递归的定义,递归算法,递归模型,递归栈,递归树
在数学和计算机科学中,递归是指在在一个过程或函数的定义时出现调用本过程或本函数的成分。
若在函数中调用函数自身或者在过程的子部分中调用子部分自身的内容,称之为直接递归,又称自递归。若不同的函数和子过程之间互相调用,则称之为间接递归,任何间接递归都可以等价地转换为直接递归(自递归),所以我们讨论递归一般只讨论直接递归。
如果一个递归过程或递归函数中,递归调用语句是最后一条执行语句,则称这种递归调用为尾递归。
一个有趣且经典的介绍递归的例子如下:
递归的定义:请查阅“递归的定义”。
这个例子不仅很好的体现了递归的特性,还同时满足自递归和尾递归,但如果在算法中使用该函数,从算法基本性质的角度而言就缺乏有限性。
递归算法(何时使用递归)
使用递归函数(过程)的算法就称为递归算法,递归算法中的递归函数(过程)需要满足算法的特性,所以递归算法中的递归函数需要满足以下几个条件:
1.递归过程中进行递归调用的次数必须是有限的。
2.必须有结束递归的条件来终止递归。
这两个条件保证了递归算法能够被结束,即递归算法的有限性。
同时从被求解问题的角度来看,需要解决的问题需要能够被“分解”成“规模较小的问题”,即可以转化为一个或多个子问题(规模较小的阶段)来求解。
我们只讨论自递归算法(所有递归算法都可以转化为自递归算法),可以发现子问题(阶段)的求解策略,求解环境与原问题基本类同,只是在具体的执行过程中因为某些与问题(阶段)相关的属性上的差异导致执行指令的不同(策略是相同的),从自递归的角度来看,递归思想就是将一个复杂的大问题逐渐转化成类同的“小问题”以及从“小问题”到“大问题”需要进行的操作。
以上即是递归使用在算法中的前提条件。
递归模型
递归模型是递归算法的抽象,它反映了一个递归问题的递归结构。
对于递归算法中的递归,递归的终止条件称之为递归出口,规模较大的问题(阶段)与规模较小的问题(阶段)之间的桥梁,即从“小问题”的解到“大问题”的解之间需要进行的操作(往往是数学公式)称为递归体。
一般地,一个递归模型由递归出口和递归体两部分,前者确定递归到何时结束,即指出明确的递归结束条件,后者确定递归求解时地递推关系。
递归出口的一般格式如下:
f(s1)=m1。
s1表示递归结束时的子问题(阶段),有些递归问题中可能有多个递归出口。递归体的格式如下:
f(s(n+1))=g(f(s(a1)),f(s(a2))·······,f(s(ak)),c1,c2······c(t))。
s(i)为递归过程中分解出来的子问题,c(i)为递归过程中连接规模较小的问题到规模较大的问题的桥梁,即可以直接(用非递归方法)解决的问题,f为递归函数,g为一个阶段的非递归求值函数。
递归算法的执行过程
从指令序列的角度来看,递归算法在执行递归函数时会不断地调用自身,但仅有调用自身的操作而不发生变化会让程序无休止地调用而陷入死循环,即从思想的角度来看规模较大的问题没有分解成规模较小的问题。
一个正确的递归程序虽然每次调用的是相同的子程序,但它的参量,输入数据等均有可能发生变化。在正常的情况下,随着调用的不断深入,必定会出现调用到某一层的函数时,不再执行递归调用而终止函数的执行,遇到递归出口便是这种情况。
递归调用是函数嵌套调用的一种特殊情况,即它是调用自身代码。也可以把每一次递归调用理解成调用自身代码的一个复制件。由于每次调用时,它的参量和局部变量均不相同,因而也就保证了各个复制件执行时的独立性。
系统为每一次调用开辟一组存储单元,用来存放本次调用的返回地址以及被中断的函数的参量值。这些单元以系统栈的形式存放,每调用一次进栈一次,当返回时执行出栈操作,把当前栈顶保留的值送回相应的参量中进行恢复,并按栈顶中的返回地址,从断点继续执行。
例 2.1
求n!的递归算法(保证输入的n为正整数)如下,分析执行fun(5)时系统栈的内部情况。
int fun(int n){
//递归出口
if (n==1) return(1);
//递归体
else return(fun(n-1)*n);
}
执行fun(5)时,进入else执行到fun(4),将fun(4)*5进栈:

因为没有返回值,所以一直调用进栈到fun(1)。

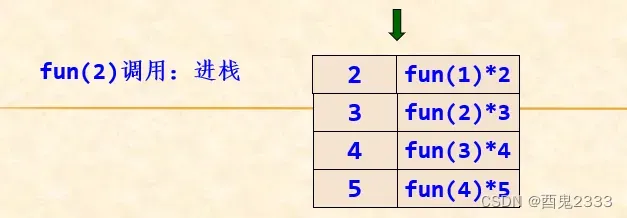
进行到fun(1)时,返回1,执行出栈,并将出栈的也就是栈顶的值恢复到fun(2)中进行运算:

直到栈为空时,执行完毕:
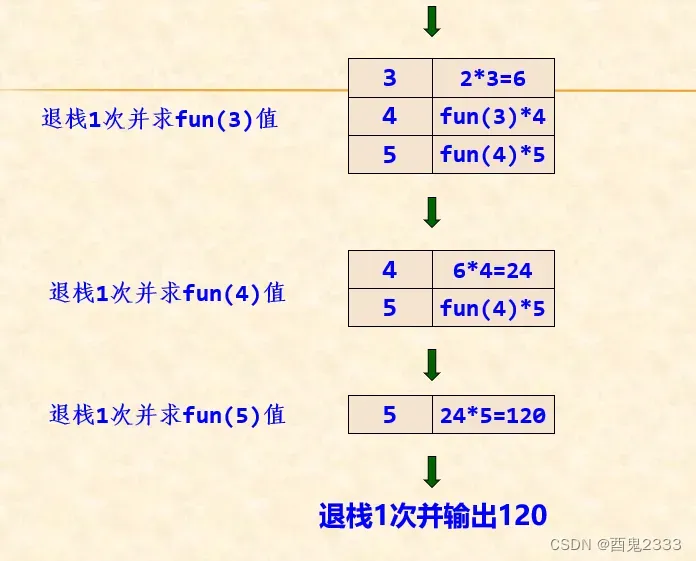
从以上过程可以得出:
1.递归是通过系统栈来实现的
2.每递归调用一次,就需进栈一次。最多的进栈元素个数称为递归深度,一般而言n越大,递归深度越深,开辟的栈空间也越大,如果进站元素过多则会出现栈溢出的情况。
