一、 *商科技公司


二 欧洲艾盛集团ISV公司
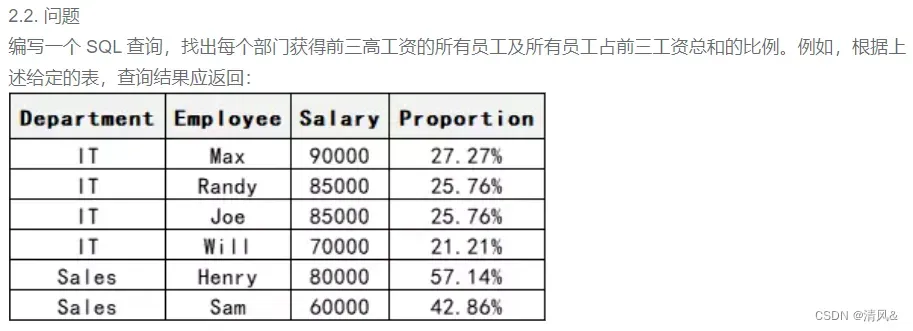
- BI笔试题


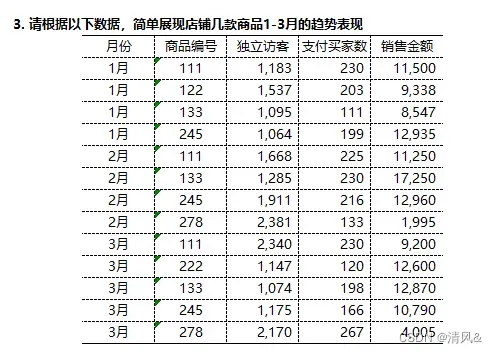
2.结构化思维考题:





三、闪****车新能源科技公司
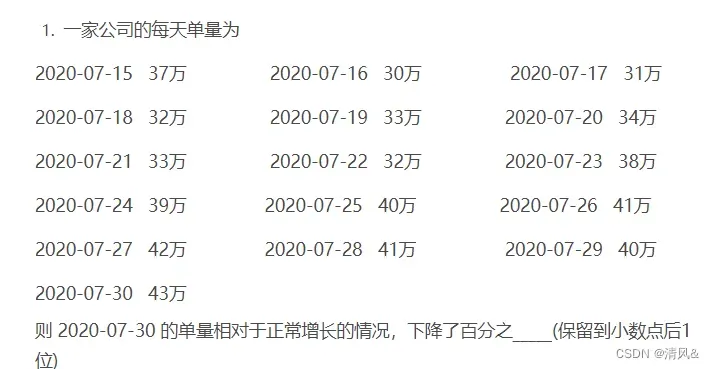
2. 一个箱子中有10个不同颜色的球,在里面随机取2~9个球,取出的球可能的组合有______种(填数字)
3.一个人做一件事出错的概率是0.3,如果做两件事,他都做对的概率为_______
3. 抛一个硬币出现正面的概率为0.3,出现反面的概率为0.5,还有0.2的概率会立起来,抛2个硬币,出现一正一反的概率为______
4. 如果在A发生的情况下B发生的概率为0.6,B发生的情况下C发生的概率为0.8,B不发生的情况下C发生的概率为0.7,则在A发生的情况下B、C至少有一个发生的概率为______
5. 在新冠肺炎疫情防控期间,某超市开通网上销售业务,每天能完成2300份订单配货,由于订单量大幅增加,导致订单积压,为解决困难,许多志愿者踊跃报名参加配货工作。已知该超市某日积压850份订单未配货,预计第二天的新订单超过3700份的概率为0.05,志愿者每人每天能完成50份订单的配货,为使第二天完成积压订单及当日订单的配货的概率不小于0.95,则至少需要志愿者______名 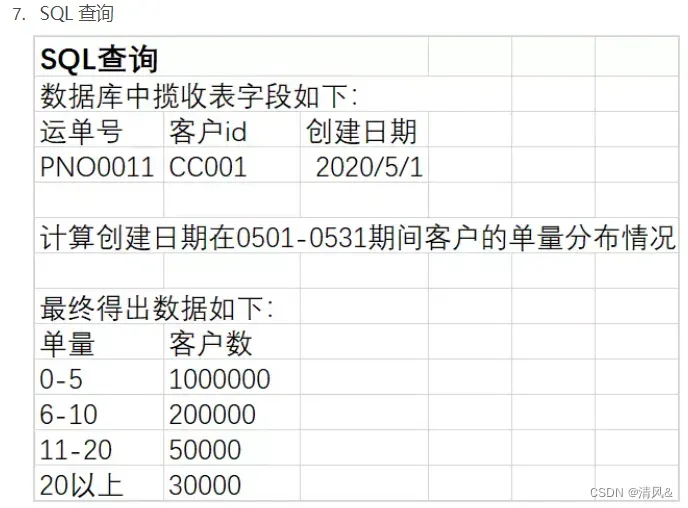 (很经典)
(很经典)
四、雷*科技公司 (算法)
一面
linux基本命令,是否会用git相关命令
K-Means算法的缺点,对异常值是否敏感
随机森林哪个模型支持回归?
