目录
1.特征工程
我们在进行模型搭建之前,需要进行特征工程。
1.1.创建样本集和标签集
def create_new_dataset(dataset,seq_len):
#新建两个空列表,用来存放样本和标签数据
x=[]
y=[]
start=0#开始位置
end=dataset.shape(0)-seq_len#截止位置
#dataset.shape(0)表示样本数
for i in range(start,end):
sample=dataset[i,i+seq_len]
label=dataset[i+seq_len]
x.append(sample)
y.append(label)
return np.array(x),np.array(y)注:这里的seq_len表示时间窗口大小
1.2.划分训练集和测试集
def split_datatset(X,y,train_ratio=0.8):
#train_ratio训练集和测试集的比例
X_len=len(X)#样本长度
train_data_len=int(X_len*train_ratio)
X_train=X[:X_len*train_ratio]
y_train=y[:X_len*train_ratio]
X_test=X[X_len*train_ratio:]
y_test=y[X_len*train_ratio:]
return X_train,X_test,y_train,y_test1.3.创建批数据
def create_batch_data(X,y,batch_size=32,data_type=1):
#data_type=1:测试集,data_type=2:训练集
if(data_type==1):
dataset=tf.Dataset.from_tensor_slices(tf.constant(X),tf.constant(y))#将X,y以元组的形式封装起来
test_batch_data=dataset.batch(batch_size)#构建批数据
return test_batch_data
else:
dataset=tf.Dataset.from_tensor_slices(tf.constant(X),tf.constant(y))
train_batch_data=dataset.cache(),shuffle(1000).batch(batch_size)
return train_batch_data
#cache():训练集储存到内存中,提高运行速度
#shuffle(1000):打乱batch2.模型训练
2.1.模型搭建
#导包
import tensorflow as tf
from tensorflow.keras import Sequential,layers,utils
model=keras.Sequential()
model.add(
keras.layers.LSTM(units=8,input_shape=(seq_len,features))
)
model.add(keras.layers.Dense(units=1))#定义全连接层2.2.定义回调(权重文件)
#定义checkpoint,保存权重文件
file_path='文件名'
checkpoint_callback=tf.keras.callbacks.ModelCheckpoint(filepath=file_path,
monitor='loss',
mode='min',
save_best_only=True,
save_weights_only=True
)2.3.模型编译
model.compile(optimizer='adam',loss='mae')2.4.模型训练
history=model.fit(train_batch_data,
epochs=10,
validation_data=test_batch_data,
callbacks=[checkpoint_callback]#可以看作是一个回调函数
)3.模型验证
test_pred=model.predict(X_test.verbose=1)
#模型评价
score=r2_score(y_test,test_pred)或者我们也可以将结果进行可视化
plt.figure(figsize=(16,8))
plt.plot(y_test,label='True_label')
plt.plot(test_pred,label='Pred label')
plt.title('True vs Pred')
plt.legend(loc='best')
plt.show()4.模型预测
这里我想预测20个数据点,就可以设置times=20
sample:test中的最后一个样本(时间步长为20的话,就是20个点组成的数据)
def predict_next(model,sample.times=20):
temp=list(sample[:,0])
for i in range(times):
sample=sample.reshape(1,seq_len,1)#转化为符合LSTM输入格式
prep=model.predict(sample)
value=prep.tolist()[0][0]#ndarray->list->value
temp.append(value)
sample=np.array(temp[i+1:i+seq_len+1])#滑动窗口,并注意转化成ndarray类型
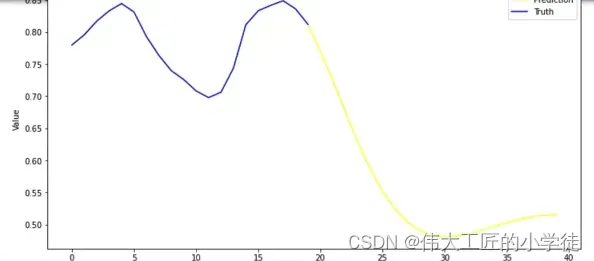
return temp我们看到下图,蓝色部分为真实值,黄色部分为预测值
文章出处登录后可见!
已经登录?立即刷新