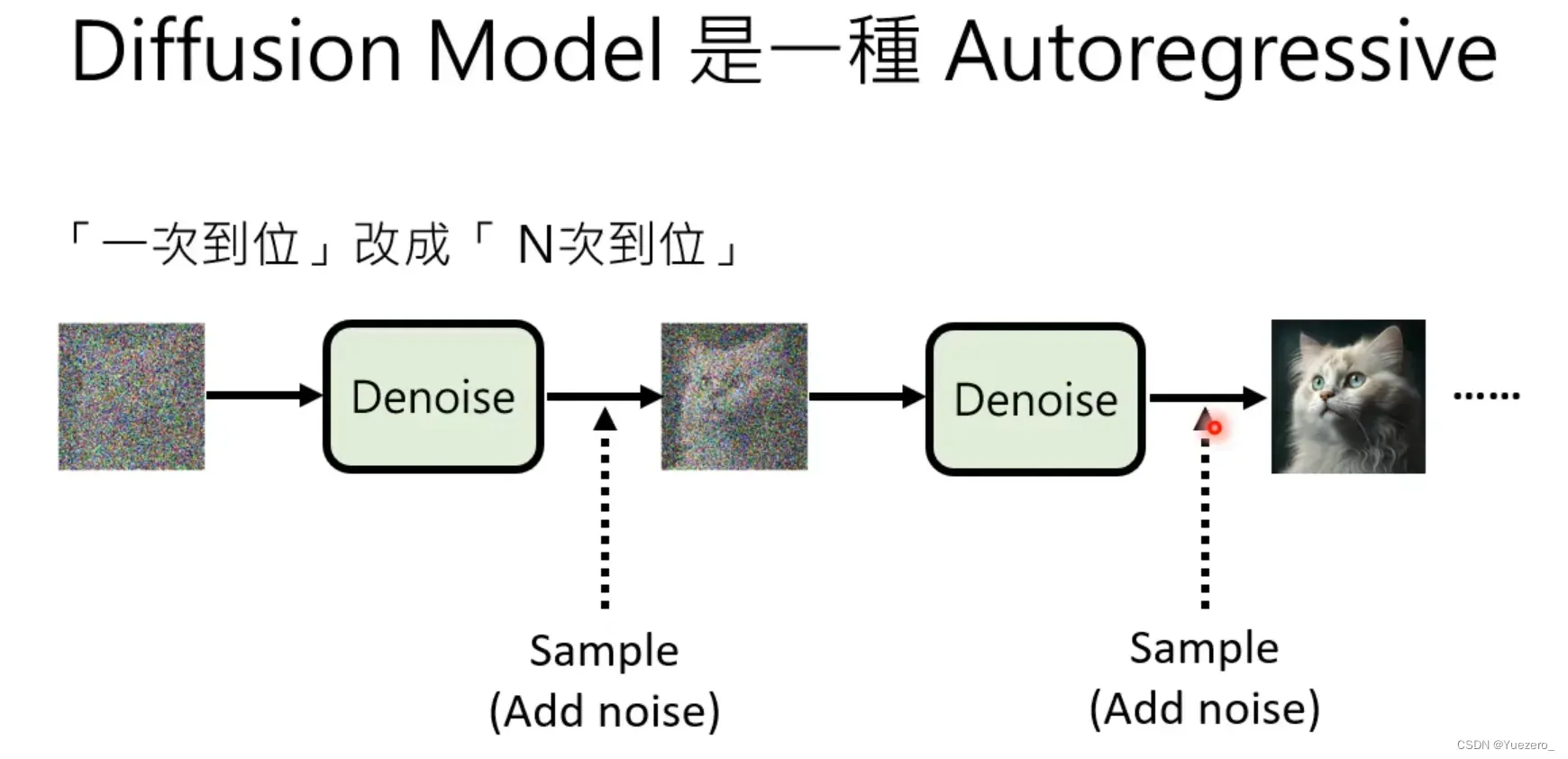
总结
扩散模型是怎么工作的?
