目录

Abstract.
Super-Resolution Generative Adversarial Network (SR–GAN)是一项开创性的工作,能够在单幅超分辨率图像中生成真实的纹理。然而,幻觉中的细节往往伴随着令人不快的伪影 unpleasant artifacts。为了进一步提高视觉质量,我们深入研究了SRGAN的三个关键组成部分——网络结构,对抗性损失adversarial loss和感知损失perceptual loss,并对它们进行了改进,得到了增强型Enhanced SRGAN(ESRGAN)。特别地,我们引入了没有批量归一化的残差密集块Residual-in-Residual Dense Block(RRDB)作为基本的网络构建单元。此外,我们借用相对论性relativistic GAN[2]的思想,让鉴别器预测相对真实度,而不是绝对值。最后,我们利用激活前的特征来改善感知损失,为亮度一致性和纹理恢复提供更强的监督。得益于这些改进,所提出的ESRGAN以比SRGAN更真实和自然的纹理获得了持续更好的视觉质量,并在PIRM2018-SR挑战[3]中获得了第一名【我们在第三区获得第一名,获得最佳感知指数】。
该代码在网址https://github.com/xinntao/ESRGAN。
1 Introduction
单图像超分辨率(SISR)作为一个基本的低水平视觉问题,在研究界和人工智能公司中引起了越来越多的关注。SISR的目标是从单个低分辨率(LR)图像中恢复高分辨率(HR)图像。自从Dong等人[4]提出SRCNN的先驱工作以来,深度卷积神经网络(CNN)方法带来了繁荣的发展。各种网络体系结构的设计和训练策略不断地提高了SR的性能,特别是峰值信噪比(PSNR)值[5,6,7,1,8,9,10,11,12]。然而,这些面向PSNR的方法倾向于输出过度平滑的结果,没有足够的高频细节,因为PSNR度量根本不同意人类观察者[1]的主观评价。
目前已经提出了几种感知驱动的方法来提高SR结果的视觉质量。例如,提出了感知损失[13,14]来优化特征空间而不是像素空间的超分辨率模型。[1,16]将生成对抗网络[15]引入到SR中,以鼓励网络支持那些看起来更像自然图像的解决方案。进一步结合语义图像先验来改善恢复的纹理细节[17]。SRGAN[1]是追求视觉上令人愉悦的结果的里程碑之一。基本模型由残差块[18]建立,并在GAN框架中使用感知损失进行优化。与所有这些技术相比,SRGAN比面向PSNR的方法显著提高了重建的整体视觉质量。
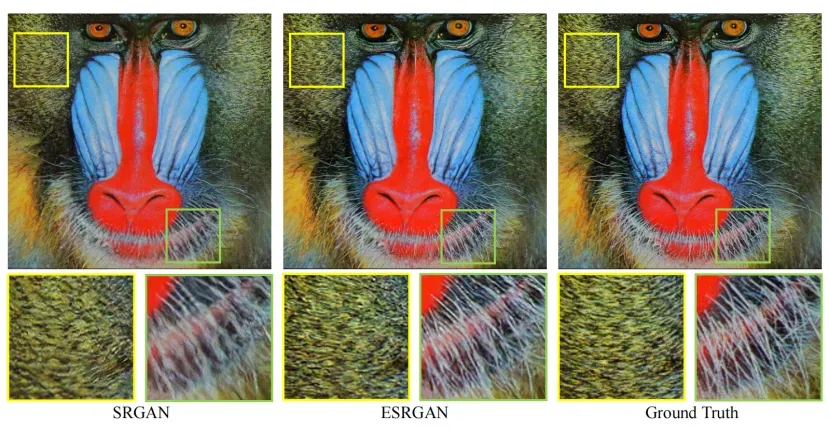
图1:×4对SRGAN的超分辨率结果【我们使用原始的SRGAN[1]论文发布的结果。https://twitter.app.box.com/s/lcue6vlrd01ljkdtdkhmfvk7vtjhetog】,提出的ESRGAN和地面真相。ESRGAN在清晰度和细节方面都优于SRGAN。
