注:本文是我学习李宏毅老师《机器学习》课程 2021/2022 的笔记(课程网站 ),文中图片均来自课程 PPT。欢迎交流和多多指教,谢谢!
Lecture 4-Sequence as input
前一节课介绍了 Deep Learning 在图像处理的应用,本节课将会介绍 Deep Learning 在自然语言处理 (NLP) 的应用。
我们先来回顾一下,前面分析的 Model (Deep Neural Network) 输入的每个 sample 是 Vector 或 Matrix (e.g. image) 的形式。其实 Matrix 可以看成是把 Vector 做了一个维度变换,从一维变成三维或更多维。这样看来,输入是 Vector 或 Matrix 时,每个 sample 的维度是固定的。
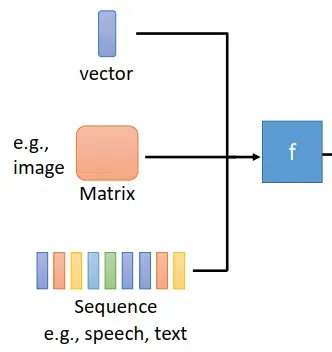
当输入的一个 sample 是一组 vectors时,不同 sample 包含的 vectors 个数可能不同。这样,sample 的维度不再固定,是变化的。这种输入也被称为 Sequence 或 vector set。就像我们说的每一句话有长有短,sequence 的长度也是变化的。这给我们提出了新的问题:变长的输入要怎么处理呢?别急,本节课将为你介绍。
输入是 Sequence(序列)的情况
我们先来看看,有哪些应用是以序列 (Sequence) 作为输入呢?
1.文本。一句话有很多字词。每个字词可以用一个 vector 表示,这样,一个句子就是一个 vector set。
字词怎么用 vector 表示呢?
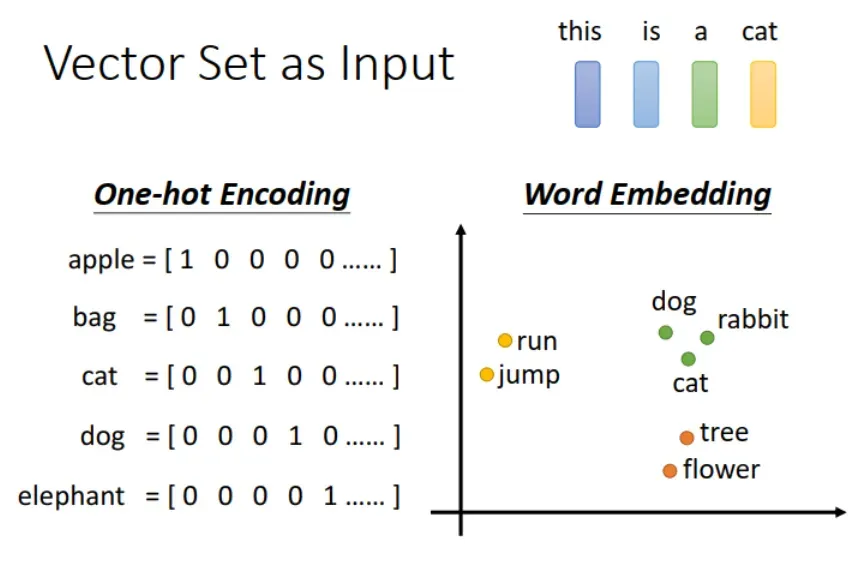
方法一:One-hot Encoding. 取一个很大的词汇表,囊括了所有的词汇,每个词唯一表示。
存在问题:词汇表很大,产生的向量是稀疏高维向量,空间占用大。而且,这种向量表示不包含语义信息。如下图所示,cat, dog 都是动物,one-hot encoding 体现不出它们的相似性。
方法二:Word Embedding. 加入了语义信息,如下图所示,同属于动物的 dog, cat, rabbit 离得更近,同属于植物的 tree, flower 离得更近。而且,产生的向量维数更少。
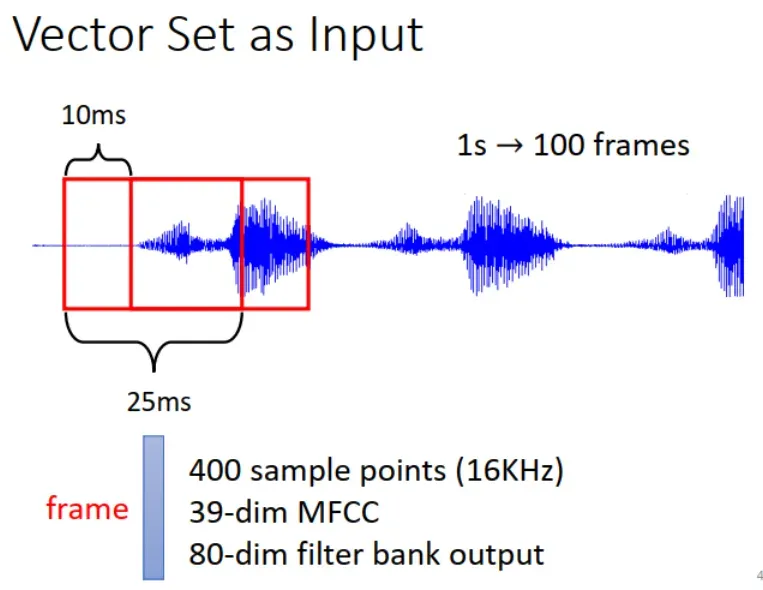
2.语音识别:把语音信号按帧 (frame) 划分,识别其中的 phoneme。每一段 frame 是一个 vector,一段语音就是 vector set。
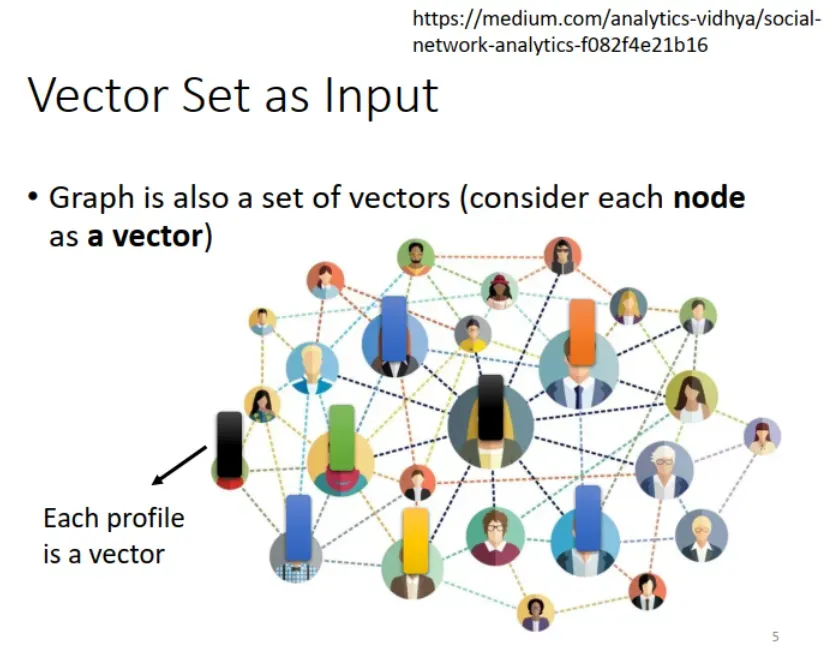
3.图网络:社交网络就是一个 Graph(图网络),其中的每一个节点(用户)都可以用 vector 来表示属性,这个 Graph 就是 vector set。
4.分子结构:在药物研发、材料研发中,可以用于分析分子特性。每个节点上的原子当作一个 vector,这个 vector 用 One-hot Encoding 表示,整体的分子结构就是 vector set.
