把近几年有关图像压缩的CVPR论文进行一个简单的总结,个人总结,大佬绕道

1、CVPR2022
1.1 ELIC:Efficient learned image compression with unevenly grouped space-channel contextual adaptive coding
(具有不均匀分组的空间通道上下文自适应编码的高效学习图像压缩)(无代码)
1.1.1 创新点
- 提出非均匀通道自适应编码(通道分组)
- 将所提出的非均匀分组模型与已有的上下文模型相结合,得到了一个空间-通道上下文自适应模型,在不影响运行速度的情况下提高了编码性能。
- 研究了变换网络的结构,并提出了一个高效的模型,ELIC,以达到最先进的速度-压缩率联合表现
1.1.2 实验结果
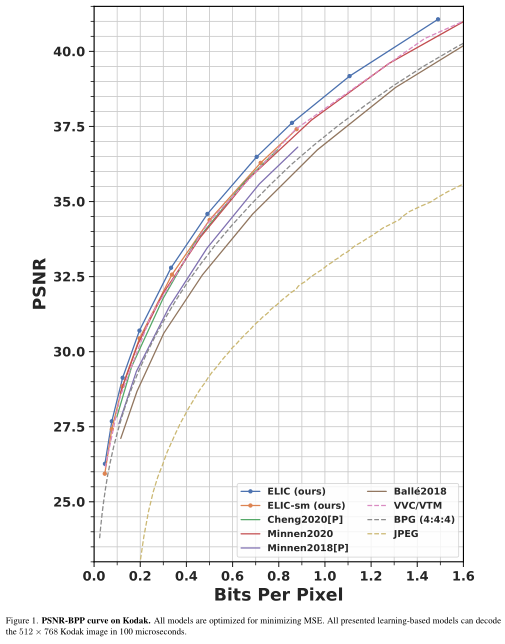
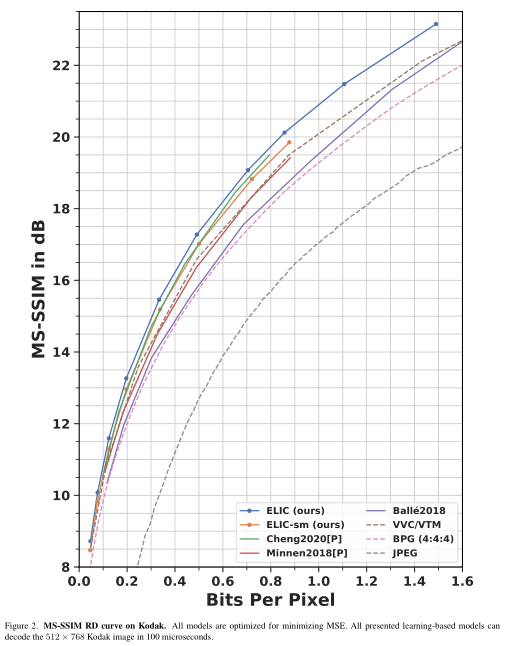
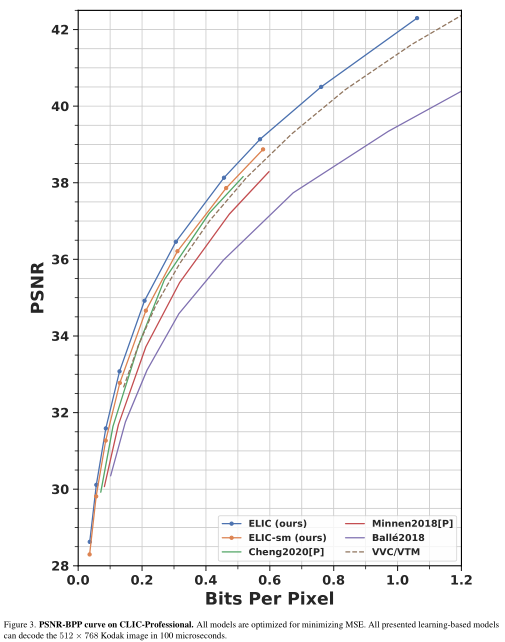
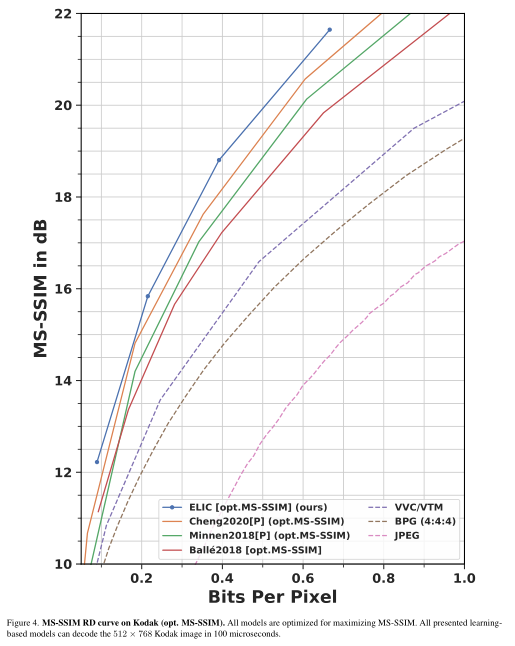
1.2 PO-ELIC: Perception-Oriented Efficient Learned Image Coding
(面向感知的高效学习图像编码)(无代码)