然而,SRGAN结果与地面真实值(GT)图像之间仍然存在明显的差距,如图1所示。在本研究中,我们回顾了SRGAN的关键组成部分,并从三个方面对该模型进行了改进。首先,我们通过引入残差密集块(RDDB)来改进网络结构,它具有更高的容量和更容易训练。我们还删除了在[20]中的批处理归一化(BN)[19]层,并使用残差缩放residual scaling[21,20]和更小的初始化来促进训练一个非常深的网络。其次,我们使用相对论平均GAN Relativistic average GAN (RaGAN)[2]改进了鉴别器,它学习判断“一幅图像是否比另一幅图像更真实”,而不是“一幅图像是真实的还是假的”。我们的实验表明,这种改进有助于发电机恢复更真实的纹理细节。第三,我们提出了一种改进的感知损失,而是在激活前而不是激活后。我们根据经验发现,调整后的感知损失提供了更清晰的边缘和视觉上更令人愉悦的结果,将会在Sec. 4.4说。大量的实验表明,增强的SRGAN,称为ESRGAN,在锐度sharpness和细节details方面始终优于最先进的方法(见图1和图7)。
我们采用ESRGAN的一个变体来参加PIRM-SR挑战[3]。这一挑战是第一个基于[22]以感知质量感知方式评估表现的SR竞争,作者声称扭曲和感知质量是不一致的。感知质量采用Ma得分[23]和NIQE[24]的非参考指标,即感知指数=1/2((10−Ma)+NIQE)。较低的感知指数代表较好的感知质量。
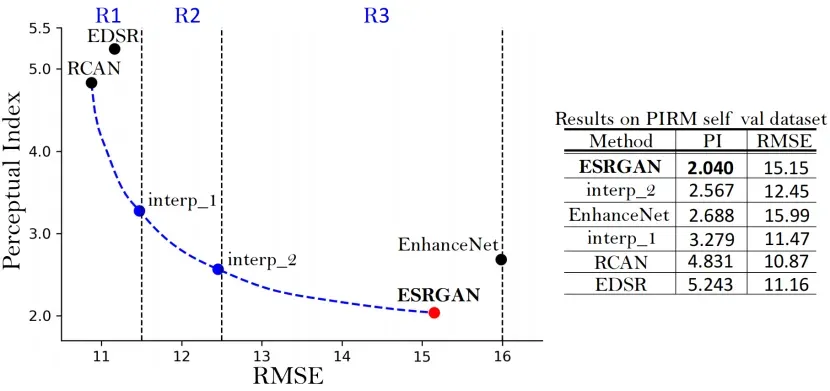
图2:PIRM自验证数据集上的感知-失真平面。我们展示了EDSR[20]、RCAN[12]和增强Net[16]的基线,以及提交的ESRGAN模型。蓝点是由图像插值产生的。
如图2所示,通过均方根误差(RMSE)的阈值划分为三个区域,每个区域感知指数最低的算法成为区域冠军。我们主要关注区域3,因为我们的目标是将感知质量带到一个新的高度。由于上述的改进和在Sec4.6中讨论的一些其他调整,我们提出的ESRGAN在PIRM-SR挑战(区域3)中以最佳感知指数获得第一名。
为了平衡视觉质量和RMSE/PSNR,我们进一步提出了网络插值策略,它可以不断地调整重建风格和平滑度。另一种选择是图像插值,它直接逐像素插值图像。我们采用这一策略来参与到区域1和区域2中来。第3.4节讨论了网络插值和图像插值策略及其差异。
2 Related Work
Lim等[20]提出了EDSR模型,通过去除残差块中不必要的BN层,扩大模型尺寸,实现了显著的改进。Zhang等[11]提出在SR中使用有效的残差密集块,并进一步探索了具有通道注意[12]的更深层网络,实现了最先进的PSNR性能。除了监督学习外,还引入了[26]强化学习和无监督学习[27]等方法来解决一般的图像恢复问题。
为了便于训练一个更深层次的网络,我们开发了一个紧凑而有效的残差密集块,这也有助于提高感知质量。
相对论鉴别器Relativistic discriminator[2]不仅可以增加生成数据真实的概率,而且同时降低真实数据真实的概率。在这项工作中,我们通过使用一个更有效的relativistic average GAN来增强SRGAN。