输出有三种形式
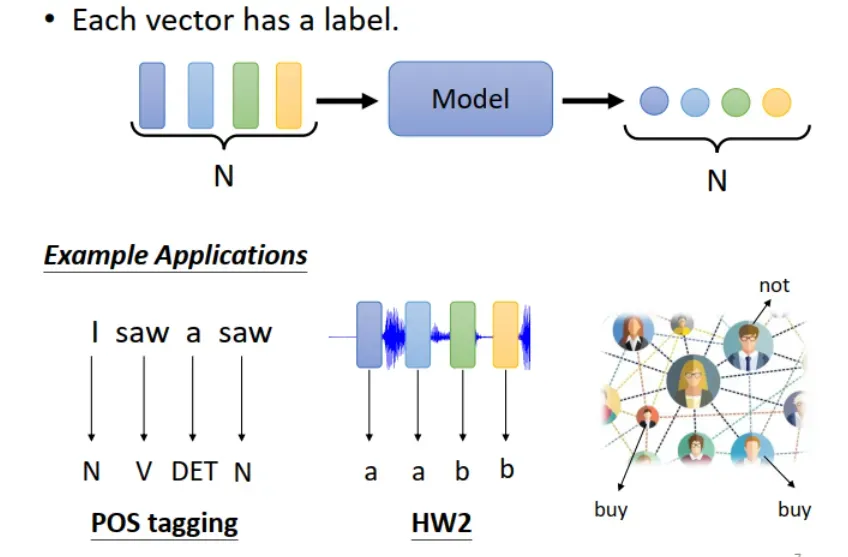
1.输出序列长度与输入序列相同。
Each vector has a label. 每个 vector 都有一个对应的 label 输出,这样输出序列长度与输入序列长度相同。这是本节课研究的重点。
应用举例:(1)词性标注 (POS tagging)。(2)语音识别(声音–>phoneme(也就是元音辅音))。(3)社交网络中的用户行为预测。
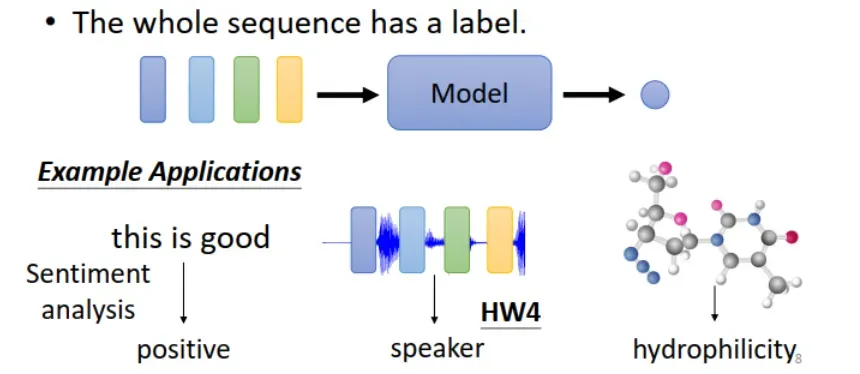
2.输出序列长度为1。
The whole sequence has a label. 整个序列输出一个 label。
应用举例:(1)Sentiment analysis,通过评论分析其中的情感 (positive, neural, negative)。(2)说话人识别。(3)判断分子特性(如亲水性)。
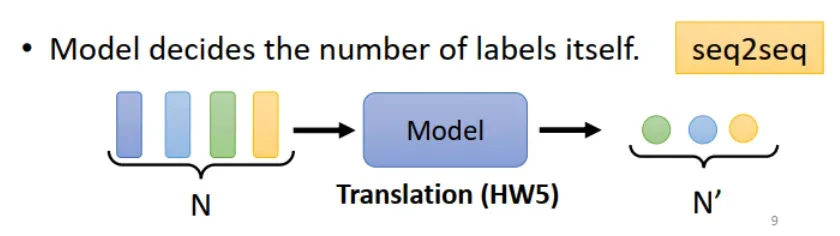
3.模型决定输出序列长度。
Model decides the number of labels itself. 由模型决定输出 label 的个数,也就是输出长度。这种情况也叫做 seq2seq 任务,将在 Lecture 5 介绍。
应用举例:(1)翻译,译文和原文的长度可能不一样。(2)语音识别,输入一段语音,输出一段文字。注意,与第一类输出形式中介绍的语音识别例子不同,这里输出的不是语音的最小单位 phoneme(也就是元音辅音),而是字词,因此与输入长度不一定相同。
Self-attention 原理
接下来,我们看看输入和输出序列长度相同时(这种情况也叫 Sequence Labeling),模型要如何设计?
首先,一个直觉的想法就是各个击破,还是用输入是 vector 的处理方法。vector set 也无非就是 vector 从一个变成多个,把这组 vectors 送入 Fully Connected Network 就好了。
但是,很快你会发现,这样存在问题。比如,对这个句子做词性标注: “ I saw a saw. ” 如果用输入是 vector 的方法来处理,机器会认为这两个 saw 是一样的。其实它们不一样,第一个是动词(看见),第二个是名词(锯子)。语音也是这样,一个音标,可以有不同的字母形式。也就是说,vector set 中的 vectors 不是独立的,它们之间有联系。我们要考虑 context(上下文)。这一点我在分享英语学习方法的文章中也提到过,就是单词的意思要放在句子(上下文语境)中记忆。我还举了几个一词多义的小例子,感兴趣的朋友欢迎点击阅读:怎样才能又快又好地记单词?。
解决办法一:设置 window.