-
前向扩散过程: 一个
固定不含参(或预定义)的前向扩散过程,这个前向过程
会逐渐向图像添加高斯噪声
,直到你最终得到纯噪声。
-
反向生成过程: 一个
通过学习得到的含参反向去噪扩散过程
,这个反向过程
就是神经网络从训练中学会如何从纯噪声开始逐渐对一个图像进行去噪,直到你最终能够得到一个实际图像。,从一个随机噪音开始逐渐去噪音
,后验方差
,后验均值
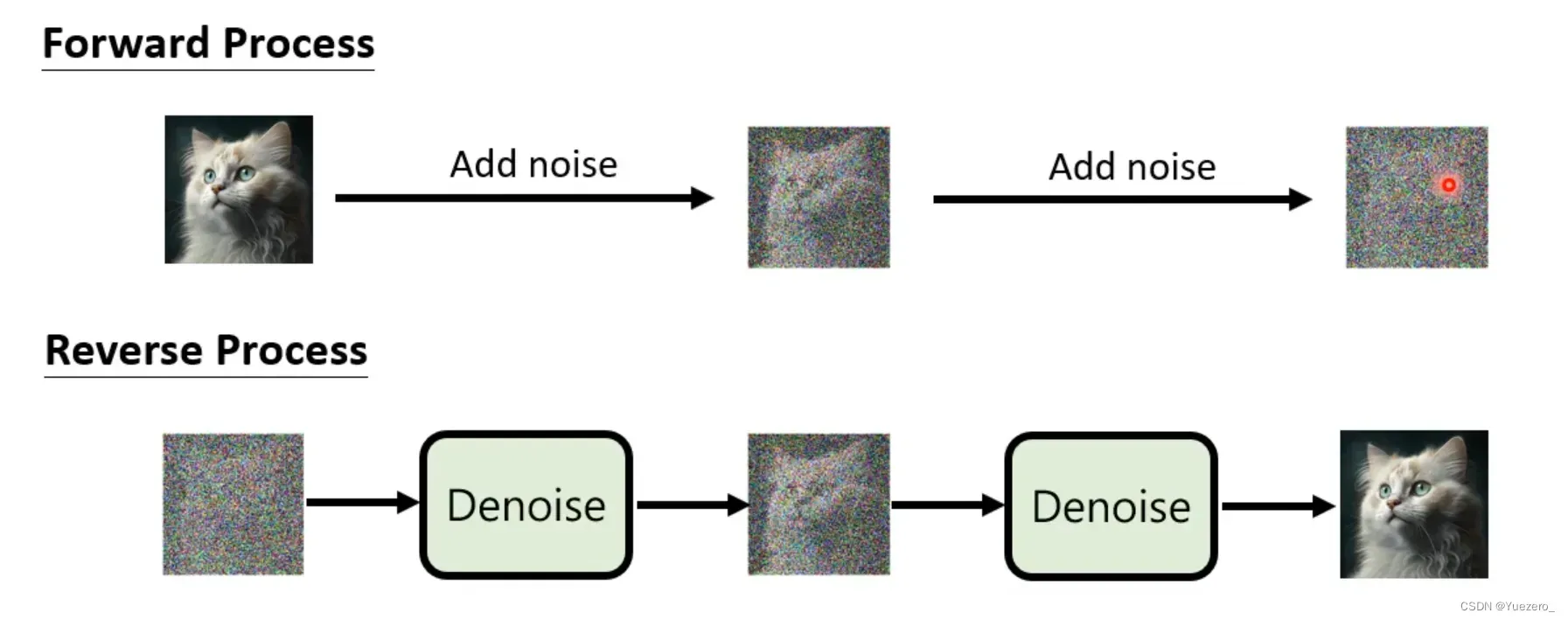
- 正向和反向都是
马尔可夫链:由一组状态和状态之间的转移概率组成。每个状态代表一个可能的事件或状态,转移概率表示从一个状态转移到另一个状态的概率。根据这些转移概率,可以使用马尔可夫链进行模拟和预测。

优化目标
https://zhuanlan.zhihu.com/p/563661713
高斯分布p和高斯分布q的KL散度:

生成目标的分布
的似然函数:
求对数似然最大值 -> 求负对数似然最小值 -> 求负似然函数上界最小值 -> 求最小值
-> 优化预测噪声和真实噪声的L2误差
这里最后一步是利用了Jensen’s inequality,对于网络训练来说,其训练目标为VLB取负:


虽然扩散模型背后的推导比较复杂,但是我们最终得到的优化目标非常简单,就是让网络预测的噪音和真实的噪音一致。DDPM的训练过程也非常简单:随机选择一个训练样本->从[1,T]随机抽样一个t->随机产生噪音–计算当前所产生的带噪音数据->输入网络预测噪音->计算产生的噪音和预测的噪音的L2损失(等价于优化负对数似然)->计算梯度并更新网络 (实际上DDPM的优化目标是噪声预测,而不是直接优化生成的图片)

一旦训练完成,其采样过程也非常简单:从一个随机噪音开始,并用训练好的网络预测噪音,然后计算条件分布的均值,然后用均值加标准差再乘以一个随机噪音,直至t=0完成新样本的生成(最后一步不加噪音)。
不过实际的代码实现和上述过程略有区别(见https://github.com/hojonathanho/diffusion/issues/5:先基于预测的噪音生成,并进行了clip处理(范围[-1, 1],原始数据归一化到这个范围),然后再计算均值。我个人的理解这应该算是一种约束,既然模型预测的是噪音,那么我们也希望用预测噪音重构处理的原始数据也应该满足范围要求。
理论推导
为什么假设噪声是正态分布(高斯分布)?
