机器学习中的监督学习主要包括分类问题和回归问题,二分类问题是多分类问题的基础。
对于二分类问题,在测试数据集上度量模型的预测性能表现时,常选择Precision(准确率), Recall(召回率), F1-score(F1值)等指标。
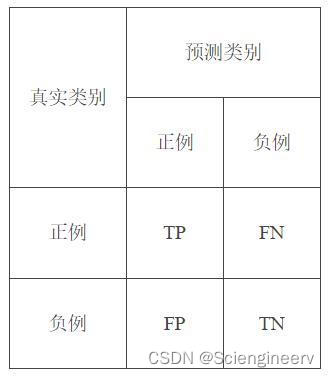
对于二分类问题,可将样例根据其真实类别和分类器预测类别划分为:
真正例(True Positive,TP):真实类别为正例,预测类别为正例的样例个数。
假正例(False Positive,FP):真实类别为负例,预测类别为正例的样例个数。
假负例(False Negative,FN):真实类别为正例,预测类别为负例的样例个数。
真负例(True Negative,TN):真实类别为负例,预测类别为负例的样例个数。
混淆矩阵(Confusion Matrix)如下表所示:

对于多分类问题,需要使用这些指标的”宏平均“(macro-average)与”微平均“(micro-average)。
宏平均(Macro-average),是先对每一个类统计指标值P、R、F1,然后在对所有类求算术平均值。
值得一提的是,欲求某一个类统计指标值P、R、F1,需计算这个类的TP、FP、FN、TN,需将这一个类视为正类,其余的所有类都视为负类(即将多分类转为n个二分类, 即one-vs-all,也称one-vs-rest , 其中n为类的个数)。
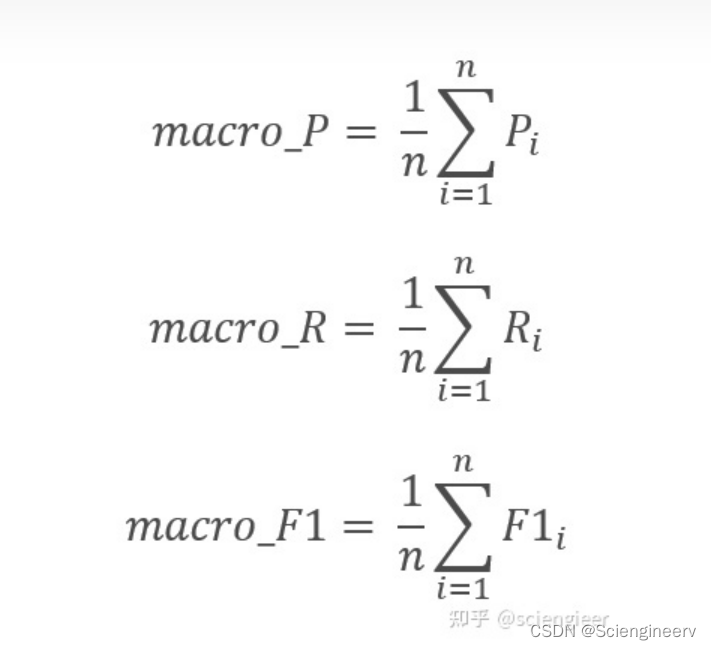
根据参考文献1,macro_F1还有另外一种说法:
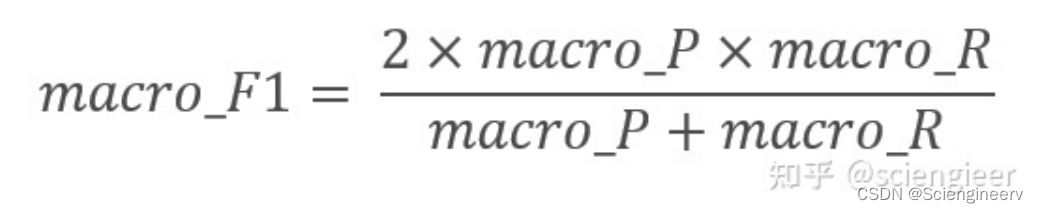
