机器学习中,有一门很有意思的提升模型accuracy的trick叫做集成学习,初次接触集成学习的时候我感觉这个方法很类似我们人类的团队,类似与我们在解决一个问题的时候需要团队不同的人各司其职一起解决,因为一个人再优秀能力也是有限的,往往一个优秀的算法只能解决我们这个问题的一方面,但是我们的问题一般都有多个方面都需要解决。就像我们做深度学习,可能我的数据集有好多种,但是lenet , vgg , alexnet对于不同的种类识别效果是不一样的,很多时候存在一种模型只对单一的几种识别效果好。
这时候,如果你一味地优化模型,你会发现模型的指标是无法提高的,因为你的模型往往只对几种类型的数据敏感,尤其是当数据类型很多的时候。这时候,我们需要使用集成学习来融合几个在不同类别中表现良好的模型。
事实上在kaggle竞赛和天池竞赛上融合模型的情况已经非常常见,在竞赛快结束提交模型的时候,排名前几的大佬一般都会去寻找同样排名靠前的人进行模型融合,一般来说模型融合的结果一定是优于单个模型的,这就是大家常说的宇宙的尽头一定是融合模型而不是单个模型。
在本篇博客中,我们将介绍融合模型的第一种方法,投票法。
为三个模型的预测结果投票。例如,如果三个模型中的两个预测第一个类型,一个预测第二个类型,那么我们将取最多,这类似于我们常见的少数服从多数的想法。 .如果三个模型的预测结果完全不同,那么我们选择第一个(一般设置为性能最好的模型)作为我们的预测结果。这是本期融合模型的核心思想。
接下来,我们简单解释一下代码:
首先导入我们需要的库
import torch
import torchvision
import torchvision.models
import numpy as np
from collections import Counter
from matplotlib import pyplot as plt
from tqdm import tqdm
from torch import nn
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
图像预处理操作:
具体函数意思可以可行百度,我这里是缩放成120*120进行处理
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(120),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((120, 120)), # 我这里是缩放成120*120进行处理的,您可以缩放成你需要的比例,但是不建议修改,因为会影响全连接成的输出
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}准备数据集,设置bach_size等参数:
自己的数据放在跟代码相同的文件夹下新建一个data文件夹,data文件夹里的新建一个train文件夹用于放置训练集的图片。同理新建一个val文件夹用于放置测试集的图片。
def main():
train_data = torchvision.datasets.ImageFolder(root = "./data/train" , transform = data_transform["train"])
traindata = DataLoader(dataset= train_data , batch_size= 32 , shuffle= True , num_workers=0 )
test_data = torchvision.datasets.ImageFolder(root = "./data/val" , transform = data_transform["val"])
train_size = len(train_data) #求出训练集的长度
test_size = len(test_data) #求出测试集的长度
print(train_size)
print(test_size)
testdata = DataLoader(dataset = test_data , batch_size= 32 , shuffle= True , num_workers=0 )是否使用GPU:
有GPU则调用GPU,没有的话就调用CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #如果有GPU就使用GPU,否则使用CPU
print("using {} device.".format(device))构建我们需要的三个模型:
当然这三种模型类型可以任意修改,可以扩展更多模型,修改代码。
首先是构建的Alexnet网络:
class alexnet(nn.Module): #alexnet神经网络 ,因为我的数据集是7种,因此如果你替换成自己的数据集,需要将这里的种类改成自己的
def __init__(self):
super(alexnet , self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 120, 120] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
nn.Flatten(),
nn.Dropout(p=0.5),
nn.Linear(512, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 7), #这里的7要修改成自己数据集的种类
)
def forward(self , x):
x = self.model(x)
return x
其次是Lenet网络:
class lenet(nn.Module): #Lenet神经网络
def __init__(self):
super(lenet , self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=5), # input[3, 120, 120] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # output[48, 27, 27]
nn.Conv2d(16, 32, kernel_size=5), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # output[128, 13, 13]
nn.Flatten(),
nn.Linear(23328, 2048),
nn.Linear(2048, 2048),
nn.Linear(2048, 7), #这里的7要修改成自己数据集的种类