SR算法通常通过几种广泛使用的失真测量方法distortion measures来评估,例如PSNR和SSIM。然而,这些指标从根本上不同意对人类观察者[1]的主观评价。非参考指标,包括Ma评分[23]和NIQE[24],两者都用于计算PIRM-SR挑战[3]中的感知指数。在最近的一项研究中,Blau等人[22]发现,失真和感知质量是相互矛盾的。
3 Proposed Methods
我们的主要目的是提高对SR的整体感知质量。在本节中,我们首先描述我们提出的网络体系结构,然后讨论从鉴别器和感知损失的改进。最后,我们描述了平衡感知质量和PSNR的网络插值策略。

图3:我们采用了SRResNet[1]的基本架构,其中大部分计算都是在LR特征空间中完成的。我们可以选择或设计“基本块”(例如,残余块[18],密集块[34],RRDB),以获得更好的性能。
3.1 Network Architecture
为了进一步提高SRGAN的恢复图像质量,我们主要对生成器G的结构做了两处改进:1)去除所有BN层;2)用提出的残余密集块Residual-in-Residual Dense Block (RRDB)替换原始basic block,结合了 multi-level residual network和密集连接 dense connections,如图4所示。
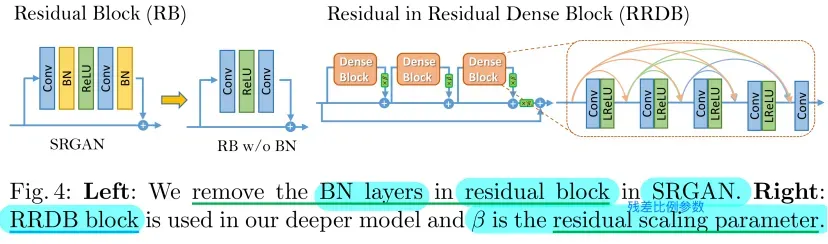
在不同的面向PSNR的任务中,包括SR [20]和去模糊[35],去除BN层已被证明可以提高性能并降低计算复杂度。BN层在训练期间使用一批中的均值和方差来归一化特征,并且在测试期间使用整个训练数据集的估计均值和方差。当训练和测试数据集的统计差异很大时,BN层往往会引入令人不愉快的伪像,并限制泛化能力。我们根据经验观察到,当网络更深并且在GAN框架下训练时,BN层更可能带来伪像。这些伪影偶尔会出现在迭代和不同的设置中,违背了对训练的稳定性能的需求。因此,为了稳定的训练和一致的性能,我们去除了BN层。此外,去除BN层有助于提高泛化能力并减少计算复杂度和内存使用。
我们保留了SRGAN的高级架构设计(见图3),并使用了一种新的基本块,即RRDB,如图4所示。根据观察,更多的层和连接总是可以提高性能[20,11,12],提出的RRDB采用了比SRGAN中的原始残差块更深、更复杂的结构。具体地,如图4所示,所提出的RRDB具有残差中残差结构residual-in-residual structure,其中残差学习被用于不同的级别。[36]中提出了一个类似的网络结构,它也应用了一个multi- level residual network。然而,我们的RRDB与[36]的不同之处在于,我们在主路径中使用密集块dense block[34]类似[11],其中受益于密集连接,网络容量变得更高。
