ABSA1: Attentional Encoder Network for Targeted Sentiment Classification
论文标题:
Attentional Encoder Network for Targeted Sentiment Classification(点击可下载pdf)
论文源码:ABSA模型库(PyTorch版)
一、引言
以往而言,对于 ABSA 问题创建的模型大多数都是 RNN + Attention 的思路。
存在问题Q:
- RNN 系列模型(例如NLP任务中的万金油 LSTM )极具表现力但很难并行化,并且随着时间的反向传播需要大量的内存和计算,基本上每个 RNN 的训练算法都是截断的 BPTT,这将会影响模型在更长时间上捕获依赖关系的能力。LSTM 在一定程度上可以缓解梯度消失问题,但通常需要大量的训练数据。
- 先前的工作大多忽略标签不可信问题(label unreliability issue)——中性标签是一种模糊的情感表示,具有中性情感标签的训练样本就是不可信的。
二、解决方案
- 提出基于注意力的模型,使用注意力绘制目标词target和上下文词context之间的内省(introspective)和交互(interactive)语义。
- The label unreliability issue——在损失函数中添加有效的标签平滑正则化项促使模型对模糊标签的学习。
标签平滑正则化LSR可参考:
https://zhuanlan.zhihu.com/p/64970719
三、模型结构AEN
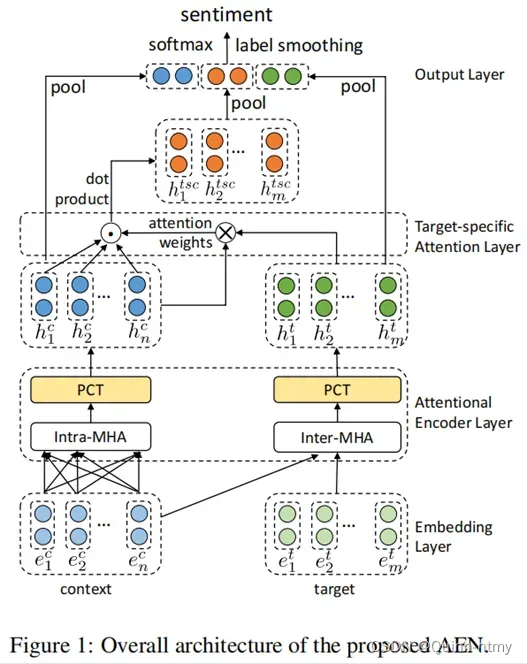
由嵌入层、注意力编码器层、目标特定注意力层和输出层组成。
1、Embedding Layer
有两种Embedding的方式:
(1)GloVe Embedding;
(2)BERT Embedding:需要将给定的上下文和目标分别转换为“[CLS] + context + [SEP]”和“[CLS] + target + [SEP]”。
2、Attentional Encoder Layer
注意力编码器层是LSTM可并行化和交互式的替代方案,计算出Input Embedding的隐藏状态。该层由多头注意力(MHA)和逐点卷积变换(PCT)两个子模块组成。相当于利用 MHA —> PCT 进行特征提取。
(1)MHA(Multi-Head Attention)
- 给定一个上下文嵌入e^c,使用Intra-MHA进行内省上下文词(context)建模,即self-attention:
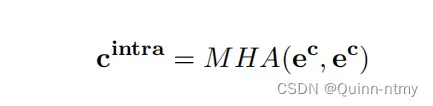
- 给定一个上下文嵌入
和一个目标嵌入
,使用Inter-MHA进行上下文感知目标词(context对于target)建模,即传统attention:
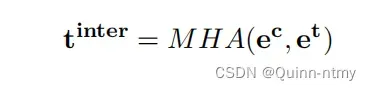
(2)PCT(Point-wise Convolution Transformation)
PCT用来转换MHA收集的上下文信息。逐点卷积,即卷积核的尺寸为1,对上述得到的两个attention encoder进行以下操作:
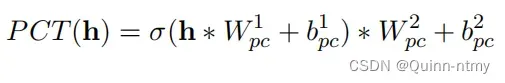
3、Target-specific Attention Layer
获得内省上下文表示和上下文感知目标表示后,使用MHA来获得目标特定上下文表示:

4、Output Layer
通过平均池化得到上一步输出的最终表示,然后将它们连接成为最终的表示,并使用全连接层将连接的向量投影到目标C类的空间中。
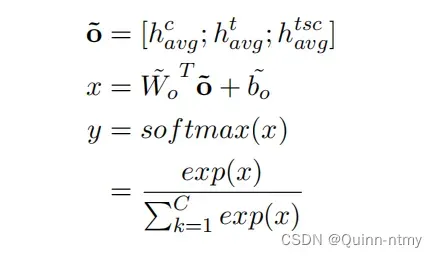
【池化的作用:减少特征图大小,也就是可以减少计算量和所需显存。即特征降维。平均池化能够很好的保留整体数据的特征,能突出背景信息;最大池化能更好的保留纹理上的特征。】
5、Loss Function
为了解决标签不可信问题,引入了LSR:
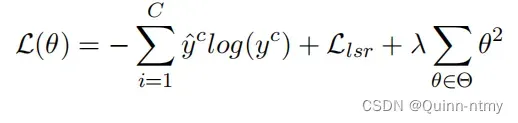
下面学习一下 LSR(Label Smoothing Regularization):
通过在输出Y中添加噪声,实现对模型进行约束,从而降低模型过拟合的一种方法,其用于分类问题。
在分类问题中,p(y|x)是预测概率分布,q(y|x)是真实概率分布数据所属类别有多个,通常用one-hot形式表示,所属类别用1表示,其他用0表示。使用one-hot形式存在两个问题:
- 容易导致过拟合
- 容易太过依赖模型,容易使预测结果严重偏离事实
LSR可以用来解决以上两个问题,引入一个先验知识 u(y),一般表示为 1/k,k 代表类的个数,ϵ 是平滑因子,属于 [0,1],
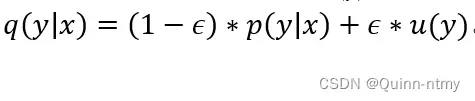
这个公式相当于在标签Y中添加了噪声,防止模型把预测值过度集中在概率较大的分类上,而把一些概率值分配到概率小的类别上。
文章出处登录后可见!