一般常用二分类评价指标有哪些?
对于缺失值、异常值、空值怎么处理的?
项目整体流程如何落地的?
可视化库一般常用的是哪个?
numpy库一般用来做什么?
二面 技术面
Python底层清理机制
协程、进程、线程的区别 GIL锁
运算符重载
Python新版本特征
统计异常值数值
Python去重
迭代器、生成器的区别 分别编写一个迭代器和一个生成器
Python数据类型及其特点
Python如何优化代码,提升时间和空间复杂度
装饰器的特点,编写一个
时间序列模型
深拷贝和浅拷贝的区别和联系
其他公司
-
指标下跌如何归因?
(1) 确认数据是否准确及异常,判断这个下降是否合理(数据质量)
(2) 维度拆分
(3) 做出假设
(4) 细分假设,确立原因 -
A/B型指标下跌怎么归?除了拆维度还用过什么方法?为什么选择现在的方法
(1)A/B型顾名思义就是比重,在应用的时候有两种情况,一种是直接求比重,或者倍数,另外一种就是求整体或者部分的数值
比如说,2010年,某省地区生产总值达到A亿元,其中,第一产业增加值达到B亿元,那么第一产业增加值占该省地区生产总值的比重就是B/A;
如果说,2010年,某省地区生产总值达到A亿元,其中第一产业增加值所占比重为a,那么第一产业增加值为Aa亿元;
再比如说,2010年,某省第一产业增加值达到B亿元,占地区生产总值的比重为a,则该省地区生产总值为B/a亿元。所以先确定A/B型的计算方式,在进行拆分
其他方法:有业务经验直接分析。拆维度是比较标准的,对于熟练的分析师来说可根据实际经验来进行原因分析。 -
项目经历(特征值如何处理?为什么用这个方法等?
特征值:对于缺失值:删除 数值型类型:均值 中值 插值填充 对于类别 可用众数或者单独作为一个类别
对于异常值: 检验用箱线图 3c原则 和 describe函数查看 处理:对数处理 边界值插入 分箱离散化
主要围绕项目经历展开:目的?方法?怎么落地的?是独立完成的吗? -
好的指标体系是怎样的
一个好的指标体系能表现出公司或产品的表现现状,及时反映出问题,同时能提前预测或规避将要发生的问题。 -
如何确保指标体系是有序的?如何划分指标体系的层级?
在我们搭建数据指标体系时一定要按照某种关系来搭建指标,后续将我们能更加有效率的分析,例如在设计指标的体系的时候可以自上而下有业务域->需求域->实现域 以此来进行指标设计,或者自下而上由系统的功能模块逆推功能指标 功能域->需求域->实现域。再者可以根据场景拆分成多个子指标的和(DAU=日新增用户+留存用户+回流用户),或者按照一定的关系(逻辑关系和时间关系)。 -
用什么衡量用户xx行为的深度?
