胶囊网络python-pytorch版本
胶囊网络概述(md原文件)
1.胶囊网络概念与理解
1.1 胶囊网络概述
摘抄Hinton等人的《Transforming Autoencoders》关于胶囊概念理解如下:
人工神经网络不应当追求“神经元”活动中的视角不变性(使用单一的标量输出来总结一个局部池中的重复特征检测器的活动),而应当使用局部的“胶囊”,这些胶囊对其输入执行一些相当复杂的内部计算,然后将这些计算的结果封装成一个包含信息丰富的输出的小向量。每个胶囊学习辨识一个有限的观察条件和变形范围内隐式定义的视觉实体,并输出实体在有限范围内存在的概率及一组“实例参数”,实例参数可能包括相对这个视觉实体的隐式定义的典型版本的精确的位姿、照明条件和变形信息。当胶囊工作正常时,视觉实体存在的概率具有局部不变性——当实体在胶囊覆盖的有限范围内的外观流形上移动时,概率不会改变。实例参数却是“等变的”——随着观察条件的变化,实体在外观流形上移动时,实例参数也会相应地变化,因为实例参数表示实体在外观流形上的内在坐标。
当我们通过计算机图形渲染来构建对象时,我们需要指定并提供一些几何信息,比如告诉计算机在何处绘制对象,该对象的比例,角度以及其他空间信息,对象通常是通过参数设置来呈现的,而这些信息全部表示出来,是屏幕上的一个对象。但是,**如果我们只是通过观察照片中的物体来提取信息呢?**这就是胶囊网络(Capsule Network)的核心思想——**逆渲染(inverse rendering)**在胶囊网络中,恰恰相反,网络是要学习如何反向渲染图像——通过观察图像,然后尝试预测图像的实例参数。胶囊网络通过重现它检测到的对象,然后将重现结果与训练数据中的标记示例进行比较来学习如何预测。通过反复的学习,它将可以实现较为准确的实例参数预测。(见2.5逆图形)
一个胶囊网络是由胶囊而不是由神经元构成。一个胶囊就是将原有大家熟知的神经网络中的个体神经元替换成了一组神经元组成的向量,这些神经元被包裹在一起,组成了一个胶囊。(注意,原文表述的胶囊是一组神经元,也就是说胶囊其实指的是一整层)它们可以学习在一个图片的一定区域内检查一个特定的对象(比如,一个矩形)。它的输出是一个向量(例如,一个8维的向量)。每个向量的长度代表了物体是否存在的估计概率[1],它的方向(例如在8维空间里)记录了物体的姿态参数(比如,精确的位置、旋转等)。如果物体有稍微的变化(比如,移动、旋转、尺寸变化等),胶囊将也会输出一个长度相同但是方向稍微变化的向量。因此胶囊是等变的。(见2.4不变性与等变性)
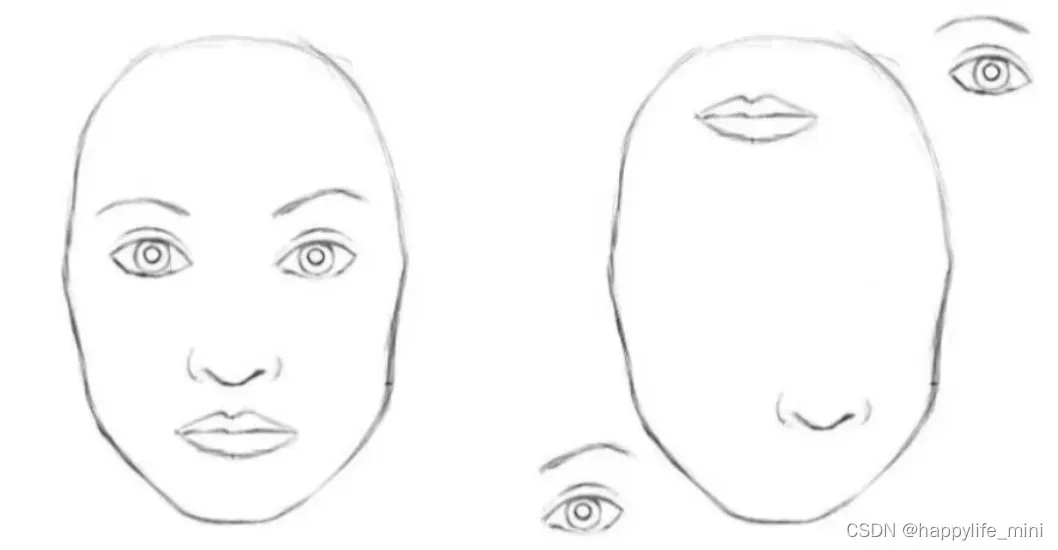
要理解胶囊网络,我们首先需要抛开对CNN架构的固有印象,因为Geoffrey Hinton实际 上认为在CNN中应用pooling是一个很大的错误,它工作得很好的事实是一场灾难(来自演讲)。在最大池化过程中,很多重要的信息都损失了,因为只有最活跃的神经元会被选择传递到下一层,而这也是层之间有价值的空间信息丟失的原因。当我们看到下图时,这看起来并不是一张十分正确的人脸图,虽然图中包含了人脸的每一个组成部分。人类可以很容易分辨出这不是一张正确的人脸,但是CNNs却很难判断这不是一张真实的人脸,因为它仅仅看图像中的这些特征,而没有注意这些特征的姿态信息。
CNN着力于检测图像像素中的重要特征。考虑简单的人脸检测任务,一张脸是由代表脸型的椭圆、两只眼睛、一个鼻子和一个嘴巴组成。而基于CNN的原理,只要存在这些对象就有强的刺激,因此这些对象空间关系反而没有那么重要。
如下图,右图不是人脸但都具备了人脸需要的对象,所以CNN有很大可能通过具有的对象激活了是人脸的判断,从而便得结果判断出错。
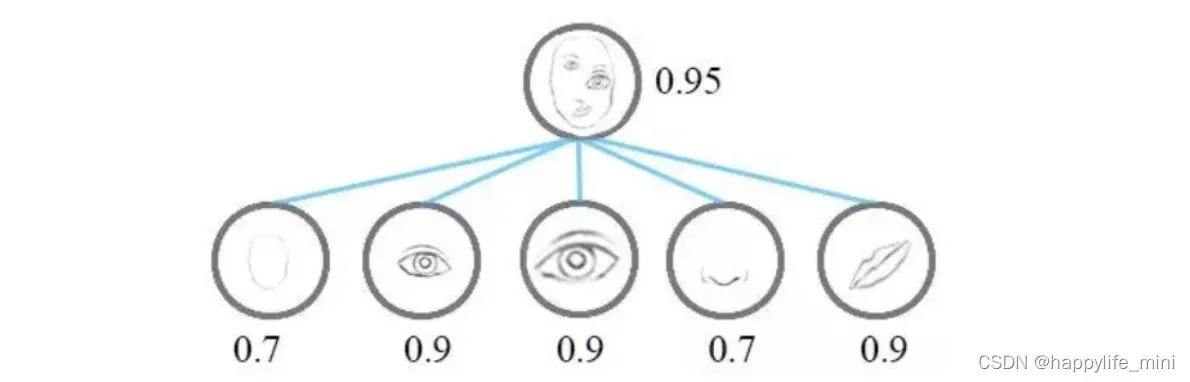
如下图,重新审视CNN的工作方式,高层特征是低层特征组合的加权和,前一层的激活与下一层神经元的权重相乘且相加,接着通过非线性激活函数进行激活。在这么一个架构中,高层特征和低层特征的位置关系变得模糊(我认还是有一些只是没有很好的利用)。而CNN解决这个问题的方法是通过最大池化层。(最大池化层或多或少会丢失位置信息)
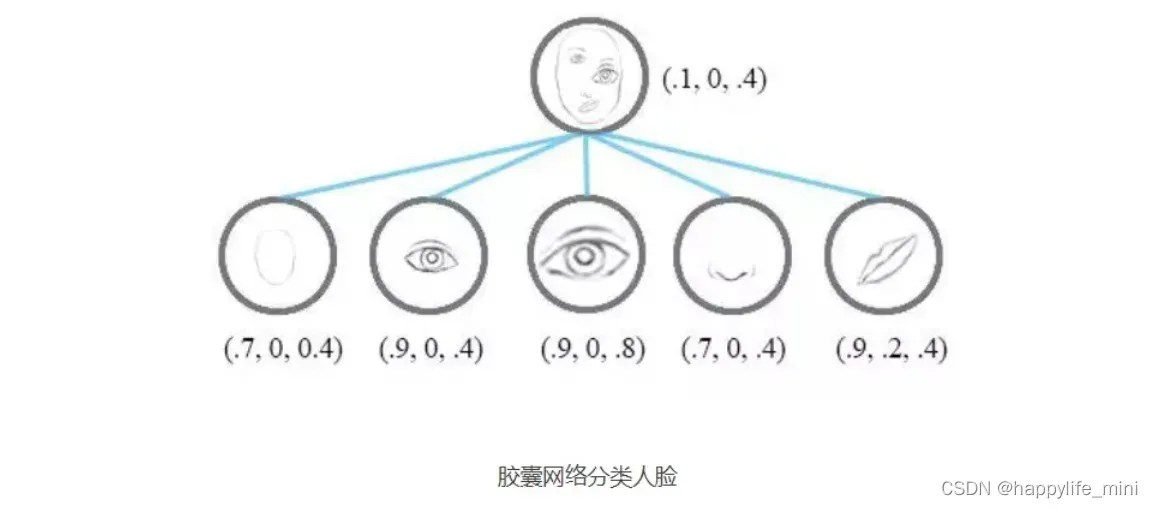
胶囊网络(capsule networks)解决这个问题的方法是,实现对空间信息进行编码同时也计算物体的存在概率。这可以用向量来表示,向量的模表示特征存在的概率,向量的方向表示特征的姿态信息。
Capsule 的工作原理归纳成一句话就是,所有胶囊检测中的特征的状态的重要信息,都将以向量的形式被胶囊封装。
简单来说,可以理解成:
- 人造神经元输出单个标量。卷积网络运用了卷积核从而使得将同个卷积核对于二维矩阵的各个区域计算出来的结果堆叠在一起形成了卷积层的输出。
- 通过最大池化方法来实现视角不变性,因为最大池持续搜寻二维矩阵的区域,选取区域中最大的数字,所以满足了我们想要的活动不变性(即我们略微调整输入,输出仍然一样),换句话说,在输入图像上我们稍微变换一下我们想要检测的对象,模型仍然能够检测到对象
- 池化层损失了有价值的信息,同时也没有考虑到编码特征间的相对空间关系,因此我们应该使用胶囊,所有胶囊检测中的特征的状态的重要信息,都将以向量形式被胶囊封装(神经元是标量)
论文 Dynamic Routing Between Capsules 中建议使用两个损失函数。主要是为了实现capsules之间的等变性。这意味着,**在图像中移动特征会改变Capsule向量,但是不影响特征存在的概率。**底层Capsules提取特征之后,就传递到匹配的更高层的Capsules。
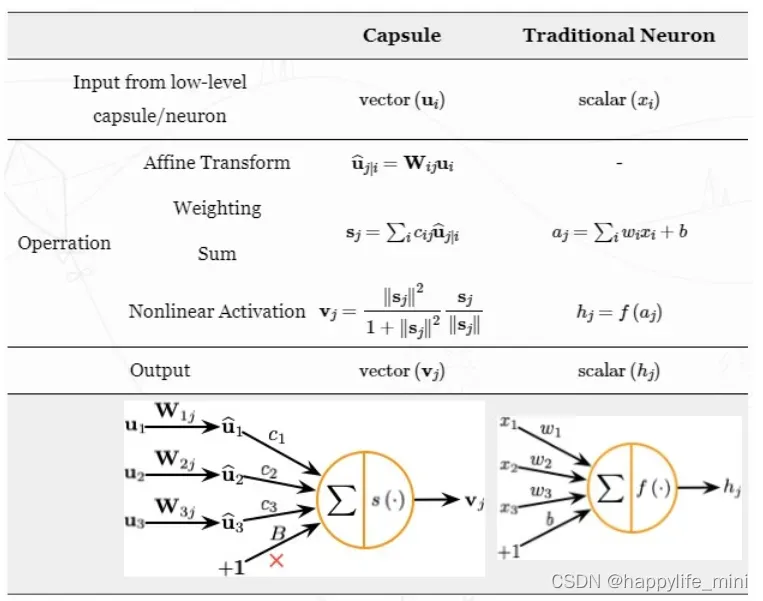
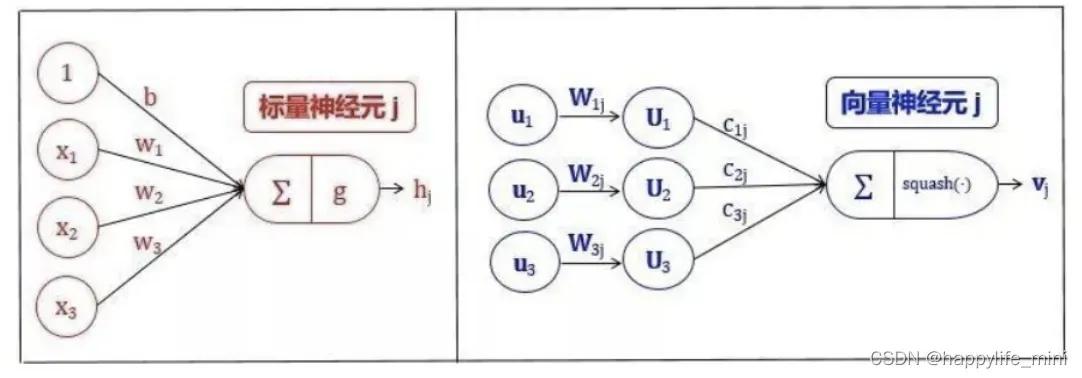
1.2 一个胶囊的组成(与普通神经元进行对比)
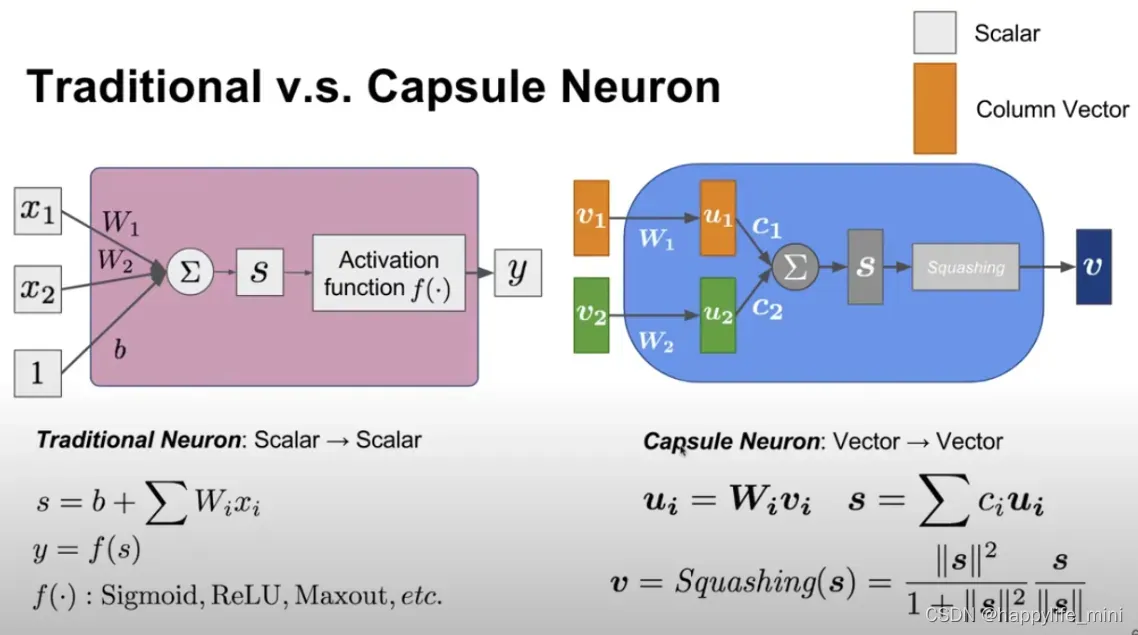
注意:参数w1和w2是需要被学习出来的,而c1和c2不是被学习出来的,而是由dynamic动态决定的。(c的和为1)
在传统神经网络里,一个神经元一般会进行如下的标量操作:
- 输入标量的标量加权;
- 对加权后的标量求和;
- 对和进行非线性变换生成新标量。
胶囊可以理解为上述 4 个步骤的向量版,同时增加了对输入的仿射变换:
-
输入向量的矩阵乘法:
胶囊接受的输入向量:编码了低层胶囊检测出的相应对象的概率,
向量的方向:编码了检测出的对象的一些内部状态。
-
仿射变换:
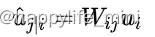
接着将这些向量乘以相应的权重矩阵 W,W 编码了低层特征(例如:眼睛、嘴巴和鼻子)和高层特征(例如:面部)之间的空间关系和其他重要关系。 -
动态路由:
神经元的权重是通过反向传播学习的,而胶囊则使用动态路由。这一过程使用权重 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8cKdDbRx-1637908330661)(https://www.zhihu.com/equation?tex=c)] 决定了(经过本层的权重矩阵投影处理后的)来自下层的向量将会如何进入高一层的向量,需要注意的是这一过程并不加入bias。
动态路由的关键在于权重系数 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-52M7162Y-1637908330663)(https://www.zhihu.com/equation?tex=c)] 如何确定。对于max pooling而言,只有一个值能够进入本层,显然对应的 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zIeaCiPI-1637908330664)(https://www.zhihu.com/equation?tex=c)] 就是一个独热的向量;而在这里我们通过一种类似聚类的方式对向量进行赋权重,称为基于一致程度的路由(Routing-by-agreement)
-
求和向量到输出向量的非线性变换: (Squash)
胶囊神经网络的非线性激活函数接受一个向量,然后在不改变方向的前提下,将其长度压缩到 1 以下。