像 homework2 语音识别中使用的方法一样,设置一个包括相邻 vectors 的 window,这不就考虑到 context 了吗?
存在问题:这对于 Sequence 并不现实。试想一下,Window 设多大合适呢?对于一段文字,只有先看其中最长的句子有多长,然后开一个这么大的 window。这样一来,运算量大,参数多,容易 overfitting。
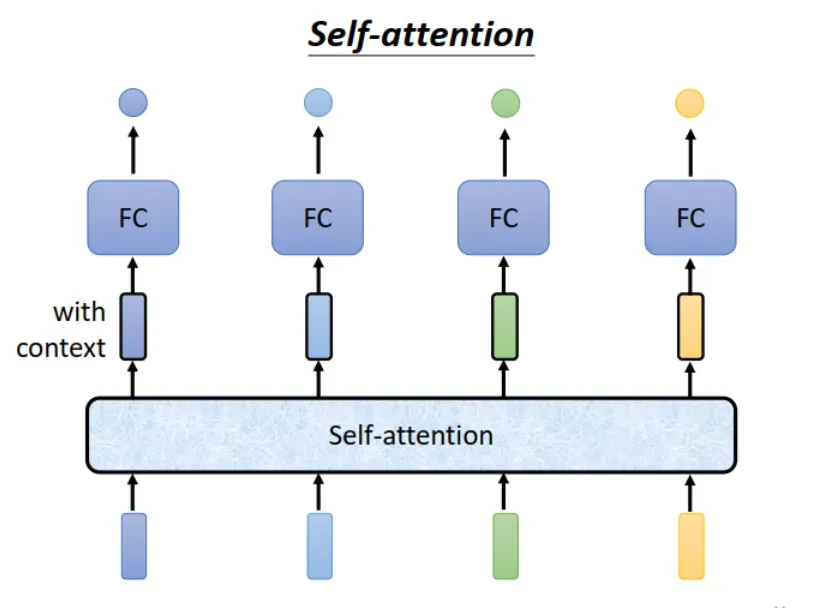
还有一种办法,在每个 vector 中融入 context 信息。这样,vector set 长度不变,但是,它们已经不是之前的 vectors 了。这就是 Self-attention 方法。
解决办法二:Self-attention.
如下图所示,把 sequence (vector set) 输入 Self-attention 模块,输出的 sequence 中每个 vector 都带有 context 信息。然后把这些 vectors 送入 Fully Connected Network,和输入是 vector 一样来处理。与方法一相比,self-attention 不会增加参数,而且考虑了整个句子的上下文信息。
和 CNN 的 Convolutional Layer 一样,Self-attention+Fully Connected Layer 也可以叠几层,如下图所示。因此,self-attention 的输入层可以是 input 或 hidden layer。
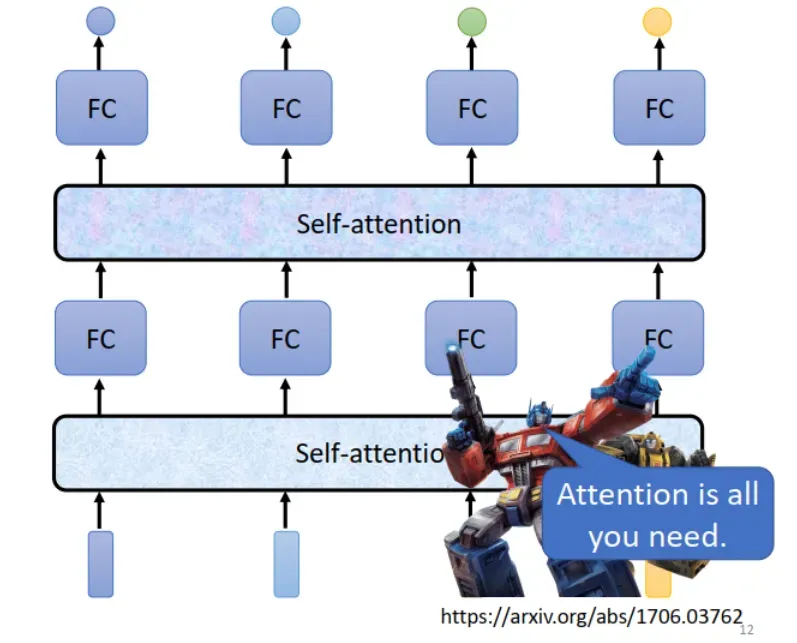
Self-attention 要做什么呢?