)
def forward(self , x):
x = self.model(x)
return x
再者是Vgg网络:
class VGG(nn.Module): #VGG神经网络
def __init__(self, features, num_classes=7, init_weights=False): #这里的7要修改成自己数据集的种类
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(4608, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
if init_weights:
self._initialize_weights() # 参数初始化
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1)
# N x 512*7*7
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules(): # 遍历各个层进行参数初始化
if isinstance(m, nn.Conv2d): # 如果是卷积层的话 进行下方初始化
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight) # 正态分布初始化
if m.bias is not None:
nn.init.constant_(m.bias, 0) # 如果偏置不是0 将偏置置成0 相当于对偏置进行初始化
elif isinstance(m, nn.Linear): # 如果是全连接层
nn.init.xavier_uniform_(m.weight) # 也进行正态分布初始化
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0) # 将所有偏执置为0
def make_features(cfg: list):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512,
'M'],
}
def vgg(model_name="vgg16", **kwargs):
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
model = VGG(make_features(cfg), **kwargs)
return model
想看懂代码,关注扩展代码,看看代码的loss和accuracy是怎么计算的:
首先创建一个空数组,存储三个模型用于训练,并创建用于损失和准确度的数组。
设置训练需要的参数,epoch,学习率learning 优化器。损失函数。
mlps = [lenet1.to(device), alexnet1.to(device), VGGnet.to(device)] #建立一个数组,将三个模型放入
epoch = 5 #训练轮数
LR = 0.0001 #学习率,我这里对于三个模型设置的是一样的学习率,事实上根据模型的不同设置成不一样的效果最好
a = [{"params": mlp.parameters()} for mlp in mlps] #依次读取三个模型的权重
optimizer = torch.optim.Adam(a, lr=LR) #建立优化器
loss_function = nn.CrossEntropyLoss() #构建损失函数
train_loss_all = [[] , [] , []]
train_accur_all = [[], [], []]
ronghe_train_loss = [] #融合模型训练集的损失
ronghe_train_accuracy = [] #融合模型训练集的准确率
test_loss_all = [[] , [] , []]
test_accur_all = [[] , [] , []]
ronghe_test_loss = [] #融合模型测试集的损失
ronghe_test_accuracy = [] #融合模型测试集的准确
开始训练:
详细评论,主要是如何存储和计算最多的值(即我们上面的投票)
for i in range(epoch): #遍历开始进行训练
train_loss = [0 , 0 , 0] #因为三个模型,初始化三个0存放模型的结果
train_accuracy = [0.0 , 0.0 , 0.0] #同上初始化三个0,存放模型的准确率
for mlp in range(len(mlps)):
mlps[mlp].train() #遍历三个模型进行训练
train_bar = tqdm(traindata) #构建进度条,训练的时候有个进度条显示
pre1 = [] #融合模型的损失
vote1_correct = 0 #融合模型的准确率
for step , data in enumerate(train_bar): #遍历训练集
img , target = data
length = img.size(0)
img, target = img.to(device), target.to(device)
optimizer.zero_grad()
for mlp in range(len(mlps)): #对三个模型依次进行训练
mlps[mlp].train()
outputs = mlps[mlp](img)
loss1 = loss_function(outputs, target) # 求损失
outputs = torch.argmax(outputs, 1)
loss1.backward()#反向传播
train_loss[mlp] += abs(loss1.item()) * img.size(0)
accuracy = torch.sum(outputs == target)
pre_num1 = outputs.cpu().numpy()
# print(pre_num1.shape)
train_accuracy[mlp] = train_accuracy[mlp] + accuracy
pre1.append(pre_num1)
arr1 = np.array(pre1)
pre1.clear() # 将pre进行清空
result1 = [Counter(arr1[:, i]).most_common(1)[0][0] for i in range(length)] # 对于每张图片,统计三个模型其中,预测的那种情况最多,就取最多的值为融合模型预测的结果,即为投票
#投票的意思,因为是三个模型,取结果最多的
