知识要点
- Keras 是一个用 Python 编写的高级神经网络 API
- 数据的开方: np.sqrt(784) # 28
- 代码运行调整到 CPU 或者 GPU:
import tensorflow as tf
cpu=tf.config.list_physical_devices("CPU")
tf.config.set_visible_devices(cpu)- 模型显示: model.summary()
创建模型:
- 模型创建: model = Sequential()
- 添加卷积层: model.add(Dense(32, activation=’relu’, input_dim=100)) # 第一层需要 input_dim
- 添加dropout: model.add(Dropout(0.2))
- 添加第二次网络: model.add(Dense(512, activation=’relu’)) # 除了first, 其他层不要输入shape
- 添加输出层: model.add(Dense(num_classes, activation=’softmax’)) # last 通常使用softmax
- TensorFlow 中,使用 model.compile 方法来选择优化器和损失函数:
-
optimizer: 优化器: 主要有: tf.train.AdamOptimizer , tf.train.RMSPropOptimizer , or tf.train.GradientDescentOptimizer .
-
loss: 损失函数: 主要有:mean square error (mse, 回归), categorical_crossentropy (多分类) , and binary_crossentropy (二分类).
-
metrics: 算法的评估标准, 一般分类用accuracy.
-
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])- model.fit(x_train, y_train, batch_size = 64, epochs = 20, validation_data = (x_test, y_test)) # 模型训练
模型评估:
- score = model.evaluate(x_test, y_test, verbose=0) 两个返回值: [ 损失率 , 准确率 ]
大数据集处理:
- 把大数据集数据变成dataset: dataset = tf.data.Dataset.from_tensor_slices((data, labels))
- 指定每批数据大小: dataset = dataset.batch(32).repeat()
- dataset 数据训练: model.fit(dataset, epochs=10, steps_per_epoch=30)
- 保存模型: model.save(‘my_model.h5’)
- 加载模型: model = tf.keras.models.load_model(‘my_model.h5’)
1 Keras 基础
1.1 简介
Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow , CNTK 或者 Theano 作为后端运行。在Keras的官方github上写着”Deep Learning for humans”, 主要是因为它能简单快速的创建神经网络,而不需要像Tensorflow一样考虑很多中间过程.
Keras说白了就是一个壳子, 需要结合TensorFlow, CNTK或者Theano等后端框架来运行.基于这些特点, Keras的入门非常简单. TensorFlow已经把keras集成了.
中文官方文档: 主页 – Keras 中文文档
1.2 Keras 使用
1.2.1 创建模型
- 最简单的使用方式是使用Keras Sequential, 中文叫做顺序模型, 可以用来表示多个网络层的线性堆叠. 使用的时候可以通过讲网络层实例的列表传递给Sequential, 比如:
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential([
Dense(32, input_shape=(784,)),
Activation('relu'),
Dense(10),
Activation('softmax'),
])
model.summary() 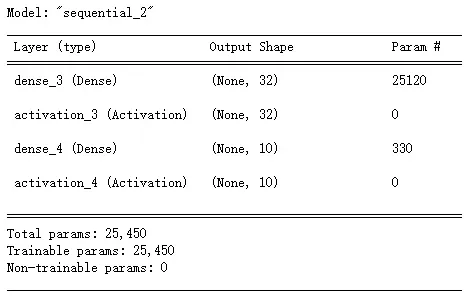
- 也可以简单的使用.add()方法将各层添加到模型中:
model = Sequential()
model.add(Dense(32, input_dim=784))
model.add(Activation('relu'))
model.summary()
1.2.2 模型参数设置
对于输入层,需要指定输入数据的尺寸,通过Dense对象中的input_shape属性.注意无需写batch的大小. input_shape=(784,) 等价于我们在神经网络中定义的shape为(None, 784)的Tensor.
