目录
一、像素级精度问题
关于解决像素级精度,一共可以分为3大类方法,如下图所示:
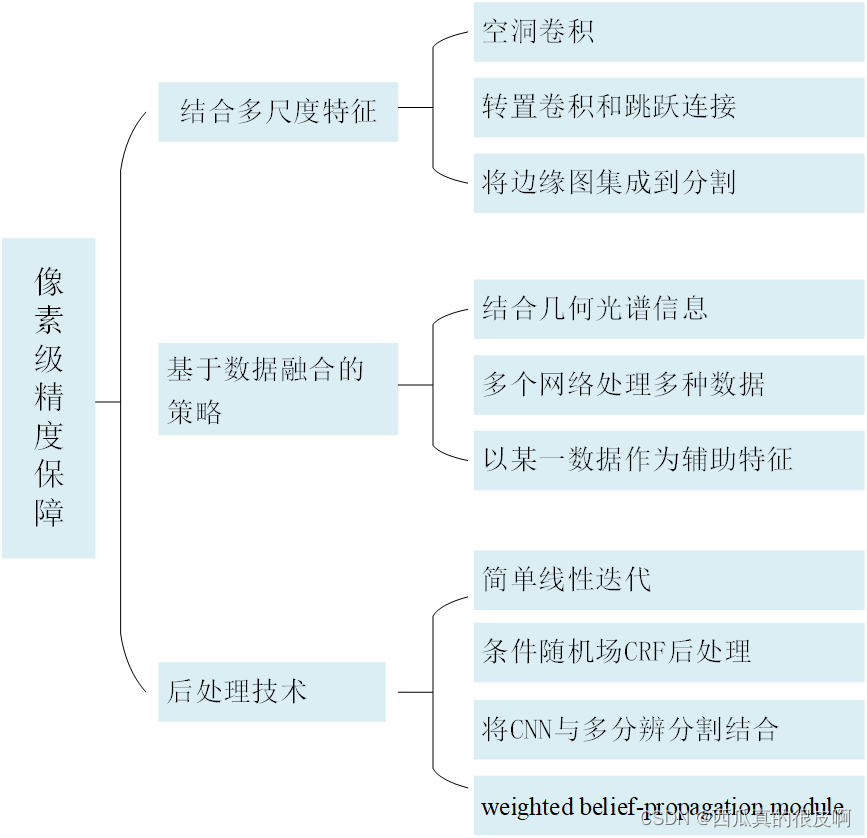
后处理技术没有详细学习,后面用到了再学吧!下面对结合多尺度特征和基于数据融合的策略做一个详细介绍。
1. 结合多尺度特征
1.1 空洞卷积
空洞卷积在语义分割里面非常常见,且很有效果,我们经常提到的有 dilated network、Deeplab系列网络都是基于空洞卷积。在这里,我选了一篇文章(也不是特别具有代表性,随便找的,刚好看了),简单介绍。
示例: Liu Y , Fan B , Wang L , et al. Semantic Labeling in Very High Resolution Images via a Self-Cascaded Convolutional Neural Network[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2018, 145(NOV.):78-95.
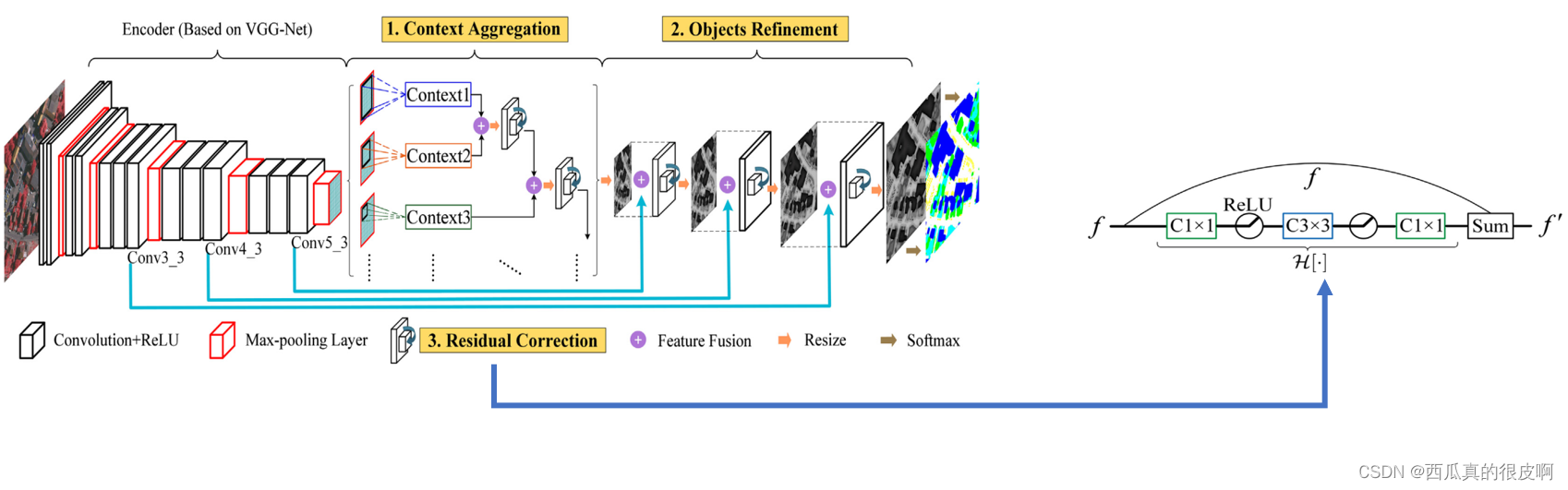
论文整体网络如上图所示。
这篇文章的整体框架:在下采样结束之后,利用不同膨胀系数的空洞卷积对最后的特征图进行处理,获得不同感受野的上下文特征(有点类似ASPP结构,但是后面的应用即融合不同),然后将其融合。随着网络的深化,cnn很难直接拟合所需的底层映射。此外,当涉及到融合不同级别的特征时,这个问题变得更加严重。其次,不同语义的多个特征融合时存在潜在的拟合残差,导致融合过程中信息的缺失。因此,本文设计了一种残差校正,用于校正多特征融合中语义空白引起的潜在拟合残差。
本文的亮点:
(1)多尺度语境聚合,用于识别易混淆的人为客体;
(2)利用底层特征对精细结构的对象进行细化;
(3)残差校正,更有效的多特征融合。
1.2 转置卷积和跳跃连接
转置卷积和跳跃连接的作用不用多说,已经有很多博主这块儿讲的非常好,大家可以自行百度。这里放一个经典网络,基于Unet的改进,DeepUnet
示例:DeepUNet: A Deep Fully Convolutional Network for Pixel-Level Sea-Land Segmentation[J]. IEEE, 2018(11).
