1. Recurrent neural network
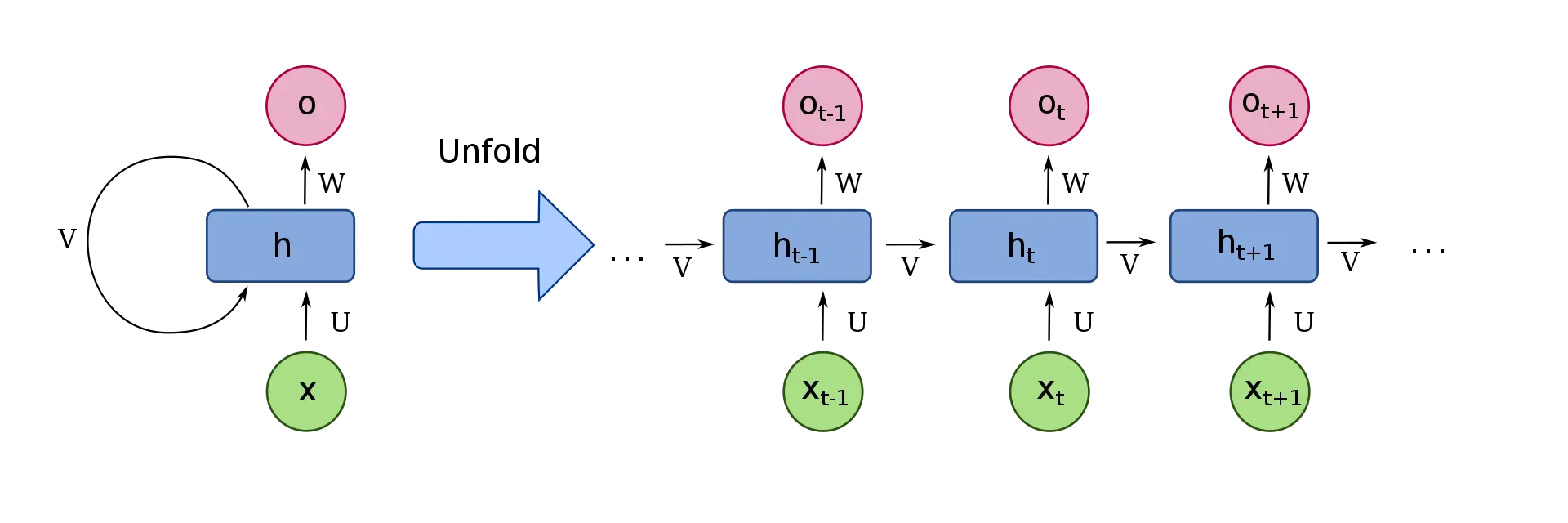
1.1 Elman network
1.2 Jordan network
Variables and functions
: input vector
: hidden layer vector
: output vector
and
: parameter matrices and vector
and
: Activation functions
1.3 Bidirectional RNN
2. Long short-term memory
2.1 LSTM with a forget gate
The compact forms of the equations for the forward pass of an LSTM cell with a forget gate are:
where the initial values are and
and the operator o denotes the Hadamard product (element-wise product). The subscript
indexes the time step.
Variables
: input vector to the LSTM unit
: forget gate’s activation vector
input/update gate’s activation vector
: output gate’s activation vector
: hidden state vector also known as output vector of the LSTM unit
cell input activation vector
: cell state vector
and
: weight matrices and bias vector parameters which need to be learned during training where the superscripts
and
refer to the number of input features and number of hidden units, respectively.
2.2 Peephole LSTM
3. training RNN
3.1 Problem
RNN: The error surface is either very flat or very steep → 梯度消失/爆炸 Gradient Vanishing/Exploding
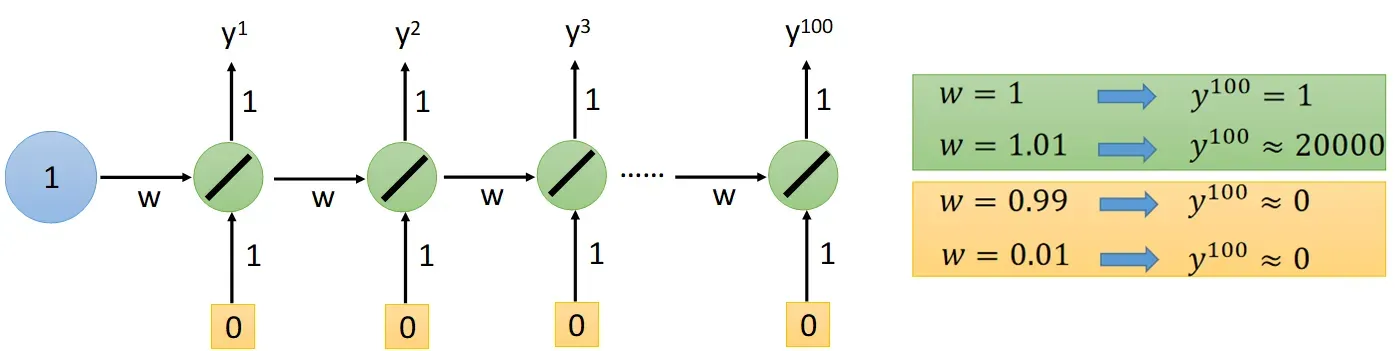
3.2 Techniques
- Clipping the gradients
- Advanced optimization technology
- NAG
- RMSprop
- Try LSTM (or other simpler variants)
- Can deal with gradient vanishing (not gradient explode)
- Memory and input are added (在RNN中,对于每一个输入,memory会重置)
- The influence never disappears unless forget gate is closed (No Gradient vanishing, if forget gate is opened.)
- Better initialization
- Vanilla RNN Initialized with Identity matrix + ReLU activation function [Quoc V. Le, arXiv’15]
参考资料
[1] Recurrent neural network – Wikipedia
[2] Long short-term memory – Wikipedia
[3] Bidirectional Recurrent Neural Networks – Dive into Deep …
[4] 机器学习 李宏毅
文章出处登录后可见!
已经登录?立即刷新