CycleGAN是一种很方便使用的用于进行图像风格转换的模型。它的一大优势就在于不需要成对的数据集就可以进行训练。比如我们只需要随便一大堆真人图像和随便另一大堆动漫图像,就可以训练出这两类风格互相转换的模型。
CycleGAN进行风格转换的原理是这样的:在CycleGAN模型中有两个生成器和两个判别器。如下图所示,生成器G能够实现X域到Y域的转换,判别器Dy可以判断输入图像是否是符合Y域的图像;生成器F能实现Y域到X域的转换,判别器Dx可以判断输入图像是否是符合X域的图像。
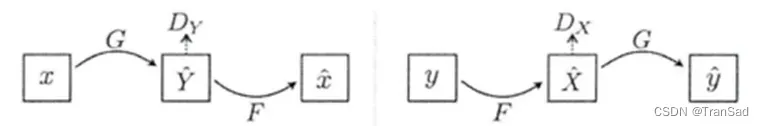
CycleGAN的关键思想就是使用循环一致性来保证生成器的输出和原图之间保持了内容上的相似性。“循环一致性”这一名词的具体解释为:给定两个不同风格域的图像x和y,图像x可以通过生成器GAB获得y,然后再通过GBA获得与A相同域的图像z,如果x和z保持一致,就相当于让图像进行了一个循环并且前后一致,这便是循环一致性。再说得通俗易懂些,就是输入图像先后经过模型中的两个生成器后,可以尽量回到本身。

CycleGAN能进行图像风格转换任务的核心就是循环一致性,为什么呢?假如说没有循环一致性,那么我们把任何一张不同的人脸送入生成器G,生成器G都只需要生成同一张卡通图像就可以骗过判别器,比如不管输入的是什么人脸图像,都生成同一张哆啦A梦的照片即可,因为它只要是个卡通图像就行。而有了
循环一致性的要求之后,我们还需要把生成结果再送入生成器F,希望结果能回到本身。这样一来单纯只用哆啦A梦的照片是无法反向生成原图的。
因此循环一致性迫使着生成模型“不得不”在生成结果中保留输入图像的内容,以便二次转换的时候能回到输入图像本身。
CycleGAN中的生成器
CycleGAN的生成器包括编码器、风格转换器以及解码器,这种编码器–解码器模型因其模型形状也被称为U-Net网络。和常见的先降采样到低纬度,再上采样到原始分辨率的编解码结构的网络相比,U-Net的区别是加入了跳跃层结构skip-connection,将编解码前后同样大小的特征图拼接在一起,这种方法可以一定程度上保留不同分辨率下像素级别的细节信息。相对于原始的编解码结构的网络,U-Net刻画细节的效果十分显著,如下图所示。
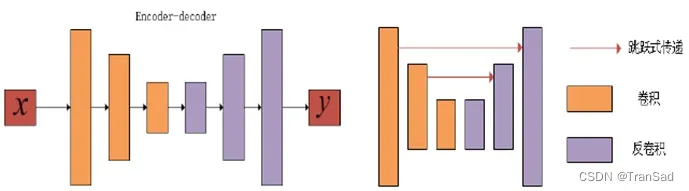
编解码网络结构与U-Net网络结构
编码器和中间部分的风格转换器使用了残差快结构,通过在神经网络传递的同时添加一条直连路径的方式,就可以确保梯度有效传递,改善网络的性能。
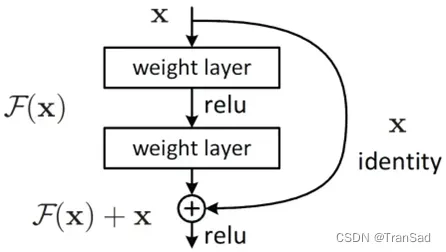
ResNet残差块
在之前的文章写到过,残差网络之所以可以避免梯度消失,是因为假如在没有残差边的时候,如果网络层数很深的话,要想更新底层的(靠近输入数据部分)的网络权重,应首先对其求梯度,根据链式法则需要一直向前累乘,只要其中的任何一个因数过小就会导致求出来的梯度很小很小,这个小梯度就算乘以再大的学习率也是无济于事;而残差边的出现,使得求梯度可以直接经过“高速公路”直达想要求梯度的对象,此时不管通过链式法则走正常路线得到的梯度多么小,两条路线相加的结果都不会小,就可以很有效地进行梯度更新。
具体定义U-Net网络时,设置输入图像通道数为3,尺寸为256*256大小,第一次卷积时采用64个大小为7*7,步长为1的卷积核来扩大通道数,激活函数选取ReLU。在接下来降采样阶段,采用3*3大小、步长为2的卷积核,随着每一次降采样,通道数逐渐扩大为原来的二倍。进入转换器阶段,采用6个定义好的残差块,此时特征图的尺寸与通道高数都不变化。在解码器阶段,使用上采样来扩大图像的尺寸,同时使用逐渐减少的卷积核来减少通道数,使其逐渐缩小为原来的一半,使用AdaLIN进行归一化。
这样一来,构建出的生成器首先使用残差网络来降采样输入的图像,然后使用反卷积来进行上采样,在整个生成器的处理图像过程中贯穿使用AdaLIN自适应归一化方式,成功提高了每一个像素的感知域,实现输入像素的跳跃式传输,保护了信息传递的完整性。