DeepUnet的整体网络图如下图所示,它和Unet的不同主要是将Unet中的卷积层换成了DownBlock和UpBlock,不管是长采样还是下采样,都有一个Plus操作。
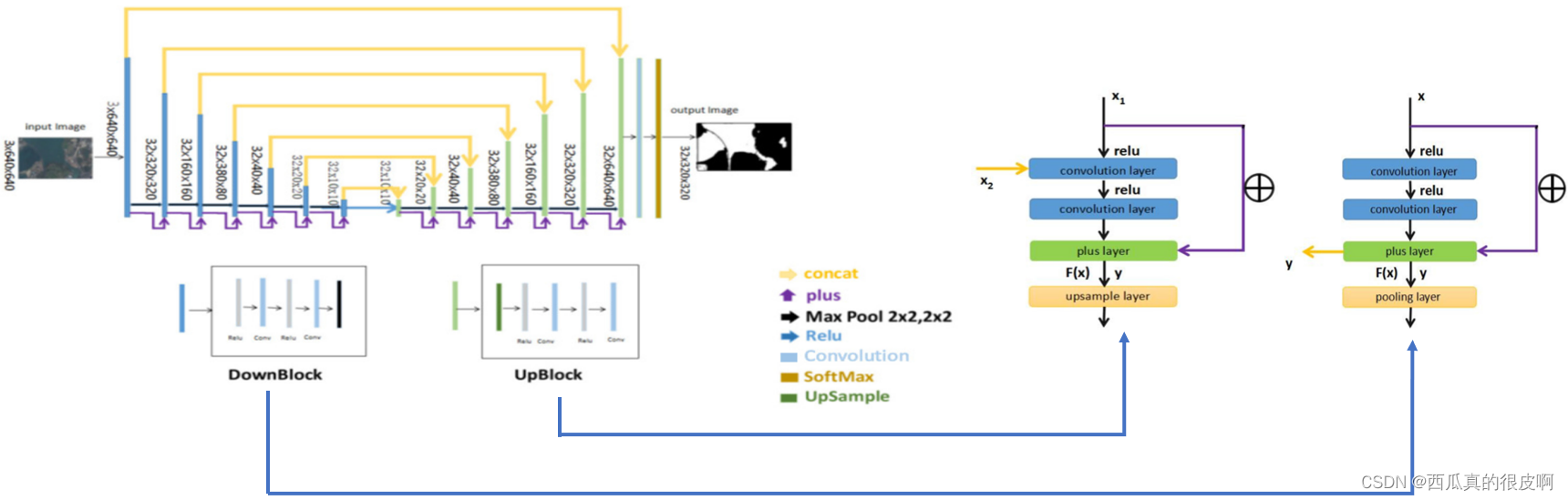
1.3 将边缘图集成到分割
将边缘图引入,其实一开始做语义分割的时候,我当时基本没怎么看论文,想着可以利用边缘来引导分割,感觉这真是个绝妙的点子,看了论文后才发现,别人2016年的时候就做了,真的笑死,果然,做科研的时候,如果你有一天突然觉得自己想到一个宇宙无敌绝妙的点子,清醒点,你一定是论文没看够!!!
示例: Fid A , Fw B , Pc A , et al. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data – ScienceDirect[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 162:94-114.