1.2.1 创新点
- 面向人类主观感知的高效深度学习图像编码
- 基于对抗训练技术改进了ELIC,它是最先进的LIC(深度图像压缩)模型之一
1.2.2 实验结果


1.3 Unified Multivariate Gaussian Mixture for Efficient Neural Image Compression
(用于高效神经图像压缩的统一多元高斯混合)(pytorch)
1.3.1 创新点
- 提出了一种多元高斯混合,其中要估计均值和协方差。
- 利用一种新的概率向量量化来有效地逼近均值,并且剩余的协方差被进一步引入统一的混合,并通过级联估计解决
- 不涉及上下文模型
1.3.2 实验结果
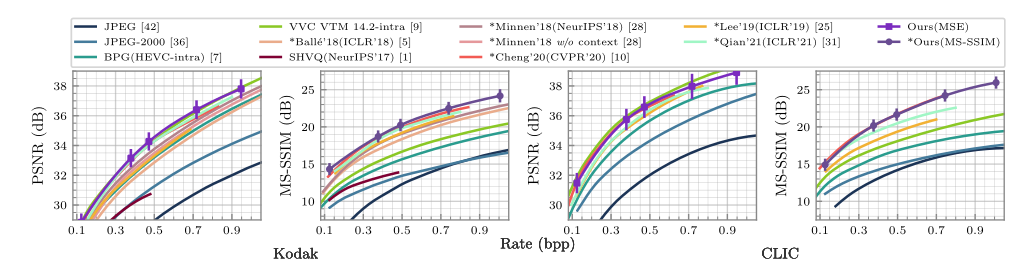
1.4 The Devil Is in the Details: Window-based Attention for Image Compression
(细节中的魔鬼:图像压缩的基于窗口的注意力)(pytorch)
1.4.1 创新点
- 引入了一种更直接有效的基于窗口的局部注意力块
- 提出了一种新颖的对称变换器(STF)框架,在下采样编码器和上采样解码器中具有绝对变换器块
1.4.2 实验结果
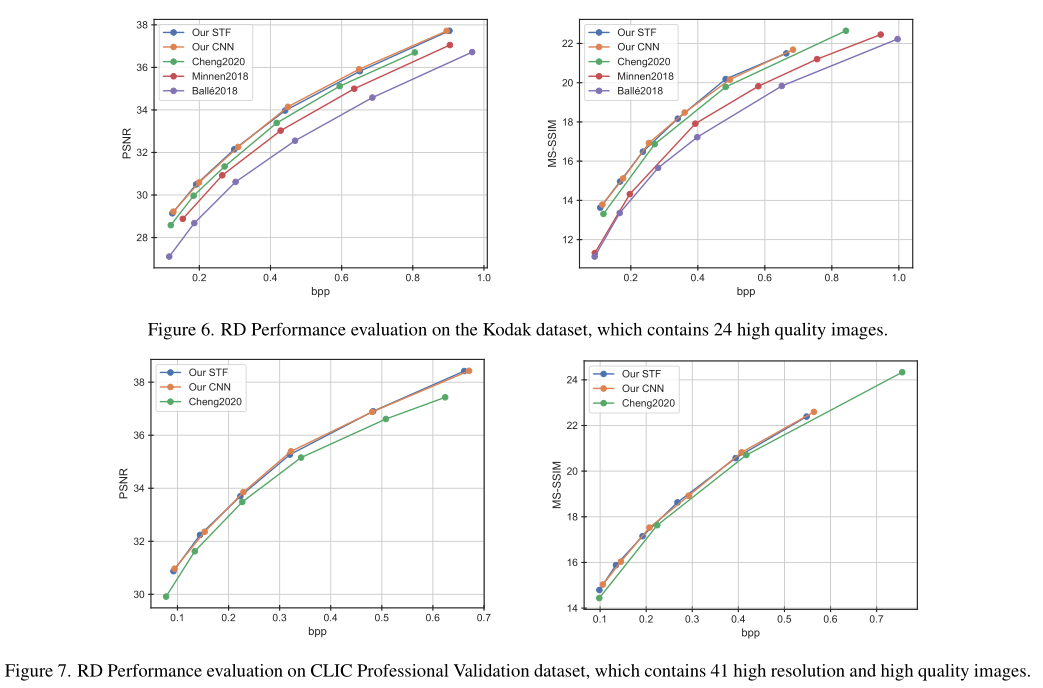