例举互联网产品来说,1.网龄(日均上网时间) 2.使用过的服务和产品数(广度) 3.对经常使用的服务和产品的了解(深度) 4.是否对某些产品或服务提供过建议5.对新鲜上线的服务和产品的敏感度 6.常用社交网络服务个数及活跃度,好友度 被关注数 -
如何进行异动分析?
-
确定数据源是否正确,是机器发生故障还是就是数据本身出现了问题
-
确定数据异动的类型,偶发性 周期性 和趋势性 (一般偶发和周期不考虑 只考虑趋势性)
-
维度拆解 业务维度和技术维度 业务维度有产品(产品线 产品类别 价格 功能 )和用户维度(用户属性 画像 地区 支付渠道),技术维度: PV,UV等功能模块是否出现异常,支付界面是否无法进行支付等
-
指标拆解 如果发现维度都在跌 可进行指标拆解
-
归因分析 确定了维度和指标后,进行归因分析.归因分析可分为内部(产品 运营 其他 )和外部(PEST 政治 经济 社会 技术)
-
A*B = C类型的指标,如果C下降了,如何归因?
先知道数据量,检验数据是否正确,其次确定下降的类型是否为偶发性?
如果是周期性,分别找出 C的维度进行拆分(A和B),将将确定的维度和指标确定下来,按照内外部归因,分别找出原因. -
讲一个项目,涉及聚类:
• 用的什么聚类方法?为什么用这个?
• 用了什么特征?如何做的特征处理?
• 如何确定要聚成这几类?
• 数据量的大小? -
还有什么涉及模型的项目?XGB相关的
• XGB都有什么参数?
• 为什么用这个模型?和其它决策树相比有什么差异? -
SQL的执行顺序?
FROM JOIN ON WHERE GROUP BY SUM AVG HAVING SELECT DISTINCT ORDER BY LIMIT -
pandas用什么包?缺失值怎么处理?
对于缺失值可以划分为两个维度重要性和缺失率,那么将产生四个区域,分别根据这四个区域做出不同策略, -
重要性高,缺失率高:其他渠道补全;其他字段计算,删除
-
重要性高,缺失率低:计算填充;根据业务经验填充
-
重要性低,缺失率高:删除
-
重要性低,缺失率低:不做处理或者简单处理
1.以下机器学习中,在数据预处理时,不需要考虑归一化处理的是:树型模型
2.数值特征归一化方法有:线性函数归一化和零均值归一化
3.需要通过梯度下降法求解的模型需要数值特征归一化:如线性回归、逻辑回归、支持向量机、神经网络模型。
(原因:随机梯度下降时,特征值相差大,会导致更新速度慢,需要兼顾特征值小的特征)
4.不需要特征归一化:决策树模型,决策树模型分裂根据信息增益,信息增益与特征归一化无关。
其他相关题目
1.字符匹配:
列名 [NOT ] LIKE
匹配串中可包含如下四种通配符:
_:匹配任意一个字符;
%:匹配0个或多个字符;
[ ]:匹配[ ]中的任意一个字符(若要比较的字符是连续的,则可以用连字符“-”表 达 );
[^ ]:不匹配[ ]中的任意一个字符
SUBSTRING_INDEX(str, delimiter, number) 截取字符串
SUBSTR(str, start, length) 长度必须一致
SUBSTRING(str, start, length) 长度必须一致
一 次日留存率
-- 方法一
-- 1.先查询第一天登录的用户数:
-- 2.在查询第二题继续登录的用户
-- 3.最后汇总求 留存率
select round(count(distinct user_id)/
(select count( distinct user_id) from login),3)
from login
where (user_id date) in
(select user_id,date_add(min(date),interval 1 day)
from login
group by user_id)
-- 方法二 窗口函数
-- 1. 先利用窗口函数计算每一行用户对应首次登录时间 设为a表
-- 2. 查找a表中登入时间和首次登入时间之差为1的数据,统计id出现的次数
-- 3. 算出第二日留存率:
select
round(count(distinct a.user_id)
/(select count(distinct user_id ) from login),3)
from
(select *,min(date) over(partition by user_id) as firstday
from login)a
where datediff(date,firstday)=1
---------------------------------------------------------------------
二 事物的四大特性 ACID
1.原子性(Atomicity) 事务包含的操作要么全部成功,要么全部失败回滚
2.一致性(Consistency) 事务必须使数据库从一个一致性状态变换到另一个一致性状态,
也就是说一个事务执行之前和执行之后都必须处于一致性状态
3.隔离性(Isolation) 多个用户并发访问数据库时,多个并发事务之间,应当相互隔离.