本文提出了一种ResUnet-a网络结构,整体就是借鉴了Unet的框架和Resnet的思想,网络结构图如下:
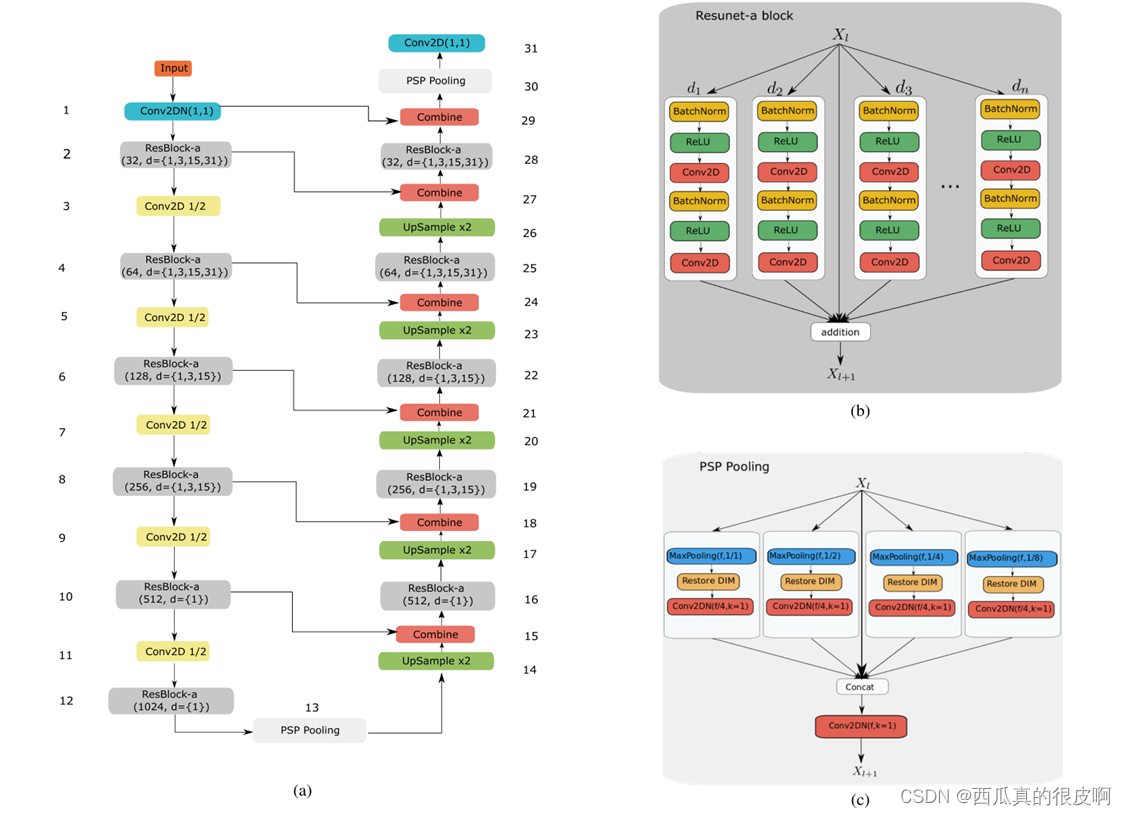
ResUNet-a 使用Unet的编码器/解码器主干,结合残差连接、atrous卷积、金字塔场景解析池和多任务推理。该方法推导出目标边界、分割掩码的距离变换、分割掩码以及输入的重构。(整一个大融合)
2. 基于数据融合的策略
2.1 结合几何和光谱信息来提高分割精度
示例: Maggiori E , Tarabalka Y , Charpiat G , et al. High-Resolution Aerial Image Labeling With Convolutional Neural Networks[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, PP(12):1-12.
采用不同分辨率的多个中间特性并结合它们似乎是一种合理的方法,可以特别解决本地化/识别权衡问题,就像跳跃网络一样。在这种方案中,高分辨率特征具有较小的接收野,而低分辨率特征具有较宽的接收野。结合它们确实构成了对资源的有效利用,因为我们实际上不需要高分辨率滤波器来拥有广泛的接受域,遵循下图的原则(离中心像素越远,分辨率可以越低,不影响整体分类结果)。

在作者提出的方案中,从网络中提取中间特征,并平等对待,创建一个来自不同分辨率的特征池。然后神经网络学习如何结合这些特征来给出最终的分类结论。这增加了学习不同解析之间更复杂关系的灵活性,并推广了跳跃体系结构的元素级添加。跳跃网络结合了来自不同分辨率的预测,即每个类的得分图。
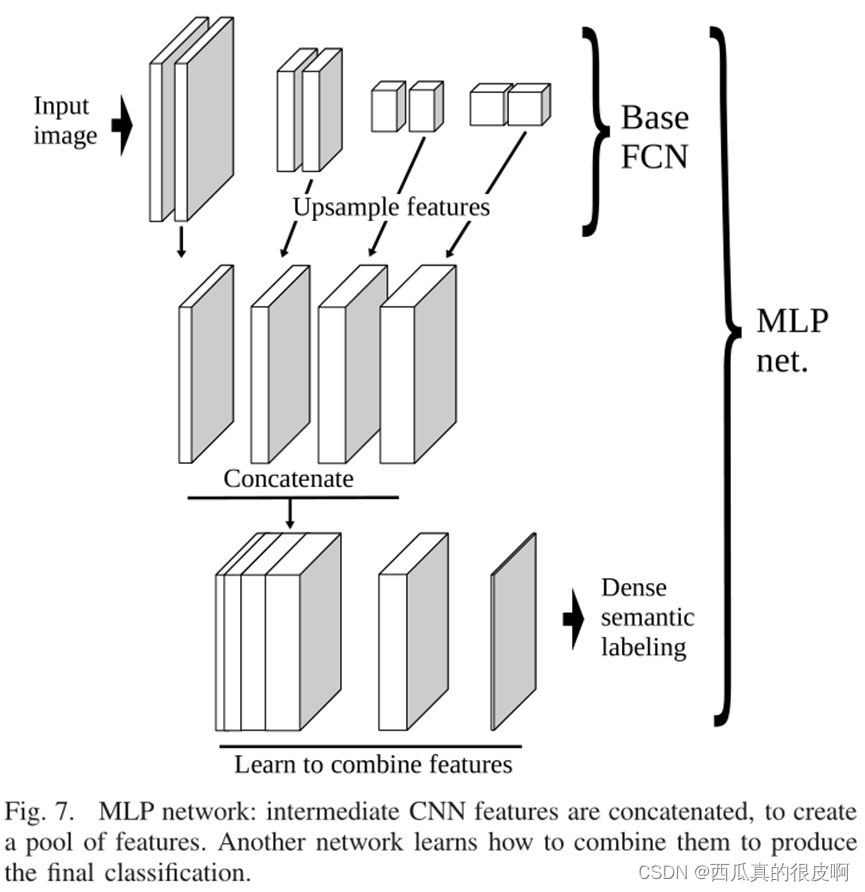
整个过程如下图所示,包括以下步骤:
1)从网络中提取中间特征子集。这些单纯的上采样,以匹配分辨率更高的特征的分辨率。需要注意的是,cnn通常会学习更多上层的特征(由下图中区块深度的变化表示)。
2)然后这些被连接起来创建特性池。注意,虽然特征图的空间维度都是相同的,但它们最初来自不同的分辨率。通过这种方式,跨空间特征响应的变化将在某些地图上更平滑,而在其他地图上更尖锐。
3)神经网络从特征池中预测最终的分类图。这个网络以像素为基础运行,假设所有的空间推理都已经在前面的步骤中传递了。
2.2 多种数据+多个网络结构
在传统遥感影像的处理过程中,也经常会用到其他类型的数据一起处理,例如光学影像+SAR影像+激光雷达数据,还有遥感影像数据结合高精度DEM、DOM、DSM。这里我看了一篇稍微有点老的文章,主要是为了和下面一篇文章形成对比,因为两者都用的是光学影像+DSM,但是做法不同。有需要的大家可以再找找,应该有很多这类文章。
示例:Marmanis D et al. Semantic Segmentation of Aerial Images with an Ensemble of CNSS[C]// ISPRS Congress. ISPRS Annals of Photogrammetry, Remote Sensing and Spatial Information Sciences, 2016.