vote1_correct += (result1 == target.cpu().numpy()).sum()
optimizer.step() # 更新梯度
losshe= 0
for mlp in range(len(mlps)):
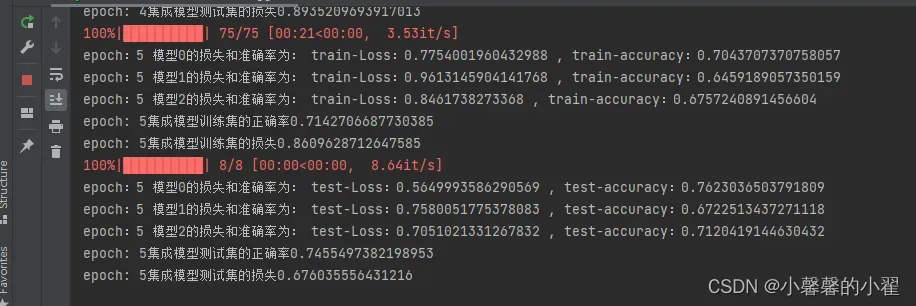
print("epoch:"+ str(i+1) , "模型" + str(mlp) + "的损失和准确率为:", "train-Loss:{} , train-accuracy:{}".format(train_loss[mlp]/train_size , train_accuracy[mlp]/train_size))
train_loss_all[mlp].append(train_loss[mlp]/train_size)
train_accur_all[mlp].append(train_accuracy[mlp].double().item()/train_size)
losshe += train_loss[mlp]/train_size
losshe /= 3
print("epoch: " + str(i+1) + "集成模型训练集的正确率" + str(vote1_correct/train_size))
print("epoch: " + str(i+1) + "集成模型训练集的损失" + str(losshe))
ronghe_train_loss.append(losshe)
ronghe_train_accuracy.append(vote1_correct/train_size)
开始测试:
三个模型都需要设置为测试状态,然后进行测试
test_loss = [0 , 0 , 0]
test_accuracy = [0.0 , 0.0 , 0.0]
for mlp in range(len(mlps)):
mlps[mlp].eval()
with torch.no_grad():
pre = []
vote_correct = 0
test_bar = tqdm(testdata)
vote_correct = 0
for data in test_bar:
length1 = 0
img, target = data
length1 = img.size(0)
img, target = img.to(device), target.to(device)
for mlp in range(len(mlps)):
outputs = mlps[mlp](img)
loss2 = loss_function(outputs, target)
outputs = torch.argmax(outputs, 1)
test_loss[mlp] += abs(loss2.item())*img.size(0)
accuracy = torch.sum(outputs == target)
pre_num = outputs.cpu().numpy()
test_accuracy[mlp] += accuracy
pre.append(pre_num)
arr = np.array(pre)
pre.clear() # 将pre进行清空
result = [Counter(arr[:, i]).most_common(1)[0][0] for i in range(length1)] # 对于每张图片,统计三个模型其中,预测的那种情况最多,就取最多的值为融合模型预测的结果,
vote_correct += (result == target.cpu().numpy()).sum()
losshe1 = 0
for mlp in range(len(mlps)):
print("epoch:"+ str(i+1), "模型" + str(mlp) + "的损失和准确率为:", "test-Loss:{} , test-accuracy:{}".format(test_loss[mlp] / test_size , test_accuracy[mlp] / test_size ))
test_loss_all[mlp].append(test_loss[mlp]/test_size)
test_accur_all[mlp].append(test_accuracy[mlp].double().item()/test_size )
losshe1 += test_loss[mlp]/test_size
losshe1 /= 3
print("epoch: " + str(i+1) + "集成模型测试集的正确率" + str(vote_correct / test_size ))
print("epoch: " + str(i+1) + "集成模型测试集的损失" + str(losshe1))
ronghe_test_loss.append(losshe1)
ronghe_test_accuracy.append(vote_correct/ test_size)
最后,要画曲线,我们只画融合模型的曲线。单独运行三个代码就可以单独训练和绘制三个模型的曲线。并保存三个模型,预测时同时读取三个模型进行预测。
绘制训练集loss和accuracy图 和测试集的loss和accuracy图。
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
# for mlp in range(len(mlps)):
plt.plot(range(epoch) , ronghe_train_loss,
"ro-",label = "Train loss")
plt.plot(range(epoch), ronghe_test_loss,
"bs-",label = "test loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.subplot(1, 2, 2)
plt.plot(range(epoch) , ronghe_train_accuracy,
"ro-",label = "Train accur")
plt.plot(range(epoch) , ronghe_test_accuracy,
"bs-",label = "test accur")
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()
torch.save(alexnet1.state_dict(), "alexnet.pth")
torch.save(lenet1.state_dict(), "lenet1.pth")