寻找 vector 之间的关系。如下图所示,对于某一个 vector,求出其与 sequence 中其它 vectors 的相关性。我们可以用 来表示相关性。
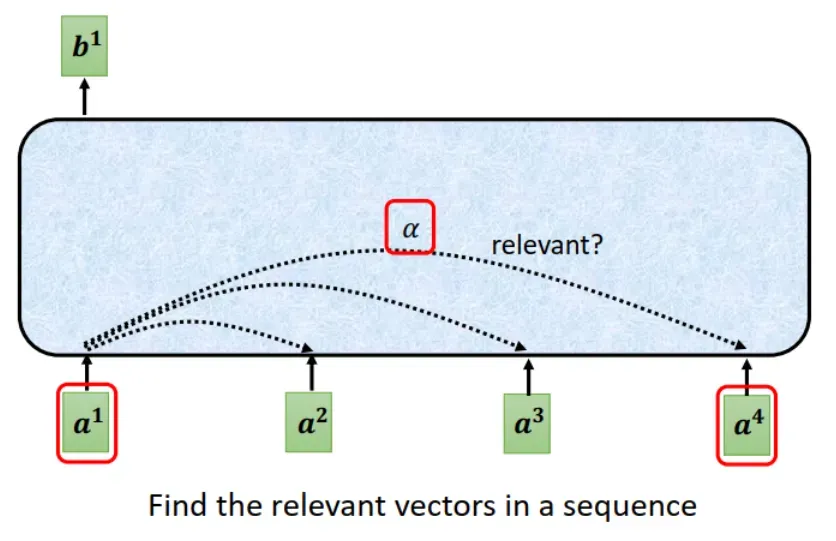
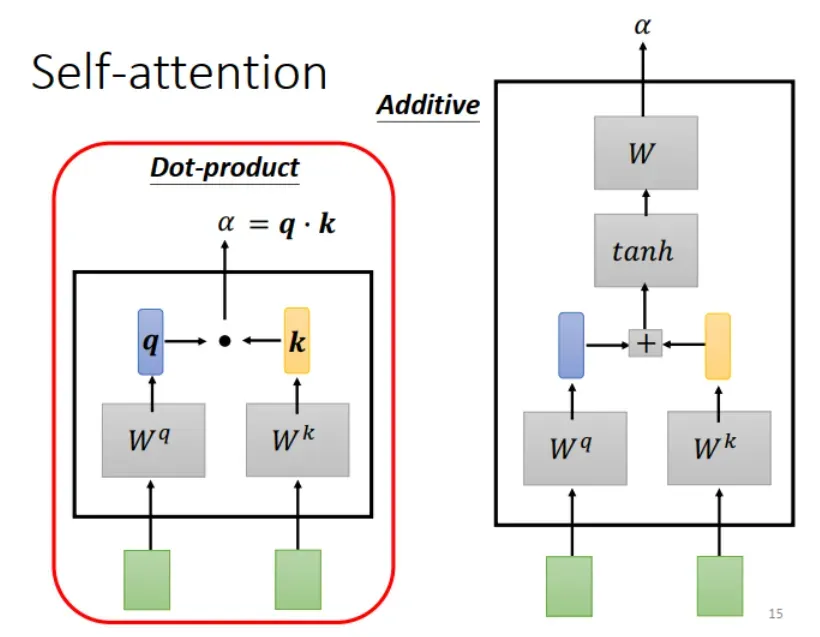
怎么计算 :用 Dot-product(点乘)或 Additive 都可以,Dot-product 更加常见。本文例子中使用 Dot-product。
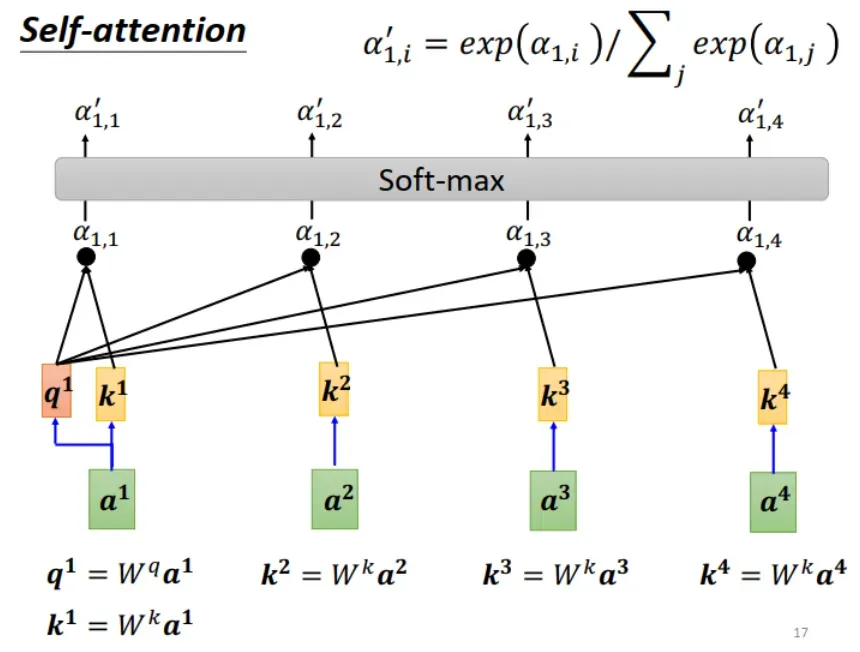
怎么计算 ?
通过输入 求出
(query) 和
(key),
与 sequence 中所有的
做 dot-product,得到
,也被称为 attention score。注意:
也和自己的
相乘。
再经过 softmax ,得到归一化的结果
。
疑问: 为什么 要和自己的
相乘?
把归一化后的 attention score 乘以
(value),就得到
。
是输入 vector 加入 context information 之后的输出。虽然输入输出序列的长度相同,但其中的每一个 vector 都加入了与序列中其它 vectors 的互信息。
疑问: 为什么要 ,直接乘以输入
不可以吗?
