注意:没有“stepladder”的同学建议不要看啦
目录
1. 安装需要的包
1.1 安装SpeechRecognition包
pip install SpeechRecognition
1.2 安装 PockSphinx包
在线装总是失败,采用本地安装
https://www.lfd.uci.edu/~gohlke/pythonlibs/#pocketsphinx
本机该项目是python3.7的环境所以选择37
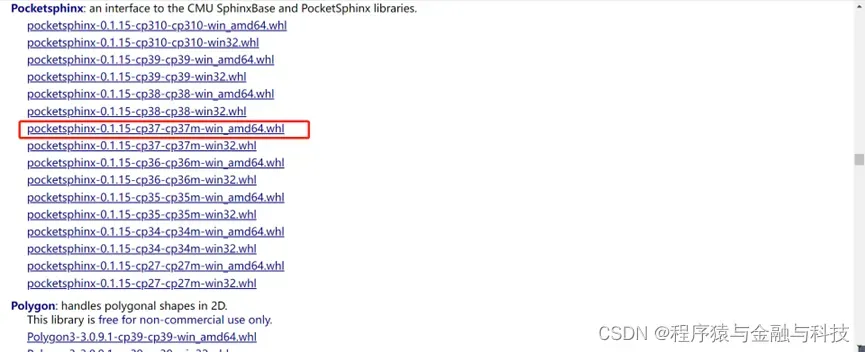
执行本地安装
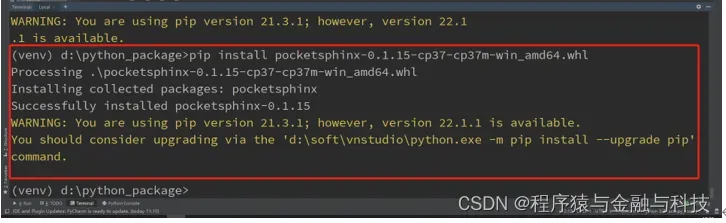
下载语言包
speech_recognition/pocketsphinx.rst at master · Uberi/speech_recognition · GitHub
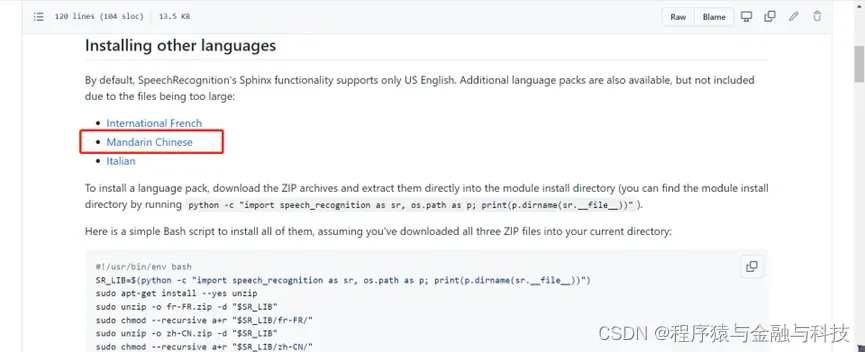

将下载后的文件复制到pocketsphinx的语言包目录下
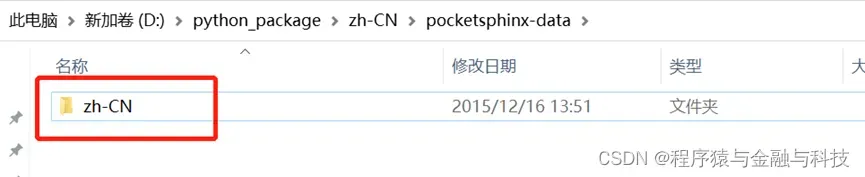
解压后如上图,将这个zh-CN文件夹复制到你自己python环境所在的目录下

1.3 安装moviepy
pip install moviepy
1.4 安装pydub
pip install pydub
2. 视频转音频
from moviepy.editor import AudioFileClip
from moviepy.video.io.VideoFileClip import VideoFileClip
from pydub import AudioSegment
from pydub.utils import make_chunks
import speech_recognition as sr
# 导入视频,提取音频并保存
def video_2_audio():
# 导入视频
one_audio_clip = AudioFileClip('D:/temp002/000.mp4')
# 提取音频并保存
one_audio_clip.write_audiofile('D:/temp002/000.wav')
pass本例中运行的000.mp4文件大约有35分钟,这个提取音频的过程挺慢的,用了好几分钟,为便于甄别最终效果,我对原始文件进行了切割,只对某一部分做处理
3. 对音频进行切割
def segment_audio():
pre_save_dir = r'D:/temp002/000_a/'
audio_file = r'D:/temp002/000.wav'
audio = AudioSegment.from_file(audio_file,'wav')
size = 30000 # 切割的毫秒数
chunks = make_chunks(audio,size) # 30s一个片段
for i,chunk in enumerate(chunks):
# chunk是切割好的文件
chunk_name = "v_{0}.wav".format(i)
print(chunk_name)
chunk.export(pre_save_dir+chunk_name,format='wav')
pass
pass将音频文件按30秒的时长进行切割
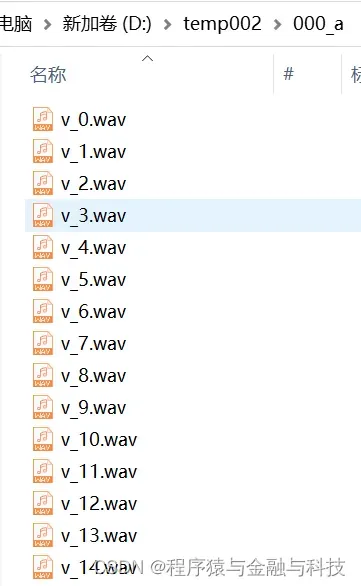
4. 对视频进行切割
# 切割视频
def segment_video():
pre_save_dir = r'D:/temp002/000_v/'