4.持久性(Durability) 事务的操作,一旦提交,对于数据库中数据的改变是永久的
三 数据库的三大范式
第一范式(1NF):确保数据库表的中所有的字段值都是不可分解的原子值
第二范式(2NF): 首先满足第一范式,另外,就是,一是表必须有一个主键,
二是非主键列必须完全依赖主键,而不能只依赖主键的一部分.
第三范式(3NF): 首先要满足第二范式,另外非主键列必须直接依赖主键,不能存在传递依赖,
即非主键列A依赖非主键列B,
非主键列B依赖主键的情况.
四 SQL 执行顺序和书写顺序
1.执行顺序
FROM
JOIN ON
WHERE
GROUP BY
AVG SUM
HAVING
SELECT
DISTINCT
ORDER BY
LIMIT
2.书写顺序
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
LIMIT
五 SQL的排序窗口函数
row_number() 按顺序来,无重复 1,2,3
rank() 占位 1,1,3 其中的2已被rank函数占用
dense_rank() 不占位 1,1,2 有重复可并列排序,序号继续使用
六 视图和游标
1.视图是一个或多个基本表或视图导出的表,是一个虚表,数据库中只存放视图的定义,
不存放视图对应的数据,对视图的操作最终都转化为基本表的操作。
2.游标是系统为用户开设的一个数据缓冲区,存放SQL语句的执行结果,
每个游标区都有一个名字。用户可以通过游标逐一获取记录并赋给主变量,
交由主语言进一步处理。
七 标识列 主键 索引
标识列:identity(int,1,1)。标识列可做为主键,只能为整型,针对一列而言。
主键:数值类型不限,只要不重复就行。可由多列组合而成,主键是关联中的主体,
是区别行数据的标识。
索引:为了提高查询效率,我们会对列建立索引,相当于建立一个列的排序。
(副作用:对系统造成极大的开销负担,不能滥用)。
主键:不能重复 非空 唯一
标识列:非空自增长 不可自行修改 主键和标识列相同点:非空 唯一
八 floor ceiling round sign trunc函数
1.floor() 向下取整,函数产生小于或等于指定值的最小整数
floor(3.145) ----> 3
2. ceil()或ceiling() 向上取整,产生大于或等于指定值的最小整数.
ceil(2.34)----> 3
ceiling(-3.13)-----> -3
3.round(value,precision) 根据指定精度输入数值
4.trunc(value,precision) 按精度截取某个数字,不进行舍入操作
5.sign() 与绝对值函数ABS()相反,ABS()给出的是值的量而不是其符号,sign()则给出
值的符号而不是量.
九 case when 函数 两种方式都支持else
1. 简单case函数 若比较的条件相同可放在case后面,只进行比较以确定结果,不进行计算.
case input_expression
when when_expression then result
else else_result_expression
end
2. case搜索函数 条件不同,则放在when后面,计算一组布尔表达式以确定结果.
case
when boolenan_expression then result
else else_result_expression
end
十 right()和left()函数
right('ABCDEF',2)------>EF
left('ABCDEF',2)------->AB
类似于sql中的substr()函数 substr(字符串,start,length)
十一 datediff()函数和timestampdiff()函数
datediff(startdate,end_date)函数返回两个日期之间的天数
timestampdiff(单位,start_date,end_date)
单位:day hour minute second 天 小时 分钟 秒
-----------------------------------------------------------------------
Hive SQL 相关知识
一 Hadoop 是一套开源软件平台 其功能:利用服务器集群对海量数据进行分布式处理.