torch.save(VGGnet.state_dict(), "VGGnet.pth")
print("模型已保存")培训代码:
import torch
import torchvision
import torchvision.models
import numpy as np
from collections import Counter
from matplotlib import pyplot as plt
from tqdm import tqdm
from torch import nn
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(120),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((120, 120)), # 我这里是缩放成120*120进行处理的,您可以缩放成你需要的比例,但是不建议修改,因为会影响全连接成的输出
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
def main():
train_data = torchvision.datasets.ImageFolder(root = "./data/train" , transform = data_transform["train"])
traindata = DataLoader(dataset= train_data , batch_size= 32 , shuffle= True , num_workers=0 )
test_data = torchvision.datasets.ImageFolder(root = "./data/val" , transform = data_transform["val"])
train_size = len(train_data) #求出训练集的长度
test_size = len(test_data) #求出测试集的长度
print(train_size)
print(test_size)
testdata = DataLoader(dataset = test_data , batch_size= 32 , shuffle= True , num_workers=0 )
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #如果有GPU就使用GPU,否则使用CPU
print("using {} device.".format(device))
class alexnet(nn.Module): #alexnet神经网络 ,因为我的数据集是7种,因此如果你替换成自己的数据集,需要将这里的种类改成自己的
def __init__(self):
super(alexnet , self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 120, 120] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
nn.Flatten(),
nn.Dropout(p=0.5),
nn.Linear(512, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 7), #这里的7要修改成自己数据集的种类
)
def forward(self , x):
x = self.model(x)
return x
class lenet(nn.Module): #Lenet神经网络
def __init__(self):
super(lenet , self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=5), # input[3, 120, 120] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # output[48, 27, 27]
nn.Conv2d(16, 32, kernel_size=5), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # output[128, 13, 13]
nn.Flatten(),
nn.Linear(23328, 2048),
nn.Linear(2048, 2048),
nn.Linear(2048, 7), #这里的7要修改成自己数据集的种类
)
def forward(self , x):
x = self.model(x)
return x
class VGG(nn.Module): #VGG神经网络
def __init__(self, features, num_classes=7, init_weights=False): #这里的7要修改成自己数据集的种类
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(4608, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
if init_weights:
self._initialize_weights() # 参数初始化
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1)
# N x 512*7*7
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules(): # 遍历各个层进行参数初始化
if isinstance(m, nn.Conv2d): # 如果是卷积层的话 进行下方初始化
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight) # 正态分布初始化
if m.bias is not None:
nn.init.constant_(m.bias, 0) # 如果偏置不是0 将偏置置成0 相当于对偏置进行初始化
elif isinstance(m, nn.Linear): # 如果是全连接层
nn.init.xavier_uniform_(m.weight) # 也进行正态分布初始化
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0) # 将所有偏执置为0
def make_features(cfg: list):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512,