1.3 胶囊之间的动态路由(Dynamic Routing)
李宏毅:动态路由有剔除离群点的意思,类似于rnn循环神经网络,最后训练的时候依旧使用的backprop反向传播。
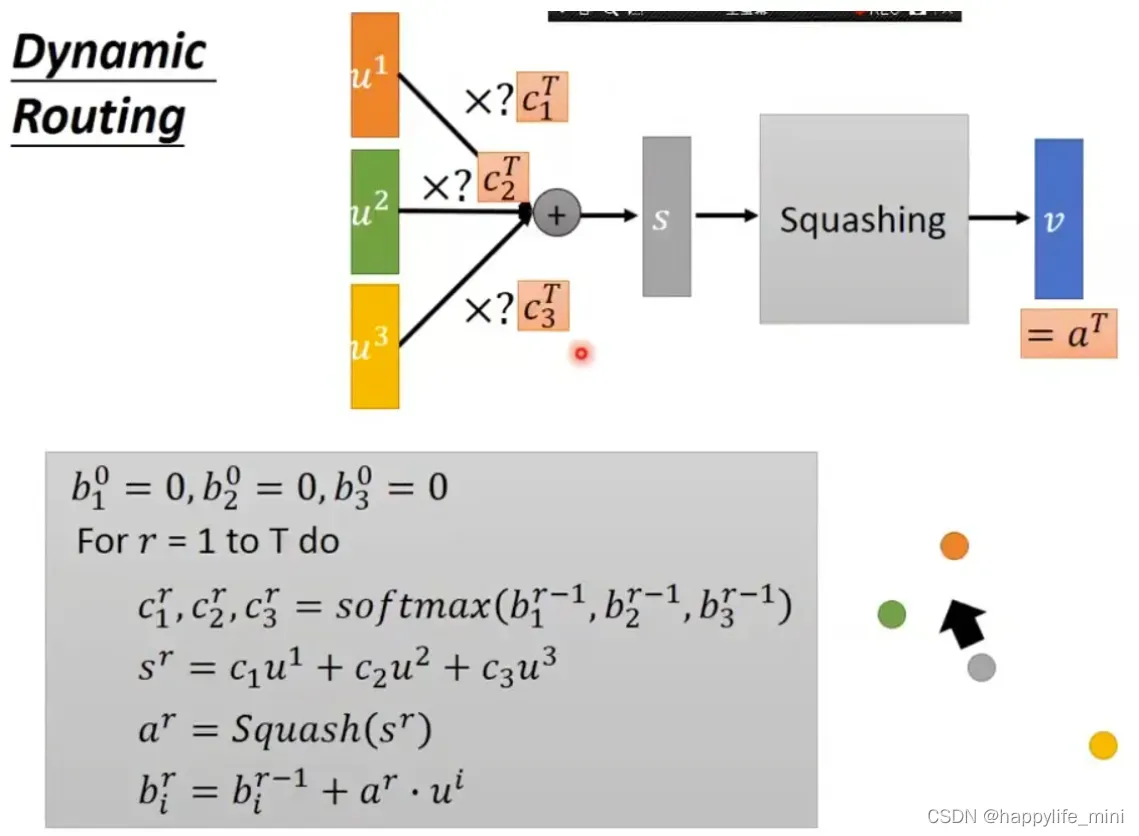
动态路由算法流程:
- 在这里的迭代计算过程中,在系数 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U1PIP9BF-1637908330667)(https://www.zhihu.com/equation?tex=c)] 最终确定前的步骤是不会计算梯度的,单纯通过聚类的方式得到, [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZOrPEAYA-1637908330668)(https://www.zhihu.com/equation?tex=c)] 不会参与梯度下降调整参数的过程。
- 这里的softmax过程,是指某个输入向量进入每一个高层胶囊神经元的概率和为1,而不是反过来。结合上文的理解是:向量在上层的某个胶囊神经元空间中越接近中心簇,被该神经元感知到的可能性越大,所以分配到这个神经元的权重就大,相应地分配到其他神经元的权重就小。
- 第 1 行表示算法的输入为:低层所有胶囊的输出 u,以及路由迭代计数 r。
- 第 2 行中的 bij 为一个临时变量,其值在迭代过程中更新,算法运行完毕后其值被保存在 cij 中,初始化都为0。
- 第 3 行表示如下步骤将会被重复 r 次。
- 第 4 行利用 bi 计算低层胶囊的权重向量 ci。softmax 确保了所有权重为非负数,且和为一。第一次迭代后,所有系数 cij 的值相等,随着算法的继续,这些均匀分布将发生改变。
- 第 5 行计算经前一步确定的路由系数 cij 与 加权后的输入向量的线性组合。该步缩小输入向量并将他们相加,得到输出向量 sj。
- 第 6 行对前一步的输出向量应用 squash 非线性函数。这确保了向量的方向被保留下来,而长度被限制在 1 以下。
- 第 7 行通过观测低层和高层的胶囊,根据公式更新相应的权重 bij。胶囊 j 的当前输出与从低层胶囊 i 处接收到的输入进行点积,再加上旧的权重作为新的权重。点积检测胶囊输入和输出之间的相似性。
- 重复 r 次,计算出所有高层胶囊的输出,并确立路由权重。之后正向传导就可以推进到更高层的网络。