1.5 Neural Data-Dependent Transform for Learned Image Compression
(用于学习图像压缩的神经数据相关变换)(无代码)
1.5.1 创新点
- 使用了一个额外的模型来在解码器端生成变换参数。模型的存在使我们的模型能够学习更抽象的神经语法,有助于更紧凑地聚类图像的潜在表示,从而提升编码效率
1.5.2 实验结果
2、CVPR2021
2.1 Learning Scalable ℓ∞-constrained Near-lossless Image Compression via Joint Lossy Image and Residual Compression
(学习可扩展ℓ∞-基于联合有损图像和残差压缩的约束近无损图像压缩)(无代码)
2.1.1 创新点
- 提出了一种联合有损图像和残差用于学习的压缩框架近无损图像压缩。通过有损图像压缩获得原始图像的有损重建,并均匀量化相应的残差以满足给定的误差界限(假设误差界为零,即无损图像压缩)
- 提出一种基于正则化的近无损压缩系统(lossy+residual压缩)。由于残差量化,本文修正训练和测试时上下文不匹配导致的概率模型偏差问题。提出了无损近无损压缩系统,并根据原理设计了无损和近无损的bias 修正。
- 实质重点在于,如何在更低码率的情况下,传输后续增强所需要的高频信息,以及如何控制这部分高频信息的量化达到可伸缩编码的效果。
2.1.2 实验结果
2.1.2.1 近无损图像编解码器的压缩性能(bpsp)
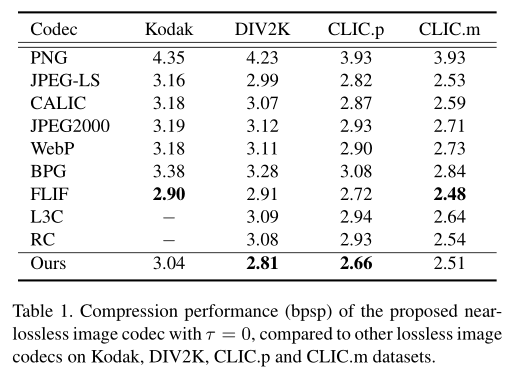
2.1.2.2 近无损图像编解码器(带偏差校正)的压缩性能(bpsp)
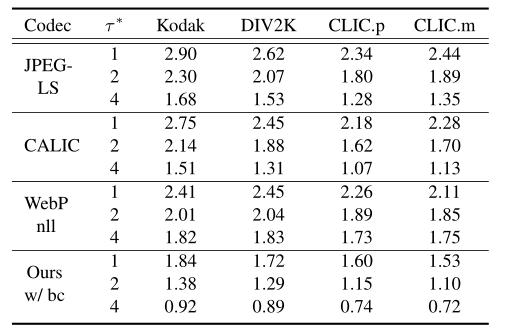
2.2 Attention-guided Image Compression by Deep Reconstruction of Compressive Sensed Saliency Skeleton
(通过深度重构压缩感知显著性骨架的注意力引导图像压缩)(无代码)
2.2.1 创新点
- 在传统压缩器的基础上加上了一个注意力引导的双层图像压缩系统。
- 本文中判断的像素关键点是边缘检测,收集重建后误差较大的点的交集,同时使用压缩感知的方式进行压缩信息。
2.2.2 实验结果
纵向和dut-TE数据集上竞争方法的ROI RD曲线
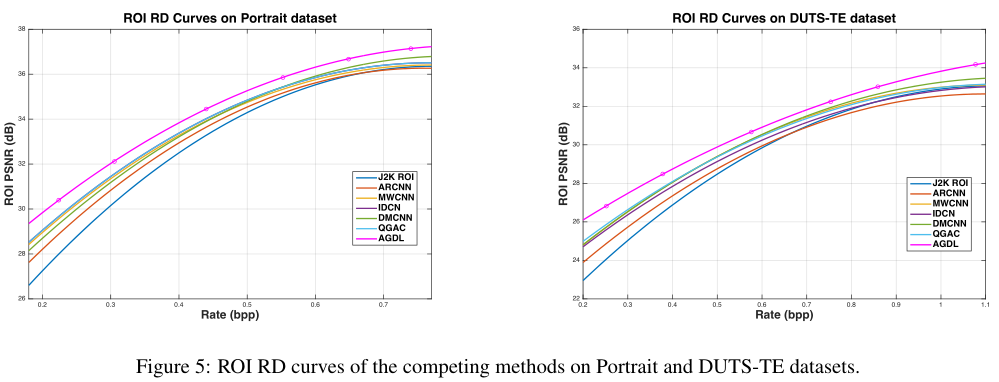
在图6中,我们可以看到AGDL压缩系统可以比最先进的QGAC方法和J2K ROI压缩更好地保留面部特征(注意更清晰的眼睛和头发,更清晰的肌肉轮廓)。对于一般对象,图7向我们展示了AGDL系统能够在CS约束的帮助下保留小结构,例如梅花鹿上的斑点和蝴蝶上的线条。此外,AGDL可以使动物毛发更加逼真,而QGAC则使毛发看起来过于光滑。