CycleGAN中的判别器
相比于生成器,CycleGAN的判别器结构功能十分简单,它仅仅用于判断输入图像是否是某一特定域的图像。如下图所示,判别器首先使用四层卷积与激活函数对图像进行特征提取和处理,最后再经过输出通道数为1的卷积得到一个Patch的输出以实现“判别”的目的。
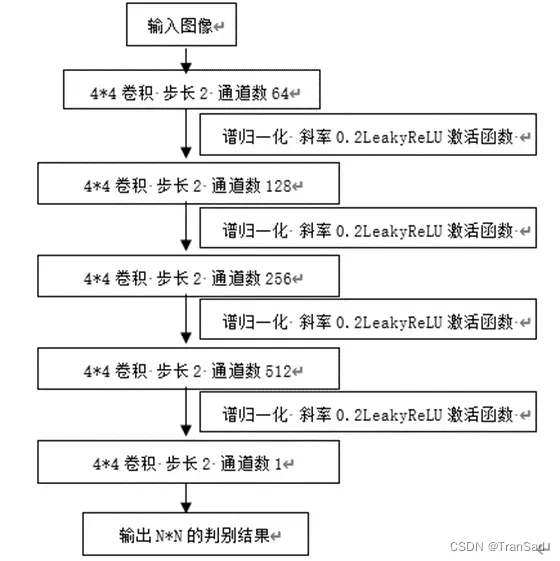
判别器网络结构
传统的GAN网络判别器通常是在最后使用sigmoid函数将输出变为0或1的单个值,这个值就是判别器对输入图像的一个判断和评价,1表示真,0表示假。而CycleGAN中的判别器采用了一个叫做PatchGAN的思想,所谓Patch是指图像经过一系列卷积层之后,并不会直接输入到全连接层或者一个简单的激活函数中,而是在最后使用一个通道数为1的卷积将特征图映射为N*N矩阵,这个矩阵的作用就等价于传统的单一评价值。相比于只输出一个值的判别方式,输出N*N矩阵的好处在于矩阵中每个点都代表原始图像中的一块小区域评价值,每一小块区域这也就是Patch含义。原来用一个值衡量整幅图,现在使用N*N的矩阵来评价整幅图,此时标签也会设置成N*N的格式,这样就可以进行损失计算了。PatchGAN的优势在于使用了更多的“感受野”,可以综合考虑更多的区域。
损失函数
CycleGAN的损失函数分为三个部分:对抗损失、循环一致性损失以及Identity损失。
对抗损失:
对抗损失就是传统GAN网络的中生成器和判别器之间的“博弈”损失。生成器希望能够生成出骗过判别器的图像,判别器希望能够正确识别图像到底是生成器生成的假图像还是非生成的真图像。在CycleGAN中,因为有两个生成器和两个判别器,因此有两个对抗损失,分别是生成器G和判别器Dy的对抗损失,以及生成器F和判别器Dx的对抗损失。
对于生成器G和判别器Dy这一对来说,应构建对抗损失函数为:
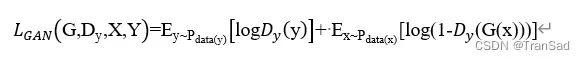
在上面公式中,G(x)是生成器G生成的Y域的虚假图像,而我们的判别器Dy目的就是判断图像是真实图像还是生成的虚假图像。因此,生成器G的目的是使损失函数值最小化,而判别器Dy的目的则是最大化损失函数的值,具体公式表示如下:
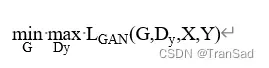
同样,构建生成器F和判别器Dx对应的对抗损失函数和对应目标为:
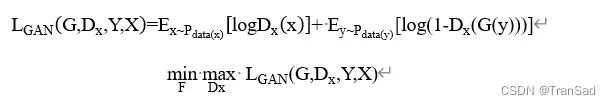
循环一致性损失:
CycleGAN的训练过程为:首先从域X中取出一组图像,再从域Y中取出另一组图像,以此训练生成器G:X->Y,得到生成图像G(x)后,再经过生成器F:Y->X得到F(G(x));同理,从Y域到X域的转换关系为G(F(y))。为了满足x->G(x)->F(G(x))≈x且y->F(y)->G(F(y))≈y,循环一致性损失可以表示如下:
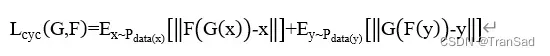
Identity损失:
最后,在CycleGAN中,还有一个损失函数非常容易忽略,那就是Identity损失。这一损失的意义是指假如将Y域的图像送入生成器G,那么得到的应尽可能还是它本身,而不再做其他转换。Identity Loss的作用主要是限制生成器G不会自主的修改输入图像的颜色,同时保证生成器G值生成Y域图像的功能。Identity损失表示如下:
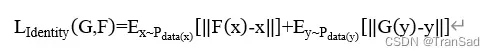
综上,整个CycleGAN的损失函数是由对抗损失、循环一致性损失以及Identity损失总和得到的,总损失函数表示如下:
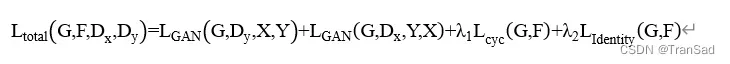
优化目标表示为:
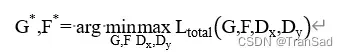
小结:
这篇文章梳理了经典的风格转换模型CycleGAN的基本原理以及损失函数,感觉CycleGAN还是比较巧妙的,比如通过循环一致性的思想来控制内容的保留等。
文章出处登录后可见!