图像直观理解:
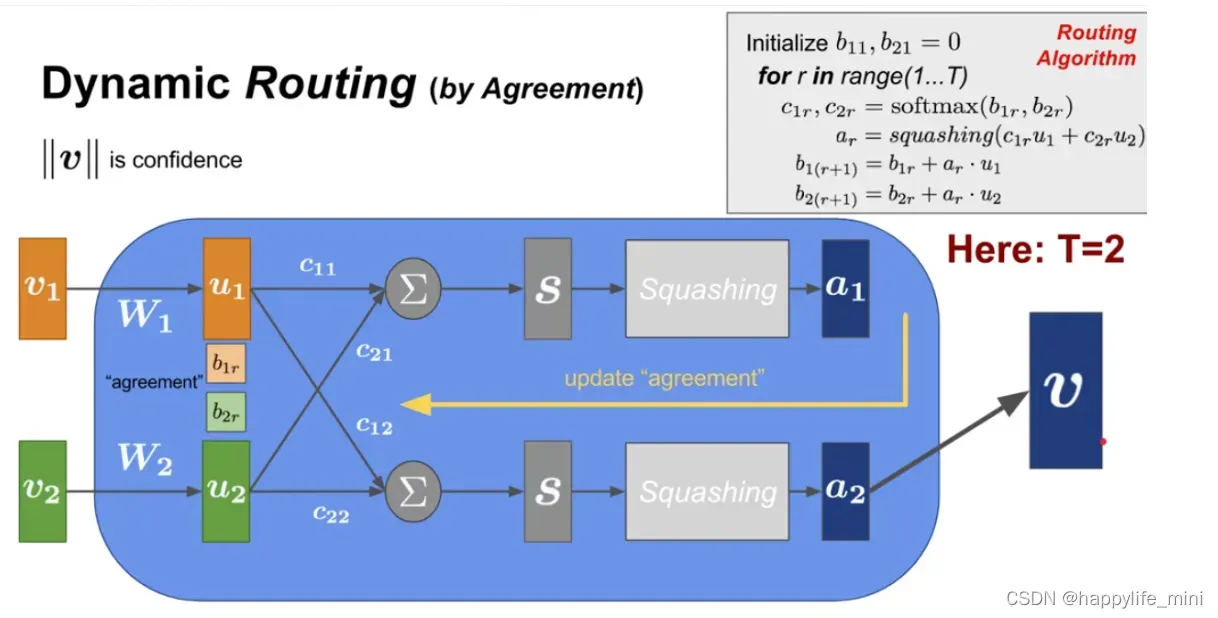
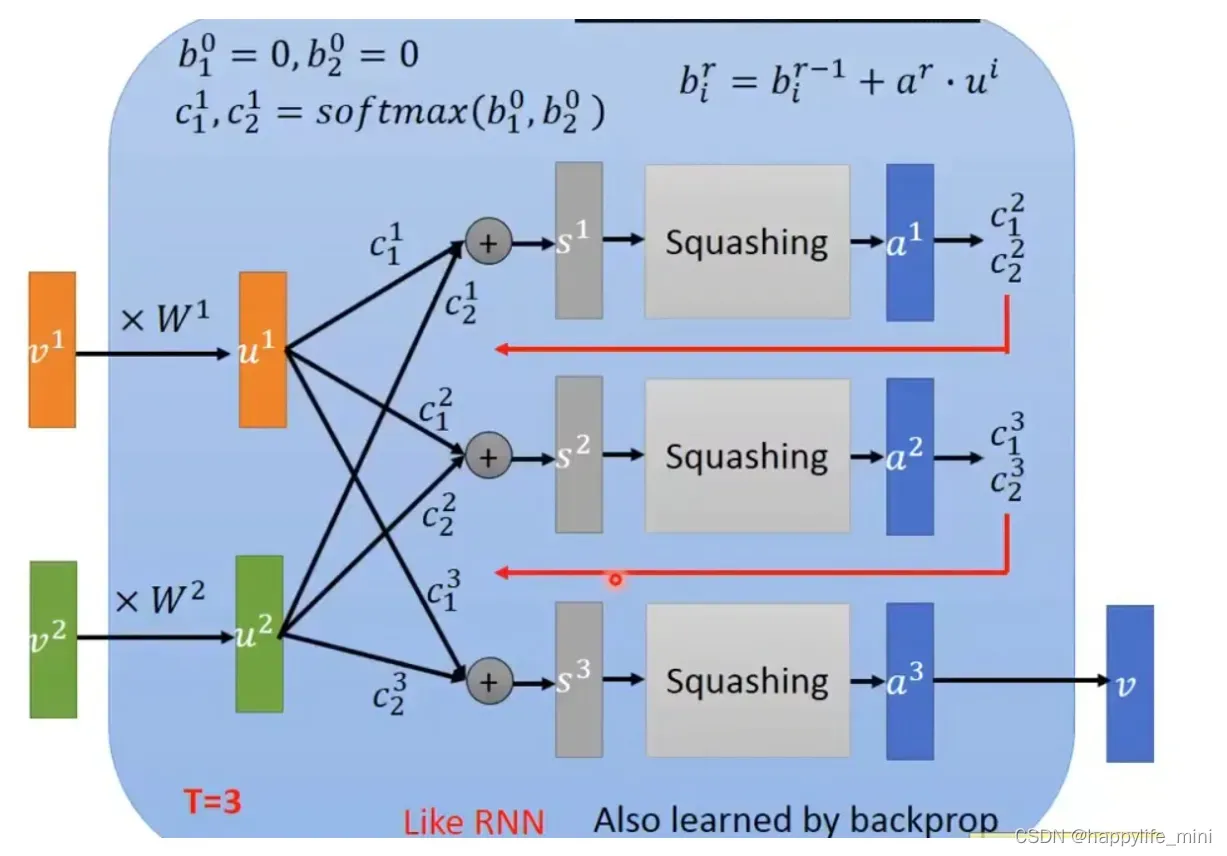
上图b1,b2是c1,c2的初始化,得到v=aT后进而进入下一轮计算c1,c2
如果a1和u1比较像,那么c1就会增加,因为a1点乘u1是具有方向的,比较像那么相乘会正并且较大,当加入b1之后再softmax也会比较大。
1.3.1 对路由系数c的理解
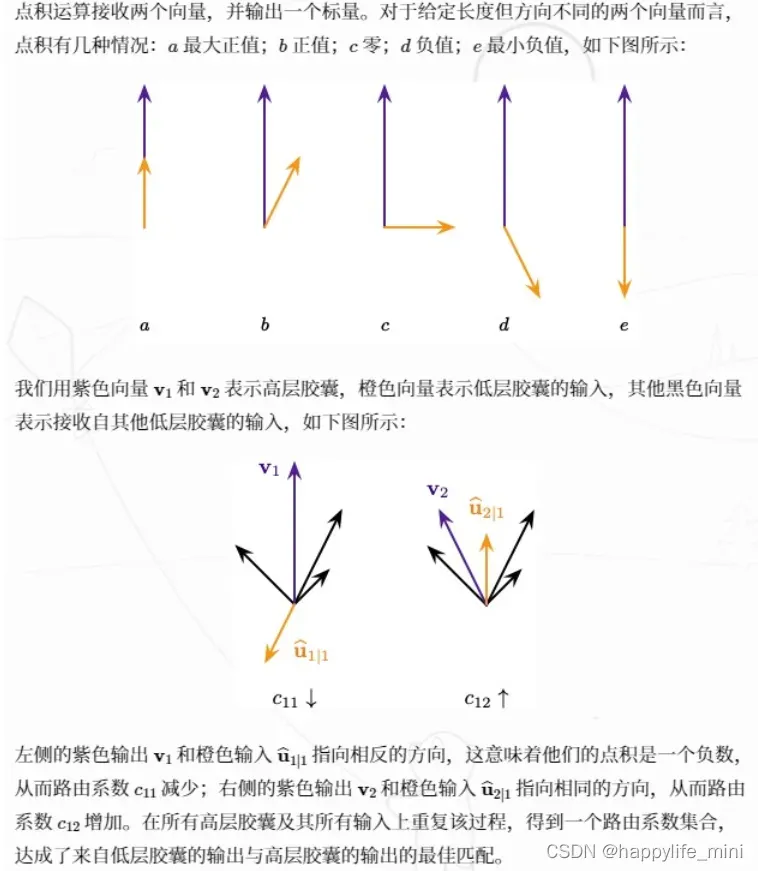
在路由(routing)过程中,下层胶囊将输入向量传送到上层胶囊。对于可以路由到的每个更高层的胶囊,下层胶囊通过将自己的输出乘上权重矩阵来计算预测向量。如果预测向量与上层胶囊的输出具有较大的标量积,则存在自顶向下的反馈,具有增加上层胶囊耦合系数,减小其他胶囊耦合系数的效果。类似于聚类或者剔除离群点。