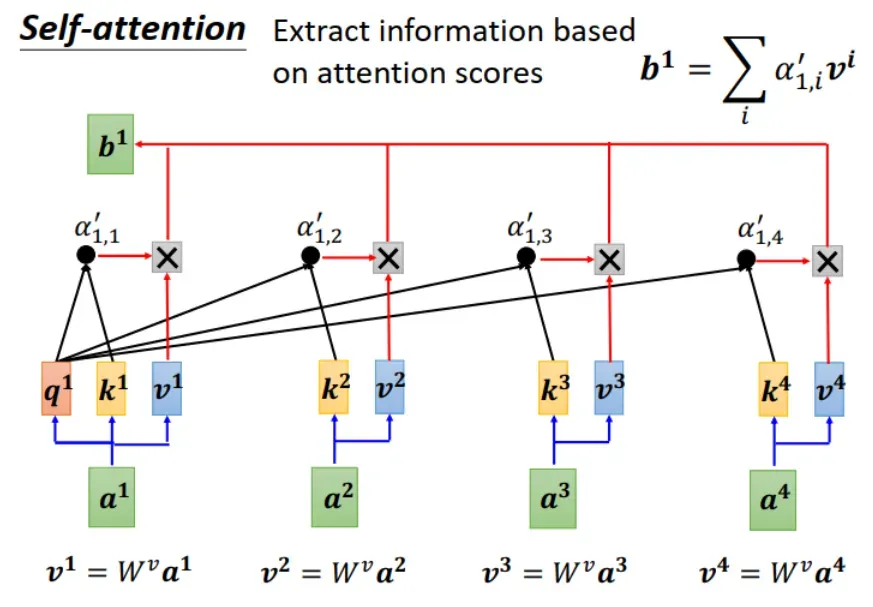
从上述计算步骤发现,计算 sequence 中的某个输出 vector 并不依赖于之前的结果
, …,
,因此,
, …,
可并行计算。
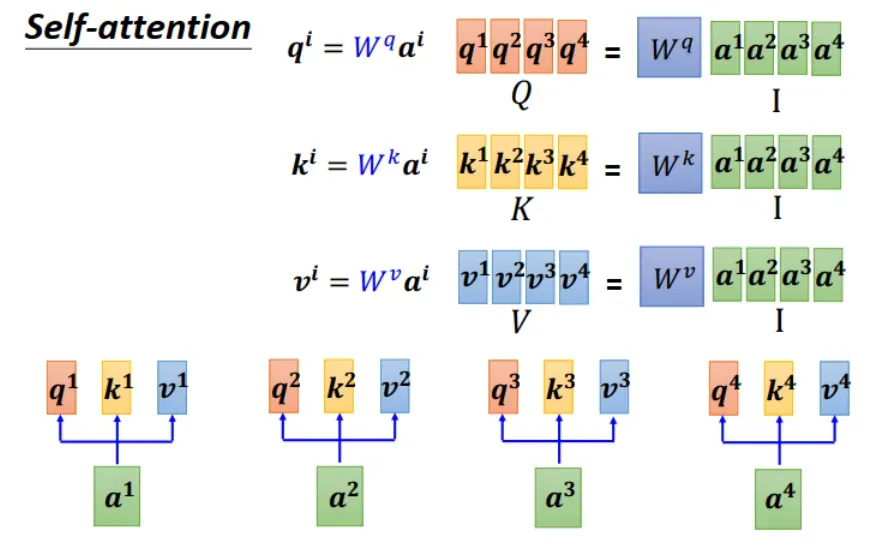
刚才我们看了如何处理输入 vector set 中的一个 vector。现在从个体转换到整体,来看看输入是 vector set (sequence) 时如何操作。下图所示的例子中,输入 sequence 长度为 4,有 4 个 vector。由
得到对应的
。
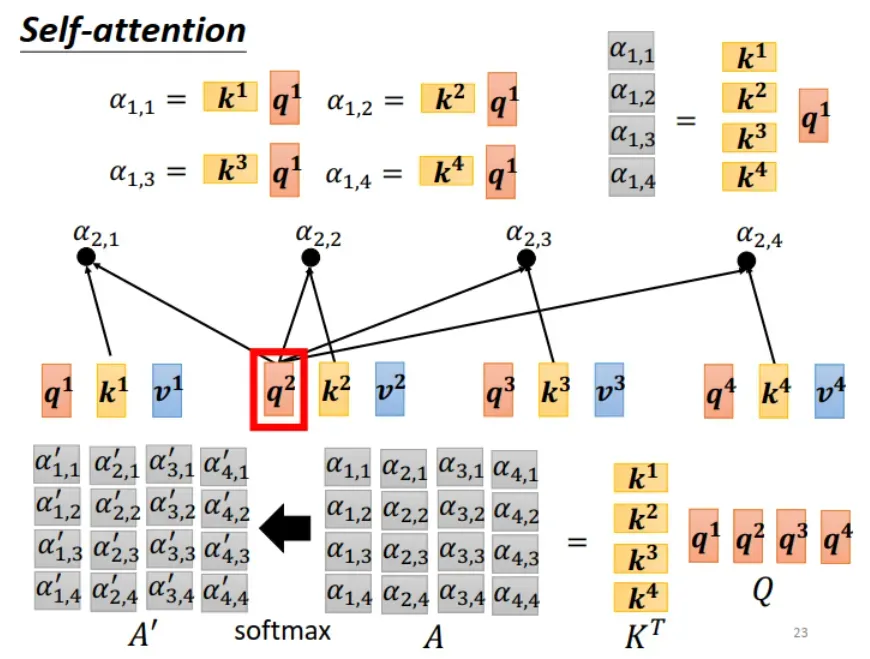
由于 是 dot-product,可以把
转置,与
做矩阵相乘,得到对应的
,组成 attention matrix A,如下图所示:
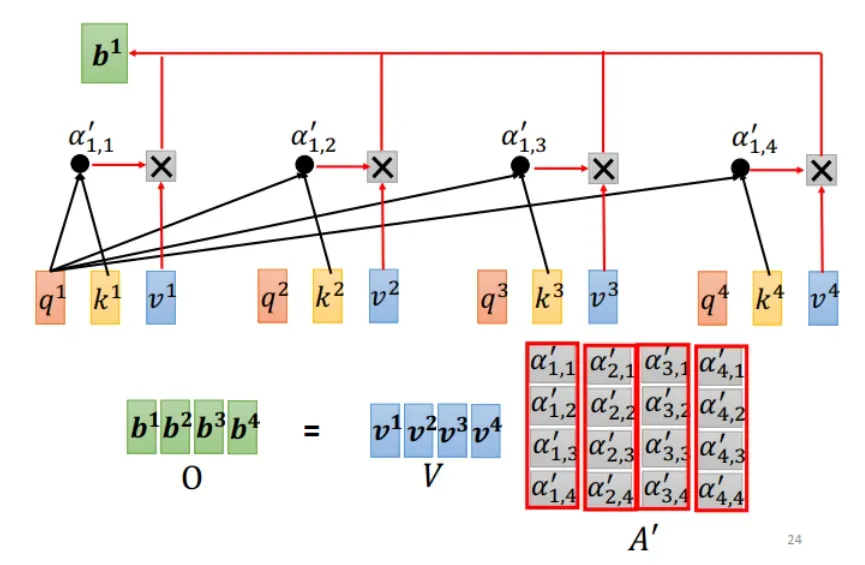
与
相乘,得到输出
,这一步运算也可以写成矩阵运算形式,如下图所示:
结合上面的分析,得到 Self attention 整个流程的矩阵运算表达式,如下图所示:
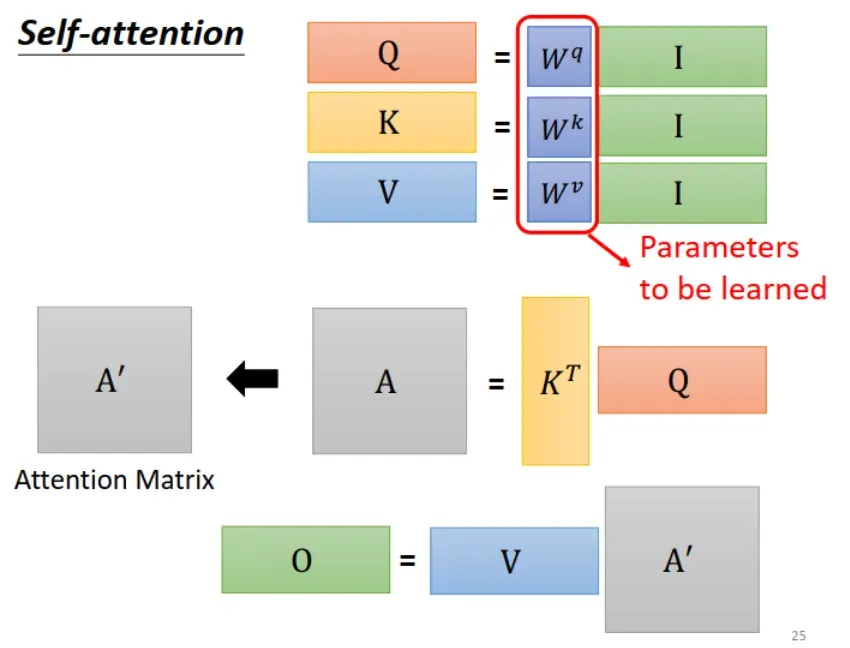
需要注意的是:
(1),
,
是要学习的参数!