3.每当遇到递归出口或完成本次执行时,需退栈一次,并将退栈的值恢复到原本的位置中,当全部执行完毕时,栈应为空。
程序执行和递归思想的角度结合来看,进栈的过程可以看作分解问题的过程,退栈恢复的过程看作问题求值的过程,能够得到以下的递归树:
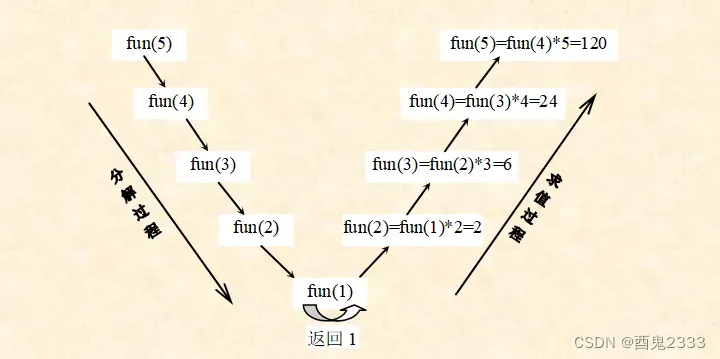
这颗递归树的结构比较简单,我们看另外一个复杂一点的问题。
例 2.3
斐波那契数列定义如下:
Fib(n)=1,n=1;
Fib(n)=1,n=2;
Fib(n)=Fib(n-1)+Fib(n-2),n>2。
对应的递归算法如下:
int Fib(int n){
if (n==1||n==2) return 1;
else return Fib(n-1)+Fib(n-2);
}
画出求Fib(5)的递归树以及递归工作栈的变化和求解过程。
Fib(5)分解成Fib(4)和Fib(3),Fib(4)分解成Fib(3)和Fib(2),Fib(3)分解成Fib(2)和Fib(1),Fib(2)和Fib(1)返回值退栈,恢复到Fib(3),再从Fib(2)和Fib(3)恢复到Fib(4),最后得到Fib(5)的值。
黑色的线表示分解过程,紫色的表现表示求解过程,求解Fib(5)的递归树如下:
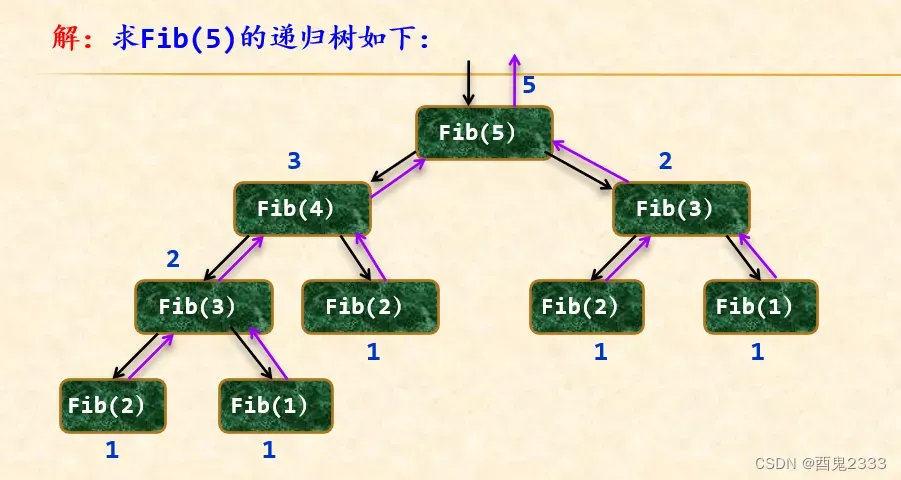
执行Fib(5)时递归工作栈的变化和求解过程:

可以发现例如Fib(3)在整个过程中是重复计算的,我们可以将Fib(3)的值存储下来,当递归到Fib(3)时直接返回存储的值,有关到后面动态规划的内容,这里就不多赘述了。
递归算法设计
递归与数学归纳法
递归算法分解问题的过程和和数学归纳法是非常类似的,虽然目的和性质不同(从实现上看,递归是算法和程序设计中为了简化代码,简化结构的一种实现技术,数学归纳法是数学问题证明的一种理论模型),我们可以将数学归纳法看作用递归设计算法的理论基础。
即我们用递归来设计算法,可以用数学归纳法作为理论基础来证明我们设计的递归算法是能够达成我们的目标的。
数学归纳法分为第一归纳原理和第二归纳原理。
第一数学归纳法
第一数学归纳法原理:
若{P(1),P(2),P(3),P(4)······}是命题序列且满足以下两个性质,则所有命题均为真:
1.P(1)为真。
2.任何命题均可以从它的前一个命题推导得出。
例如证明1到n的求和结果为n(n+1)/2。
1.当n=1时,左式=1,右式=1*(1+1)=1,左右两式相等,等式成立。
2.假设当n=k-1时等式成立,有1+2+······+(k-1)=(k-1)k/2。
当n=k时,根据n=k-1的结论,左式=1+2+…+k=1+2+…+(k-1)+k=(k-1)k/2+k=k(k+1)/2,满足n=k时的结论。
根据第一数学归纳法和结论1,2,问题即证。
第二数学归纳法
第二数学归纳法原理:
若{P(1),P(2),P(3),P(4),······}是命题序列且满足以下两个性质,则所有命题均为真:
1.P(1)为真。
2.任何命题均可以从它前面的所有命题推导得出。
条件2的意思是P(i)可以从前面所有命题假设{P(1),P(2),P(3),…,P(i-1)}推导得出。
例如,采用第二数学归纳法证明,任何含有n(n≥0)个不同结点的二又树,都可由它的中序序列和先序序列唯一地确定。
1.n等于0时,结论显然成立。
2.假设结点数小于n且所有结点值不同的任何二叉树,都可以由其先序序列和中序序列唯一地确定。
通过结点个数为n的二叉树的先序遍历结果,我们可以找到该二叉树的根节点(先序遍历的第一个结点为根结点),由于结点值不同,我们可以通过根节点的值在该二叉树的中序序列找到根结点的位置,然后将中序序列分割成两个左右子树对应的中序序列,根据左右子树对应的中序序列的长度可以在先序序列中找到左右子树对应的先序序列。
这样我们就有了左右子树对应的中序序列和先序序列,左右子树的结点个数显然小于n,根据归纳假设的条件,左右子树可以由其先序序列和中序序列唯一地确定。于是这颗结点个数为n的二叉树也唯一地确定了。
根据第二数学归纳法和结论1,2,问题即证。
递归算法设计的一般步骤
一般步骤就是去建立递归模型,然后用程序去实现它。
获取递归模型的步骤如下:
1.对原问题进行分析,分解出合理的较小阶段,即划分阶段(得到数学归纳法中一连串的命题序列)。
2.假设较小阶段对应的问题是可解的,在此基础上确定原问题(较大问题)的解,即求解出命题之间的关系(相当于归纳假设前面的命题成立,然后通过归纳假设的结论的基础上来证明当前命题成立)。
3.确定一个较小的阶段直接求(返回)解,由此作为递归出口(相当于数学归纳法中,求证n=1或n=0时等式成立)。
例 2.5
用递归法求一个整数数组a的最大元素。