除了改进的架构之外,我们还利用几种技术来促进训练非常深的网络:1)残差缩放[21,20],即,在将残差添加到主路径之前,通过乘以0和1之间的常数来缩小残差,以防止不稳定性;2)较小的初始化,因为我们根据经验发现,当初始参数方差变小时,残差架构更容易训练。更多的讨论可以在补充材料中找到。
提出网络的训练细节和有效性将在第四节中介绍
3.2 Relativistic Discriminator
除了改进的生成器结构外,我们还在Relativistic GAN[2]的基础上改进了判别器。与SRGAN中估计一个输入图像x是真实和自然的概率的标准鉴别器D不同,相对判别器relativistic discriminator试图预测真实图像xr比虚假图像xf相对更真实的概率,如图5所示。



3.3 Perceptual Loss
我们还开发了一种更有效的感知损失Lpercep,它是通过在激活前而不是激活后限制特征来实现的,如SRGAN中所实践的那样。
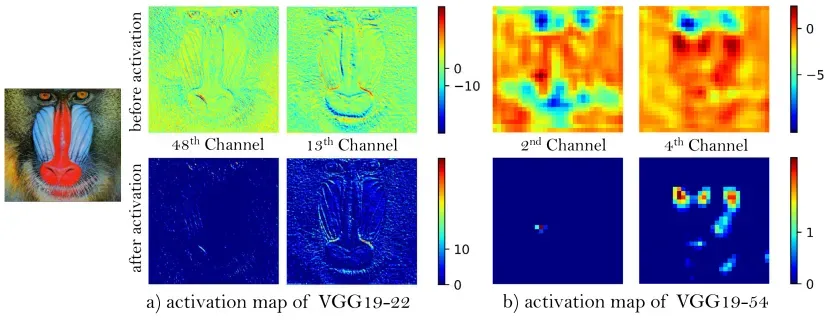
图6:图像“baboon”激活前后的代表性特征图。随着网络的深入,激活后的大多数特征变得不活跃,而激活前的特征包含更多信息。
基于更接近感知相似性的思想[29,14],Johnson等人[13]提出了感知损失,并在SRGAN [1]中进行了扩展。感知损失先前被定义在预训练的深度网络的激活层上,其中两个激活特征之间的距离被最小化。与惯例相反,我们建议在激活层之前使用特性,这将克服原始设计的两个缺点。首先,激活的特征非常稀疏,尤其是在非常深的网络之后,如图6所示(上)。例如,在VGG19-54 3【我们使用预训练的19层VGG网络[37],其中54表示在第5个最大池层之前通过第4次卷积获得的特征,代表高级特征,类似地,22表示低级特征。】层之后,图像“狒狒”的激活神经元的平均百分比仅为11.17%。稀疏激活提供较弱的监督,因此导致较差的性能。第二,激活后使用特征还会导致与真实图像相比的不一致的重建亮度,我们将在第4.4节展示这一点。

我们还在PIRM-SR挑战中探索了感知损失的一种变体。与采用为图像分类而训练的VGG网络的常用感知损失相比,我们开发了更适合于SR-MINC损失的感知损失。它基于一个用于材质识别的微调VGG网络fine-tuned VGG network[38],该网络关注于纹理而不是对象。尽管MINC损失带来的感知指数的增加是微不足道的,但我们仍然相信,探索侧重于纹理的感知损失对于超分辨率重建是至关重要的。
3.4 Network Interpolation
为了在保持良好感知质量的同时消除基于GAN的方法中令人不愉快的噪声,我们提出了一种灵活有效的策略——网络插值。具体来说,我们首先训练一个面向PSNR的网络GPSNR,然后通过微调获得一个基于GAN的网络GGAN。我们对这两个网络的所有相应参数进行插值,以导出插值模型GINTERP,其参数为:

提出的网络插值有两个优点。首先,插值模型能够对任何可行的α产生有意义的结果,而不引入伪影。第二,我们可以在不重新训练模型的情况下持续平衡感知质量和保真度。