模型创建成功之后,需要进行编译.使用.compile()方法对创建的模型进行编译.compile()方法主要需要指定一下几个参数:
-
优化器 optimizer: 可以是Keras定义好的优化器的字符串名字,比如’rmsprop’也可以是Optimizer类的实例对象.常见的优化器有: SGD, RMSprop, Adagrad, Adadelta等.
-
损失函数 loss: 模型视图最小化的目标函数, 它可以是现有损失函数的字符串形式, 比如:categorical_crossentropy, 也可以是一个目标函数.
-
评估标准 metrics. 评估算法性能的衡量指标.对于分类问题, 建议设置为metrics = [‘accuracy’].评估标准可以是现有的标准的字符串标识符,也可以是自定义的评估标准函数。
以下为compile的常见写法:
# 多分类问题
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 二分类问题
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# 均方误差回归问题
model.compile(optimizer='rmsprop',
loss='mse')
# 自定义评估标准函数
import keras.backend as K
def mean_pred(y_true, y_pred):
return K.mean(y_pred)
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy', mean_pred])
model.summary()
- 训练模型: 使用.fit()方法,将训练数据,训练次数(epoch), 批次尺寸(batch_size)传递给fit()方法.
# 训练模型,以 32 个样本为一个 batch 进行迭代
model.fit(data, labels, epochs=10, batch_size=32)1.3 Keras函数式API
Sequential 顺序模型封装了太多东西,不够灵活,如果你想定义复杂模型可以使用Keras的函数式API.
以下是一个全连接网络的例子: # 手写数字识别
from keras.layers import Input, Dense
from keras.models import Model
from keras.datasets import mnist
import tensorflow as tf
# 导入手写数字数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 对数据进行初步处理
x_train = x_train.reshape(60000, 784)
x_train = x_train.astype('float32')
x_train /= 255
# 将标记结果转化为独热编码
y_train = tf.keras.utils.to_categorical(y_train, num_classes=10)
# 这部分返回一个张量
inputs = Input(shape=(784))
# 层的实例是可调用的,它以张量为参数,并且返回一个张量
output_1 = Dense(64, activation='relu')(inputs)
output_2 = Dense(64, activation='relu')(output_1)
predictions = Dense(10, activation='softmax')(output_2)
# 这部分创建了一个包含输入层和三个全连接层的模型
model = Model(inputs=inputs, outputs=predictions)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train) # 开始训练这个例子能够帮助我们进行一些简单的理解。
-
网络层的实例是可调用的,它以张量为参数,并且返回一个张量
-
输入和输出均为张量,它们都可以用来定义一个模型 (Model)
-
这样的模型同 Keras 的 Sequential 模型一样,都可以被训练.
2. TensorFlow中使用Keras
keras集成在tf.keras中.
2.1 创建模型
创建一个简单的模型,使用 tf.keras.sequential.
import tensorflow as tf
import tensorflow.keras.layers as layers
model = tf.keras.Sequential()
# 创建一层有64个神经元的网络:
model.add(layers.Dense(64, activation='relu'))
# 添加另一层网络:
model.add(layers.Dense(64, activation='relu'))
# 输出层:
model.add(layers.Dense(10, activation='softmax'))2.2 配置layers
layers 包含以下三组重要参数:
-
activation: 激活函数, ‘relu’, ‘sigmoid’, ‘tanh’.
-
kernel_initializer 和 bias_initializer: 权重和偏差的初始化器. Glorot uniform是默认的初始化器.一般不用改.
-
kernel_regularizer 和 bias_regularizer : 权重和偏差的正则化: L1, L2.
以下是配置模型的例子:
import tensorflow.keras.layers as layers
# 激活函数为sigmoid:
layers.Dense(64, activation='sigmoid')
# Or:
layers.Dense(64, activation=tf.sigmoid)
# 权重加了L1正则:
layers.Dense(64, kernel_regularizer=tf.keras.regularizers.l1(0.01))
# 给偏差加了L2正则
layers.Dense(64, bias_regularizer=tf.keras.regularizers.l2(0.01))
# 随机正交矩阵初始化器:
layers.Dense(64, kernel_initializer='orthogonal')
# 偏差加了常数初始化器
layers.Dense(64, bias_initializer=tf.keras.initializers.constant(2.0))2.3 训练和评估
2.3.1 配置模型
使用compile配置模型, 主要有以下几组重要参数.