思考建立求解整数数组a最大元素的递归模型(第一数学归纳法):
我们想到以元素的个数来划分阶段,设f(a,i)求解数组a中前i个元素的最大元素,则f(a,i-1)求解数组a中前i-1个元素的最大元素,前者为规模较大的问题,后者为规模较小的问题,f(a,n)为我们想要求解的原问题。
假设f(a,i-1)已求出,则有f(a,i)=MAX{f(a,i-1),a[i-1]}。当我们向左递推到a中只剩下一个元素时,最小元素一定为该元素,返回该元素即可,于是递归出口为:f(a,1)=a[0]。
对应的递归算法如下:
int fmax(int a[],int i){
if (i==1) return a[0];//递归出口
else return(fmax(a,i-1),a[i-1]);//递归体
}
前面提到能够用递归解决的问题应该满足以下三个条件:
1.需要解决的问题可以转化为一个或多个子问题(规模较小的阶段)来求解,而这些子问题(阶段)的求解策略与原问题完全相同,只是在某些与问题(阶段)相关的属性上不同(策略的细节会因为属性的不同而改变)。
2.递归调用的次数必须是有限的。
3.必须有结束递归的条件来终止递归。
这三个条件是笼统地介绍可以递归可以使用的地方,但是像很多问题,例如上面求解一个数组的最大元素,它可以用递归设计算法,但是这样用递归设计出来的算法就像为了使用递归而用递归设计一样,递归简化代码的特性没能够体现出来,这样使用递归在算法设计中显然是不够灵活的。
所以我们还需要讨论一些经常要用到递归和适合用递归的地方。
递归数据结构及其递归算法设计
采用递归方式定义(数据结构结构体的成员类型是数据结构本身或数据结构本身对应的指针)的数据结构称为递归数据结构,在递归数据结构定义中包含的递归运算称为基本递归运算。
例如单链表就是一种递归数据结构,结构体的成员变量next的数据类型为结构体Node本身对应的指针:
typedef struct LNode{
ElemType data;
struct LNode *next;
}LinkList;
对于任一单链表结点t而言,取其下一个结点t->next就是基本递归运算。
归纳起来,递归数据结构的定义如下:
RD={D,Op}
其中,D为构成该数据结构的所有元素的集合,Op是基本递归运算的集合,Op中的基本递归运算对于集合D存在封闭性。
基于递归数据结构的递归算法设计
递归算法设计建立递归模型最重要的步骤是对于分解出规模较小的问题。对于递归数据结构,分解问题的过程要明显和简单很多,因为从定义上而言本来就是递归的,直接通过递归数据结构中的基本递归运算来分解规模较小的问题即可。
单链表的递归算法设计
对单链表L进行递归算法设计的一般步骤如下:
1.设求解为以L结点指针为首结点指针的整个单链表的问题为规模最大的“原问题”。
2.设求解为以L->next为首结点指针的单链表的问题为规模较小的“子问题”。
3.由“大问题”的解和“小问题”的解之间的关系得到递归体(假设“子问题”的完成是前提,思考如何在小问题完成的前提下完成大问题)。
4.再考虑特殊情况:通常是单链表为空或者只有一个结点时,此时往往能够直接返回问题的解,从而得到递归算法的递归出口。
例 2.6
有一个不带头结点的单链表L,设计一个算法释放其中所有结点。
释放以L为首结点指针的单链表的所有节点为规模最大的原问题,释放以L->next为首结点指针的单链表的所有节点为规模较小的子问题。
假设以L->next为首结点指针的单链表的所有节点已经全部被释放,我们再将释放L指向的空间就相当于释放了以L为首结点指针的单链表的所有节点。
我们设f(t)为释放以t为首结点指针的单链表的所有节点,则f(L)就可以采用先调用f(L->next),然后释放L指向的空间来求解。
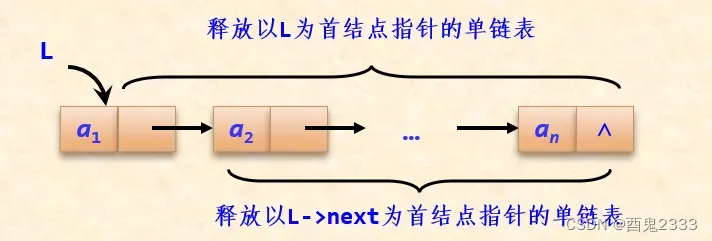
当想要释放的单链表为空时,不用进行另外的操作,整个单链表释放结束,即为该递归算法的递归出口。
对应的递归算法如下:
//释放单链表L中所有结点
void DestroyList(LinkNode *&L){
if (L!=NULL){
DestroyList(L->next);
free(L);
}
}
例 2.7
有一个不带头结点的单链表L,设计一个算法删除其中所有结点值为x的结点。
删除以L为首结点指针的单链表的所有结点值为x的结点为规模最大的原问题,删除以L->next为首结点指针的单链表的所有结点值为x的结点为规模较小的子问题。
我们假设以L->next为首结点指针的单链表的所有结点值为x的结点全部被删除,在该前提下删除以L为首结点指针的单链表的所有值为x的结点,只需讨论L所指向的结点的data域是否为x,我们根据L所指向结点的data域是否为x进行删除或不删除,就完成了删除以L为首结点指针的单链表的所有结点值为x的结点。