我们还探索了替代方法来平衡面向PSNR和基于GAN的方法的效果。例如,可以直接内插它们的输出图像(逐像素)而不是网络参数。然而,这种方法未能在噪声和模糊之间实现良好的平衡,即内插图像要么太模糊,要么带有伪像的噪声(参见第4.5节)。另一种方法是调整内容损失和对抗损失的权重,即等式(3).中的参数λ和η。但是这种方法需要调整损失权重和微调网络,因此实现图像风格的连续控制成本太高。
4 Experiments
4.1 Training Details
按照SRGAN [1],所有实验都是在LR和HR图像之间以×4的比例因子进行的。我们通过使用MATLAB双三次核函数对HR图像进行下采样来获得LR图像。最小批量设置为16。裁剪后的HR面片的空间大小为128 × 128。我们观察到,训练更深的网络受益于更大的块大小,因为扩大的感受野有助于捕捉更多的语义信息。但是,它花费更多的训练时间,消耗更多的计算资源。在面向PSNR的方法中也观察到这种现象(见补充材料)。
训练过程分为两个阶段。首先,我们用L1损失训练一个面向PSNR的模型。学习速率初始化为2×10 -4,每2 × 10 5次小批量更新,学习速率衰减2倍。然后,我们采用经过训练的面向PSNR的模型作为生成器的初始化。使用等式(3)中的损失函数来训练生成器,λ= 5×10 -3,η= 1×10 -2。学习速率设置为1×10 -4,并在[50k,100k,200k,300k]次迭代时减半。使用逐像素损失进行预训练有助于基于GAN的方法获得视觉上更令人满意的结果。原因是:1)它可以避免生成器不希望的局部最优;2)在预训练之后,鉴别器在最开始接收到相对较好的超分辨率图像,而不是极端的假图像(黑色或有噪声的图像),这有助于它更加专注于纹理鉴别。
为了优化,我们使用Adam [39],β1 = 0.9,β2 = 0.999。我们交替更新生成器和鉴别器网络,直到模型收敛。我们对生成器使用两种设置——其中一种包含16个残差块,容量与SRGAN相似,另一种是具有23个RRDB块的更深模型。我们使用PyTorch框架实现我们的模型,并使用NVIDIA Titan Xp GPUs训练它们。
4.2 Data
对于训练,我们主要使用DIV2K数据集[40],这是一个用于图像恢复任务的高质量(2K分辨率)数据集。除了包含800张图像的DIV2K训练集之外,我们还为我们的训练寻找具有丰富多样纹理的其他数据集。为此,我们进一步使用由Flickr网站上收集的2650张2K高分辨率图像组成的Flickr2K数据集[41]和OutdoorSceneTraining (OST) [17]数据集来丰富我们的训练集。我们根据经验发现,使用这个具有更丰富纹理的大型数据集有助于生成器产生更自然的结果,如图8所示。
我们在RGB通道中训练我们的模型,并用随机水平翻转和90度旋转来扩充训练数据集。我们在广泛使用的基准数据集上评估我们的模型——set 5[42],Set14 [43],BSD100 [44],Urban100 [45]以及PIRM-SR挑战赛中提供的PIRM自我验证self-validation数据集。