(2)图中所示 Attention Matrix 的计算是运算量最大的部分,假设 sequence 长度为 L,其中的 vector 维度为 d,那么需要计算 L x d x L 次。
Self-attention 的改进
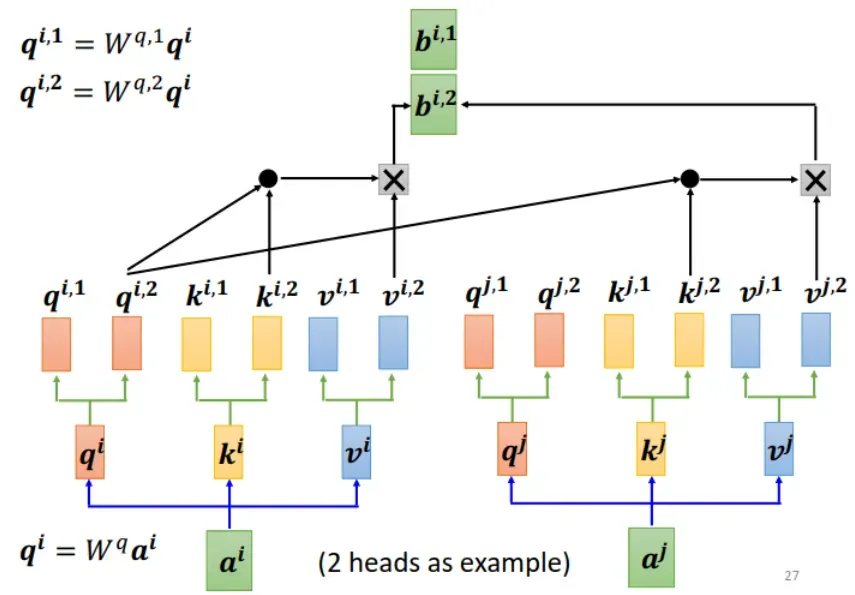
1. Multi-head Self-attention
有时候,我们要考虑多种相关性,需要不只一种 self attention,于是有了 Multi-head Self-attention。如下图所示(图中为 2 heads 的情况),此时, 由一组变成多组。注意:每组的
是对应运算的,不跨组。
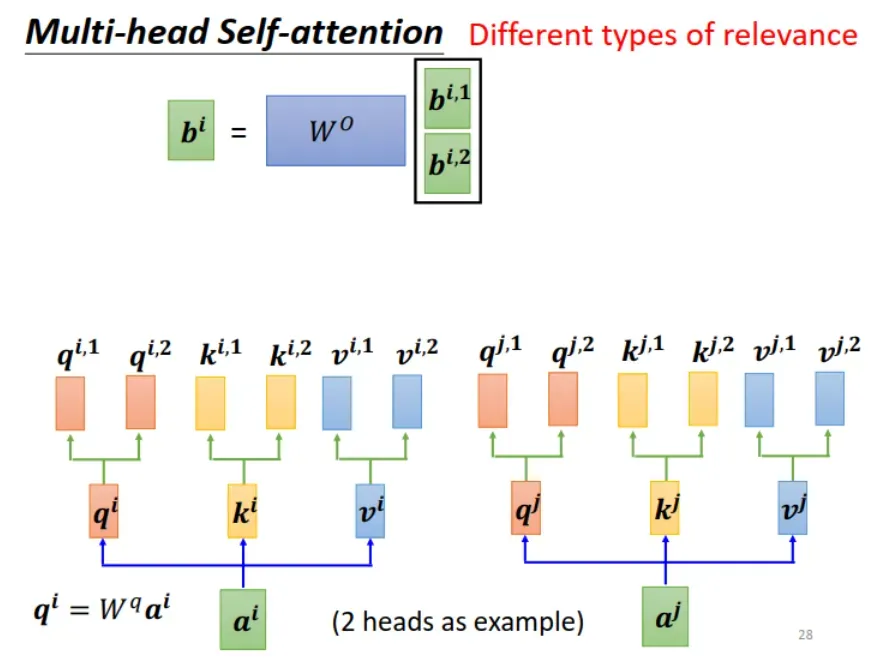
与单个的 self attention 相比,Multi-head Self-attention 最后多了一步:由多个输出组合得到一个输出。
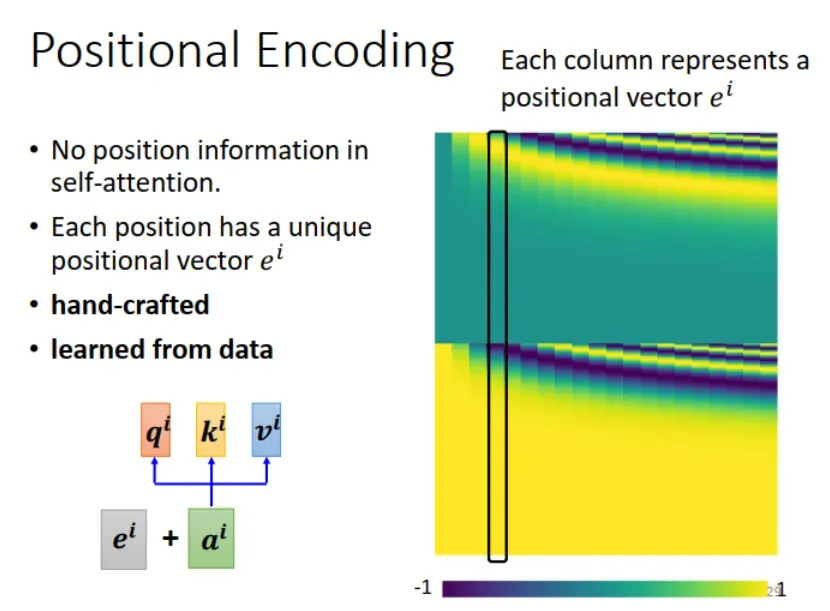
2. Positional Encoding
回顾 self attention 的计算过程,我们发现 self-attention 没有考虑位置信息,只计算互相关性。比如某个字词,不管它在句首、句中、句尾, self-attention 的计算结果都是一样的。但是,有时 Sequence 中的位置信息还是挺重要的。
解决方法:Positional Encoding,把位置信息 加入到输入
中。可以自己设计,如下图中的黑色竖方框所示为一个
,也可以从数据中学到。
Self-attention 的应用
1. 应用于 NLP
Self-attention 在 NLP 中广泛应用,如鼎鼎有名的 Transformer, BERT 的模型架构中都使用了 Self-attention。
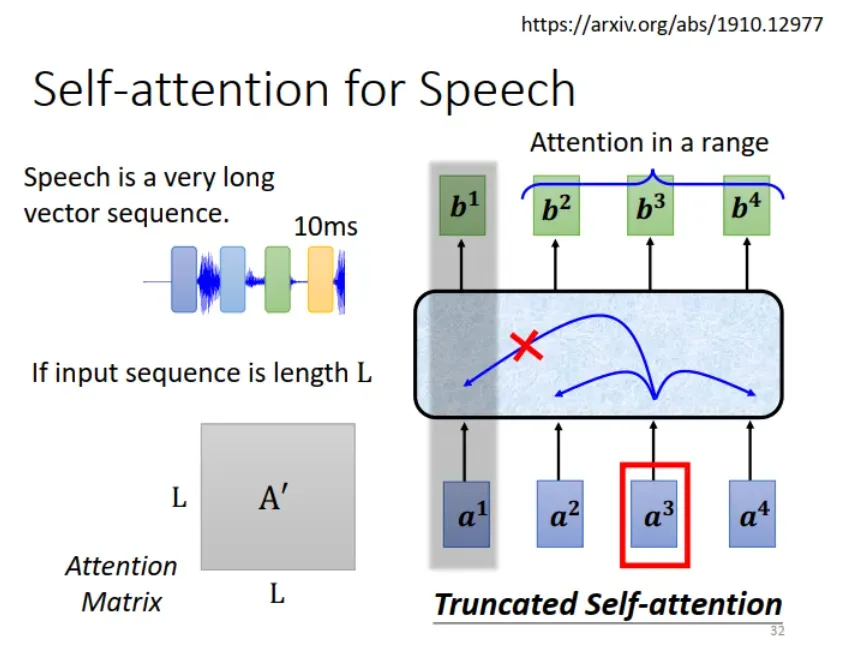
2. 应用于语音识别,改进:Truncated Self-attention
在语音处理中用 Self-attention,可以把 frames 当做 vector set。
存在问题:假设每次移动 10ms 取下一个 frame,1s 就有 100 个 vectors。一个句子很长,计算 Attention Matrix 运算量很大。