中心极限定理(CLT):对于一个分布的预测,若通过大量的独立同分布采样取均值进行,在满足一些条件下(工程上一般默认满足),它依分布逼近于正态分布,且具有与未知分布相同的均值和方差。因此,在前向过程中,不断给样本加高斯分布的噪声,最后样本也变成一个高斯噪声了。
前向扩散过程重要公式:
是t时刻的图像分布,
是噪声,我们可以通过初始的分布
和噪声
,进行N步扩散,得到最终的噪声图像

反向生成过程重要公式:
学习到噪声预估模型后,随机生成一个初始噪声
,通过该模型,做N步生成去噪声,恢复到
图片。


Diffusion起作用的关键:
隐变量模型、两个过程都是一个参数化的马尔可夫链、变分推断来进行建模和求解
代码解析
import io
import torch
import numpy as np
import torch.nn as nn
import matplotlib.pyplot as plt
from sklearn.datasets import make_s_curve
from PIL import Image
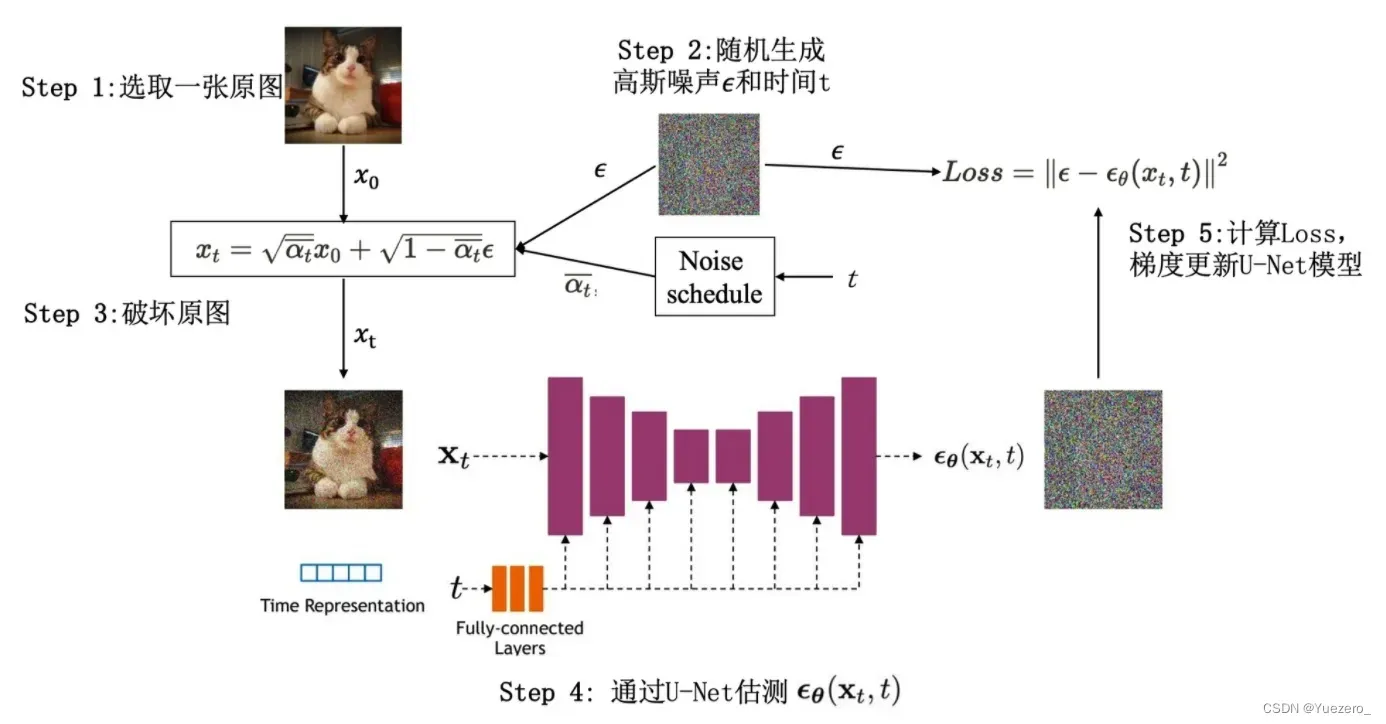
def diffusion_loss_fun(model, x_0):
"""输入原图x_0预测随机时刻t的噪声计算loss,t是随机生成的,实际上是计算batch_size个原图的噪声预测loss"""
batch_size = x_0.shape[0]
# 随机采样一个时刻t,为了提高训练效率,保证t不重复
t = torch.randint(0, model.num_steps, size=(batch_size // 2,))
t = torch.cat([t, model.num_steps - 1 - t], dim=0) # [batch_size, 1]
t = t.unsqueeze(-1) # batch_size长度的序列
# x0的系数
x_weight = model.alpha_bar_sqrt[t]
# noise_eps的系数
noise_weight = model.one_minus_alpha_bar_sqrt[t]
# 生成noise
noise = torch.randn_like(x_0)
# 构造模型的输入x_t
x_t = x_0 * x_weight + noise * noise_weight
# 送入模型,预测t时刻的噪声
pred = model(x_t, t.squeeze(-1))
# 计算预测结果与真实结果的L2误差(噪声图像MSE loss)
return (noise - pred).square().mean()
class DDPM(nn.Module):
def __init__(self, num_steps=100, num_units=128):
super(DDPM, self).__init__()
"""设置超参数 T、alpha、beta"""
self.num_steps = num_steps # 迭代步数T
# 生成100步中,每一步的beta, 保证噪声的权重beta比较小,且逐渐增大,来满足每个逆扩散过程也是高斯分布的假设
self.betas = torch.linspace(-6, 6, self.num_steps)
self.betas = torch.sigmoid(self.betas) * (0.5e-2 - 1e-5) + 1e-5
# 根据beta, 计算alpha, alpha_prod, alpha_previous, alpha_bar_sqrt
self.alpha = 1 - self.betas