作者提出,使得非常高分辨率图像的自动化特别具有挑战性的是,一方面他们的光谱分辨率(光谱分辨率指成像的波段范围,分得愈细,波段愈多,光谱分辨率就愈高,细分光谱可以提高自动区分和识别目标性质和组成成分的能力。)本来就比较低,另一方面小物体和小尺度表面纹理变的可见。总之,这导致图像的高类内可变性同时低类间差异。
2.3 以某一数据作为辅助特征
和上面那篇文章不同,这里的DSM没有训练,它是作为辅助来帮助整个网络训练的更好。
示例:Sun W , Wang R . Fully Convolutional Networks for Semantic Segmentation of Very High Resolution Remotely Sensed Images Combined With DSM[J]. IEEE Geoscience & Remote Sensing Letters, 2018:1-5.
作者提出了一个基于形态学运算的DSM后端,从彩色图像和DSM中同时提取互补信息。
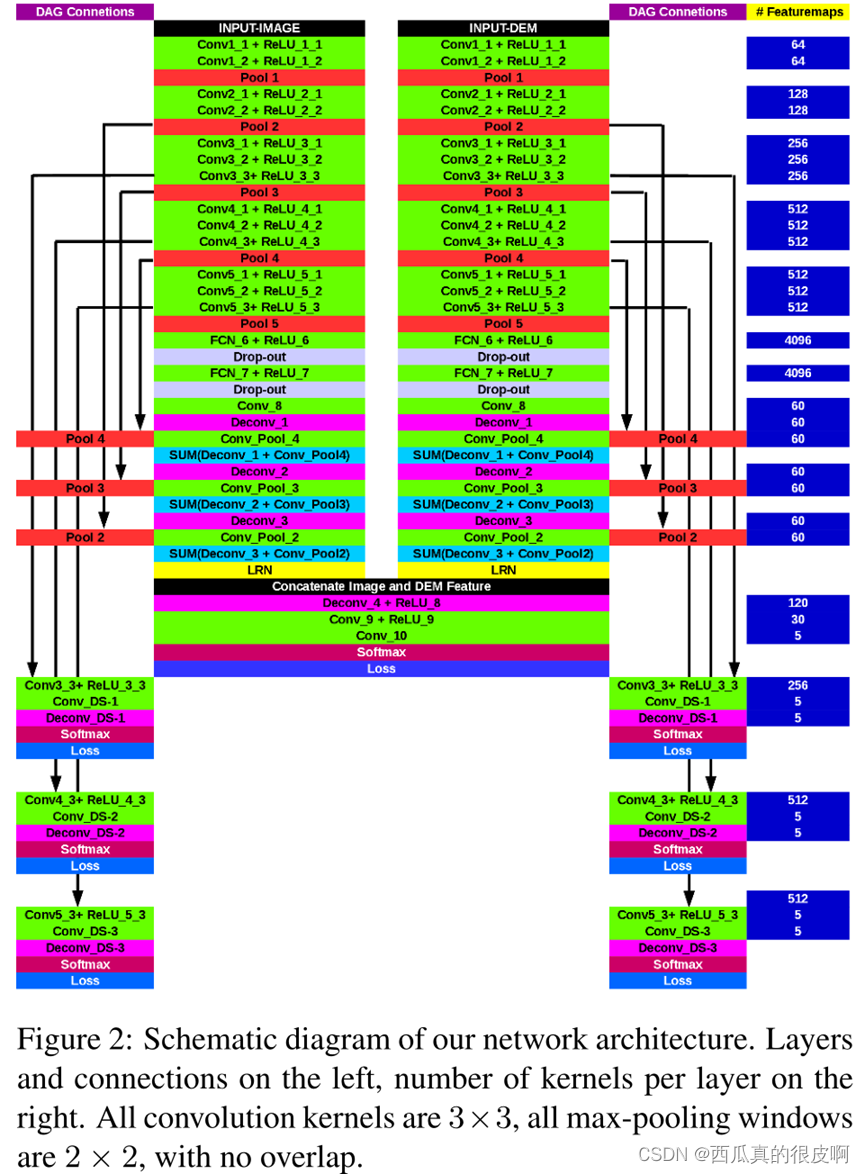
本文的主要贡献是基于DSM的VHR遥感图像语义分割方案。如下图所示,所提出的方案包括两个部分:1)使用所提出的MFS(maximum fusion strategy)的FCN从彩色图像中计算初始标签图,2)使用初始标签地图和DSM,提出DSM后端来纠正FCN结果中的错误。DSM后端根据FCN的初始标签图从DSM中提取地表。利用地面对FCN结果进行细化。该方法有效地融合了彩色图像的光谱信息和DSM的几何信息,改善了VHR遥感图像的语义分割。

(1)最大融合策略
对于像素到像素的融合,双线性插值恢复分数映射从单位到相同大小的输入图像。高分辨率的浅层单元插值步长较小,能够保持相对精细的边界信息。因此,来自深层单位的分数比来自浅层单位的分数包含更多语义,但更少的细节。融合策略的目标是通过融合不同单元评估的类分数来结合语义和细节。需要注意的是,语义和细节的性能取决于区域类型。因此,我们建议MFS可以选择性地选择不同区域的语义和细节。在正向过程中,(c)类的最终得分计算为

(2)DSM后端处理