改进:用 Truncated Self-attention,如图所示,不在全部 sequence 上计算 attention score,限制在相邻一定范围内计算。
思考:Truncated Self-attention 感觉有点像 CNN 的 receptive field。
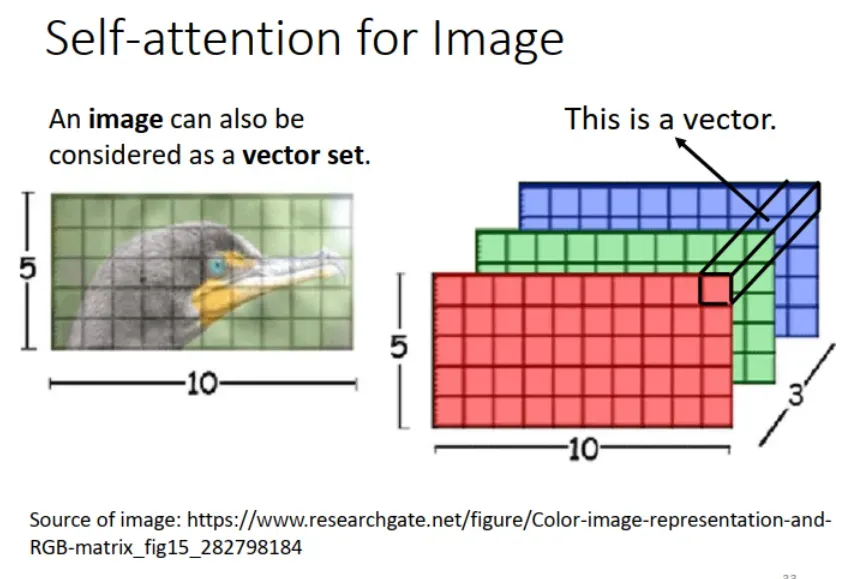
3. 应用于图像处理,对比:CNN 模型
在图像处理中用 self attention,如图所示,把一个像素点(W,H,D)当成一个 vector,一幅图像就是 vector set。
其实,Self-attention 可以看成是更加灵活的 CNN。为什么这么说呢?
把一个像素点当作一个 vector,CNN 只看 receptive field 范围的相关性,可以理解成中心的这个 vector 只看其相邻的 vectors,如下图所示。从 Self-attention 的角度来看,这就是在 receptive field 而不是整个 sequence 的 Self-attention。因此, CNN 模型是简化版的 Self-attention。
另一方面,CNN 的 receptive field 的大小由人为设定 ,比如: kernel size 为 3×3。而 Self-attention 求解 attention score 的过程,其实可以看作在学习并确定 receptive field 的范围大小。与 CNN 相比,self-attention 选择 receptive field时跳出了相邻像素点的限制,可以在整幅图像上挑选。因此,Self-attention 是复杂版的 CNN 模型。

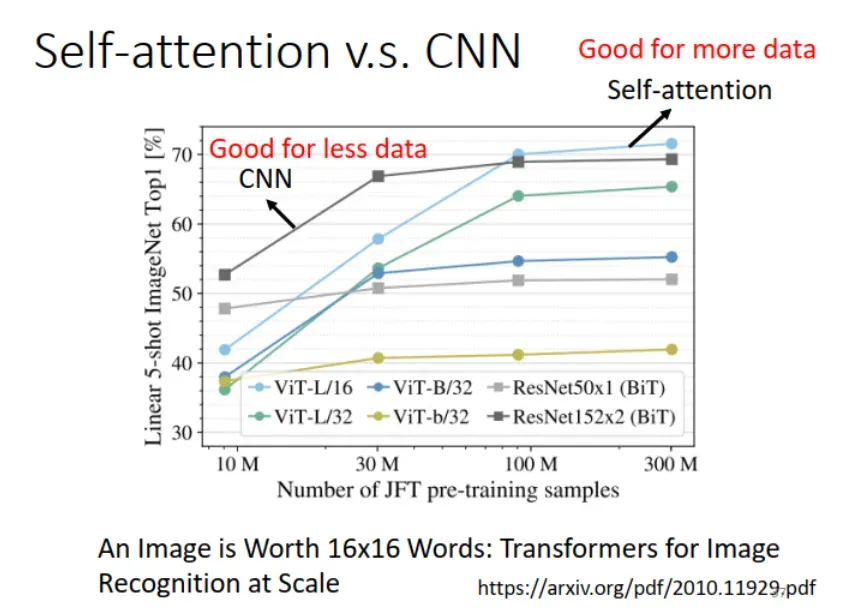
通过上面的分析可以发现,self-attention 复杂度更大 (more flexible),|H| 更大,因此需要训练集的数据量 N 更大。如下图所示,在图像识别 (Image Recognition) 任务上,数据量相对较小 (less data) 时,CNN 模型表现更好。数据量相对较大 (more data) 时,Self-attention 模型表现更好。
注意:以下的 less data 都有 10M (一千万)条数据,并不是我们想象中的小数据量哦,哈哈!