self.alpha_prod = torch.cumprod(self.alpha, 0) # 每一步之前所有alpha的累乘
self.alpha_prod_p = torch.cat([torch.tensor([1]).float(), self.alpha_prod[:-1]],
0) # 去掉alpha_prod[-1],然后在前面添加1值
self.alpha_bar_sqrt = torch.sqrt(self.alpha_prod) # 原图x_0的权重weight
# 计算log(1-alpha_bar), sqrt(1-alpha_bar)
self.one_minus_alpha_bar_log = torch.log(1 - self.alpha_prod)
self.one_minus_alpha_bar_sqrt = torch.sqrt(1 - self.alpha_prod) # 噪声noise的权重weight
assert (self.alpha.shape == self.alpha_prod.shape == self.alpha_prod_p.shape == self.alpha_bar_sqrt.shape ==
self.one_minus_alpha_bar_sqrt.shape == self.one_minus_alpha_bar_log.shape)
print(f"all shape same:{self.betas.shape}")
"""反向去噪过程,预测噪声的模型(一般为Unet),但此处使用MLP与直接x+t"""
# 输入含噪图像x_t的mlp
self.mlp = nn.ModuleList(
[
nn.Linear(2, num_units),
nn.ReLU(),
nn.Linear(num_units, num_units),
nn.ReLU(),
nn.Linear(num_units, num_units),
nn.ReLU(),
nn.Linear(num_units, 2)
]
)
# 时间步t的embedding
self.step_embeddings = nn.ModuleList(
[
nn.Embedding(num_steps, num_units),
nn.Embedding(num_steps, num_units),
nn.Embedding(num_steps, num_units),
]
)
def forward(self, x_0, t): # 用mlp模拟unet预测输入原图x_0在第t步生成的噪声
x = x_0
for idx, embedding_layer in enumerate(self.step_embeddings): # 3次对x进行t_embedding融合
t_embedding = embedding_layer(t) # 对t进行embedding
x = self.mlp[2 * idx](x) # 对x进行全连接计算
x += t_embedding # x+t
x = self.mlp[2 * idx + 1](x) # x经过relu
return self.mlp[-1](x) # 经过最后的fc层使得x形状不变
def q_x(self, x_0, t):
"""基于 原图x_0 计算 第t步 生成 噪声图片x_t"""
noise = torch.randn_like(x_0) # noise与x_0形状相同的高斯噪声图像