DSM后端完成三个任务:1)根据DSM和FCN计算的对应的初始标签图,计算每个像素到周围地面(H2G)图像的高度;2)根据H2G图像去除假top-hats;3)根据H2G图像去除假ground。
作者提出了三种基于形态学操作的算法策略:
① H2G图像:首先,基于FCN结合MFS整体准确率(OA)达到90%以上的情况,提取大型地物(即草地和道路)的掩模。其次,计算地表,即剔除非地表区域后的DSM(ground_DSM)。采用修复方法从ground_DSM中恢复非ground区域的高度。第三,通过DSM减去地表得到H2G图像。
② False Ground:利用H2G图像,计算初始标签地图中虚假Ground的掩码。我们通过对初始标签图编码,使top-hats(顶帽)的数量较大,而地面的数量较小,对初始标签地图进行膨胀操作,将top-hats包围在一个固定大小的窗口内,以取代错误的地面。在计算假地掩模之前,我们对H2G图像进行了小尺寸核(5 × 5)的侵蚀操作,以避免在DSM不准确的屋顶边缘出现假地掩模的错误。因此,该算法对DSM中锯齿状屋顶边缘等噪声具有较强的鲁棒性。
③ 假Top-Hat:首先我们对H2G图像进行扩张操作。其次,利用H2G图像计算假礼帽掩模;第三,对编码后的标签映射进行侵蚀操作,去除假帽子。
二、非常规数据分析
关于非常规数据,在遥感领域里,高光谱数据(几十成百个谱段)、SAR数据、点云数据,都和传统的自然影像有很大差异,所以把他们定义为非常规数据,这里的非常规不代表数据本身有任何问题。
关于解决非常规数据分析,目前方法分类如下:
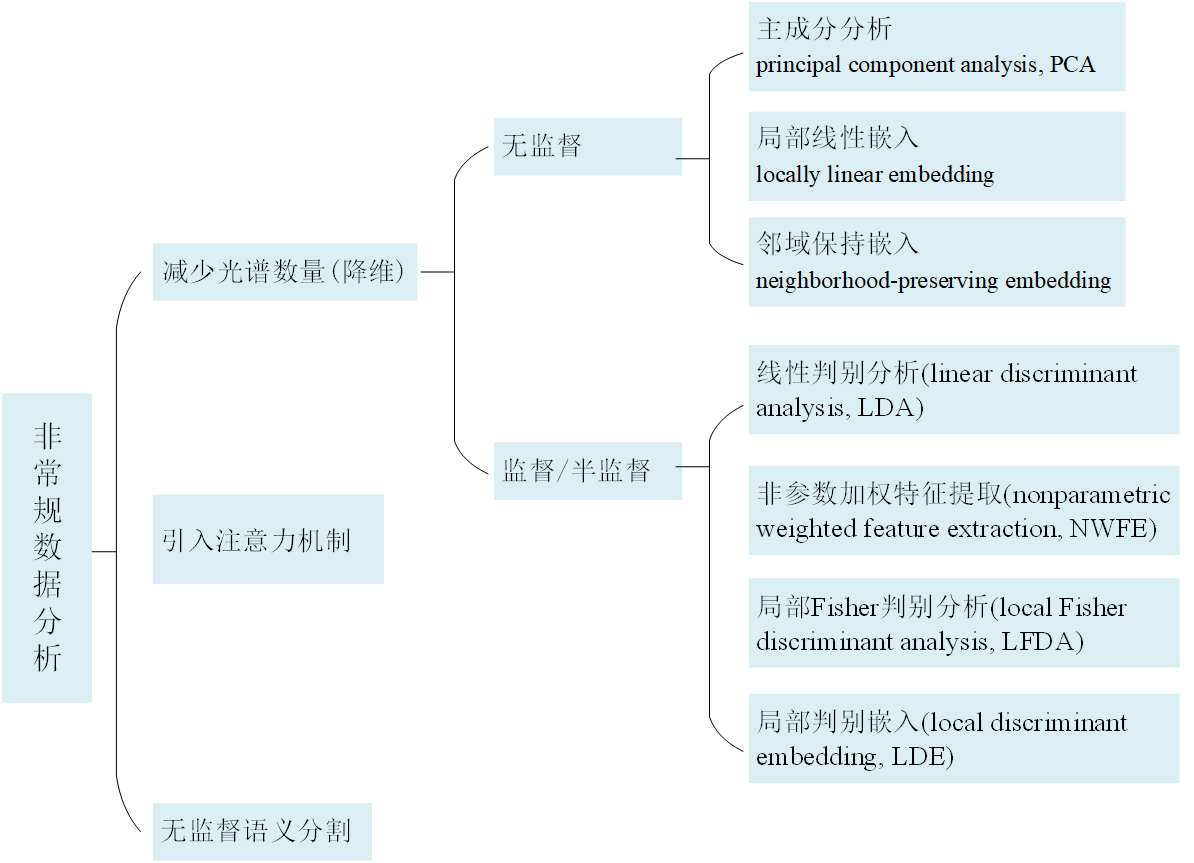
1. 减少光谱数量
示例:Zhao W , Du S . Spectral–Spatial Feature Extraction for Hyperspectral Image Classification: A Dimension Reduction and Deep Learning Approach[J]. IEEE Transactions on Geoscience and Remote Sensing, 2016, 54(8):4544-4554.