当单链表为空时,不需要进行删除和另外的操作,即为该递归算法的递归出口。
对应的递归算法如下:
//删除L中所有结点值为x的结点
void Delallx(LinkNode *&L,ElemType x){
LinkNode *p;
if (L==NULL) return;//递归出口
//L所指向的结点的data域为x
if (L->data==x){
p=L; L=L->next; free(p);//删除结点值为x的结点L
Delallx(L,x);//此时的L即为原本的L->next
}
else Delallx(L->next,x);
}
二叉树的递归算法设计
二叉树也是一种典型的递归数据结构,相较于单链表,因为有左子节点和右子节点两种基本递归运算,规模较大的问题的解的来源不仅仅来源于一个规模较小的子问题,而往往同时来源于左子树和右子树两个规模较小的子问题。
对二叉树b进行递归算法设计的一般步骤如下:
1.设求解为以b结点指针为根结点指针的整个二叉树的问题为规模最大的“原问题”。
2.设求解为以L->lchild为根结点指针的左子树的问题和求解为以L->rchild为根结点指针的右子树的问题为规模较小的“子问题”。
3.由“大问题”的解和“小问题”的解之间的关系得到递归体(假设“子问题”的完成是前提,思考如何在小问题完成的前提下完成大问题)。
4.再考虑特殊情况:通常是二叉树为空或者只有一个结点时,此时往往能够直接返回问题的解,从而得到递归算法的递归出口。
和单链表是基本一致的,可以发现对于递归数据结构,相关的规模较小的子问题与基本递归运算往往是直接相关的。
例 2.8
对于含n个结点的二叉树,所有结点值为int类型且data域不同,设计一个算法由其先序序列a和中序序列b创建对应的二叉链存储结构。
证明过程前面有,这里不再作赘述。
设f(a,b,n)为以长度为n的先序序列a和中序序列b构建二叉链存储结构bt,然后返回二叉链存储结构的根节点指针bt。以左子树对应的先序序列和中序序列创建二叉链存储结构,和以右子树对应的先序序列和中序序列创建二叉链存储结构为规模较小的子问题。
我们假设子问题已经解决,即左右子树的二叉链存储结构已经创建好,我们可以根据左子树的根结点指针和右子树的根结点指针以及整棵树的根节点指针建立整棵树的二叉链结构。
那么怎么寻找根节点呢?先序序列的第一个结点即为根节点,我们可以根据根节点的值从中序序列中得到左子树的中序序列和右子树的中序序列,再根据左右子树的结点个数从先序序列中得到左右子树的先序序列。
递归到二叉树为空(结点个数n为0)时,返回NULL,不用做额外的操作,即为递归算法的递归出口。
递归算法如下,这里的a和b是数组指针的使用方法:
//由长度为n先序序列a和中序序列b建立二叉链存储结构bt
BTNode *CreateBTree(ElemType a[],ElemType b[],int n){
int k;
if (n<=0) return NULL;
ElemType root=a[0];//根结点值为先序序列的第一个结点的值
BTNode *bt=(BTNode *)malloc(sizeof(BTNode));
bt->data=root;
//在b中查找b[k]=root的根结点,k即为左子树的结点个数
for (k=0;k<n;k++) if (b[k]==root) break;
bt->lchild=CreateBTree(a+1,b,k);//递归创建左子树
bt->rchild=CreateBTree(a+k+1,b+k+1,n-k-1);//递归创建右子树
return bt;
}
例 2.9
假设二叉树采用二叉链存储结构,设计一个递归算法释放二叉树bt中的所有节点。
释放以bt为根节点指针的二叉树的所有节点为规模最大的原问题,释放以bt->lchild和bt->rchild为根节点的左右子树的所有节点为规模较小的子问题。
假设左右子树的所有结点已经全部释放完全,我们只需要释放bt指向的结点就能够释放以bt为根节点指针的二叉树的所有节点。
当bt指向为空,即需要释放的二叉树为空,不需要进行其他的操作,即为递归出口。
对应的递归算法如下:
//释放以bt为根结点指针的二叉树的所有节点
void DestroyBTree(BTNode *&bt){
if (bt!=NULL){
DestroyBTree(bt->lchild);//释放左子树的所有节点
DestroyBTree(bt->rchild);//释放右子树的所有节点
free(bt);
}
}
例 2.10
假设二叉树采用二叉链存储结构,设计一个递归算法由二叉树bt复制产生另一棵二叉树bt1。