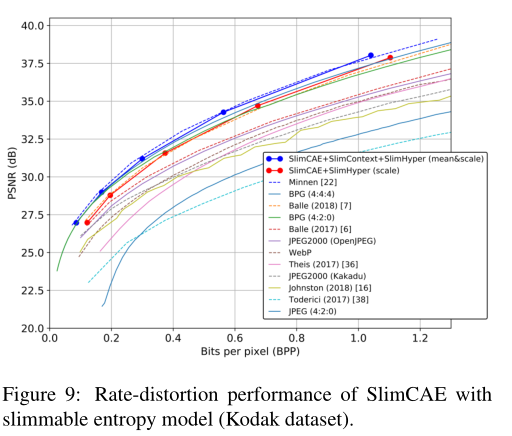
2.3 Slimmable Compressive Autoencoders for Practical Neural Image Compression
(用于实际神经图像的轻薄压缩自动编码器压缩)(tensorflow)
2.3.1 创新点
- 提出SlimCAEs,能够提供变化码率已经自适应复杂性,提出可精简的GDN层已经slimmable概率模型。每一个特征图都利用了之前的特征特的信息,同时给每一个特征图分配不同的lambda值。
2.3.2 实验结果
2.4 Checkerboard Context Model for Efficient Learned Image Compression
(用于高效学习图像压缩的棋盘上下文模型)(pytorch)
2.4.1 创新点
- 基于上下文的模型能够有效的减少隐变量的空间冗余,但其顺序扫描结构会极大的降低解码速度,影响并行化结果。
- 本文中使用了可以并行化的棋盘格上下文模型并改变解码顺序,从而在不破外性能的情况下,使解码速度加快40倍。
2.4.2 实验结果