'M'],
}
def vgg(model_name="vgg16", **kwargs):
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
model = VGG(make_features(cfg), **kwargs)
return model
VGGnet = vgg(num_classes=7, init_weights=True) #这里的7要修改成自己数据集的种类
lenet1 = lenet()
alexnet1 = alexnet()
mlps = [lenet1.to(device), alexnet1.to(device), VGGnet.to(device)] #建立一个数组,将三个模型放入
epoch = 5 #训练轮数
LR = 0.0001 #学习率,我这里对于三个模型设置的是一样的学习率,事实上根据模型的不同设置成不一样的效果最好
a = [{"params": mlp.parameters()} for mlp in mlps] #依次读取三个模型的权重
optimizer = torch.optim.Adam(a, lr=LR) #建立优化器
loss_function = nn.CrossEntropyLoss() #构建损失函数
train_loss_all = [[] , [] , []]
train_accur_all = [[], [], []]
ronghe_train_loss = [] #融合模型训练集的损失
ronghe_train_accuracy = [] #融合模型训练集的准确率
test_loss_all = [[] , [] , []]
test_accur_all = [[] , [] , []]
ronghe_test_loss = [] #融合模型测试集的损失
ronghe_test_accuracy = [] #融合模型测试集的准确
for i in range(epoch): #遍历开始进行训练
train_loss = [0 , 0 , 0] #因为三个模型,初始化三个0存放模型的结果
train_accuracy = [0.0 , 0.0 , 0.0] #同上初始化三个0,存放模型的准确率
for mlp in range(len(mlps)):
mlps[mlp].train() #遍历三个模型进行训练
train_bar = tqdm(traindata) #构建进度条,训练的时候有个进度条显示
pre1 = [] #融合模型的损失
vote1_correct = 0 #融合模型的准确率
for step , data in enumerate(train_bar): #遍历训练集
img , target = data
length = img.size(0)
img, target = img.to(device), target.to(device)
optimizer.zero_grad()
for mlp in range(len(mlps)): #对三个模型依次进行训练
mlps[mlp].train()
outputs = mlps[mlp](img)
loss1 = loss_function(outputs, target) # 求损失
outputs = torch.argmax(outputs, 1)
loss1.backward()#反向传播
train_loss[mlp] += abs(loss1.item()) * img.size(0)
accuracy = torch.sum(outputs == target)
pre_num1 = outputs.cpu().numpy()
# print(pre_num1.shape)
train_accuracy[mlp] = train_accuracy[mlp] + accuracy
pre1.append(pre_num1)
arr1 = np.array(pre1)
pre1.clear() # 将pre进行清空
result1 = [Counter(arr1[:, i]).most_common(1)[0][0] for i in range(length)] # 对于每张图片,统计三个模型其中,预测的那种情况最多,就取最多的值为融合模型预测的结果,即为投票
#投票的意思,因为是三个模型,取结果最多的
vote1_correct += (result1 == target.cpu().numpy()).sum()
optimizer.step() # 更新梯度
losshe= 0
for mlp in range(len(mlps)):
print("epoch:"+ str(i+1) , "模型" + str(mlp) + "的损失和准确率为:", "train-Loss:{} , train-accuracy:{}".format(train_loss[mlp]/train_size , train_accuracy[mlp]/train_size))
train_loss_all[mlp].append(train_loss[mlp]/train_size)
train_accur_all[mlp].append(train_accuracy[mlp].double().item()/train_size)
losshe += train_loss[mlp]/train_size
losshe /= 3
print("epoch: " + str(i+1) + "集成模型训练集的正确率" + str(vote1_correct/train_size))
print("epoch: " + str(i+1) + "集成模型训练集的损失" + str(losshe))
ronghe_train_loss.append(losshe)
ronghe_train_accuracy.append(vote1_correct/train_size)
test_loss = [0 , 0 , 0]
test_accuracy = [0.0 , 0.0 , 0.0]
for mlp in range(len(mlps)):
mlps[mlp].eval()
with torch.no_grad():
pre = []
vote_correct = 0
test_bar = tqdm(testdata)
vote_correct = 0
for data in test_bar:
length1 = 0
img, target = data