alpha_x_0_t = self.alpha_bar_sqrt[t] # 第t步原图x_0的权重
alpha_noise_t = self.one_minus_alpha_bar_sqrt[t] # 第t步噪声noise的权重
return alpha_x_0_t * x_0 + alpha_noise_t * noise # 基于x_0和步骤t直接计算噪声图像x_t
def forward_diffusion(self, num_show: int, dataset):
"""模拟经过num_steps步加噪声的过程"""
fig, axs = plt.subplots(2, num_show // 2, figsize=(28, 3))
plt.rc('text', color='blue')
# 10000个点,每个点2个坐标,生成num_steps=100步以内每隔num_steps//num_show=5步加噪声后的图像
for i in range(num_show):
j = i // 10
k = i % 10
q_i = self.q_x(dataset, torch.tensor([i * self.num_steps // num_show])) # 生成i时刻的加噪图像x_i
axs[j, k].scatter(q_i[:, 0], q_i[:, 1], color='red', edgecolor='white')
axs[j, k].set_axis_off()
axs[j, k].set_title('$q(\mathbf{x}_{' + str(i * self.num_steps // num_show) + '})$')
plt.savefig('forward_diffusion.png')
def p_sample_loop(model, shape):
"""inference:从x_t恢复x_{t-1}...x_0"""
cur_x = torch.randn(shape) # [10000,2] 10000个点的坐标
x_seq = [cur_x]
for i in reversed(range(model.num_steps)): # 倒着从x_100, x_99, x_98...x_0进行预测噪声去噪生成,放入x_seq
cur_x = p_sample(model, cur_x, i)
x_seq.append(cur_x)
return x_seq
def p_sample(model, x, t):
"""从x_t预测t时刻的噪声,重构图像x_0"""
t = torch.tensor([t])
coeff = model.betas[t] / model.one_minus_alpha_bar_sqrt[t]
eps_theta = model(x, t) # 预测第t步噪声图像的噪声eps
mean = (1 / (1 - model.betas[t].sqrt()) * (x - (coeff * eps_theta))) # 将含噪图像x减去噪声eps得到均值mean
z = torch.rand_like(x) # 再随机采样作为方差sigma
sigma_t = model.betas[t].sqrt() # 方差的权重weight
sample = mean + sigma_t * z
return sample
def train():
seed = 0
batch_size = 128
num_epoch = 4000
print('Train model...')