查找一番,竟然发现知乎上有大佬专门找了以上两种定义的macro_F1的论文(文献2)。目前来看,macro_F1为各类别F1算术平均值这种定义是主流,sklearn里面用的也是这种,文献2评论中有人提到有论文(https://arxiv.org/pdf/1911.03347.pdf) 表明算术平均值定义的macro_F1鲁棒性更好,有兴趣的同学可以研究一下。当然,有些限定计算方式的场合下(比如比赛)具体选用的哪种macro_F1得看实际情况。
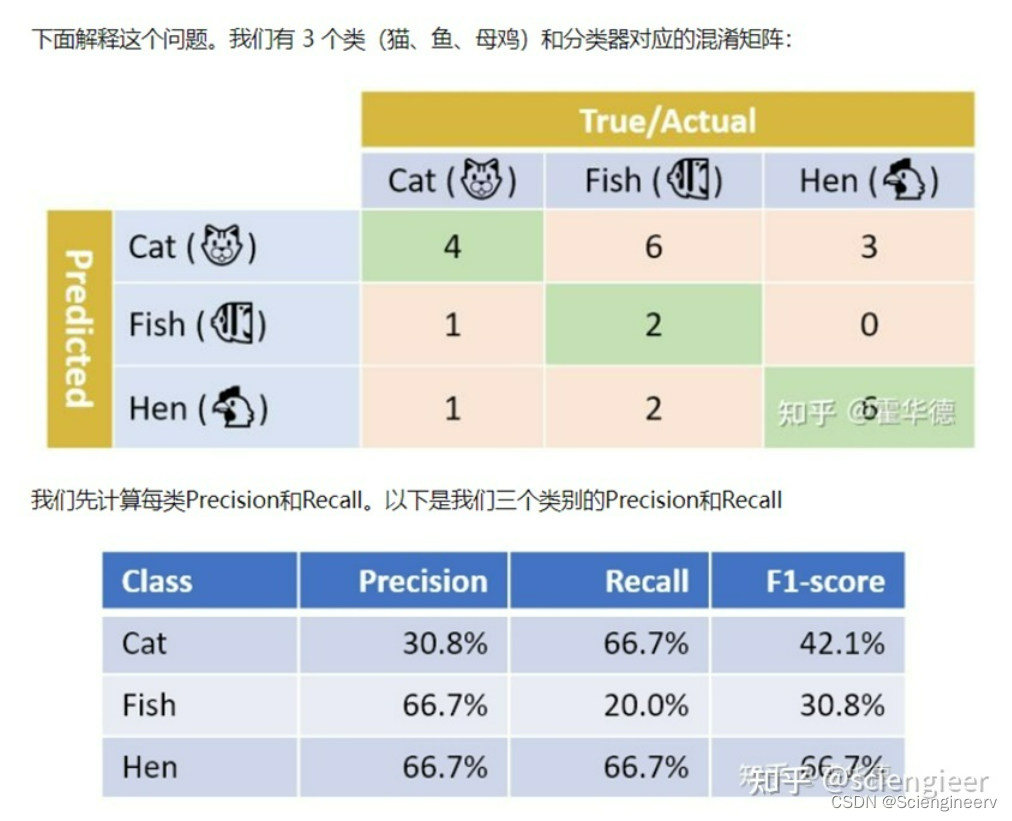
结合文献2中的例子,说明一下,多分类情况下,计算某一个类的TP、FP、FN、TN需将这一个类视为正类,其余的所有类都视为负类。这里以计算猫这个类的P和R为例:

微平均(Micro-average),是计算数据集总体的TP、FP、TN、FN (类别1、2、3……对应的TP、FP、TN、FN样例个数都分别加起来,同样地,这些样例个数计算方式是将多分类转为n个二分类, 即one-vs-all), 建立全局混淆矩阵,然后计算相应指标。

文献3给出了微平均的计算示例,截图如下:

参考资料:
- 谈谈评价指标中的宏平均和微平均
https://www.cnblogs.com/robert-dlut/p/5276927.html - 两个 Macro-F1 的故事
https://zhuanlan.zhihu.com/p/492625916 - sklearn中 F1-micro 与 F1-macro区别和计算原理
https://blog.csdn.net/lyb3b3b/article/details/84819931
文章出处登录后可见!