length1 = img.size(0)
img, target = img.to(device), target.to(device)
for mlp in range(len(mlps)):
outputs = mlps[mlp](img)
loss2 = loss_function(outputs, target)
outputs = torch.argmax(outputs, 1)
test_loss[mlp] += abs(loss2.item())*img.size(0)
accuracy = torch.sum(outputs == target)
pre_num = outputs.cpu().numpy()
test_accuracy[mlp] += accuracy
pre.append(pre_num)
arr = np.array(pre)
pre.clear() # 将pre进行清空
result = [Counter(arr[:, i]).most_common(1)[0][0] for i in range(length1)] # 对于每张图片,统计三个模型其中,预测的那种情况最多,就取最多的值为融合模型预测的结果,
vote_correct += (result == target.cpu().numpy()).sum()
losshe1 = 0
for mlp in range(len(mlps)):
print("epoch:"+ str(i+1), "模型" + str(mlp) + "的损失和准确率为:", "test-Loss:{} , test-accuracy:{}".format(test_loss[mlp] / test_size , test_accuracy[mlp] / test_size ))
test_loss_all[mlp].append(test_loss[mlp]/test_size)
test_accur_all[mlp].append(test_accuracy[mlp].double().item()/test_size )
losshe1 += test_loss[mlp]/test_size
losshe1 /= 3
print("epoch: " + str(i+1) + "集成模型测试集的正确率" + str(vote_correct / test_size ))
print("epoch: " + str(i+1) + "集成模型测试集的损失" + str(losshe1))
ronghe_test_loss.append(losshe1)
ronghe_test_accuracy.append(vote_correct/ test_size)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
# for mlp in range(len(mlps)):
plt.plot(range(epoch) , ronghe_train_loss,
"ro-",label = "Train loss")
plt.plot(range(epoch), ronghe_test_loss,
"bs-",label = "test loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.subplot(1, 2, 2)
plt.plot(range(epoch) , ronghe_train_accuracy,
"ro-",label = "Train accur")
plt.plot(range(epoch) , ronghe_test_accuracy,
"bs-",label = "test accur")
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()
torch.save(alexnet1.state_dict(), "alexnet.pth")
torch.save(lenet1.state_dict(), "lenet1.pth")
torch.save(VGGnet.state_dict(), "VGGnet.pth")
print("模型已保存")
if __name__ == '__main__':
main()
预测代码:
需要先运行train代码,然后有生成的三个模型文件,才能进行预测这点需要注意。
import numpy as np
import torch
from PIL import Image
from torch import nn
from torchvision.transforms import transforms
from collections import Counter
image_path = "2.JPG"#相对路径 导入图片
trans = transforms.Compose([transforms.Resize((120 , 120)),
transforms.ToTensor()]) #将图片缩放为跟训练集图片的大小一样 方便预测,且将图片转换为张量
image = Image.open(image_path) #打开图片
#print(image) #输出图片 看看图片格式
image = image.convert("RGB") #将图片转换为RGB格式
image = trans(image) #上述的缩放和转张量操作在这里实现
#print(image) #查看转换后的样子
image = torch.unsqueeze(image, dim=0) #将图片维度扩展一维
classes = ["1" , "2" , "3" , "4" , "5" , "6" , "7" ] #预测种类
class alexnet(nn.Module): # alexnet神经网络 ,因为我的数据集是7种,因此如果你替换成自己的数据集,需要将这里的种类改成自己的
def __init__(self):
super(alexnet, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 120, 120] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
nn.Flatten(),
nn.Dropout(p=0.5),
nn.Linear(512, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 7), # 这里的7要修改成自己数据集的种类
)
def forward(self, x):