"""导入数据集dataset和dataloader"""
s_curve, _ = make_s_curve(10 ** 4, noise=0.1) # 生成S曲线散点数据集(高斯噪声0.1)
s_curve = s_curve[:, [0, 2]] / 10.0 # 包含10000个点的坐标
dataset = torch.Tensor(s_curve).float()
dataloader = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)
plt.rc('text', color='blue')
"""实例化DDPM模型"""
model = DDPM() # 输出维度是2,输入是x和step
"""实例化optimizer优化器,但不能实例化loss,因为要一并输入batch_size个x_0"""
optimizer = torch.optim.Adam(model.parameters())
x_seq = None
for t in range(num_epoch):
for idx, batch_x in enumerate(dataloader): # dataloader这里只能得到batch_size个x_0,不能得到y噪声标签,因为那是在loss里生成的
loss = diffusion_loss_fun(model, batch_x)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 这里遍历model每个参数用EMA
if t % 100 == 0: # 每训练100个epoch,就打印一次loss,并进行一次推理预测p_sample_loop
print(f"epoch:{t}, loss:{loss}")
# 进行一次推理预测p_sample_loop,预测100个图像的序列x_seq的
x_seq = p_sample_loop(model, dataset.shape) # 共100个元素
fig, axs = plt.subplots(1, 10, figsize=(28, 3)) # 对100个元素进行推理生成
for i in range(1, 11):
cur_x = x_seq[i * 10].detach() # 间隔10,共取10个元素进行可视化
axs[i - 1].scatter(cur_x[:, 0], cur_x[:, 1], color='red', edgecolor='white')
axs[i - 1].set_axis_off()
axs[i - 1].set_title('$q(\mathbf{x}_{' + str(i * 10) + '})$')
plt.savefig(f'./logs/res{t}.png')
plt.close(fig) # 手动关闭图形窗口
torch.save(x_seq, './logs/final_x_seq.pt') # 保存为 PyTorch Tensor 格式
def Generating_gif():
"""正向过程(加噪声)gif生成"""
s_curve, _ = make_s_curve(10 ** 4, noise=0.1) # 生成S曲线散点数据集(高斯噪声0.1)
s_curve = s_curve[:, [0, 2]] / 10.0 # 包含10000个点的坐标
dataset = torch.Tensor(s_curve).float()
ddpm = DDPM()
imgs = []
for i in range(100):
plt.clf()
q_i = ddpm.q_x(dataset, torch.tensor([i]))
