Container简记
- 粗看了一遍,稍微记录下
参考
简记
- 港中文李鸿升团队从一个更广义的视角对Transformer、深度卷积以及MLP-Mixer进行了“大一统”,并由此提出Container,该方案在图像分类、目标检测以及实例分割方面取得显著的性能提升。
- 所谓的大一统就是本文的container,下文从两个方面展开:什么事container;如何整合DWConv、Transformer、MLP-MIxer
Container
-
定义如下:对于输入
,带残差的卷积可以表示为:
-
定义关联矩阵
,用于表示上下文关联程度的集合(就理解为Self-Att中的相似程度的分数这种的),于是Container可以被表示成:
- 可以把A看成self-att的相似度,V就简单理解成X的一个特征转换,AV的话就等价于att的一个效果,然后(AV)W1就理解成线性相乘,即可表示为卷积,+X就是Res
-
然后将V分片,(对应多头注意力、或者多课Conv Kernel这种情况)
-
整合DWConv、Transformer、MLP-Mixer
- 对于此三者我们需要抽取的是关联矩阵
。当然,剩下的部分也都是对应的(指线性计算对应,残差计算对应)
Transformer
- 懒得打公式了,常见self-Att中在关联矩阵是(就是KQ计算那一段,此时还没有乘上V):
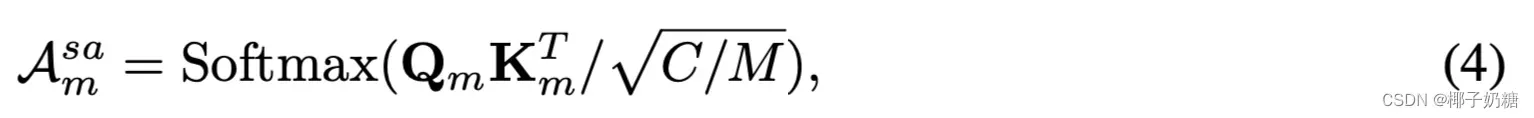
- 关联矩阵特点是;动态的(我的理解是对应着Self-Att的输入自适应性)
DWConv
- 对于1-d的卷积核(高阶矩阵依此推导即可),关联矩阵是:
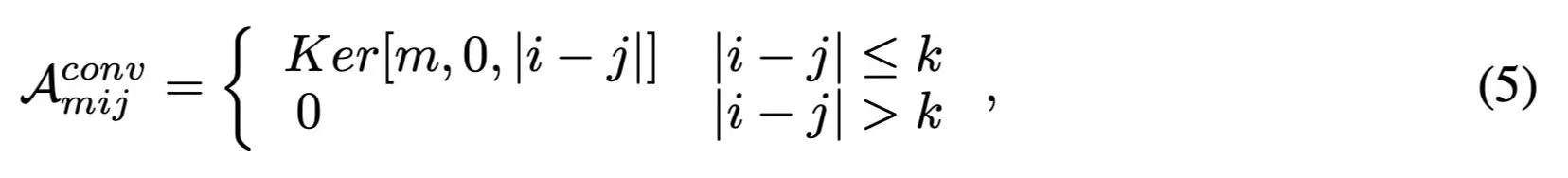
- 其中
- 其中
- 关联矩阵的特点是:静态的(权重不变)
MLP-Mixer
-
对于MLP-Mixer,其表达式可以表示为:
-
于是关联矩阵可以表示为:

-
关联矩阵的特点是:静态、稠密、参数不共享
Container Block的设计
-
对于上一节的描述,关联矩阵
-
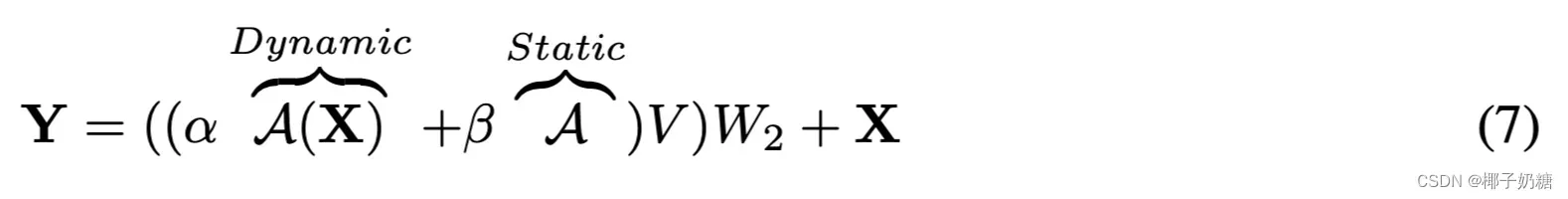
- α and β are learnable parameters
-
-
在这种情况下计算复杂度与朴素的Transformer相当
-
对应关系如下图所示:

Container-Light的设计
- 如果一开始就用Container Block势必会造成计算量过大的问题(参考Transformer的情况),于是作者提出在特征提取的前期使用静态的Container Block(即Conv),后期再用完整版,即
-
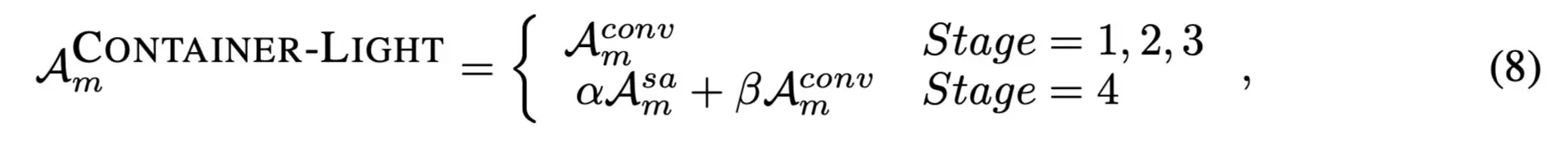
实验
-
具体略,大致看了以下,通过实验证明了:Container收敛速度快、精度高、同时具有Trans和Conv的优点
-
实验大致有:分类、检测(RetinaNet、Mask-RCNN、DETR)、分割(Mask-RCNN)、自监督学习
文章出处登录后可见!
已经登录?立即刷新