降维是不使用全光谱波段进行数据处理,而是寻求高光谱影像(Hyperspectral images,HSI)解释的低维表示。因此,降维可以有效地找到类特定的子空间,也可以更好地解释性能。
(1)论文框架
在SSFC(spectral–spatial feature based classification)中,采用BLDE方法对高维光谱信息进行降维处理,提取低维光谱特征。空间特征是通过训练CNN在原始数据集的少数第一主成分(PC)波段上得到的。采用特征融合技术[26]生成光谱空间特征。最后,基于光谱-空间特征组合训练分类器,如下图所示。本文提出的SSFC方法的特点如下。1)提出了一种基于cnn的空间特征提取方法用于HSI分类。与传统手工提取的数字空间特征相比,提取的数字空间特征具有更强的鲁棒性和有效性。2)所提出的BLDE能够平衡局部保持散射矩阵和类间散射矩阵,从而获得更好的判别投影。3)将光谱特征与基于cnn的空间信息相结合的策略可以很好地揭示原始数据所包含的内在属性。
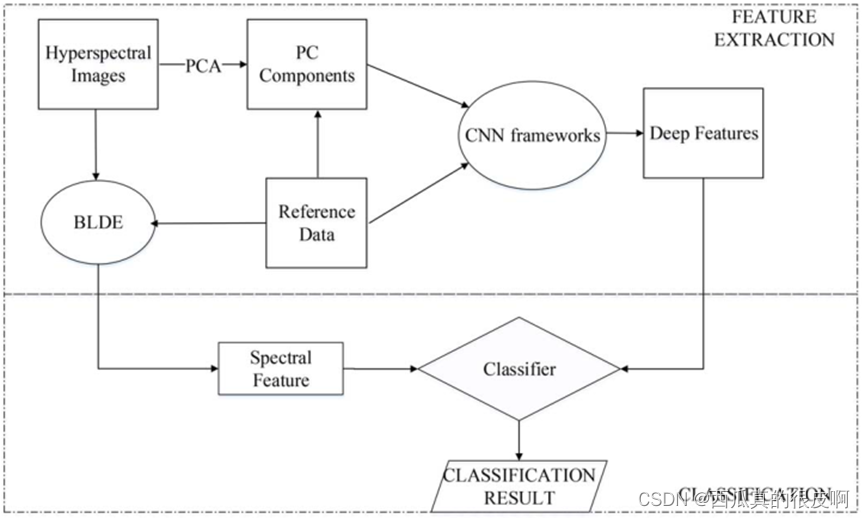
论文提出的基于光谱空间特征的分类(spectral–spatial feature based classification,ssfc)的HSI分类算法结构如上图所示。它可以分为两个主要部分。第一步,分别提取光谱特征和空间特征;对于光谱数据,通常建议采用降维方法降低光谱维数;具体而言,本研究选择(balanced local discriminant embedding,BLDE)算法对HSI图像进行低维表示。利用CNN框架自动提取与空间相关的高层次深度特征。然后,将基于bldeb的光谱特征与基于cnn的空间特征叠加,得到所提出的光谱空间特征。最后,将叠加的特征输入LR分类器,得到分类结果。
2. 无监督/半监督分割
2.1 关于自编码器的学习
网上很多,里面的图大多来自其他博主的:
(1)自编码器模型
自编码器可以理解为一个试图去还原其原始输入的系统。自编码器模型如下图所示:
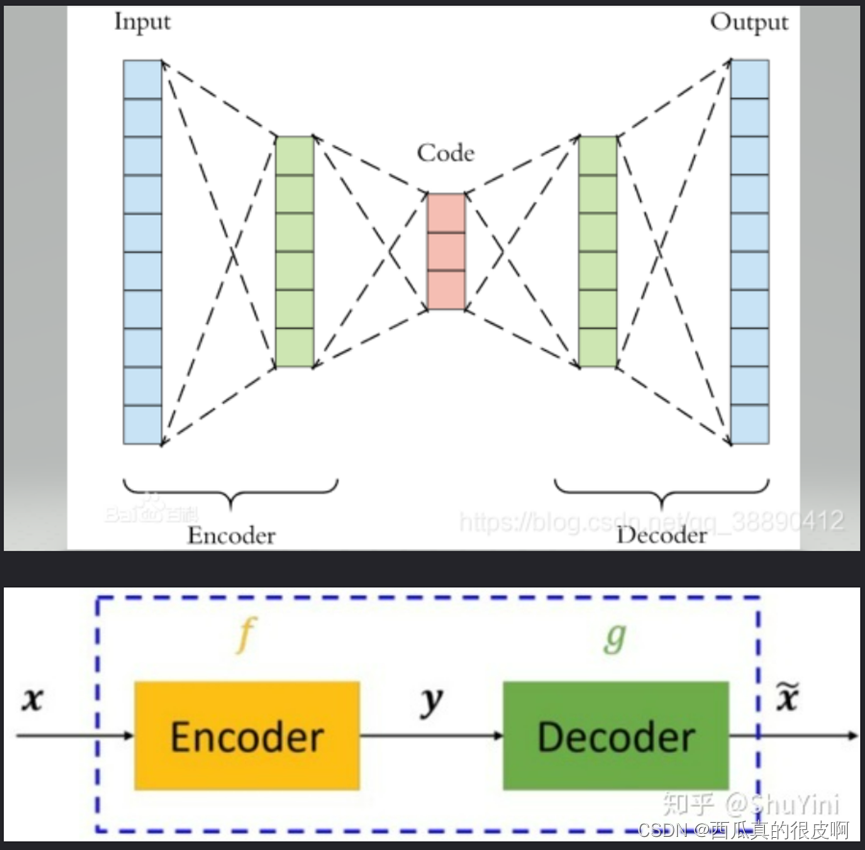
从上图可以看出,自编码器模型主要由编码器(Encoder)和解码器(Decoder)组成,其主要目的是将输入x转换成中间变量y,然后再将y转换成x![]() ,然后对比输入x和输出x