由二叉树bt赋值产生另一棵二叉树bt1为规模最大的原问题,由二叉树的左子树和右子树产生另一棵二叉树为规模较小的子问题。
如果左子树和右子树都已经复制产生了另一棵二叉树,我们只需要将这两颗二叉树作为左右子树插入到bt1的左右子节点处即可,bt1的data域复制bt的data域。
当需要被复制的二叉树为空时,将复制的结果置空,复制结束,即为递归算法的递归出口。
对应的递归算法如下,比起例2.9这里要先处理根节点,因为根节点存在才能复制左子树和右子树:
//由二叉树bt复制产生bt1
void CopyBTree(BTNode *bt,BTNode *&bt1){
if (bt==NULL) bt1=NULL;//递归出口
else{
//复制根节点
bt1=(BTNode *)malloc(sizeof(BTNode));
bt1->data=bt->data;
//复制左子树和右子树
CopyBTree(bt->lchild,bt1->lchild);
CopyBTree(bt->rchild,bt1->rchild);
}
}
例 2.11
假设二叉树采用二叉链存储结构,设计一个递归算法输出从根结点到值为x的结点的路径,假设二叉树中所有结点值不同。
输出从根结点到值为x的结点的路径为规模最大的原问题,这样设计的原问题分解到左右子节点会有一个问题,就是由于所有节点的值不同,值为x的结点要么存在于左子树上要么存在于右子树上,也就是说不一定存在根结点的左(右)子节点到值为x的结点的路径。
于是我们需要对原问题的设计进行修改,修改的方向有两种,因此对应的递归算法也有两种:
第一种设计的方案是“如果存在从根节点到值为x的结点的路径,返回true,且求解出根节点到值为x的结点的路径(在true的前提下)”为规模最大的原问题,于是分解出左子节点和右子节点的子问题。
我们假设左子节点和右子节点的子问题已经解决,即我们现在拥有的是左右子树是否存在值为x的结点,以及如果如果左右子树中存在值为x的结点,左右子节点到值为x的结点的路径。
此时我们可以根据左右子树是否存在值为x的结点和当前结点的值,判断出是否存在当前结点到值为x的结点的路径,如果存在,我们将当前结点接入到路径中即可。
递归出口有两种情况:
1.当前结点为空,即以该节点为根节点的子树为空,此时返回false,确定这条分支上的查找是失败的。
2.当前结点值为x,代表值为x的结点被找到,不再向下继续寻找,返回true。
对应的递归算法如下:
//path为最终想要返回的路径
bool Findpath1(BTNode *b,int x,vector<int> &path){
if (bt==NULL) return false;//递归出口1,查找到叶子结点,查找失败
//根据左右子树是否存在值为x的结点和当前结点的值,判断出是否存在当前结点到值为x的结点的路径
//如果存在,我们将当前结点接入到路径中即可
if (b->data==x){
path.push_back(x); return true;//递归出口2,查找成功
}
else if (Findpath1(b->lchild,x,path)||Findpath1(b->rchild,x,path)){
path.push_back(b->data); return true;
}
}
第二种设计方案在从规模较小的问题得到规模较大的问题和第一种设计方案有所区别,规模较大问题的true或false仍是根据子问题返回的true或false得到,但是规模较大问题的解不再与子问题的true or false相关,而是对于任意的结点用tmppath都保存根结点到该节点的路径,当找到值为x的结点时,直接将tmppath赋值给最终答案path。
对应的递归算法如下:
//path为最终答案,tmppath为递归到当前结点的路径
bool Findxpath2(BTNode *bt,int x,vector<int> tmppath,vector<int> &path){
if (bt==NULL) return false;//递归出口1,查找到叶子结点,查找失败
tmppath.push_back(bt->data);//当前结点加入path
//当前结点值为x,返回true
if (bt->data==x){path=tmppath; return true;}
bool find=Findxpath2(bt->lchild,x,tmppath,path);//在左子树中查找
if (find) return true;//左子树中成功找到
//左子树中没有找到,在右子树中查找
else return Findxpath2(bt->rchild,x,tmppath,path);
}
书上认为第二种方法更加直接,从上面的分析来看,你觉得呢?两种方法哪种效率更高呢?