video_file = r'D:/temp002/000.mp4'
source_video = VideoFileClip(video_file)
video = source_video.subclip(0,30)
video.write_videofile(pre_save_dir+'0_v.mp4')
pass
视频切割耗费的时间比较长,我只切割出前30秒
5. 从音频中识别出文本
5.1 使用离线方法
def voice_to_text_local():
audio_file = 'D:/temp002/000/v_0.wav'
r = sr.Recognizer()
with sr.AudioFile(audio_file) as source:
audio = r.record(source)
res_txt = r.recognize_sphinx(audio,language='zh-CN')
print(len(res_txt))
print(res_txt)识别出的结果:
长度:241
地 调 降 耗 这里是 独裁 堡 市 选出 本期 士兵 是 中国 版 拉 纽 股 复 牌 系列 的 第四 期 市 地 县 也 使我们 中国 上市 公司 里 涨幅 最大 的 一批 公司 为 家 乐 福 看 他们 上市 以来 的 股价 走势 和 经济部 的 最终 目的是 在 邵 氏 公司 的 年报 里 寻找 确定 新的 投资 机会 本期 我们 付款 的 公司 说 它 称为 是 我们 先 看 上海 同 为 四 上司 以来 的 股价 走势 泰国 卫生 二零零零年 在 儿孙 交 所 上市结果非常糟糕。。。
5.2 使用在线方法
附加说明pycharm设置代理ip方法
File->Settings->System Settings->Http Proxy
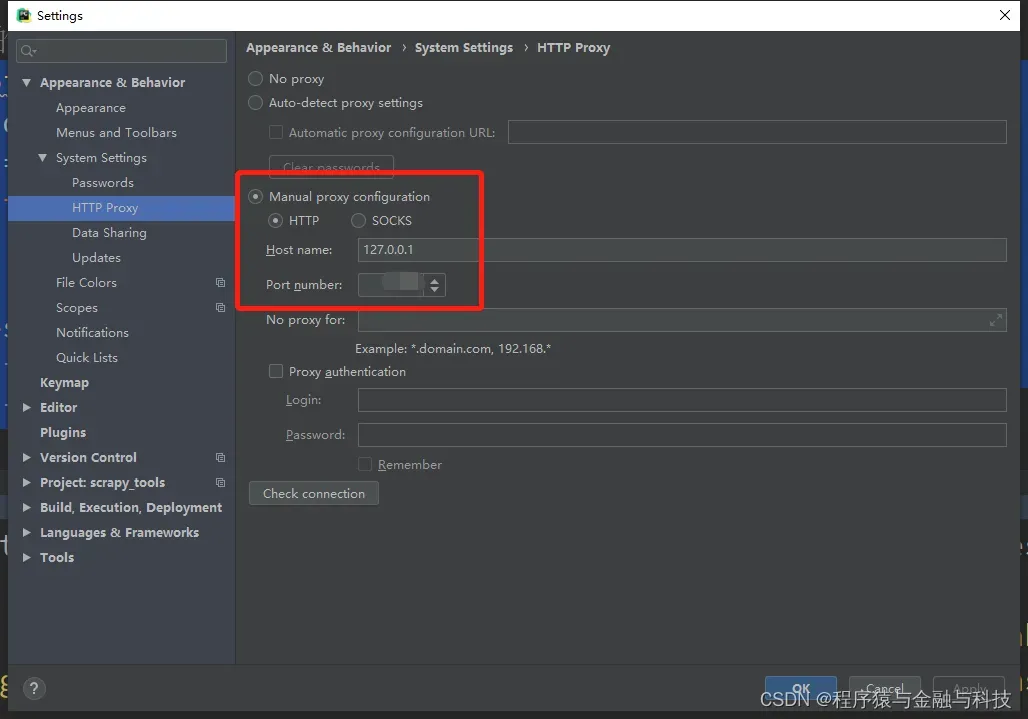
填上ip和端口
以下回归正题:
def voice_to_text():
audio_file = 'D:/temp002/000/v_0.wav'
r = sr.Recognizer()
with sr.AudioFile(audio_file) as source:
audio = r.record(source)
res_txt = r.recognize_google(audio,language='zh-cn')
print(len(res_txt))
print(res_txt)识别出的结果:
长度:149
大家好这里是独裁暴雪选股本期视频是中国百大牛股护盘系列的第4集这个系列是以我们中国上市公司里涨幅最大的一批公司为样本复盘他们上市以来的股价走势和经济路到最终的目的是在上市公司的年报里寻找确定性的投资机会本期我们付款的公司是海康威视我们先看一下海康威视上市以来的股价走势排行为是2010年在深交所上市还不错
5.3 两种方法比较
人工识别的结果:
大家好这里是读财报学选股本期视频是中国百大牛股复盘系列的第4集这个系列是以我们中国上市公司里涨幅最大的一批公司为样本复盘他们上市以来的股价走势和经济情况,最终的目的是在上市公司的年报里寻找确定性的投资机会,本期我们复盘的公司是海康威视我们先看一下海康威视上市以来的股价走势,海康威视在2010年在深交所上市比较两种方法:
本地方法获得的结果基本不可用;在线的方法没有出太多差错
6. 用到的包下载
链接:https://pan.baidu.com/s/1tDO3mNAqraBpbSnjqv6idQ
提取码:zpjk
文章出处登录后可见!