一、概述
这篇文章做的是VQA。
在之前几个博客中,我们有提到在问题query对图像做attention的时候,有两种attention方式,一种是对feature map做attention,另一种是对Faster R-CNN抽取到的bounding box做attention。
对feature map做attention的模型可以参考以下几篇论文阅读笔记:
【多模态】《Stacked Attention Networks for Image Question Answering》论文阅读笔记
【多模态】《Where To Look: Focus Regions for Visual Question Answering》论文阅读笔记
【多模态】《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》论文阅读笔记
【多模态】《Visual7W: Grounded Question Answering in Images》论文阅读笔记
对bounding box做attention的模型可以参考:【多模态】《Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering》论文阅读笔记
而这篇文章集之前的两种方法于一体,既对feature map做了attention,又对bounding box做了attention,以共同关注与问题相关的自由形式(free-form,本文指的是feature map)图像区域和检测框,从而获得更准确的问题回答。
之所以提出这种方法,是因为基于feature map的attention和基于bounding box的attention各有优缺点:
- 对于基于free-form区域的方法,长短期记忆(LSTM)网络学习的问题特征和卷积神经网络(CNN)学习的图像特征通过乘法或连接进行融合每个图像空间位置的操作。free-form的注意力图是通过在融合的特征图上应用 softmax 非线性操作来获得的。由于对获得的注意力图没有限制,free-form的注意力区域能够同时关注全局视觉上下文和特定的前景对象以推断答案。然而,由于没有限制,自由形式的注意力区域有时可能会关注部分对象或不相关的上下文。例如,对于“你看到什么动物?”的问题,自由形式的区域注意力图可能会错误地只关注前景猫的一部分,并生成“狗”的答案。
- 另一方面,对于基于检测的注意方法,注意机制用于将问题与预先指定的检测框相关联,不是在所有图像空间位置上应用 softmax 操作,而是在所有检测框上计算操作。 因此,参与区域仅限于预先指定的检测框区域,并且这种与问题相关的区域对于回答有关前景对象的问题可能更有效。 然而,这样的限制也会对其他类型的问题造成挑战。 例如,对于“今天天气怎么样?”这个问题,天空中可能不存在检测框,导致无法回答这个问题。
为了更好地理解问题和图像内容及其关系,一个好的 VQA 算法需要识别全局场景属性、定位对象、识别对象属性、数量和类别以做出准确的推理。我们认为,上述两种参与机制提供了互补的信息,应该有效地集成在一个统一的框架中,以利用参与的自由形式区域和参与的检测区域。以上面提到的两个问题为例,关于动物的问题可以用基于检测的注意力图更有效地回答,而关于天气的问题可以用基于自由形式区域的注意力图更好地回答。
在本文中,我们提出了一种新颖的双分支深度神经网络,用于解决 VQA 问题,它结合了基于free-form区域和基于检测的注意机制。整个框架由两个注意力分支组成,每个分支都将问题与最相关的自由形式区域或输入图像中最相关的检测区域相关联。为了获得这两种区域更多与问题相关的注意力权重,我们建议使用乘法特征嵌入方案来学习输入问题、整个图像和检测框的联合特征表示。这种乘法方案在两个分支之间不共享参数,并且显示出比现有方法更稳健的回答性能。
二、模型
模型结构为:
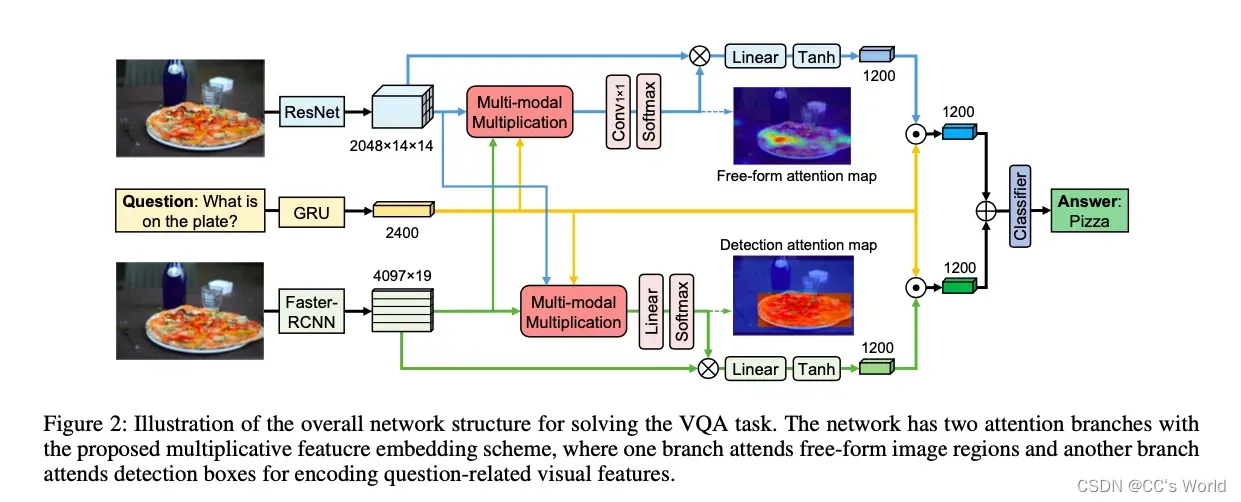