plt.scatter(q_i[:, 0], q_i[:, 1], color='red', edgecolors='white', s=5)
plt.axis('off')
img_buf = io.BytesIO()
plt.savefig(img_buf, format('png'))
img = Image.open(img_buf)
imgs.append(img)
"""正向过程(加噪声)gif生成"""
reverse = []
for i in range(100):
plt.clf()
x_seq = torch.load('./logs/final_x_seq.pt') # 拿到训练阶段生成的x_seq
cur_x = x_seq[i].detch()
plt.scatter(cur_x[:, 0], cur_x[:, 1], color='red', edgecolors='white', s=5)
plt.axis('off')
img_buf = io.BytesIO()
plt.savefig(img_buf, format('png'))
img = Image.open(img_buf)
reverse.append(img)
"""合并加噪和去噪"""
imgs = imgs + reverse
imgs[0].save("./logs/diffusion.gif", format='GIF', append_imges=imgs, save_all=True, duration=100, loop=0)
if __name__ == "__main__":
train()
Generating_gif()
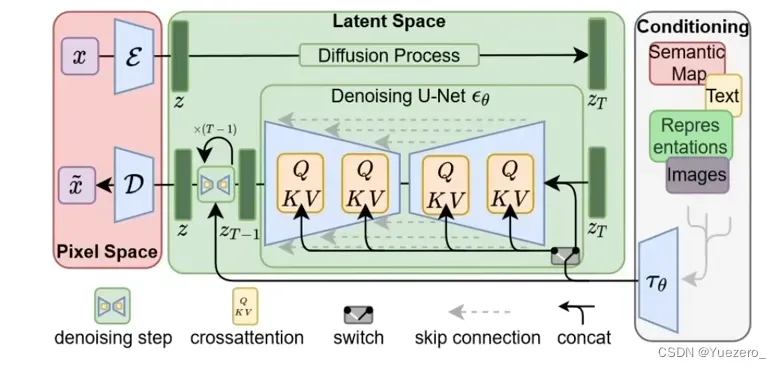
2.2 Stable Diffusion
扩散模型最大的问题是它的时间成本和经济成本都极其“昂贵”。Stable Diffusion的出现就是为了解决上述问题。如果我们想要生成一张 1024 × 1024 尺寸的图像,U-Net 会使用 1024 × 1024 尺寸的噪声,然后从中生成图像。这里做一步扩散的计算量就很大,更别说要循环迭代多次直到100%。一个解决方法是将大图片拆分为若干小分辨率的图片进行训练,然后再使用一个额外的神经网络来产生更大分辨率的图像(超分辨率扩散)。
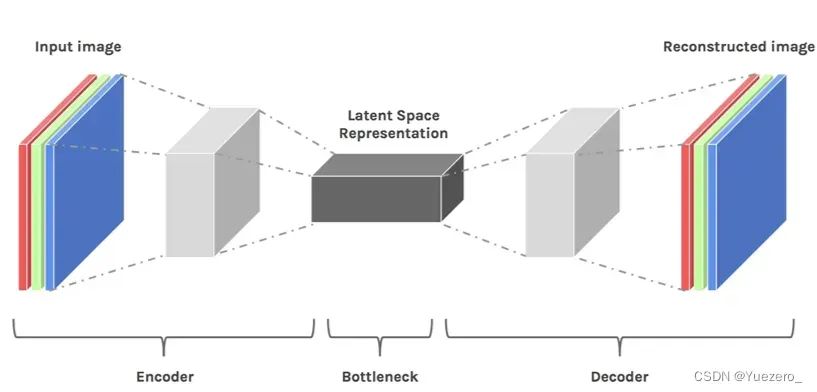
假设我们像通过全连接的卷积神经网络训练一个图像分类模型。当我们说模型在学习时,我们的意思是它在学习神经网络每一层的特定属性,比如边缘、角度、形状等……每当模型使用数据(已经存在的图像)学习时,都会将图像的尺寸先减小再恢复到原始尺寸。最后,模型使用解码器从压缩数据中重建图像,同时学习之前的所有相关信息。因此,空间变小,以便提取和保留最重要的属性。这就是潜在空间适用于扩散模型的原因。
任何生成性学习方法都有两个主要阶段:感知压缩和语义压缩。
感知压缩
在感知压缩学习阶段,学习方法必须去除高频细节将数据封装到抽象表示中。此步骤对构建一个稳定、鲁棒的环境表示是必要的。GAN 擅长感知压缩,通过将高维冗余数据从像素空间投影到潜在空间的超空间来实现这一点。潜在空间中的潜在向量是原始像素图像的压缩形式,可以有效地代替原始图像。更具体地说,用自动编码器 (Auto Encoder) 结构捕获感知压缩。 自动编码器中的编码器将高维数据投影到潜在空间,解码器从潜在空间恢复图像。
语义压缩
在学习的第二阶段,图像生成方法必须能够捕获数据中存在的语义结构。 这种概念和语义结构提供了图像中各种对象的上下文和相互关系的保存。 Transformer擅长捕捉文本和图像中的语义结构。 Transformer的泛化能力和扩散模型的细节保存能力相结合,提供了两全其美的方法,并提供了一种生成细粒度的高度细节图像的方法,同时保留图像中的语义结构。
