目录
四、map(),apply(),applymap()函数的区别
一、map()函数
划重点:map 函数对Series的每个元素执行遍历处理,该参数可以是字典,也可以是函数;
1.map() 参数为字典;
import pandas as pd
s=pd.Series(['增长','持平','下降'])
s.map({'增长':0.1,'持平':0,'下降':-0.1})
当map()函数参数为字典的时候,返回字典的的值;
2.map() 参数为内置函数;
使用map()函数给数字后面添加”月”;
import numpy as np
s1=pd.Series(np.arange(1,13))
s1.map('{}月'.format)
map()函数遍历Series的每个元素,对每个元素进行格式化处理,后面添加了”月”。
3.map() 参数定义为自定义函数;
map()自定义函数实现对数据的任意操作,常见的操作有:
Series字符串处理;
Series数据格式化操作;
Series分组数据分组操作;
Series对数据进行自定义运算;
例:数据自定义运算:Series数据扩大10倍
def fun(x):
return x*10
s2=pd.Series(np.random.randint(10,100,10))
print(s2)
s2.map(fun)
4.map() 参数为lambda匿名函数;
map()参数为lambda匿名函数,使用范围更广,写法更为简洁;
接上文,使用lambda匿名函数对Series数据扩大十倍;
s2.map(lambda x: x*10)
二、apply()函数
划重点:apply()函数遍历DataFrame的行和列;
df=pd.DataFrame({
'A':np.random.randint(80,150,10),
'B':np.random.randint(30,150,10),
'C':np.random.randint(10,150,10),
})
df
使用匿名函数输出一下:
df.apply(lambda x: print(x))
划重点:使用apply()函数遍历DataFrame,数据从左至右按列遍历,每一列数据都是Series。
1.遍历DataFrame按列求和
df.apply(sum,axis=0) 
2. 遍历DataFrame按列行求和
df['sum']=df.apply(sum,axis=1) #按行求和
df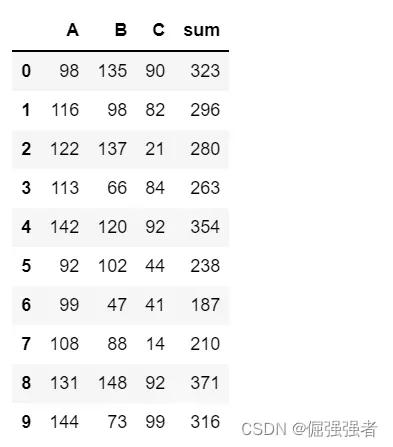
三、 applymap()函数
划重点:applymap()函数遍历DataFrame中每个元素;
df1=pd.DataFrame({
'A':np.random.rand(10),
'B':np.random.rand(10),
'C':np.random.rand(10),
})
df1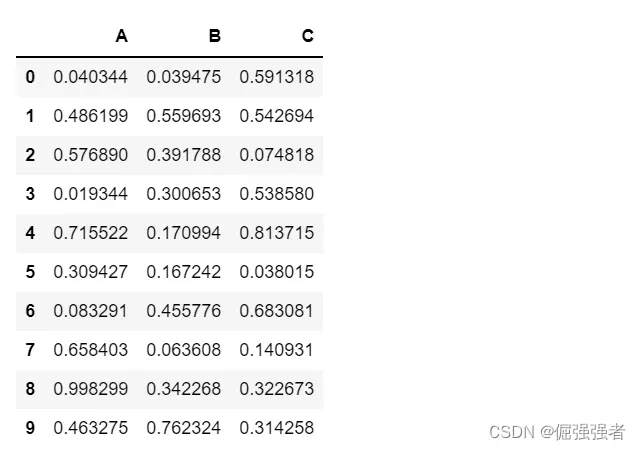
1.对数据进行格式化处理,保留两位小数
pandas格式化处理完数据为为”object”,需要转化为”float”
df1.applymap('{:.2f}'.format).astype('float')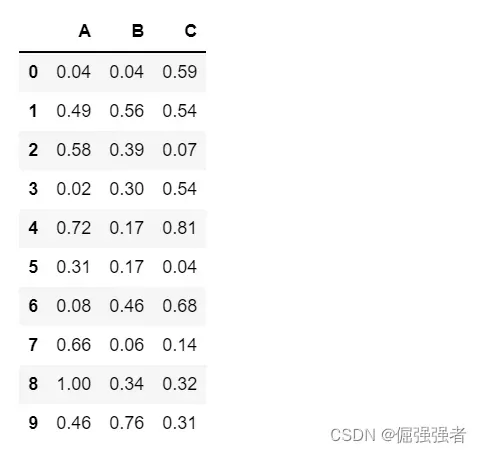
四、map(),apply(),applymap()函数的区别
| map()函数 | 遍历Series数据 |
| apply()函数 | 遍历DataFrame数据或Series数据 |
| applymap()函数 | 遍历DataFrame中的每个元素 |
文章出处登录后可见!
已经登录?立即刷新