基于归纳思想的递归算法设计
比起基于递归数据结构的递归算法设计能够快速的划分阶段,通过基本递归运算寻找子问题,基于归纳思想的递归算法设计简单来说就是对一些更加朴素的,从数据角度来看不那么“递归”的数学问题进行递归算法的设计。
这需要通过对求解问题的深入分析,提炼出问题定义和求解过程中的相似性而不是数据结构的相似性,算法设计的难度进一步提升了。
从求解数学问题的角度来看分为两类:定义是递归的,问题的求解方法是递归的。
定义是递归的
有许多数学公式,数列等的定义是递归的,以这些定义为基础的问题的求解过程可以将其递归定义直接转化为对应的递归算法。
例如:Fibonacci数列。
问题的求解方式是递归的
有些问题的解法是递归的,典型的有汉诺塔问题求解(这里不多作赘述),问题的求解方式是递归的是最不显形的能用递归解决的一类问题,甚至在某些场景下会表现出为了使用递归而使用递归的感觉,这就需要对问题更深刻的理解和分析。
后面会介绍的分治法和动态规划算法本质上都是问题求解方式是递归的递归算法,区别在于分割问题的策略不同,实际优化的思想不同和分析的角度不同。
(动态规划的递归算法将问题分解成若干个阶段,分治法将问题分割成若干个子问题)
书上举了一个求解多项式的Horner规则,个人觉得应该放在动态规划算法的部分介绍,严格意义上从优化的思想来看更倾向于动态规划算法(动态规划算法也属于递归算法,但是动态规划算法优化的策略,思想具有一定的特性)。
例 2.12
设计一个递归算法,输出一个大于零的十进制数n的各数字位。例如n=123,输出各个数字位为1,2,3。
输出n位整数的n个数字位为规模最大的原问题,记作f(n),输出i位整数的i个数字位为规模较小的原问题,记作f(i)。
假设我们现在已经能够输出n位整数中连续的n-1位数字位(如果连续的n-1位集中在左边,就除以10后再进行f(n-1)即可),我们需要输出另外一位(最左或最右的)数字位即可,显然用mod 10的方法输出最右的数字位,然后将原数除以10,得到规模较小的问题,是较好的从规模较大的问题分解到规模较小的问题的策略。
当n=1时,直接输出该数即可,即为该递归算法的递归出口。
void digits(int n){
if (n!=0){
digits(n/10); printf("%d",n%10);
}
}
例 2.13
设计一个递归算法,求n!末尾所含有的0的个数。
求解n!末尾所含有的0的个数为规模最大的原问题,那么很显然的有求解i!末尾所含有的0的个数为规模较小的子问题。
当我们知道了(n-1)!末尾所含有的0的个数之后,n!末尾所含有的0的个数还是不能够简单的通过数字n与(n-1)!末尾所含有的0的个数来确定,还需要直到(n-1)!中含有的多余的2和5的因子,以及n中5的因子个数,于是需要对问题进行进一步的剖析。
一个数的末尾所含有的0的个数取决于该数因子中2的个数和5的个数,对于n!,我们有显然的结论是n!中2的因子的个数一定远超过5的因子个数,所以我们只需要统计n!中5的因子的个数。
接下来朴素的做法是,每次计算n中5的因子的个数,然后从规模较小的问题扩展到规模较大的问题。但事实上,根据5的因子出现的频率有更好的处理方法:
我们用f(n)表示n中5的因子的个数,于是可以得到:
f(n!)=f(1*2*3*······n)
=f(5*10*15······)(只考虑被5整除的数)
=n/5+f(1*2*3······*(n/5))(将被5整除的数的5的因子提取出来)
=n/5+f((n/5)!)
这个递推式在效率上能够达到更好的效果。
递归算法设计示例
介绍一些经典的递归算法设计的例子。
简单选择排序和冒泡排序
对于给定的含有n个元素的数组a,分别采用简单选择排序和冒泡排序方法对其按元素值递增排序。
简单选择排序和冒泡排序从递归算法设计的角度考虑而言和求解最小元素的递归算法设计一样,都是将“n个元素全部排序好”作为规模最大的原问题,将“前i个元素排序好”作为规模较小的子问题。
那么我们怎么从规模较小的子问题得到规模较大的子问题呢?即前i个元素已经排序好后,我们该如何得到前i+1个排序好的元素。
选择排序的策略是从后面的n-i个数中找到最小的数与第i+1个位置的数进行替换;冒泡排序的策略则是从最后一个元素开始不断地将较小的元素向前交换(上浮),直到后半段较小,也就是最小的的元素上浮到第i+1个元素的位置。
两种策略都能从规模较小的子问题得到规模较大的子问题。
递归出口就是需要排序的元素只有一个时,保持不变即可。
选择排序对应的递归算法如下:
void SelectSort(int a[],int n,int i){
if (i==n-1) return; //递归出口:元素全部排序完毕
else{
int k=i;//k记录最小元素的下标
//寻找最小元素的下标
for (int j=i+1;j<n;j++) if (a[j]<a[k]) k=j;
//若最小元素不是a[i],a[i]和a[k]交换
if (k!=i) swap(a[i],a[k]);
//递归到小问题
SelectSort(a,n,i+1);
}
}