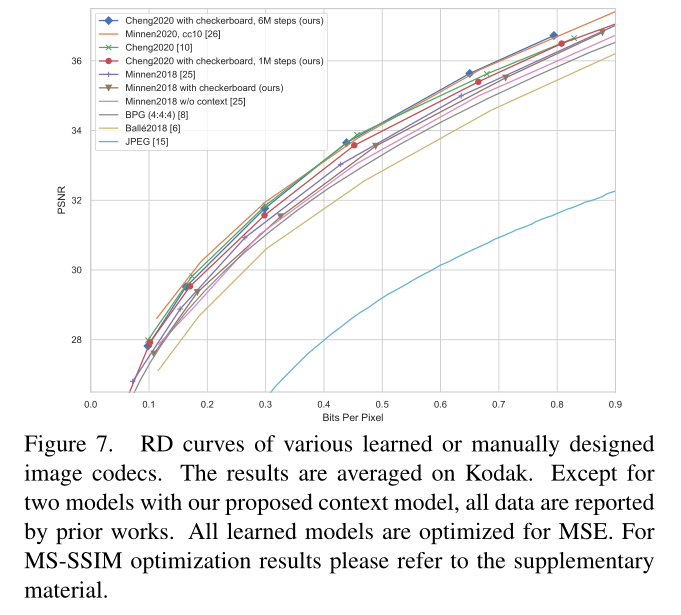
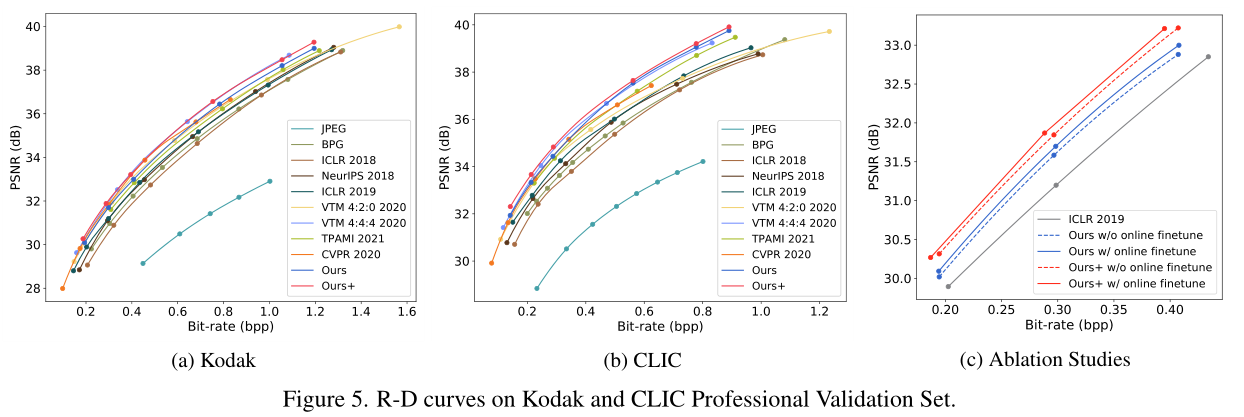
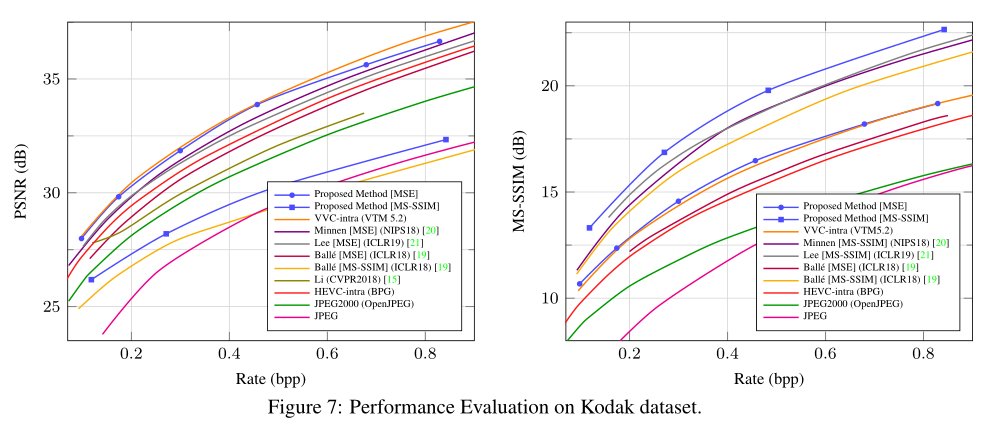
图7。各种学习或手动设计的图像编解码器的RD曲线。结果在柯达上平均。除了两个模型与我们提出的背景模型,所有的数据都是由先前的工作。所有学习到的模型都针对MSE进行了优化。
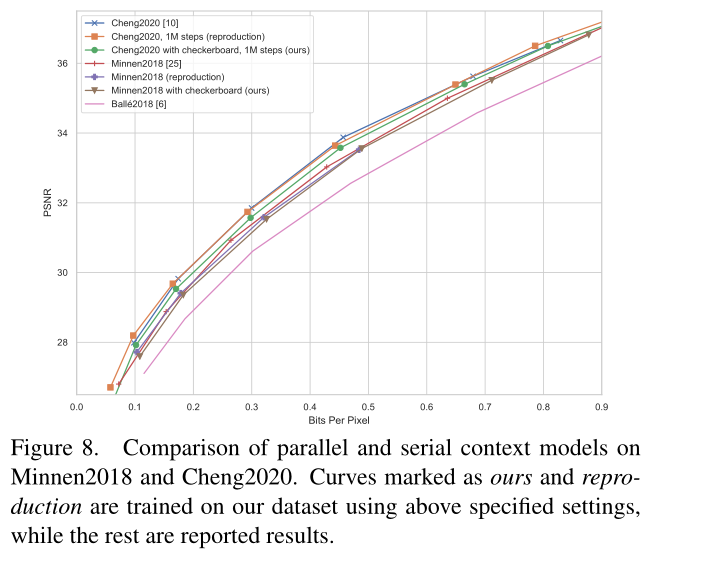
图8。并行和串行上下文模型在Minnen2018和Cheng2020上的比较。使用上面指定的设置在我们的数据集上训练标记为我们的和复制的曲线,而其余的是报告的结果。
2.5 Asymmetric Gained Deep Image Compression With Continuous Rate Adaptation
(具有连续速率自适应的非对称增益深度图像压缩)(pytorch)
2.5.1 创新点
- 神经网络压缩目前要么是不同码率点使用不同模型,要么是单一的大容量的网络模型缺乏码率可变的压缩。
- 引入增益单元实现码率自适应,引入指数插值将离散速率拓展到连续速率变化,引入非对称的高斯熵模型实现更加准确的熵估计。
2.5.2 实验结果
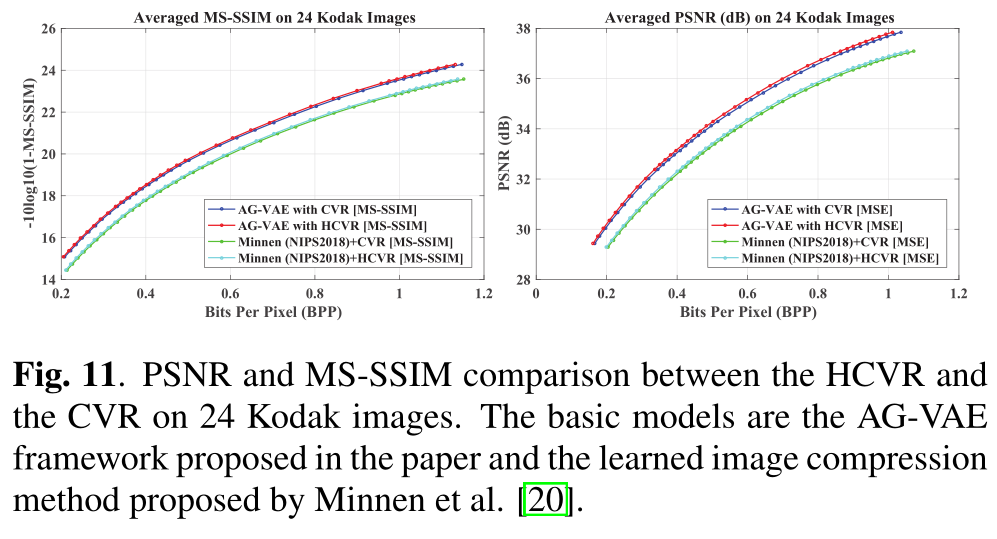