可见,在投影后的每个空间中较为合群的(接近中心簇的)向量权重将会提高,而反之则降低。由此可以提取出所有向量的主要特征。
2.胶囊网络与cnn对比
两者最大的不同在于,胶囊网络中的神经元是一个整体,包含了特征状态的各类重要信息 , 比如长度、角度、方向等,而传统的CNN 里每个神经元都是独立的个体,无法刻画位置角度等信息 。这也就是为什么CNN通过数据增广的形式(对于同一个物体 ,加入不同角度、不同位置的图片进行训练),能够大大提高模型最后的结果 。
2.1 胶囊网络优点
当前,每种任务都需要一个不一样的CNN架构。比如分类里的ResNet,物体检测里的YOLO,实例分割里的Mask R-CNN等。恩,是的。我们已经见到了很多神奇的CNN,但是。
- CNN需要非常多的图片进行训练(或重复使用了已用海盖数据训练过的神经网络的一部分)。而 CapsNet便用少得多的训练数据就能泛化,且胶囊网络在MNIST数据集上达到业界最佳精度;
- CNN们并不能很好地应对模糊性,但CapsNet可以,动态路由算法也十分适合拥挤的场景,所以它能在非常拥挤的场景里也表现得很好(尽管它目前还需要解决背景图的问题);
- CNN会在池化层里丟失大是的信息,从而降低了空间分辨率,这就导致对于输入的微小变化, 其输出基本上是不变的。在诸如语义分割这样的场景里,这会是一个问题,因为细节信息必须要在网络里被保留。**现在,这一问题已经被通过在CNN里构建复杂的架构来恢复这些损失的信息所解决。**在CapNet里,细节的姿态信患(比如对象的准确位置、旋转、厚度、倾斜度、尺寸等)会在网络里被保存下来,不用先丟失再恢复。输入上微小的变化会带来输出上的小变化,信息被保存。这被称为==“等变的”==。这就让 CapsNet能使用一个简单和统一的架构来应対不同的视觉任务,且使得它非常使用于图像分区与目标检测处;
- 最后,CNN需要额外的组件来自动识别每个小部分属于哪个物体(例如这条腿属于这只羊)。而CapsNet路由树的结构映射着对象组件的层次结构关系,这样所有部件都与整体相连,则它可以给你这些部分的层次结构。
2.2 胶囊网络缺点
-
跟传统的CNN相比,当前的胶囊网络在实验效果手写数字识别上取得了更好的结果,但是训练过程却慢了很多,因为动态路由过程消耗资源,算法含有内部循环;
-
无论什么类型的对象,在给定位置永远只有一个胶囊,所以胶囊网络不可能检测出两个非常靠近的同一类型的对象,叫做拥挤现象;
-
虽然CapsNet在简单的数据集MNIST上表现出了很好的性能,但并未在较大的网络上表现较好,比如在更复杂的数据集如ImageNet、CIFAR-10上表现欠缺,这是因为在图像中发现的信息过多会使胶囊脱落;
总体来看,胶囊网络仍然处于研究和开发阶段,并且不够可靠,现在还没有很成熟的任务。
2.3 卷积神经网络
2.3.1 卷积神经网络概述
众所周知,卷积神经网络(CNN)在时序数据和图像数据相关的问题上具有较好的表现。一般而言,基本的CNN的结构可以表示为:[INPUT – CONV – RELU – POOL – FC],也就是==[输入-卷积-激活-池化-分类得分]==。模型通过重复的卷积层自底向上地捕捉图像特征,并根据特征进行分类。其中,池化层用于降低采样数,将一个邻域的极值(一般是最大值)取出用于代表区域特征。
2.3.2 卷积神经网络对于空间坐标系没有任何概念
假设我们只有两个向量胶囊:一个识别矩形的胶囊和一个识别三角形的胶囊,而且假定他们都能检测到相应的形状。
矩形和三角形可以是房子或是船的一部分。根据矩形的姿态,它们都是稍微向右旋转了一 点,那么房子和船也都会向右旋转了一点。根据三角形的姿态,这个房子几乎芫全是上下颠倒的,而船则是稍微向右旋转了一点。
注意在这里,整体的形状和整体与部分的关系都是在训练中学习的。**现在可以看到矩形和 三角形在船上的姿态是一致的,而在房子上的姿态则非常不一致。**因此,很有可能这里的矩形和三角形是同一 条船上的一部分,而房子上则不是。
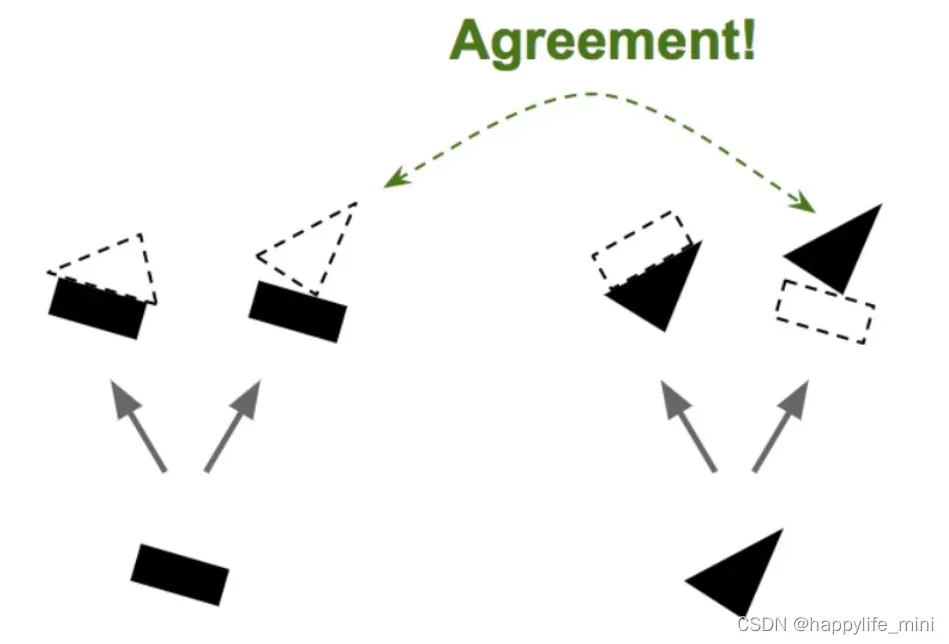
因为我们现在已经很有信心地知道矩形和三角形是船的一部分,所以把矩形和三角形的输出更多指向船的胶囊而更少指向房子的胶囊就顺理成章了。用这个方法,船的胶囊将会获得更多的有用输入倍号,而房子的胶囊则接收更少的噪音。对每个连接,按一致性路由算法会维护一个路由权重:它对于一致的会增加权重,而对于不一致的则降低权重。(更多详细描述见2.6 有关矩阵-三角形和房屋-船的解释)
2.3.3 pooling丢失大量信息
在最大池化过程中,很多重要的信息都损失了,因为只有最活跃的神经元会被选择传递到下一层,而这也是层之间有价值的空间信息丢失的原因。为了解决这个问题,Hinton提出使用一个叫做 “routing-by-agreement” 的过程。这意味着,**较为底层的特征(手、眼睛、嘴巴等)将只被传送到与之匹配的高层。**如果,底层特征包含的是类似于眼睛或者嘴巴的特征,它将传递到“面部”的高层,如果底层特征包含的是类似手指、手掌等特征,它将传递到“手”的高层。
这个完整的解决方案将空间信息编码为特征,同时使用动态路由(dynamic routing)。这由Geoffrey Hinton在NIPS2017提出,称为胶囊网络(Capsule Networks)。
CNN 最大的缺陷就是忽略了不同特征之间的相对位置,从而无法从图像中识别出姿势、纹理和变化。CNN 中的池化操作使得模型具有空间不变性,因此模型就不具备等变性。以下图为例,CNN 会把第一幅和第二幅识别为人脸,而将第三幅方向翻转的图识别为不是人脸。池化操作造成了部分信息的丢失,因此需要更多的训练数据来补偿这些损失。
2.4 不变性和等变性(invariance and equivariance )
如下图,左边显示不变性:虽然输入的1有些不一样,但是network学会无视差别,学会输出一样的东西;
右边显示等变性:希望network的输出完全反映现在看到的情况,比如1有翻转,那么输出希望包含翻转的特性;
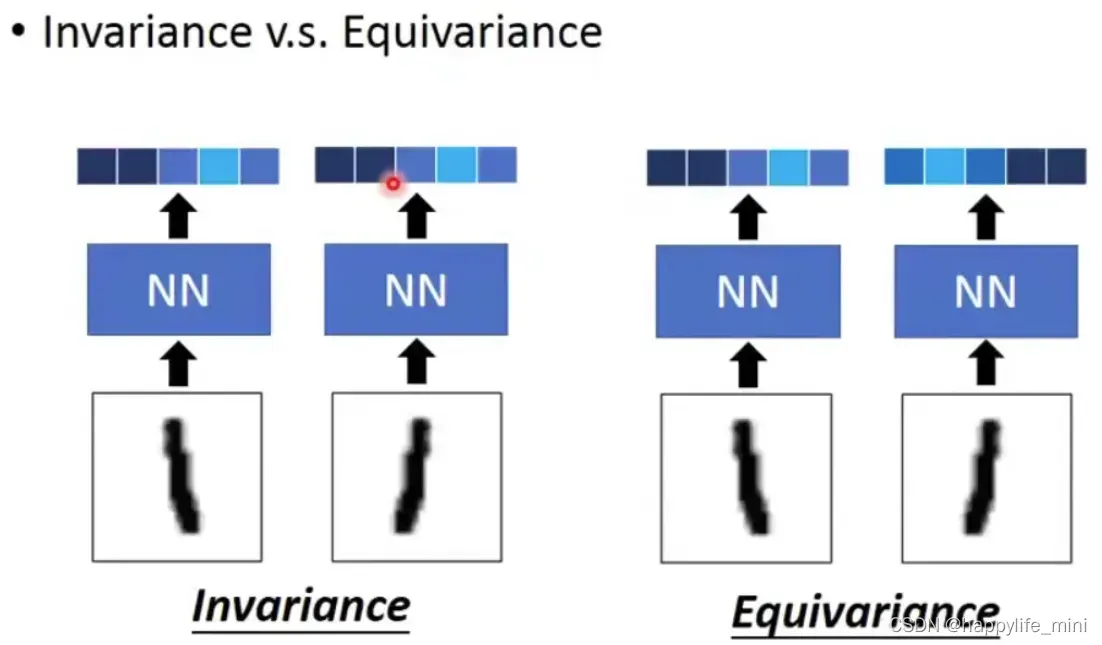
如下图,原来的cnn只能做到不变性,maxpooling机制只能做到不变性;而capsule可以做到不变性和等变性;

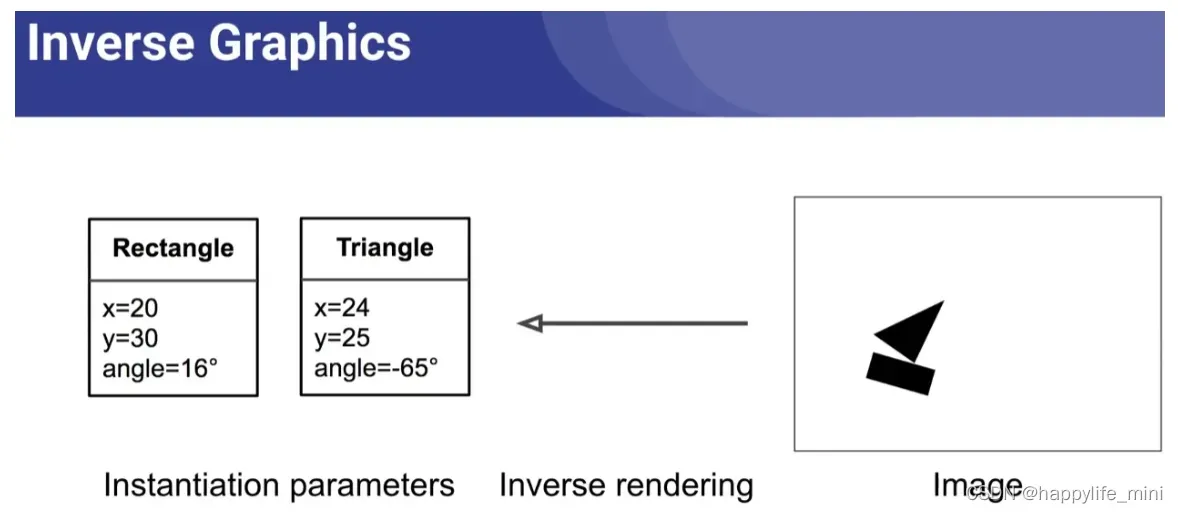
2.5 逆图形(inverse graphisc)
在计算机图形应用程序中,比如设计或者渲染,对象通常是通过参数设置来呈现的。而在胶囊网络中,恰恰相反,网络是要学习如何反向渲染图像——通过观察图像,然后尝试预测图像的实例参数。
胶囊网络通过重现它检测到的对象,然后将重现结果与训练数据中的标记示例进行比较来学习如何预测。通过反复的学习,它将可以实现较为准确的实例参数预测。
所以胶囊网路就是一种尝试演绎逆图形过程的神经网络