二 Hadoop的核心组件:
1.HDFS:块级别的分布式文件存储系统
2.MapReduce:分布式计算框架 (分而治之的思想) 两个阶段 Map阶段:切分任务,
Reduce阶段:汇总任务
3.YARN:作业调度和资源管理器
4.Hadoop基础功能库
三 Hive 基于Hadoop的开源的数据仓库工具,用于处理海量的结构化数据.
Hive把HDFS中的结构化的数据文件映射成数据表,通过HiveSQL进行解析和转换,最终
生成一系列在Hadoop上运行的mapreduce任务,通过执行这些任务完成数据分析与处理.
四 HiveSQL 常用函数
1. show functions 查看hive中函数
2. desc function 函数名 查看函数的具体用法
3. from_unixtime(bigint unixtime,string format) 将时间戳转换为日期函数
五 HiveSQL核心技能--窗口函数
1. 累计计算窗口函数:
sum() over()
avg() over()
2.分区排序窗口函数:
row_number() over(partition by order by asc) 1,2,3 asc默认是升序,desc是降序
rank() over(partition by order by asc) 1,1,3
dense_rank() over(partition by order by asc) 1,1,2
3.切片排序窗口函数:
ntile(n) over(partition by order by)
4.偏移分析窗口函数
lag(字段名,offset,defval) over(partition by order by) 取前n行数据
lead(字段名,offset,defval) over(partition by order by ) 后n行数据
注意 没有默认值时,默认返回为NULL
六 HiveSQL表连接
1.inner join (inner可以省略不写) 表连接时必须必须进行重命名,先去重在进行表连接
2.left join 和 right join 效果几乎差不多,已某一个表为基础,进行左边拼接或者右边
拼接,没有对应的则显示NULL
3. full join 是将 left join 和 right join 的一种组合 不管哪一个表只要有的就都显示
3.union 和 union all
注意:字段名称必须一致,字段顺序必须一致,没有连接条件!没有连接条件!
区别:union all 不去重不排序 快
union 去重且排序 慢
七 HiveSQL 常用优化技巧
1.技巧一 列裁剪和分区裁剪 只读需要的列和分区
配置项:hive.optimize.cp 和 hive.optimize.pruner 默认为true
2.技巧二 排序技巧 sort by 代替 order by
order by 会按照某个字段进行全局排序,会统一放到一个reduce中,使用sort by 会启动多个
reduce 为控制map段分配到reduce中的key,使用distribute by
distribute by a sort by a
3.技巧三 去重技巧 使用group by 代替distinct 在极大的数据量时,使用group by可提高效率
4.技巧四 聚合技巧 grouping sets/cube/rollup
(1).grouping sets 指定分组的维度
查看性别城市等级分布 (多个分布需要些多次sql语句)
select sex,city,level,count(distinct user_id)
from user_info
group by sex,city,level
grouping sets(sex,city,level); grouping sets 指定分组的维度
(2).cube 根据group by 维度的所有组合进行聚合
性别城市等级的各种组合的用户分布
select sex,city,level,count(distinct user_id)
from user_info
group by sex,city,level
with cube;
(3). rollup 以最左侧的维度为主,进行层级聚合,是cube的子集
计算每个月的支付金额和每年的支付总金额
select year(dt) as `year`,month(dt) as `month`,sum(pay_amount)
from user_trade
where dt >'0'
group by year(dt),month(dt)
with rollup;
5. 技巧五 换个思路解题 条条大路通罗马
6. 技巧六 union all 时可以开启并发执行,hive中互相没有依赖关系的job间是可以并发执行额
参数设置: set hive.exec.parallel=true;
7. 技巧七 表连接优化
(1).小表在前,大表在后
(2).使用相同的连接键
(3).尽早的过滤数据 减少每个阶段的数据量,分区表要加分区,只选择需要使用的字段
8. 技巧八 遵循严格模式
严格模式:强制不允许用户执行3中有风险的HiveSQL语句,一但执行就会报错
(1).查询分区表时不限定分区列的语句
(2).两表join产生了笛卡尔积的语句
(3).要order by 来排序但没有指定limit的语句
开启严格模式 将参数 hive.mapred.mode = strict
建议:技术面一定要多做题,多去牛客刷刷大厂的题,才会有机会过。
文章出处登录后可见!