PSNR和MS-SSIM在24张柯达影像上对HCVR和CVR的比较。基本模型是论文中提出的AG-V AE框架和Minnen等人提出的学习图像压缩方法[20]
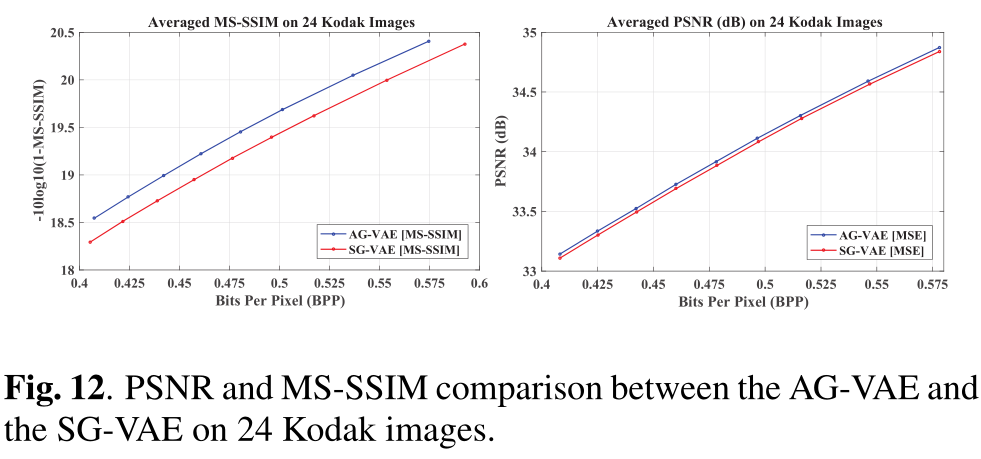
2.6 How to Exploit the Transferability of Learned Image Compression to Conventional Codecs
(如何利用学习图像压缩到传统编解码器的可转移性)(无代码)
2.6.1 创新点
- 卷积神经网络的计算量大,现有的codec计算量小,速度快。Codec结合GAN对压缩后的图像做一个滤波处理从而用较低的编码成本获取获得纹理信息丰富的结果。
- 在编码端提出一个过滤机制,作为learned codec。压缩后的图像,在图像分类领域表现良好。Filter与GAN匹配,使纹理区域被编码更短的相似部分代替。提升编码性能
2.6.2 实验结果
视觉比较,显示了我们的算法如何修改图像中的某些纹理,以模仿原始图像的细节,具有由生成性对抗网络控制的较低代码长度的内容。



3、CVPR2020
3.1 Learned Image Compression with Discretized Gaussian Mixture Likelihoods and Attention Modules