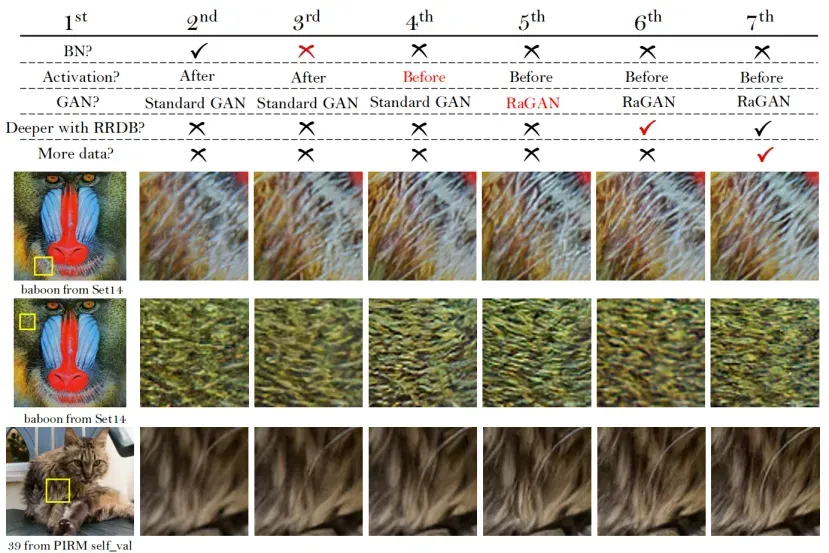


图8:显示ESRGAN中各成分的效果的整体视觉比较。每一列表示一个模型,其配置在顶部。红色符号表示与前一模型相比的主要改进。
4.3 Qualitative Results定性
我们在几个公共基准数据集上将我们的最终模型与最先进的面向PSNR的方法(包括SRCNN [4]、EDSR [20]和RCAN [12])以及感知驱动的方法(包括SRGAN [1]和EnhanceNet [16])进行了比较。由于感知质量没有有效的标准度量,我们在图7中给出了一些代表性的定性结果。还提供了PSNR(在YCbCr色彩空间中的亮度通道上评估)和PIRM-SR挑战中使用的感知指数以供参考。
从图7可以看出,我们提出的ESRGAN在清晰度和细节方面都优于以前的方法。例如,与PSNR导向的方法相比,ESRGAN可以产生更清晰、更自然的狒狒胡须和草纹理(见图43074 ),后者往往会产生模糊的结果;与以前基于GAN的方法相比,前者的纹理不自然,包含令人不快的噪声。ESRGAN能够在建筑物中生成更详细的结构(见图片102061),而其他方法要么不能生成足够的细节(SRGAN),要么添加不需要的纹理(EnhanceNet)。此外,先前的基于GAN的方法有时会引入令人不愉快的伪像,例如,SRGAN会给面部增加皱纹。我们的ESRGAN消除了这些伪像,产生了自然的结果。
4.4 Ablation Study
为了研究建议的ESRGAN中每个组件的影响,我们逐渐修改基线SRGAN模型并比较它们的差异。总体视觉比较如图8所示。每列代表一个型号,其配置显示在顶部。红色标志表示与前模型相比的主要改进。详细讨论如下。
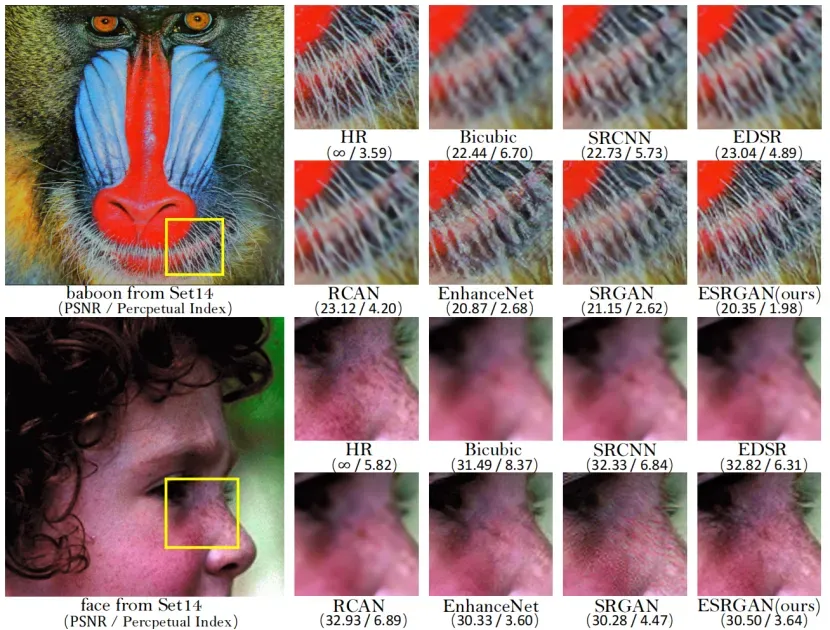

图7:ESRGAN的定性结果。ESRGAN产生更自然的纹理,如动物皮毛、建筑结构和草的纹理,也不会产生那么令人不快的伪影,如SRGAN面部的伪影。
BN去除。我们首先去除所有BN层,以获得稳定一致的性能,而不会出现伪像。它不会降低性能,但节省了计算资源和内存使用。在某些情况下,从图8中的第2列和第3列可以观察到轻微的改善(例如图39)。此外,我们观察到,当网络更深更复杂时,具有BN层的模型更有可能引入令人不愉快的伪像。这些例子可以在补充材料中找到。
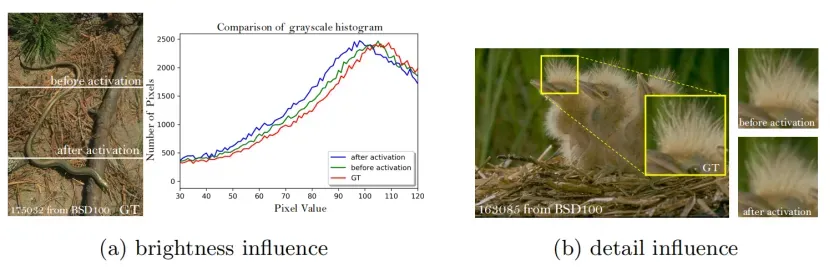
图9:激活前和激活后的比较。
在感知损失激活之前。我们首先证明,在激活之前使用特征可以产生更精确的重建图像亮度。为了消除纹理和颜色的影响,我们使用高斯核对图像进行滤波,并绘制其灰度直方图。图9a示出了每个亮度值的分布。使用激活的特征使分布向左倾斜,导致更暗的输出,而在激活之前使用特征导致更精确的亮度分布,更接近真实情况。
我们可以进一步观察到,在激活之前使用特征有助于产生更清晰的边缘和更丰富的纹理,如图9b(见鸟羽毛)和图8(见第3和第4列)所示,因为激活之前的密集特征提供了比稀疏激活所能提供的更强的监督。