,然后对比输入x和输出x![]() 使得他们两个无限接近。
使得他们两个无限接近。
(2) 神经网络自编码模型
在深度学习中,自动编码器是一种无监督的神经网络模型,它可以学习到输入数据的隐含特征,这称为编码(coding),同时用学习到的新特征可以重构出原始输入数据,称之为解码(decoding)。从直观上来看,自动编码器可以用于特征降维,类似主成分分析PCA,但是其相比PCA其性能更强,这是由于神经网络模型可以提取更有效的新特征。除了进行特征降维,自动编码器学习到的新特征可以送入有监督学习模型中,所以自动编码器可以起到特征提取器的作用。举个例子,我有一张清晰图片,首先我通过编码器压缩这张图片的大小(如果展现出来可能比较模型),然后在需要解码的时候将其还原成清晰的图片。具体过程如下图所示:
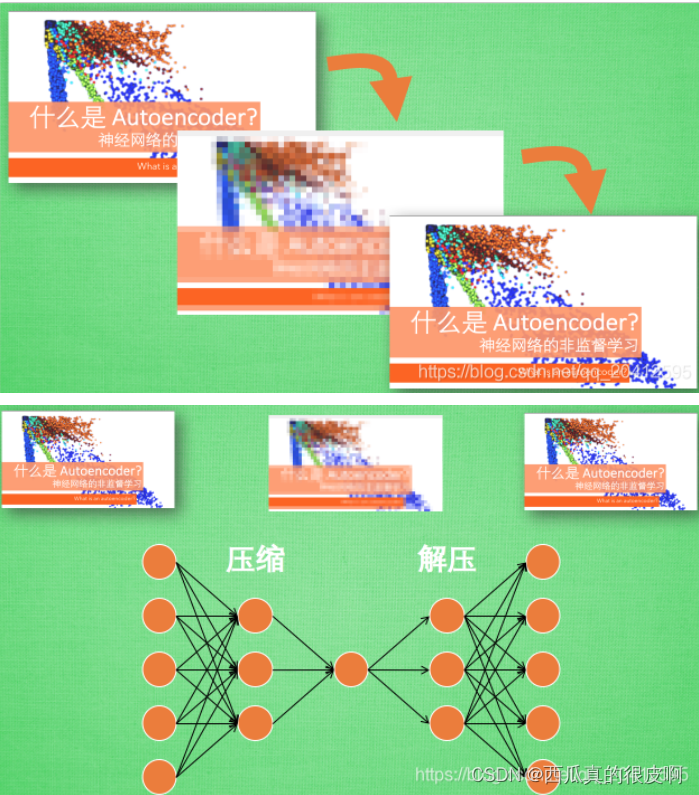
这个图片来自:(39条消息) 神经网络中自编码器Autoencoder_且行且安~的博客-CSDN博客_自编码器神经网络
(3) 自动编码器的三个特征
① 自动编码器是数据相关的(data-specific 或 data-dependent),这意味着自动编码器只能压缩那些与训练数据类似的数据。比如,使用人脸训练出来的自动编码器在压缩别的图片,比如树木时性能很差,因为它学习到的特征是与人脸相关的。
② 自动编码器是有损的,意思是解压缩的输出与原来的输入相比是退化的,MP3,JPEG等压缩算法也是如此。这与无损压缩算法不同。
③ 自动编码器是从数据样本中自动学习的,这意味着很容易对指定类的输入训练出一种特定的编码器,而不需要完成任何新工作。
2.2 关于无、半监督的示例论文
示例:Ronald K , Ryan L , Christopher K . Low-Shot Learning for the Semantic Segmentation of Remote Sensing Imagery[J]. IEEE Transactions on Geoscience & Remote Sensing, 2018, PP:1-10.