我们提出的 VQA 模型由两个共同注意分支组成,分别用于自由形式的图像区域和检测框。 在计算每种区域的注意力权重之前,通过乘法方法获得问题的联合特征表示、全图视觉特征和检测框视觉特征。 通过这种方式,从所有三个输入中学习每种类型区域的注意力权重。 重要的是,联合多模态特征嵌入对于每个分支都有不同的参数,这会导致更好的回答准确性。 来自两个分支的最终视觉特征与问题表示融合,然后相加以获得最终的问题图像嵌入。 采用多类线性分类器来获得最终的预测答案。
2.1 input feature encoding
2.1.1 Encoding whole-image features
我们利用 ImageNet 预训练的 ResNet-152来学习图像视觉特征。 ResNet 的输入图像大小调整为 448 × 448,最后一个卷积层的 2048 × 14 × 14 输出特征图用于编码整个图像的视觉特征 R ∈ ,其中 14 × 14 是它的空间大小,2048 是视觉特征通道的数量。
2.1.2 Encoding detection-box features
我们采用 Faster-RCNN 框架来获取输入图像中的目标检测框。 对于 Faster-RCNN 生成的所有目标提议及其相关检测分数,应用具有联合交集 (IoU) 0.3 的非最大抑制,并选择排名靠前的 19 个检测框作为检测框特征 对于我们的整体框架。 Faster-RCNN 的 fc7 层的 4096 维视觉特征与框的检测分数相连接,用于编码每个检测框的视觉特征。 令 D = [f1,····, f19] ∈ 表示排名靠前的 19 个检测框的视觉特征。
2.1.3 Encoding question features
采用门控循环单元(GRU)对问题特征进行编码。 给定一个问题 q = [q1 , …, qT ],其中 qt 是位置 t 的 one-hot 向量,T 是问题的长度。 我们通过线性变换 将每个单词 qt 转换为特征向量。 在每个时间步,单词特征向量 qt 被顺序输入 GRU 以对输入问题进行编码。
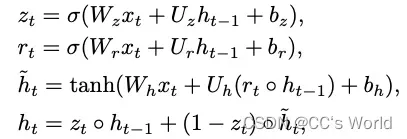
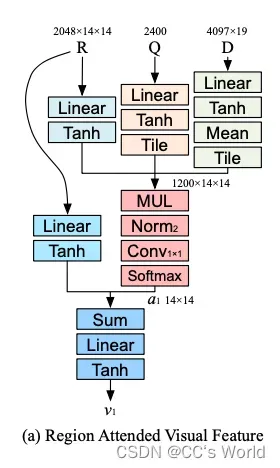
2.2 Learning to attend free-form region visual features with multiplicative embedding
我们提出的框架有两个分支,一个用于处理与问题相关的自由格式图像区域以学习整个图像特征,另一个用于处理检测框区域以学习与问题相关的检测特征。 对于每个注意力分支,它以问题特征 Q、整幅图像特征 R 和检测框特征 D 作为输入,并输出问题参与的视觉特征 v1 和 v2 用于问答。
我们的每个注意力分支都通过乘法特征嵌入方案融合了所有三种类型的输入特征,以利用来自输入的完整信息。如图所示:

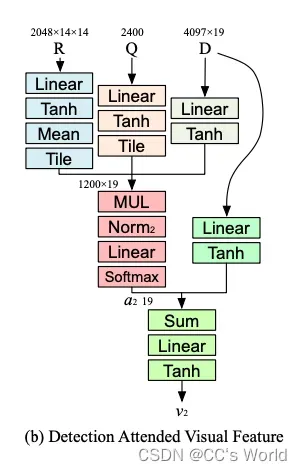
2.3 Learning to attend detection-box visual features with multiplicative embedding
2.4 Learning for answer prediction
给定参与的全图像特征 v1、参与的检测特征 v2 和输入问题特征 Q,问题-图像联合编码是通过转换后的问题特征和来自两个分支的参与特征的元素相乘获得的:

我们为两个分支选择不同的问题转换参数的原因是来自两个不同分支的参与视觉特征从输入图像中捕获了不同的信息。 一种来自有人参与的自由形式区域特征,能够捕捉场景的全局上下文和属性。 另一个来自有人参与的检测特征,能够提取有关前景对象的信息。
通过加法合并来自两个分支的问题图像编码后,训练线性分类器以进行最终答案预测:
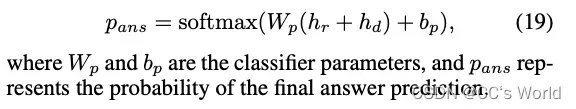
文章出处登录后可见!