2.6 有关矩阵-三角形和房屋-帆船的解释
- 逆图形思想:通过图形得出预测图像实例参数
-
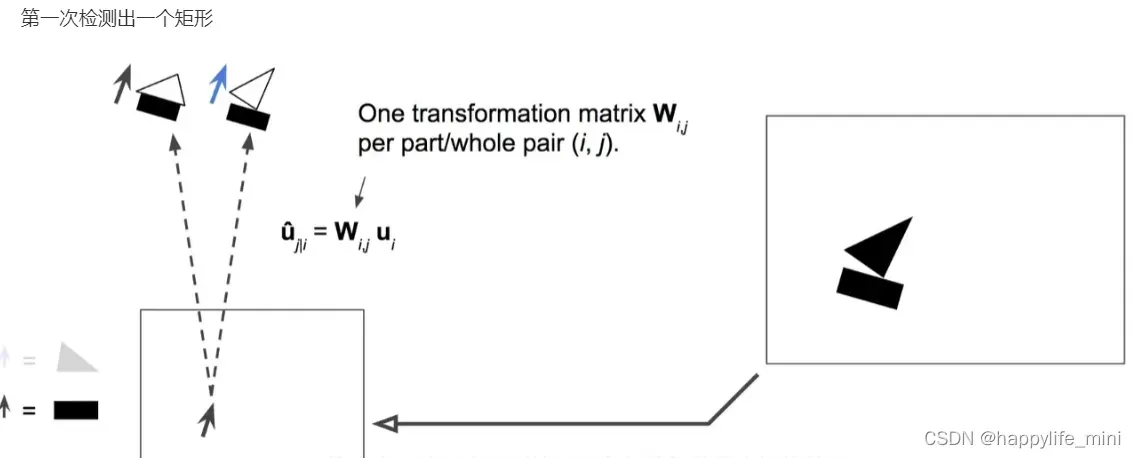
第一层胶囊会尝试预测第二层胶囊的输出
第一次检测出一个矩形
再检测出一个三角形
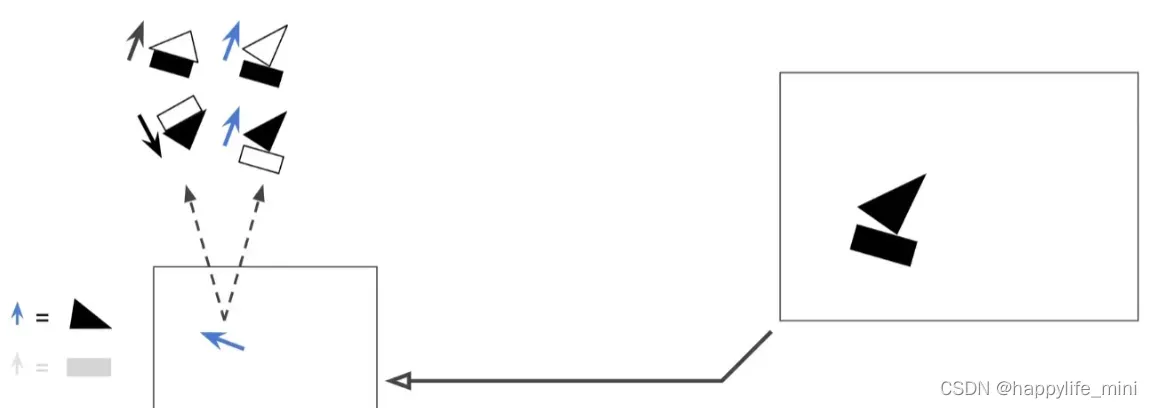
矩形-胶囊与三角形-胶囊非常认同彼此对帆船-胶囊的预测,所有矩形-胶囊与三角形-胶囊就只会与帆船-胶囊保持紧密的联系,而无需将自己的输出发送给其他胶囊,避免徒增噪音。这个方法叫做协议路由 “routing by agreement” , 这么做有几个好处:
1.因为胶囊的输出将只会被引导至合适的下一层胶囊,这些胶囊将会获得非常干净的输入信号,并且更加精确的确定对象的姿态;
2.通过审视激活的路径,将清楚的观察到组件的层次结构,因此非常精准地知道哪个组件属于哪个对象(类似矩形属于帆船,或者三角形同属帆船,等等)
3.最后,协议路由“routing by agreement”将会帮助解析那些拥有大量重叠再一起的对象所构成的一个拥挤的场景。
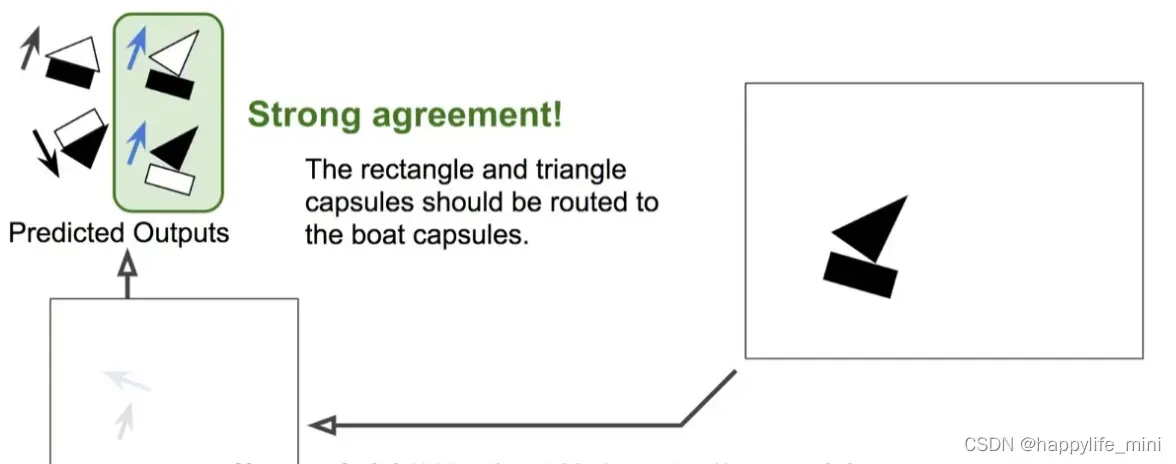
2.6.1 协议路由(routing by agreement)对拥挤的场景的预测
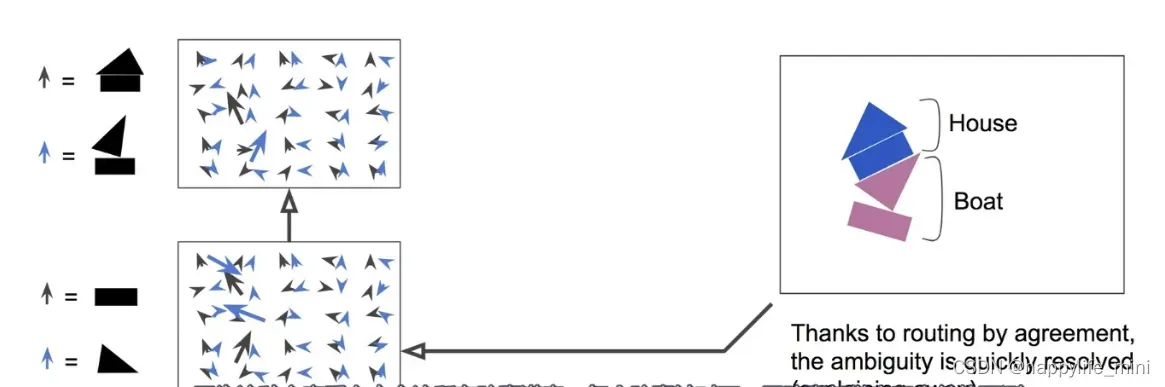
2.6.2 帆船案例中的解码器网络(decoder network)
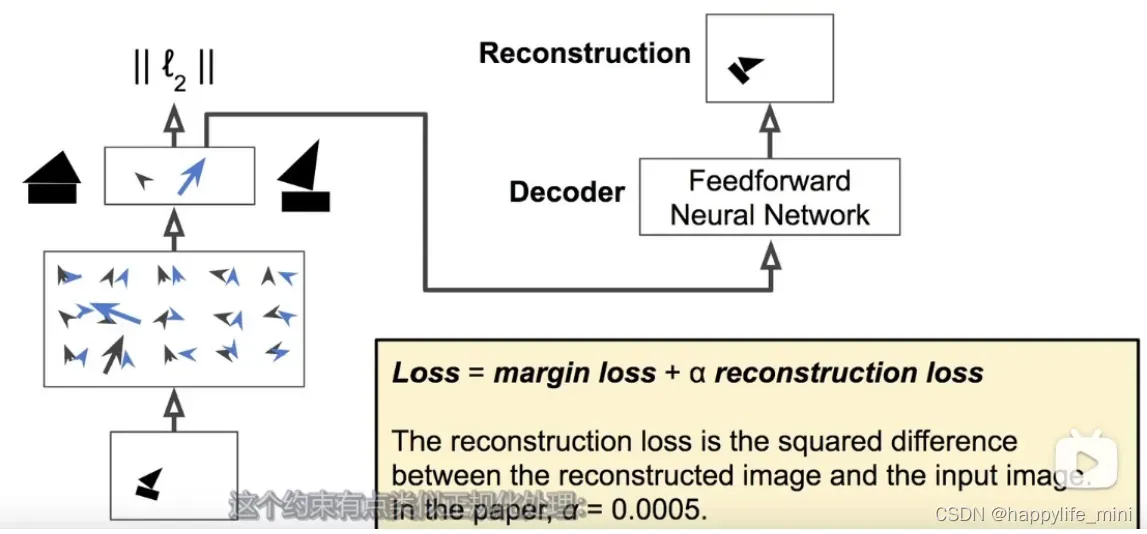
deocder network:
一个三层全连接层然后在输出层加上sigmoid激活函数(FC relu,FC relu,FC sigmoid),这个结构试图重建输入的图片,通过最小化重建图片与原始输入图片之间的方式来实现。损失函数采用的是margin loss,再加上重建的损失(因为这部分被过度压缩了,所以可以基本上当作是margin loss主宰了整个训练过程)采用重建损失的一个好处是这可以强制网路保留所有重建图像所需的信息,回到胶囊网路的顶层,也就是它的输入层。这个操作降低了过拟合的风险,并且提高了应用到新实例的泛化性能。