自动编码器VAE
自动编码器 (VAE) 由两个主要部分组成:编码器和解码器。编码器会将图像转换为低维潜在表示(像素空间–>潜在空间),该表示将作为输入传递给U_Net。解码器做的事情刚好相反,将潜在表示转换回图像(潜在空间–>像素空间)。

文本编码器
文本编码器会将输入提示转换为 U-Net 可以理解的嵌入空间。一般是一个简单的基于Transformer的编码器,它将标记序列映射到潜在文本嵌入序列。高质量的提示(prompt)对输出质量直观重要,这就是为什么现在大家这么强调提示设计(prompt design)。提示设计就是要找到某些关键词或表达方式,让提示可以触发模型产生具有预期属性或效果的输出。
3 Consistency终结Diffusion
扩散模型依赖于迭代生成过程,这导致此类方法采样速度缓慢,进而限制了它们在实时应用中的潜力。
OpenAI 为了克服这个限制,提出了 Consistency Models,这是一类新的生成模型,无需对抗训练即可快速获得高质量样本。Consistency Models 支持快速 one-step 生成,同时仍然允许 few-step 采样,以权衡计算量和样本质量。它们还支持零样本(zero-shot)数据编辑,例如图像修复、着色和超分辨率,而无需针对这些任务进行具体训练。Consistency Models 可以用蒸馏预训练扩散模型的方式进行训练,也可以作为独立的生成模型进行训练。
Consistency Models 作为一种生成模型,核心设计思想是支持 single-step 生成,同时仍然允许迭代生成,支持零样本(zero-shot)数据编辑,权衡了样本质量与计算量。
首先 Consistency Models 建立在连续时间扩散模型中的概率流 (PF) 常微分方程 (ODE) 之上。如下图 所示,给定一个将数据平滑地转换为噪声的 PF ODE,Consistency Models 学会在任何时间步(time step)将任意点映射成轨迹的初始点以进行生成式建模。Consistency Models 一个显著的特性是自洽性(self-consistency):同一轨迹上的点会映射到相同的初始点。这也是模型被命名为 Consistency Models(一致性模型)的原因。
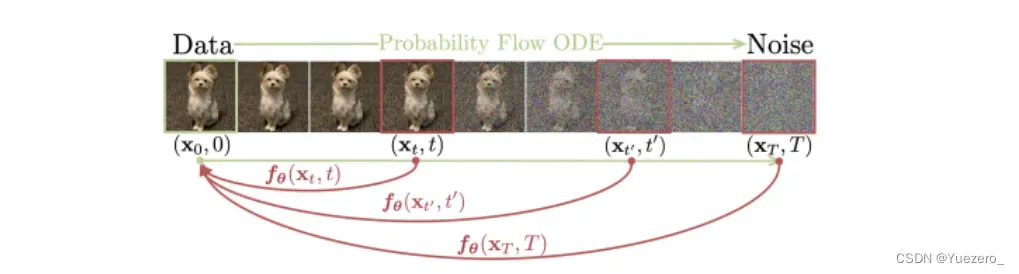
Consistency Models 允许通过仅使用 one network 评估转换随机噪声向量(ODE 轨迹的端点,例如图 1 中的 x_T)来生成数据样本(ODE 轨迹的初始点,例如图 1 中的 x_0)。更重要的是,通过在多个时间步链接 Consistency Models 模型的输出,该方法可以提高样本质量,并以更多计算为代价执行零样本数据编辑,类似于扩散模型的迭代优化。
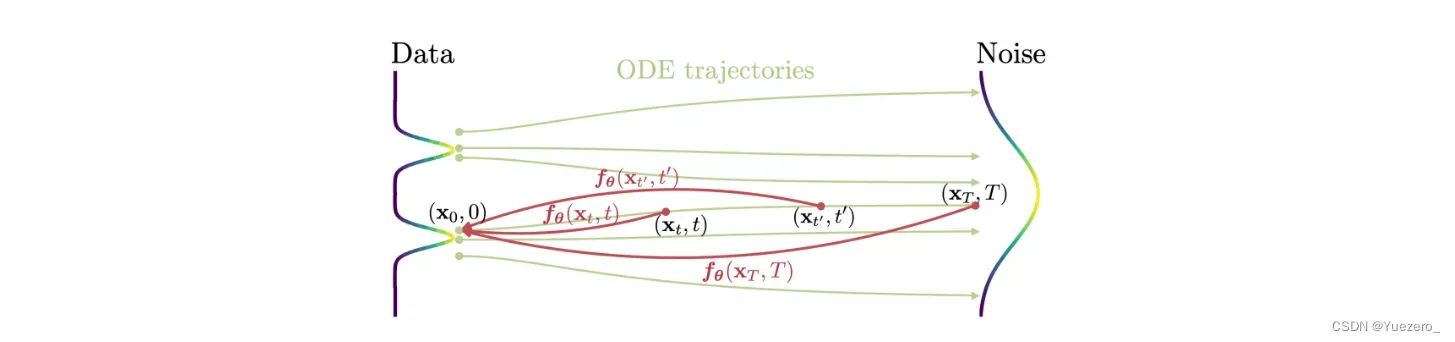
-
第一种方法依赖于使用数值 ODE 求解器和预训练扩散模型来生成 PF ODE 轨迹上的相邻点对。通过最小化这些点对的模型输出之间的差异,该研究有效地将扩散模型蒸馏为 Consistency Models,从而允许通过 one network 评估生成高质量样本。
-
第二种方法则是完全消除了对预训练扩散模型的依赖,可独立训练 Consistency Models。这种方法将 Consistency Models 定位为一类独立的生成模型。
值得注意的是,这两种训练方法都不需要对抗训练,并且都允许 Consistency Models 灵活采用神经网络架构。
文章出处登录后可见!