冒泡排序对应的递归算法如下(这里的冒泡排序是进行过一定优化的版本,当某次排序寻找最小元素没有进行上浮时,代表后面的序列也是有序的,更进一步的优化是range-limiting bubble sort):
void BubbleSort(int a[],int n,int i){
bool exchange;
if (i==n-1) return;//递归出口:元素全部排序完毕
else{
exchange=false;//exchange代表是否进行上浮操作
for (int j=n-1;j>i;j--) if (a[j]<a[j-1]){
swap(a[j],a[j-1]); exchange=true;//上浮
}
//flagged bubble sort的优化
if (exchange==false) return;
else BubbleSort(a,n,i+1);
}
}
求解n皇后问题
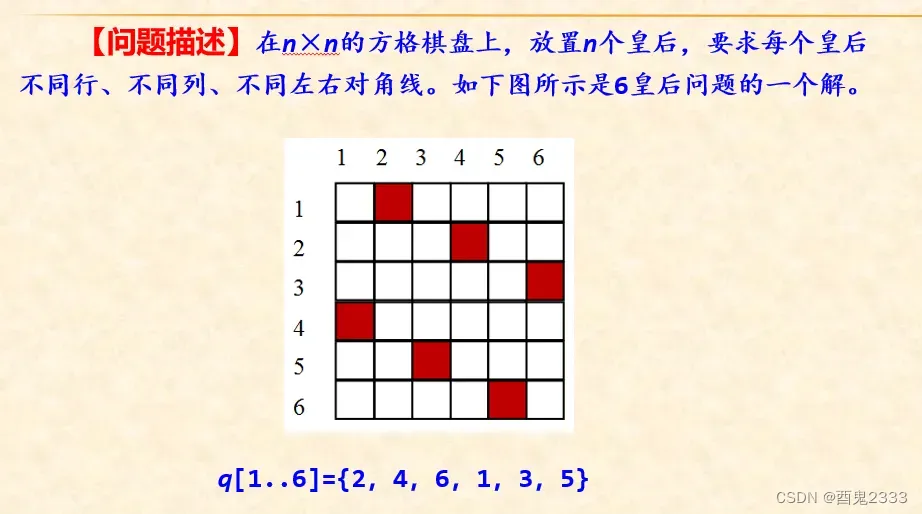
我们将问题分解成一行一行的放置皇后棋子,就可以比较简单的得到我们的递归模型:
放置n行的皇后棋子为规模最大的原问题,放置前i行的皇后棋子为规模较小的子问题;当我们前i行的皇后棋子放置完毕后,需要做的就是在第i+1行找到能够放置棋子且不会与前面i行放置棋子冲突的位置(这个判断的方法有很多,教材上用的是直接和前面棋子放置的位置比较的做法,也可以用类似于计数排序的方法将各行各列各斜线是否被占据的情况进行统计)。
递归出口是所有棋子放置完毕,或者出现一些糟糕的放置情况导致棋子无法放置完毕。
对应的递归算法如下:
//测试(i,j)位置能否摆放皇后
bool place(int i,int j){
//第一行的第一个皇后总是可以放置
if (i==1) return true;
int k=1;
//判断和前面放置过的棋子是否冲突
while (k<i){
if ((q[k]==j)||(abs(q[k]-j)==abs(i-k)))
return false;
k++;
}
//没有冲突就可以放置
return true;
}//放置1~i的皇后
void queen(int i,int n){
if (i>n) dispasolution(n);//递归出口:所有皇后放置结束,输出结果
else{
//在第i行上试探每一个列j
//在第i行上找到一个合适位置(i,j)
for (int j=1;j<=n;j++)
if (place(i,j)){
//放置位置后分解到规模较小的子问题
q[i]=j; queen(i+1,n);
}
}
}
递归算法转化非递归算法
把递归算法转化为非递归算法有如下两种基本方法:
1.直接用循环结构的算法替代递归算法。
2.用数据结构栈来模拟系统栈的运行过程,通过分析去保存有必要保存的信息(比如保存数据,不保存代码),从而用非递归算法替代递归算法。
第1种是直接转化法,不需要使用栈;第2种是间接转化法,需要使用栈。
用循环结构替代递归过程
采用循环结构消除递归这种直接转化法没有通用的转换算法,对于具体问题要深入分析对应的递归结构,设计有效的循环语句进行递归到非递归的转换。
(简单来说就是没有通用的法则,不是我们学习的重点)
用栈消除递归过程
用栈来消除递归过程就是用栈来模拟系统栈的功能:
系统栈中存储递归函数递归到某个阶段的各个参数和结果,但这个结果在没有全部递归到递归出口前是无法得到的,我们用一个tag表示当前栈顶阶段的结果是否不明确(递归出口的tag为0),不明确就一直进栈阶段直到进栈到递归出口的阶段,栈顶阶段的tag为0。
tag为0代表栈顶的结果是明确的,我们需要将栈顶阶段退栈然后将栈顶阶段的结果返回到前面的阶段代入,来让前面的阶段tag变为0(即结果明确)。
那么会不会出现退栈之后前面阶段结果仍不明确的情况呢?从递归树的角度而言是不可能的,但由于我们是用数据结构栈来模拟递归栈过程,这就很看大家程序设计的水平了。
我们以求解n!的递归算法到非递归算法为例:
//求n!的递归算法转换成的非递归算法
int fun2(int n){
//NodeType对应的类型为阶段
NodeType e,e1,e2; stack<NodeType> st;
e.n=n; e.tag=1; st.push(e);//e为原问题
while (!st.empty()){
//栈顶阶段的结果不明确,让下一个阶段进栈
if (st.top().tag==1){
if (st.top().n==1){
st.top().f=1; st.top().tag=0;//递归出口(相当于进行了进站和出栈的两次操作)
}
else{
e1.n=st.top().n-1;
e1.tag=1;
st.push(e1);//子任务(n-1)!进栈
}
}
//栈顶阶段的结果明确,代入回前面阶段
else{
//将栈顶阶段退栈
e2=st.top(); st.pop();
//结果和前面阶段的参数一起计算前面阶段的结果
st.top().f=st.top().n*e2.f;
//在这个递归模型中,该阶段的结果通过这样就明确了