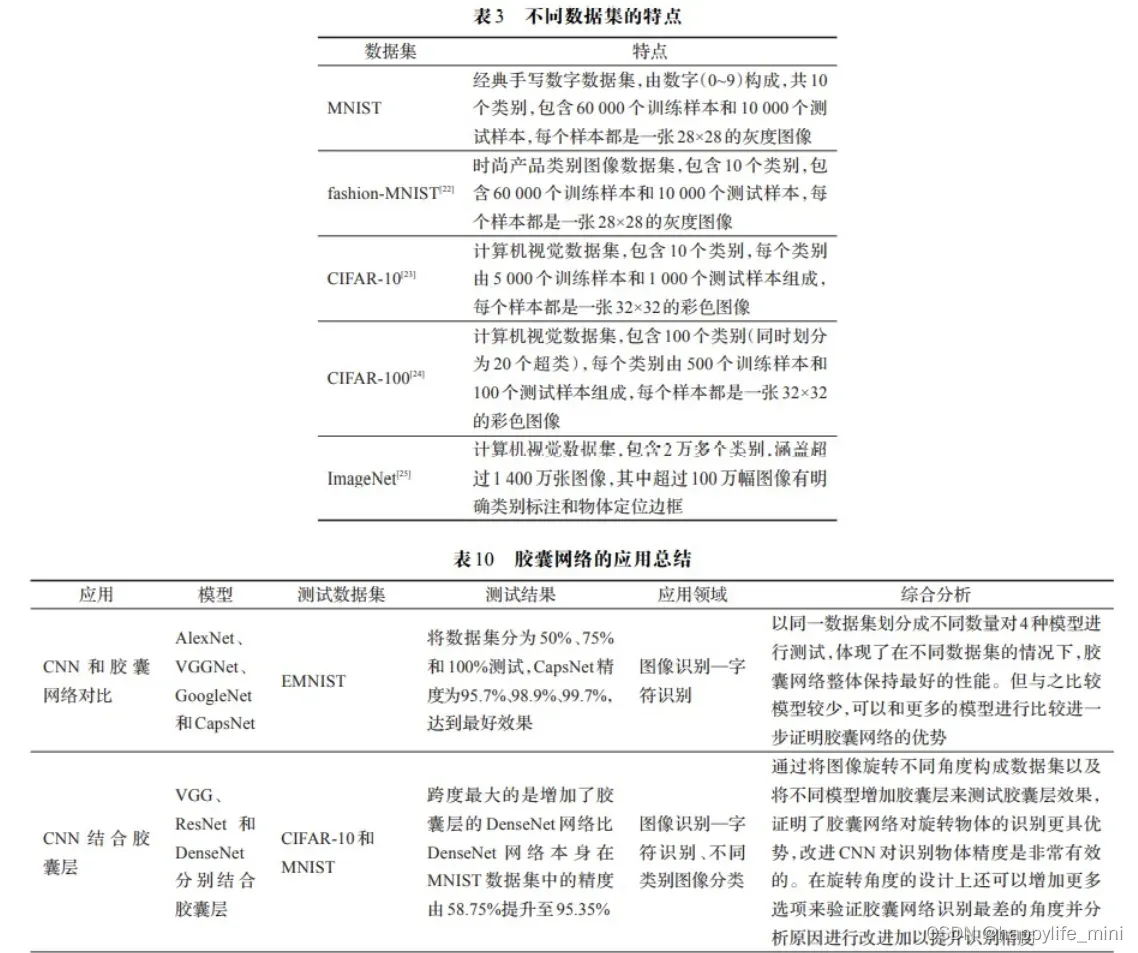
2.7 不同数据集的特点
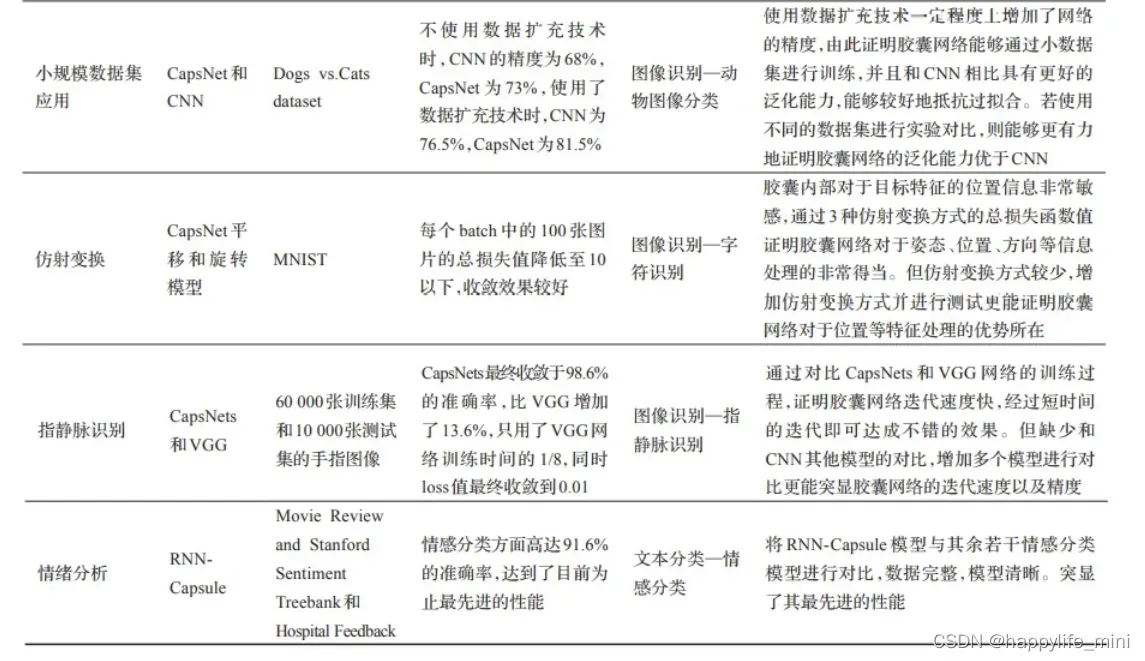
2.8 胶囊网络优化总结
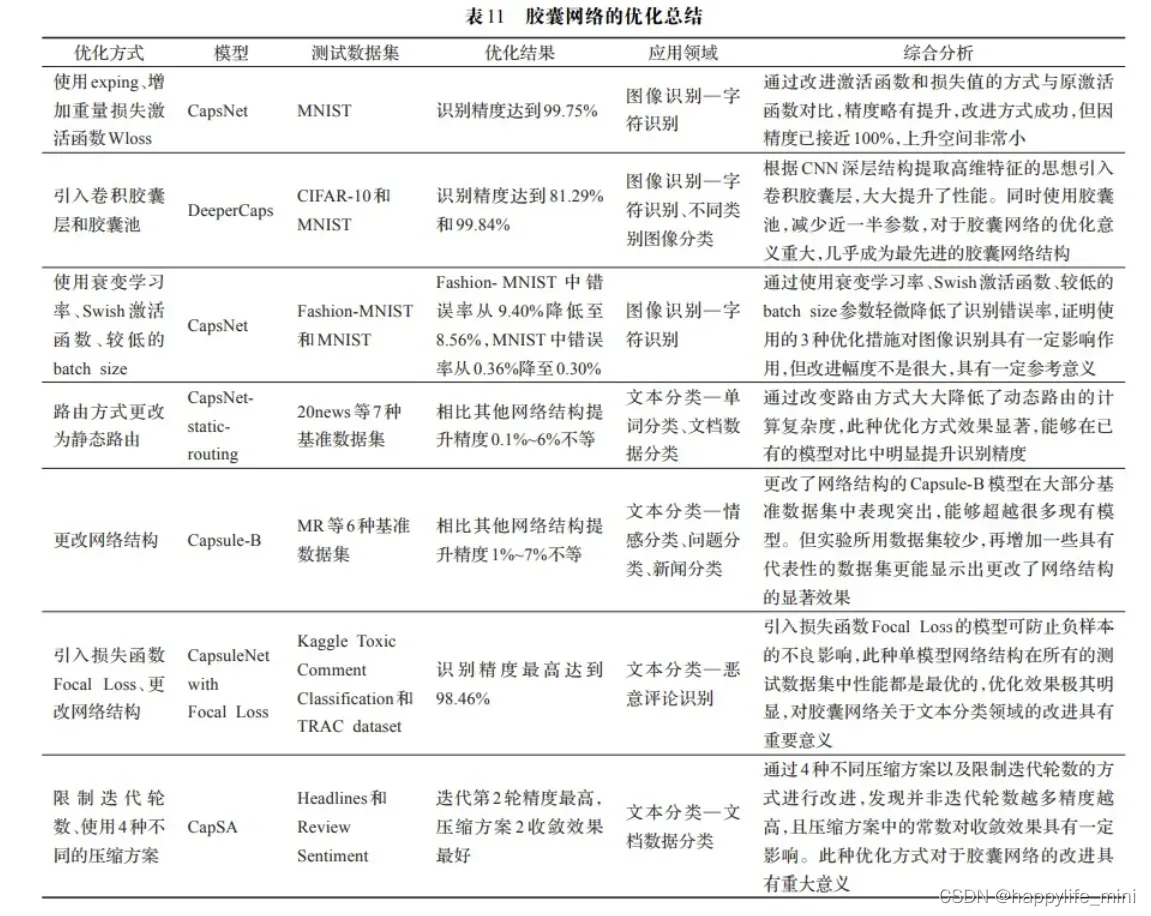
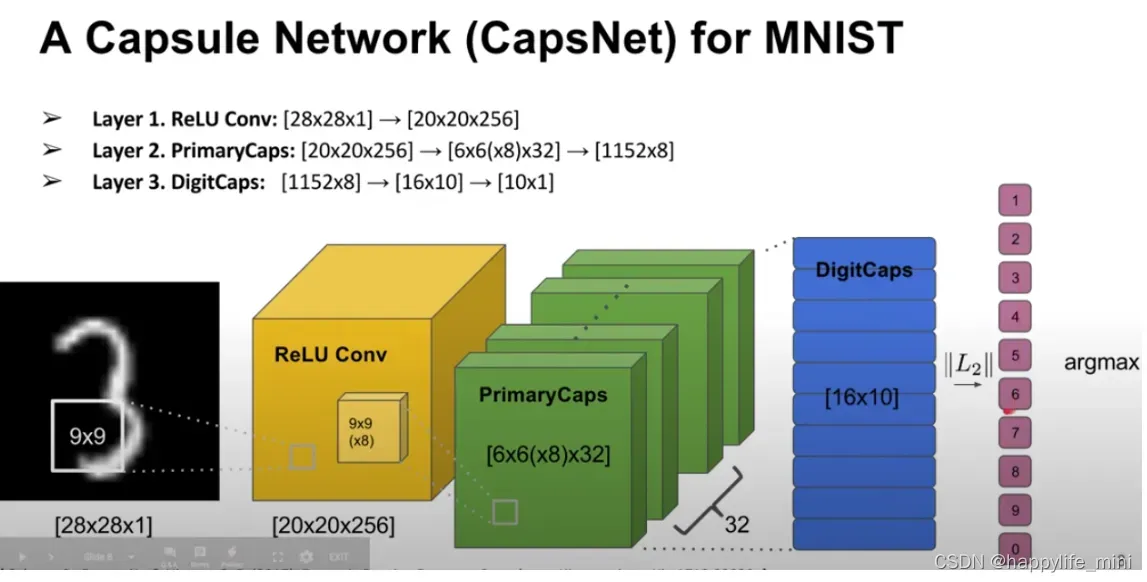
3.网络架构
3.1 总述
对于手写数字识别,普通神经网络在最后的输出层会输出十个神经元,而胶囊网络在output layer会输出是十个capsule,每一个capsule对应于一个数字——即V1的二范数表示识别为数字1的置信度,所有没有哪个向量的模型大于1,因为向量的模长代表概率。其中minimize reconstruction error为最小化重构误差(参考(63条消息) 2020李宏毅机器学习笔记——22.More about Auto-encoder(自动编码器)_CatcousCherishes的博客-CSDN博客)
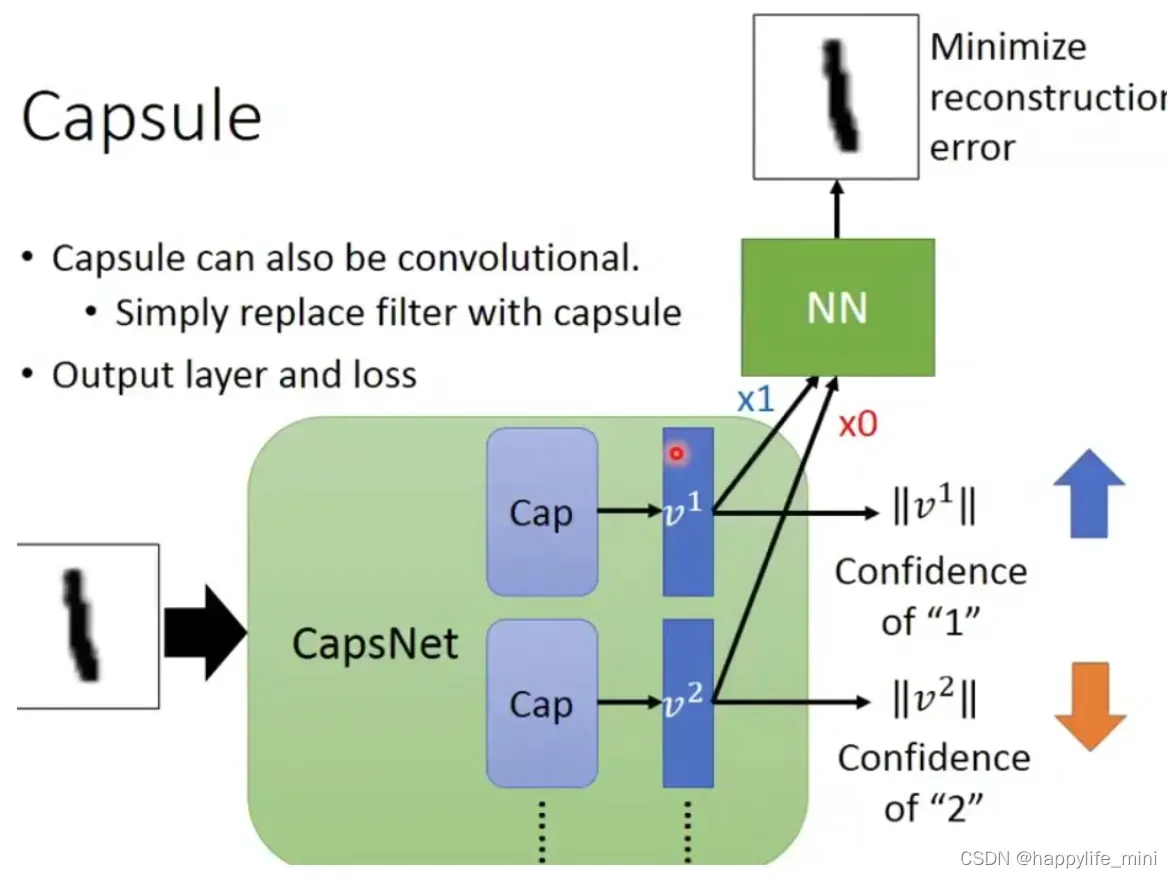
胶囊网络由 6 层神经网络构成,前 3 层是编码器,后 3 层是解码器:
-
CapsuleConvLayer(卷积层):in (128,1,28,28),out (128,256,20,20)
-
PrimaryCaps(主胶囊)层:
初始化:一个unit为stride=2的(128,256,9,9)卷积,in (128,256,20,20) out (128, 32, 6, 6) 一个self.units为8个unit 操作: 将数据x带入胶囊进行卷积,得到(128,8,32,6,6),reshape成(128,8,1152),在对1152这个数据维度进行squash操作,返回(128,8,1152) 最后得到的结果为(128,8,1152) -
DigitCaps(数字胶囊)层
初始化:初始化了一个可以计算梯度的参数W,w.shape=(1, 1152, 10, 16, 8) 操作:进行动态路由更新c值 -
第一全连接层
-
第二全连接层
-
第三全连接层
网络结构图:
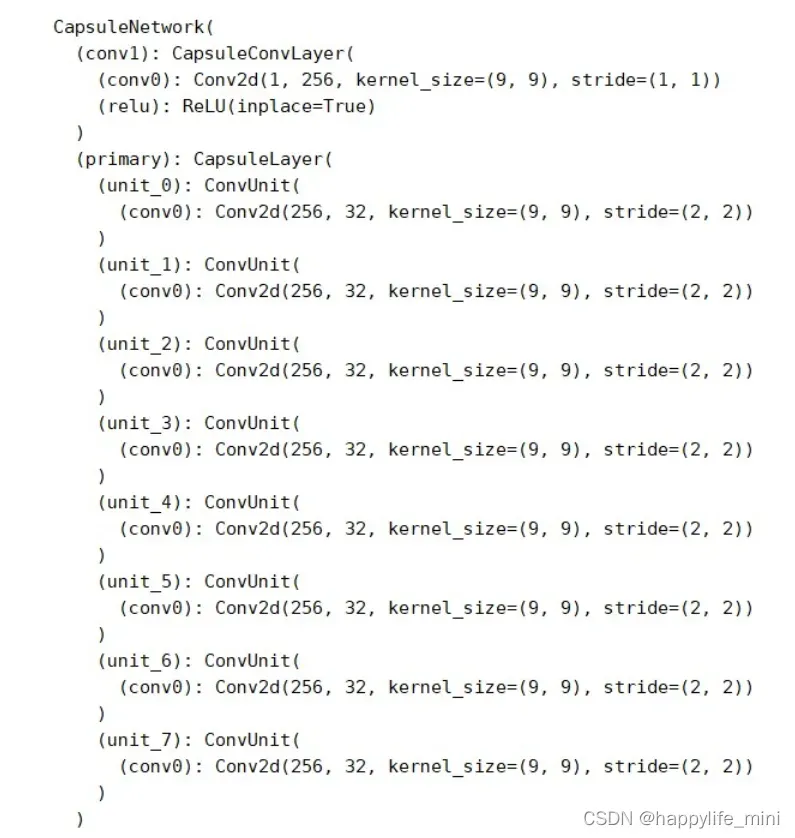