x = self.model(x)
return x
class lenet(nn.Module): # Lenet神经网络
def __init__(self):
super(lenet, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=5), # input[3, 120, 120] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # output[48, 27, 27]
nn.Conv2d(16, 32, kernel_size=5), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # output[128, 13, 13]
nn.Flatten(),
nn.Linear(23328, 2048),
nn.Linear(2048, 2048),
nn.Linear(2048, 7), # 这里的7要修改成自己数据集的种类
)
def forward(self, x):
x = self.model(x)
return x
class VGG(nn.Module):
def __init__(self, features, num_classes=10, init_weights=False):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(4608, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
if init_weights:
self._initialize_weights() #参数初始化
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1)
# N x 512*7*7
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules(): #遍历各个层进行参数初始化
if isinstance(m, nn.Conv2d): #如果是卷积层的话 进行下方初始化
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight) #正态分布初始化
if m.bias is not None:
nn.init.constant_(m.bias, 0) #如果偏置不是0 将偏置置成0 相当于对偏置进行初始化
elif isinstance(m, nn.Linear): #如果是全连接层
nn.init.xavier_uniform_(m.weight) #也进行正态分布初始化
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0) #将所有偏执置为0
def make_features(cfg: list):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def vgg(model_name="vgg16", **kwargs):
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
model = VGG(make_features(cfg), **kwargs)
return model
#以上是神经网络结构,因为读取了模型之后代码还得知道神经网络的结构才能进行预测
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #将代码放入GPU进行训练
print("using {} device.".format(device))
VGGnet = vgg(num_classes=7, init_weights=True) # 这里的7要修改成自己数据集的种类
lenet1 = lenet()
alexnet1 = alexnet()
VGGnet.load_state_dict(torch.load("VGGnet.pth", map_location=device))#训练得到的VGGnet模型放入当前文件夹下
lenet1.load_state_dict(torch.load("lenet1.pth", map_location=device))#训练得到的lenet模型放入当前文件夹下
alexnet1.load_state_dict(torch.load("alexnet.pth", map_location=device))#训练得到的alexnet模型放入当前文件夹下
mlps = [lenet1.to(device), alexnet1.to(device), VGGnet.to(device)] #建立一个数组,将三个模型放入
for mlp in range(len(mlps)):
mlps[mlp].eval()#关闭梯度,将模型调整为测试模式
with torch.no_grad(): #梯度清零
pre = []
length1 = image.size(0)
for mlp in range(len(mlps)):
outputs = mlps[mlp](image.to(device))#将图片打入神经网络进行测试
outputs = torch.argmax(outputs, 1)
pre_num = outputs.cpu().numpy()
pre.append(pre_num)
arr = np.array(pre)
print(arr)#查看三个模型输除的结果
pre.clear() # 将pre进行清空
result = [Counter(arr[:, i]).most_common(1)[0][0] for i in range(length1)] # 对于每张图片,统计三个模型其中,预测的那种情况最多,就取最多的值为融合模型预测的结果,
print(result) #选取最多的情况最为
# 对应找其在种类中的序号即可然后输出即为其种类
print(classes[result[0]-1])#因为他是输出的第几种情况,然后我们的列表是从0开始的因此,这里需要减一代码可拓展性很强,也可以替换成自己想要的模型进行融合,比如人resnet,googlenet均可。有兴趣的可以尝试拓展,欢迎评论交流,如何代码运行有问题可以在评论区指出来看到了会回复。
最后,如果觉得有用,请给个赞,万分感谢!
代码链接:https://pan.baidu.com/s/1zgdhEV6J8nOrS163Du9D6Q
提取码:z0vc
文章出处登录后可见!