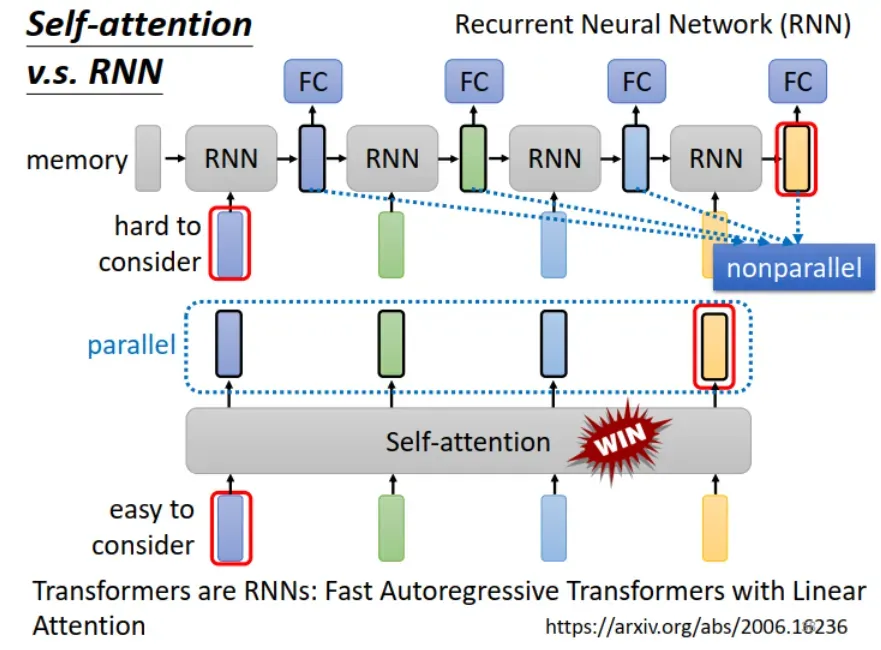
4. Self-attention v.s. RNN
在 self-attention 之前,输入为 sequence 时经常使用的网络结构是 RNN (Recurrent Neural Network)。下面来看一下这两者有什么不同。
第一印象:RNN 只能看之前的 vectors,self-attention 可以看整个句子。
其实不是,也有 bidirectional RNN,既从句首到句尾计算,也从句尾到句首计算,这样也可以看整个句子。
真正的不同之处在于:
(1)如下图所示,如果RNN 最后一个 vector 要联系第一个 vector,比较难,需要把第一个 vector 的输出一直保存在 memory 中。而这对 self-attention 来说,很简单。整个 Sequence 上任意位置的 vector 都可以联系,“天涯若比邻”,距离不是问题。
(2)RNN 前面的输出又作为后面的输入,因此要依次计算,无法并行处理。 self-attention 可以并行计算。
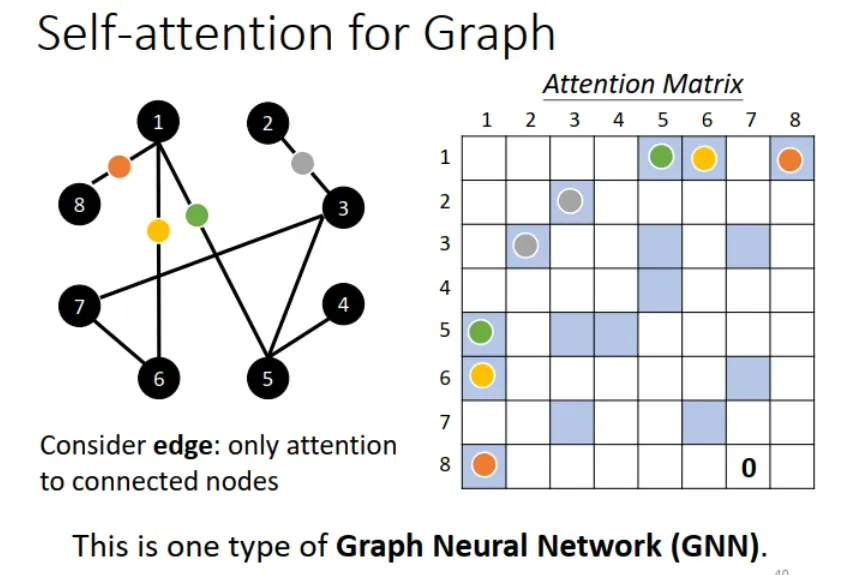
5. Self-attention for Graph
Graph 中,可以根据 edge 来简化 attention 计算。有 edge 连接的 nodes 就计算 attention,没有 edge 连接的就设为 0,这是 Graph Neural Network(GNN) 的一种。
觉得本文不错的话,请点赞支持一下吧,谢谢!
关注我 宁萌Julie,互相学习,多多交流呀!
阅读更多笔记,请点击 李宏毅老师《机器学习》笔记–合辑目录。
参考
李宏毅老师《机器学习 2022》:
课程网站:https://speech.ee.ntu.edu.tw/~hylee/ml/2022-spring.php
视频:https://www.bilibili.com/video/BV1Wv411h7kN
文章出处登录后可见!