RaGAN。RaGAN使用了一种改进的相对鉴别器,这种鉴别器被证明有利于学习更锐利的边缘和更详细的纹理。例如,在图8的第5列中,生成的图像比它们左边的图像更清晰,具有更丰富的纹理(参见狒狒,图像39和图像43074)。
Deeper network with RRDB。具有所提出的RRDB的更深模型可以进一步改善恢复的纹理,特别是对于像图8中图像6的屋顶这样的规则结构,因为深度模型具有捕捉语义信息的强大表示能力。此外,我们发现更深的模型可以减少不愉快的噪声,如图8中的图像20。
与声称更深的模型越来越难以训练的SRGAN相反,我们的更深的模型显示出其易于训练的优越性能,这要归功于上面提到的改进,尤其是提出的没有BN层的RRDB。
4.5 Network Interpolation
我们比较了网络插值和图像插值策略在平衡面向PSNR的模型和基于GAN的方法的结果方面的效果。我们对两种方案都应用简单的线性插值。插值参数α从0到1中选择,间隔为0.2。
如图10所示,纯基于GAN的方法产生锐利的边缘和更丰富的纹理,但是具有一些令人不愉快的伪像,而纯面向PSNR的方法输出卡通风格的模糊图像。通过使用网络插值,在保持纹理的同时减少了令人不愉快的伪像。相比之下,图像插值不能有效地消除这些伪影。
有趣的是,在图10中观察到网络插值策略提供了平衡感知质量和保真度的平滑控制。

图10:网络插值与图像插值的对比
4.6 The PIRM-SR Challenge
我们带着一个ESRGAN的变体参加PIRM-SR挑战赛[3]。具体来说,我们使用具有16个残差块的所提出的ESRGAN,并且还进行了一些改进以迎合感知指数。1)MINC损失被用作感知损失的变体,如在第3.3.节中所讨论的。尽管感知指数的边际收益,我们仍然认为探索侧重于纹理的感知损失对SR至关重要。2)用于学习感知指数的原始数据集[24]也在我们的训练中使用;3)由于PSNR约束,使用了高达η = 10的高权重损失L1;4)我们还使用反投影back projection[46]作为后处理,它可以提高PSNR,有时会降低感知指数。
对于需要更高PSNR的其他区域1和2,我们使用我们的ESRGAN结果和PSNR导向方法RCAN [12]的结果之间的图像插值。图像插值方案实现了较低的感知指数(越低越好),尽管我们通过使用网络插值方案观察到了更加视觉愉悦的结果。我们提出的ESRGAN模型以最佳感知指数赢得了PIRM-SR挑战赛(区域3)的第一名。
5 Conclusion
我们提出了一个ESRGAN模型,它比以前的SR方法获得了更好的感知质量。该方法在PIRM-SR挑战赛中获得了感知指数第一名。我们制定了一个新的架构,包含几个没有BN层的RDDB块。此外,使用包括残差缩放和较小初始化的有用技术来促进所提出的深度模型的训练。我们还介绍了使用相对GAN作为鉴别器,它学习判断一个图像是否比另一个图像更真实,指导生成器恢复更详细的纹理。此外,我们通过使用激活前的特征增强了感知损失,这提供了更强的监督,从而恢复了更准确的亮度和更真实的纹理。
文章出处登录后可见!