-
optimizer: 优化器: 主要有: tf.train.AdamOptimizer , tf.train.RMSPropOptimizer , or tf.train.GradientDescentOptimizer .
-
loss: 损失函数: 主要有:mean square error (mse, 回归), categorical_crossentropy (多分类) , and binary_crossentropy (二分类).
-
metrics: 算法的评估标准, 一般分类用accuracy.
以下是compile的 实例:
# 配置均方误差的回归.
model.compile(optimizer = tf.train.AdamOptimizer(0.01),
loss = 'mse', # mean squared error
metrics = ['mae']) # mean absolute error
# 配置多分类的模型.
model.compile(optimizer=tf.train.RMSPropOptimizer(0.01),
loss=tf.keras.losses.categorical_crossentropy,
metrics=[tf.keras.metrics.categorical_accuracy])2.3.2 训练
使用model的fit方法进行训练, 主要有以下参数:
-
epochs: 训练次数
-
batch_size: 每批数据多少
-
validation_data: 测试数据
对于小数量级的数据,可以直接把训练数据传入fit.
import numpy as np
data = np.random.random((1000, 32))
labels = random_one_hot_labels((1000, 10))
val_data = np.random.random((100, 32))
val_labels = random_one_hot_labels((100, 10))
model.fit(data, labels, epochs=10, batch_size=32,
validation_data=(val_data, val_labels))对于大数量级的训练数据,使用tensorflow中dataset.
# 把数据变成dataset
dataset = tf.data.Dataset.from_tensor_slices((data, labels))
# 指定一批数据是32, 并且可以无限重复
dataset = dataset.batch(32).repeat()
val_dataset = tf.data.Dataset.from_tensor_slices((val_data, val_labels))
val_dataset = val_dataset.batch(32).repeat()
# 别忘了steps_per_epoch, 表示执行完全部数据的steps
model.fit(dataset, epochs=10, steps_per_epoch=30)
model.fit(dataset, epochs=10, steps_per_epoch=30,
validation_data=val_dataset,
validation_steps=3)2.3.3 评估和预测
使用 tf.keras.Model.evaluate and tf.keras.Model.predict进行评估和预测. 评估会打印算法的损失和得分.
data = np.random.random((1000, 32))
labels = random_one_hot_labels((1000, 10))
# 普通numpy数据
model.evaluate(data, labels, batch_size=32)
# tensorflow dataset数据
model.evaluate(dataset, steps=30)预测:
result = model.predict(data, batch_size=32)
print(result.shape)2.4 使用函数式API
函数式API, 主要是需要自己把各个组件的对象定义出来, 并且手动传递.
inputs = tf.keras.Input(shape=(32,)) # 返回placeholder
# A layer instance is callable on a tensor, and returns a tensor.
x = layers.Dense(64, activation='relu')(inputs)
x = layers.Dense(64, activation='relu')(x)
predictions = layers.Dense(10, activation='softmax')(x)
model = tf.keras.Model(inputs=inputs, outputs=predictions)
# The compile step specifies the training configuration.
model.compile(optimizer=tf.train.RMSPropOptimizer(0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
# Trains for 5 epochs
model.fit(data, labels, batch_size=32, epochs=5)2.5 保存和恢复
- 使用model.save把整个模型保存为HDF5文件
model.save('my_model.h5')- 恢复使用tf.keras.models.load_model即可.
model = tf.keras.models.load_model('my_model.h5')注意: 如果使用的tensorflow的optimizer, 那么保存的model中没有model配置信息, 恢复以后需要重新配置.推荐用keras的optimizer.
文章出处登录后可见!