3.2 编码器
接下来我们来认识完整的胶囊网络模型(注:这个模型并不是胶囊思想的唯一实现,是作者在论文中对MSNIT手写数字识别的处理):

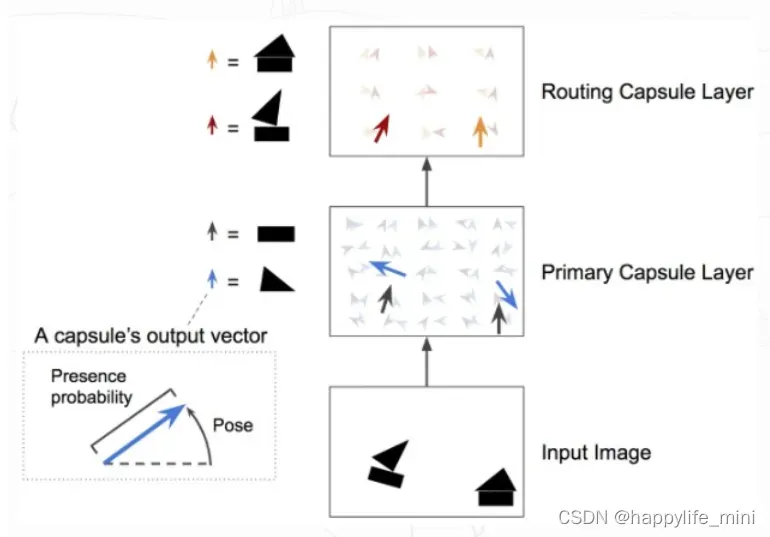
原论文中作者通过在MNIST上构造的模型验证了自己的想法。在这个网络中主要分成三层:
- 卷积层(ReLU Conv1),用于抽取底层特征。
- 初始胶囊层(Primary Caps),用于第二次卷积并初始化胶囊输入。
- 路由胶囊层(Digit Caps),用于编码空间信息并进行最终分类。
下面结合代码介绍具体每一层,以及胶囊网络的损失函数。
3.2.1 卷积层

卷积层代码如下

3.2.2 初始胶囊层
这里我个人认为论文中讲的不清楚,这里我看了一些别人的实现才知道原来不是平行地做32个深度为8的卷积……而是做输出通道为256的卷积,然后将输出分割为32乘8的向量!
注意:输入20乘20,kernel=9乘9,stride=2,则计算结果为 (20-9)/stride向下取整 +1

2. 进行squash激活操作
3.2.3 路由胶囊层

初始胶囊层和路由胶囊层的部分代码截图如下:

3.3 解码器
3.3.1 损失函数
胶囊网络的损失函数由两部分构成。
-
原本MNIST任务的最简单损失为结合单个标签的损失,但是作者更进一步,提出了重叠数字识别任务,目标可能包含多标签也可能只有一个标签,所以使用MarginLoss,用于惩罚False Negative和False Positive的识别结果。
-
为了证明胶囊网络能够保留特征的空间信息,设置一个重构图像的任务,并设置Reconstruction Loss,即使用一个decoder网络(如下图)进行还原,并使用MSELoss和原图像进行像素级地比较和计算损失,重建的损失是由重构图片与输入图片之间的方差构成。(用于计算空间信息,向量方向)
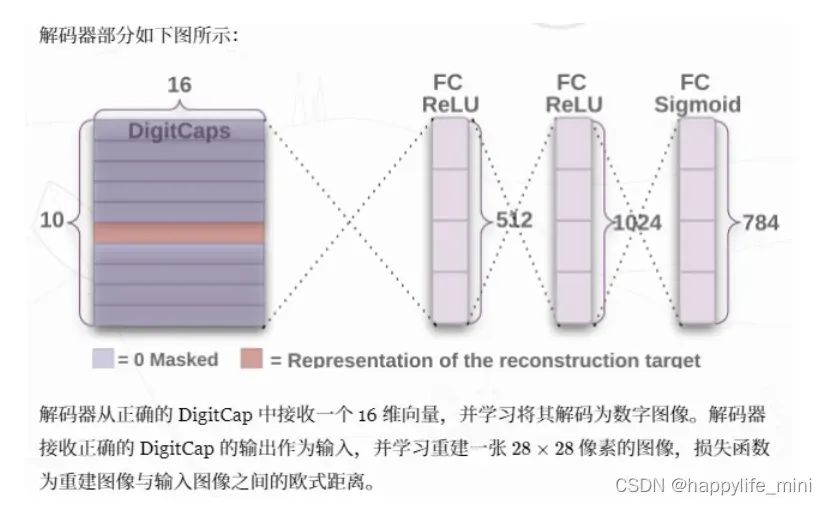
MarginLoss
这些16维的向量的长度将被用于计算Margin loss
MSELoss