(基于离散高斯混合似然和注意模块的学习图像压缩)(tensorflow)
3.1.1 创新点
- 在joint基础上使用离散的高斯混合似然来对分布进行参数化,从而消除了剩余的冗余以实现准确的熵模型,从而直接导致所需的编码位数更少。
- 网络架构中采用了注意力模块的简化版本,注意模块可以使学习的模型更加关注复杂区域,从而以中等训练复杂度提高我们的编码性能。
3.1.2 实验结果
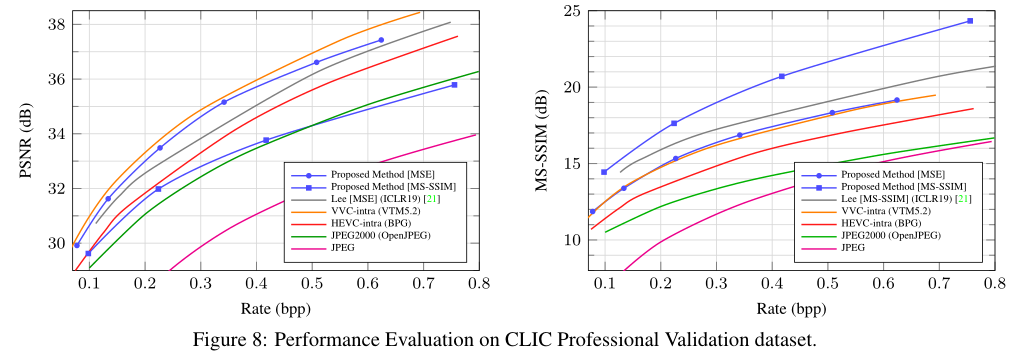
3.2 Learning Better Lossless Compression Using Lossy Compression
(使用有损压缩学习更好的无损压缩)(pytorch)
3.2.1 创新点
- 在有损压缩的基础上构建无损压缩系统。原始图像分解成BPG压缩后重建的有损图像和残差。对残差用网络预测概率分布,然后用熵编码的带残差编码。用来存储的是BPG编码和残差编码。
3.2.2 实验结果
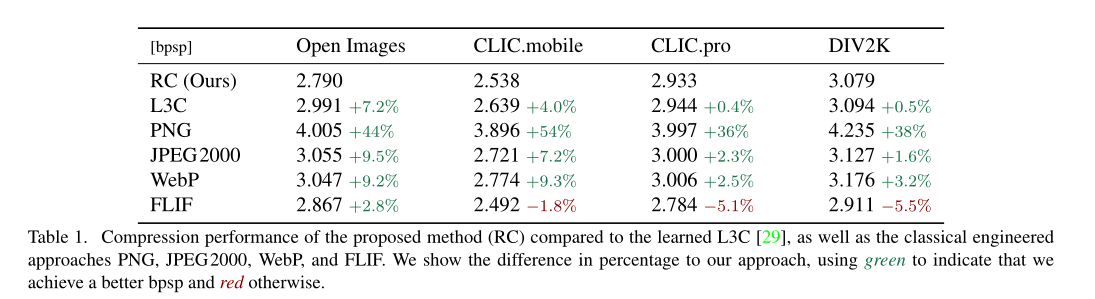
与L3C [29]以及传统的工程方法PNG、JPEG2000、WebP和FLIF相比,所提出的方法(RC)的压缩性能。我们用百分比表示我们方法的差异,用绿色表示我们实现了更好的bpsp,否则用红色表示
文章出处登录后可见!