st.top().tag=0;
}
//栈中只有一个阶段且结果明确时,就是我们需要的解
if (st.size()==1&&st.top().tag==0) break;
}
return(st.top().f);
}
上面一类的问题,原问题的解是通过规模最小的问题(递归出口)一步一步扩展到规模较大的问题的解得到的,较小规模的参数对于最终的解都是有意义的,书上称上面大问题与小问题的关系为等值关系:规模较大问题的解等于规模较小问题的解的某种运算结果。
反之如果中间较小规模的参数对于最终的解没有贡献,即最终解是最小规模问题(递归出口)解的组合,书上称这样的关系为等价关系:规模较大问题的求解过程是转化为规模较小问题的求解过程而得到的。
例如比较经典的汉诺塔问题的递归模型就是等价关系,等价关系的递归算法转化成非递归算法就不需要将解代入回规模较大的子问题中(事实上区别不大)。
汉诺塔问题递归算法转化的非递归算法如下(详见代码,汉诺塔问题实在没有再次分析的必要了):
typedef struct{
int n;//阶段的n值
char x,y,z;//阶段的属性值
int tag;//tag表示是否还没有求解出子问题的解
}NodeType;
//求Hanoi递归算法转换成的非递归算法
//Hanoi1(n,x,y,z)表示将n个盘子从x盘以y盘作为中介放入到z盘步骤最少的方法
//汉诺塔问题的求解策略是将n-1个盘子先放入到y中,将最下面的盘子放入到z中
//再将n-1个盘子通过x从y放入到z中
void Hanoi1(int n,char x,char y,char z){
NodeType e,e1,e2,e3; stack<NodeType>st;
//未求解的原问题进栈
e.n=n; e.x=x; e.y=y; e.z=z; e.tag=1; st.push(e);
while (!st.empty()){
if (st.top().tag==1){
e=st.top(); st.pop();//分解子问题:Hanoi(n,x,y,z)
//产生规模更小的子问题进栈:Hanoi(n-1,y,x,z)
e1.n=e.n-1; e1.x=e.y; e1.y=e.x; e1.z=e.z;
if (e1.n==1) e1.tag=0;//递归出口1
else e1.tag=1;
st.push(e1);
//将最下面的盘子从x放到z的过程,和Hanoi(1,x,y,z)是等价的
e2.n=e.n; e2.x=e.x; e2.z=e.z; e2.tag=0;
st.push(e2);
//产生规模更小的子问题进栈:Hanoi(n-1,x,z,y)
e3.n=e.n-1; e3.x=e.x; e3.y=e.z; e3.z=e.y;
if (e3.n==1) e3.tag=0;//递归出口2
else e3.tag=1;
st.push(e3);
}
//递归出口
else if (st.top().tag==0){
printf("\t将第%d个盘片从%c移动到%c\n",
st.top().n,st.top().x,st.top().z);
st.pop();
}
}
}
递推式的计算
设计出递归算法之后,能够计算出递归式和通过递归式计算出时间复杂度对于算法的分析是非常重要的,主要有特征方程求解递归方程和递归树求解递归方程两种方法。
特征方程求解递归方程
递推式的一般格式如下:
f(n)=a[1]*f(n-1)+a[2]*f(n-2)+…+a[k]*(n-k)+g(n);
f(i)=b[i] 0≤i<k。
当g(n)=0时,我们称它为线性齐次递推式。这类问题的解决非常困难(不能),线性齐次递推式有通用的解法,而对于非齐次的递推式,需要寻找特解,现在还没有一种寻找特解的有效方法(高数课上大概是讲过的)。一般课内讨论的多的是线性齐次递推式中一阶和二阶的情况。
一阶线性齐次递推关系,即f(n)=a*f(n-1),就是简单的等比数列。
二阶线性齐次递推关系,即f(n)=a[1]*f(n-1)+a[2]*f(n-2)。
解决策略是求解x2=a[1]*x+a[2]的解r[1]和r[2],有结果如下:

递归树方法求解递归方程
用递归树求解递归方程的方法就比较粗暴(更倾向于统计),基本过程是:
1.展开递归方程,构造对应的递归树。
2.把每一层的时间进行求和,从而得到算法时间复杂度的估计。
例 2.15
分析以下递归方程的时间复杂度:
T(n)=1,当n=1;
T(n)=2T(n/2)+n2,当n>1。
递归树求解的过程如下:
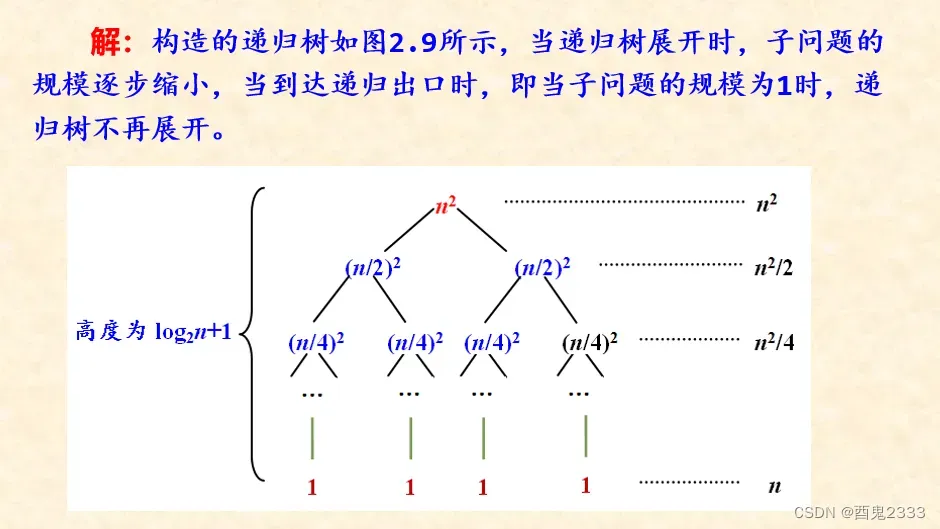
第i层有2i个结点,每个结点时间复杂度为为(n/2i)2,于是得到每一层的复杂度为2i*(n/2i)2=n2/2i,一共有logn+1层,等比数列求和即可,复杂度为O(n2)。
另一个例子基本类似就不做赘述了。
主方法求解递归方程就是递归树方法的数学归纳得到的公式,一般用于计算分治法的渐进时间复杂度,详见上科大课件的lecture 9。
模型:

结论:

(水印都看不清了)
文章出处登录后可见!