整个胶囊层和损失函数的部分代码截图如下

3.4 完整模型(main函数)
代码太多了,我将链接放在这里
胶囊网络python-pytorch版本完整代码
3.5 在MNIST数据集上的表现
Baeskine为普通cnn网络,下面为capsNet动态路由的次数以及是否reconstruction在MNIST数据集上的错误率

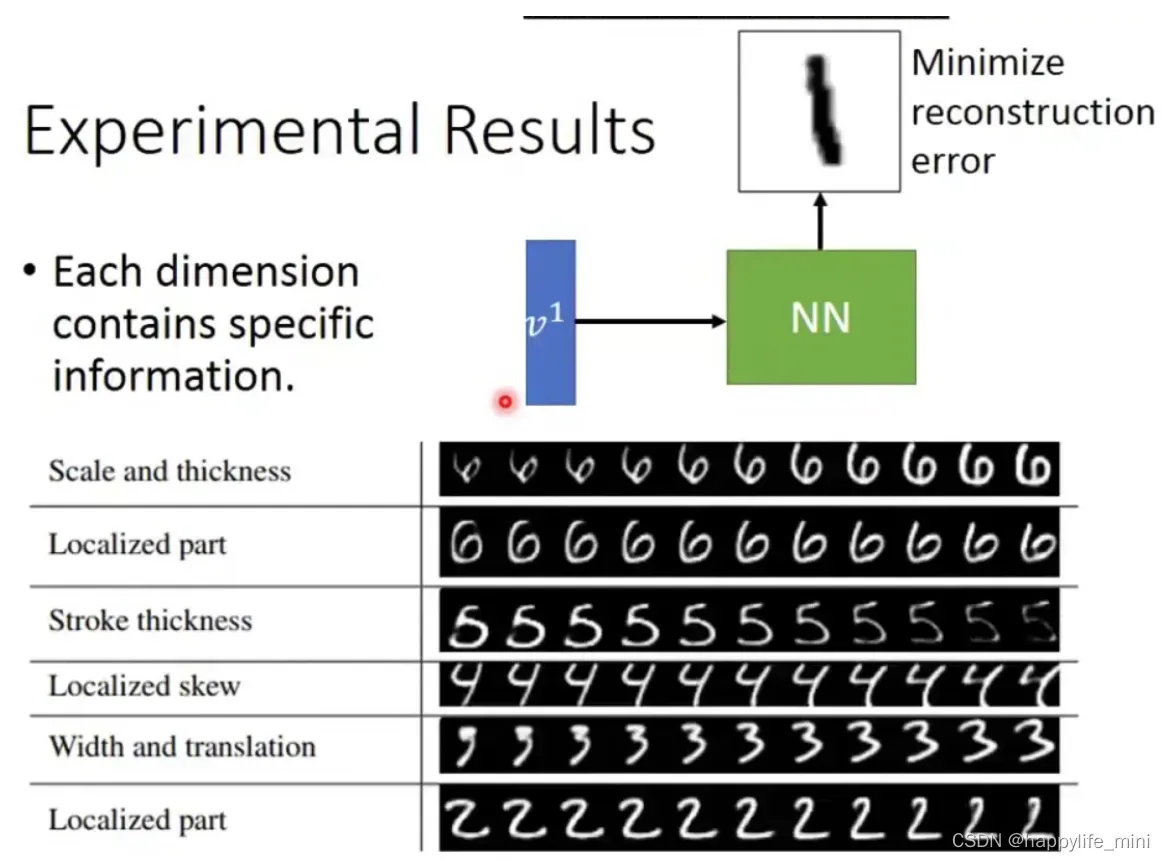
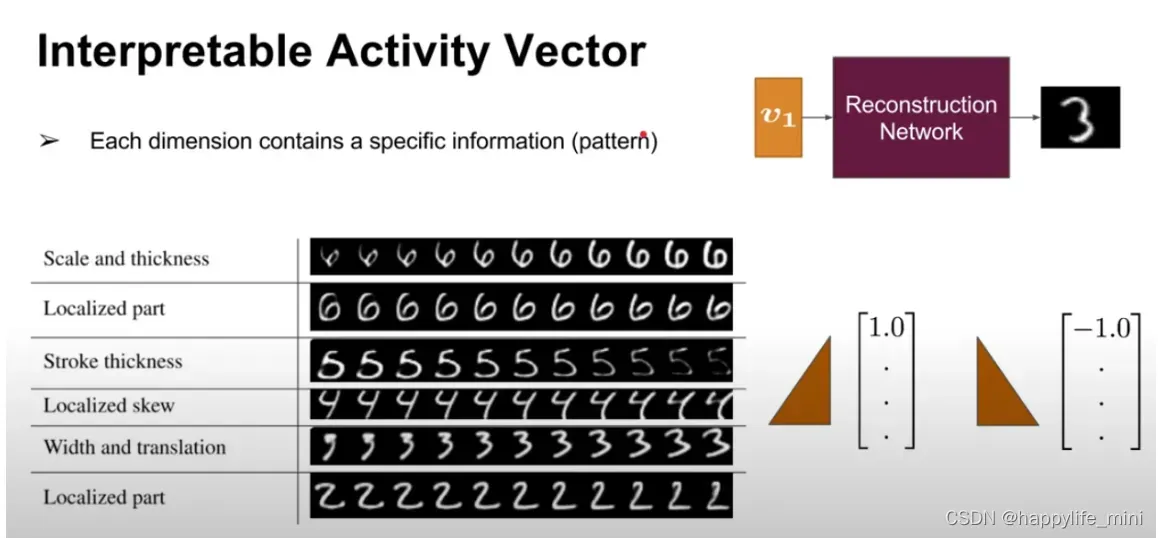
下图显示不同的维度代表了需要侦测pattern的某一种的特征,如笔画的粗细等
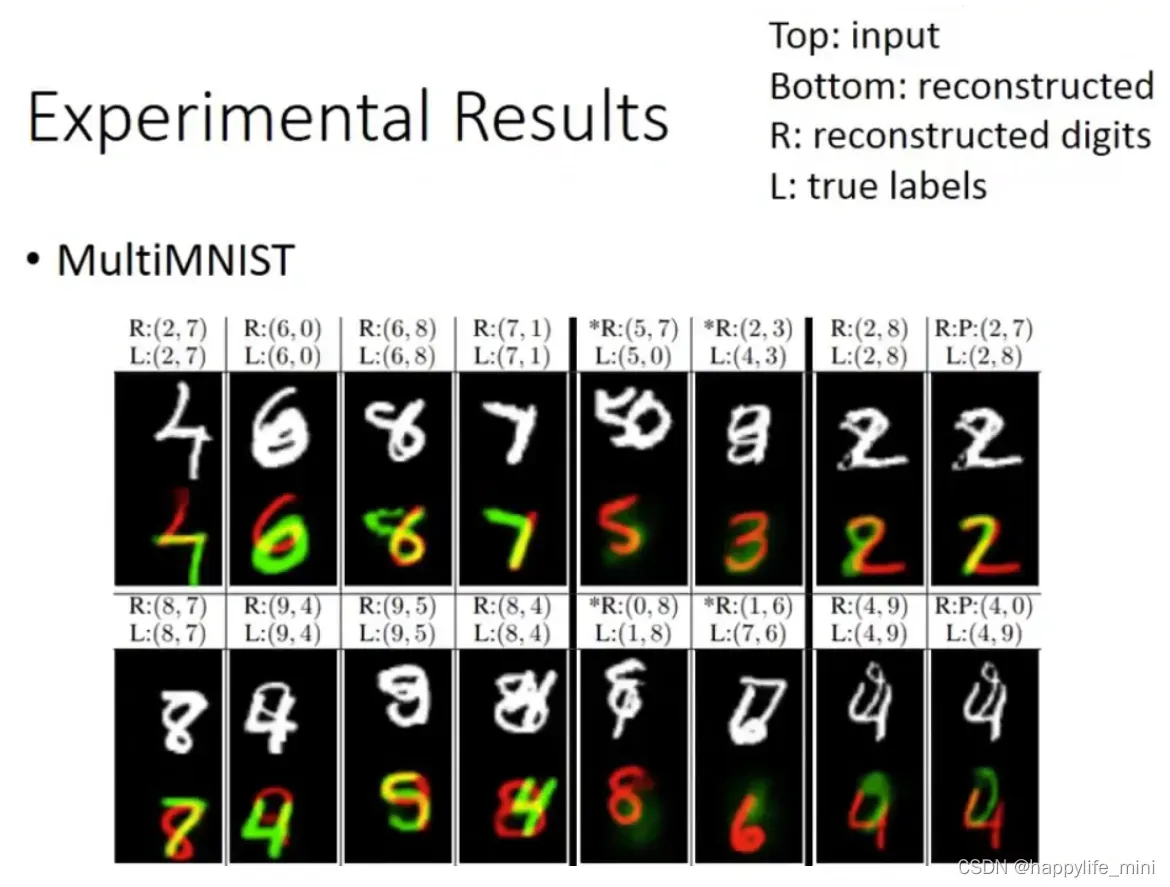
下图中在训练和测试的数据集中数字都有重叠(李宏毅:更好的情况是训练时未重叠,测试时有重叠,依旧可以识别出来)
4. 胶囊网络过去及未来发展
4.1 过去发展



4.2 未来发展
胶囊网络的研究目前是研究意义大于实际应用的意义,这是把脑科学和AI从神经元级别上升到电路层次来衔接的重要一步。在技术上有两个地方值得学习,一个是球形的嵌 入,第二个就迭代的图计算。
5.参考文献
https://zhuanlan.zhihu.com/p/130354532
胶囊神经网络
https://www.jiqizhixin.com/articles/2019-01-18-14
https://towardsdatascience.com/capsule-networks-the-new-deep-learning-network-bd917e6818e8
https://leovan.me/cn/2021/03/capsule-network/
https://arxiv.org/pdf/1710.09829.pdf
[5]朱应钊,胡颖茂,李嫚.胶囊网络技术及发展趋势研究[J].广东通信技术,2018,38(10):51-54+74.
[4]杨巨成,韩书杰,毛磊,代翔子,陈亚瑞.胶囊网络模型综述[J].山东大学学报(工学版),2019,49(06):1-10.
胶囊网络python-pytorch版本
胶囊网络概述(md原文件)
转载需注明
文章出处登录后可见!