自学特征学习侧重于特征在附加数据上的无监督学习,然后在有监督系统中使用这些特征。半监督算法通过监督学习和无监督学习来提高监督任务上的泛化能力,从而提高测试数据上的分类性能。在这两种情况下,当只给出少量标记HSI样本时,无监督学习有助于这些算法避免过拟合。
半监督框架赋予模型增加特征空间维度的能力,这使它们能够了解对优化性能最重要的特性,也使它们能够在很少注释数据的情况下保持良好的性能。
(1)本文的主要贡献如下:
1)作者描述了用于非rgb遥感影像空间光谱特征提取的堆叠多损耗卷积自编码器(SMCAE)模型(见下图)。SMCAE采用无监督自学学习的方法获得了一个深度的特征提取库。SuSA使用SMCAE进行特征提取。
2)作者提出了半监督多层感知器(SS-MLP)模型用于非rgb遥感图像的语义分割。SuSA利用SS-MLP对来自SMCAE的特征表示进行分类,而SS-MLP的半监督机制使其在低镜头学习中表现良好。
3)作者证明,SuSA在IEEE GRSS数据和算法标准评估(DASE)以及ISPRS数据集上实现了最先进的结果。
(2)论文的主要框架
作者描述了如下图所示的自教半监督自动编码器(self-taught semi – supervised autoencoder, SuSA)语义分割框架。SuSA的设计是为了在图像注释稀缺的多光谱(multispectral image,MSI)和高光谱(Hyperspectral image, HSI)数据上表现良好。SuSA由两个模块组成。第一个模块负责提取空间光谱特征,第二个模块对这些特征进行分类。
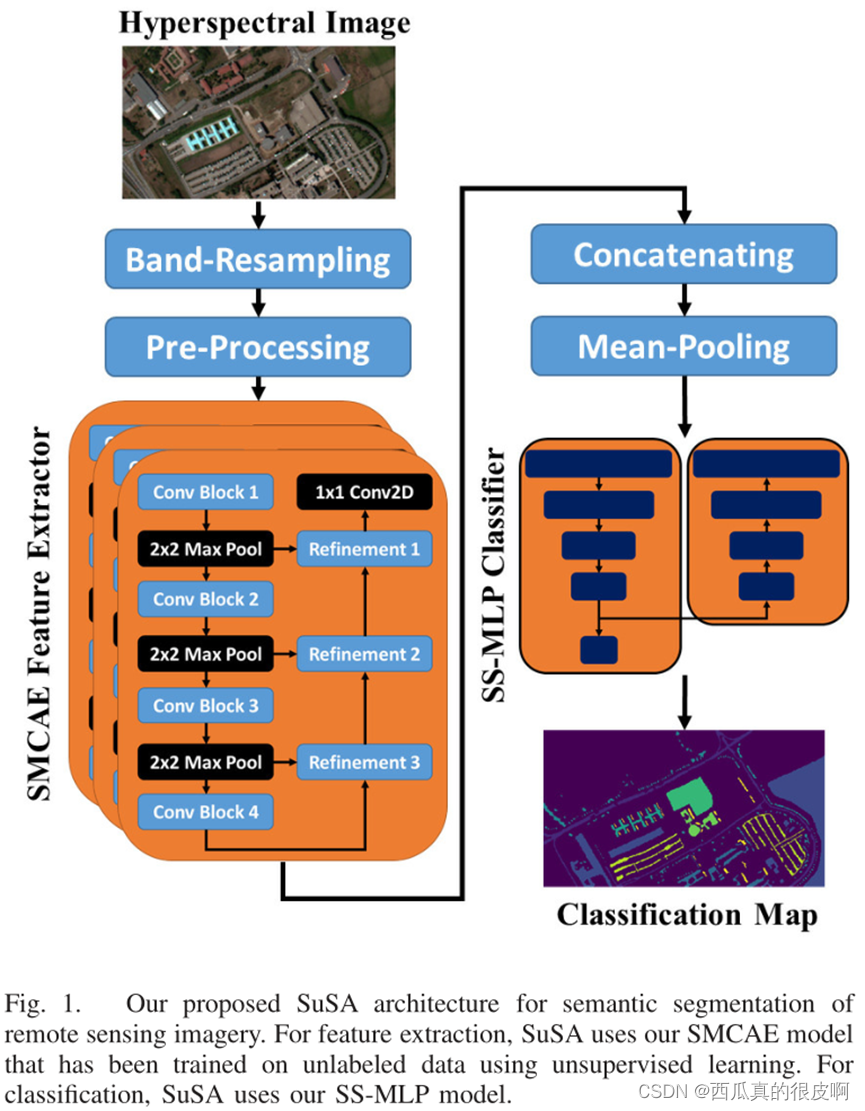
(3)stacked multi-loss convolutional autoencoder, SMCAE
MCAE本质上还是一个自编码器,如下图所示,左侧是一个编码器结构,右侧是一个解码器结构,中间用多个损失约束,最终的期望是X和 之间的损失越小越好。
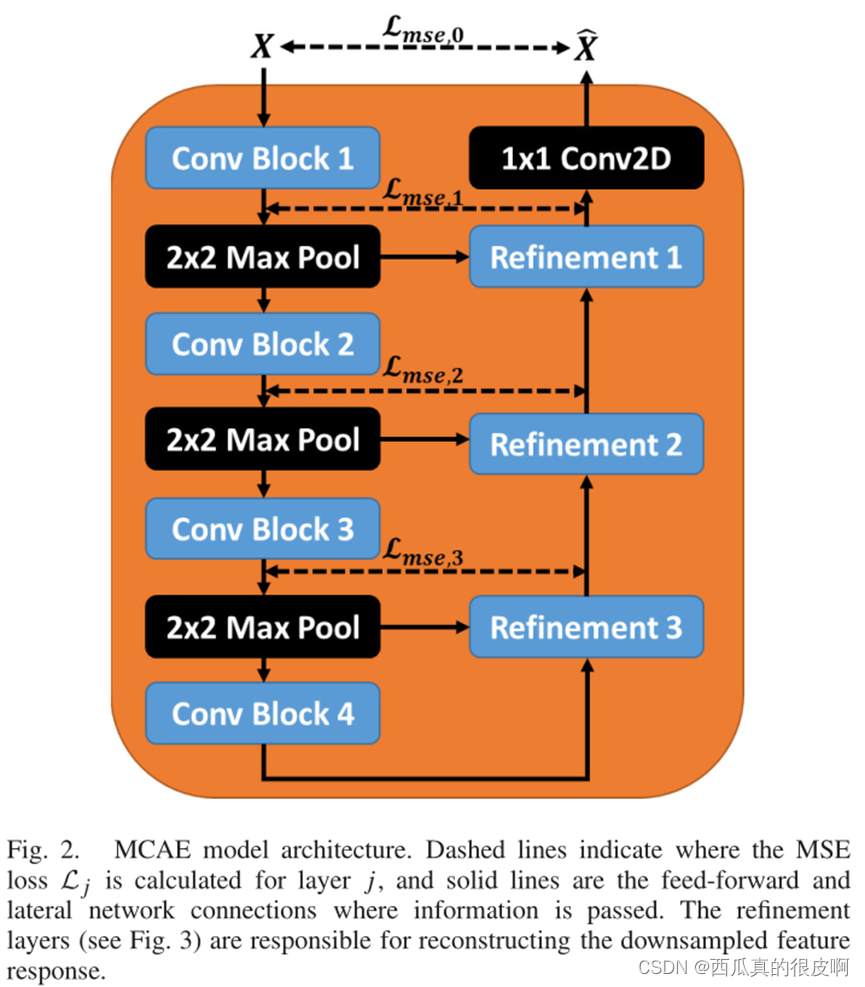
在上述结构中,refinement的结构如下图所示,其中,它的Lateral Connection代表的是编码器中对应层输入进来的特征层(也就是跳跃连接)。
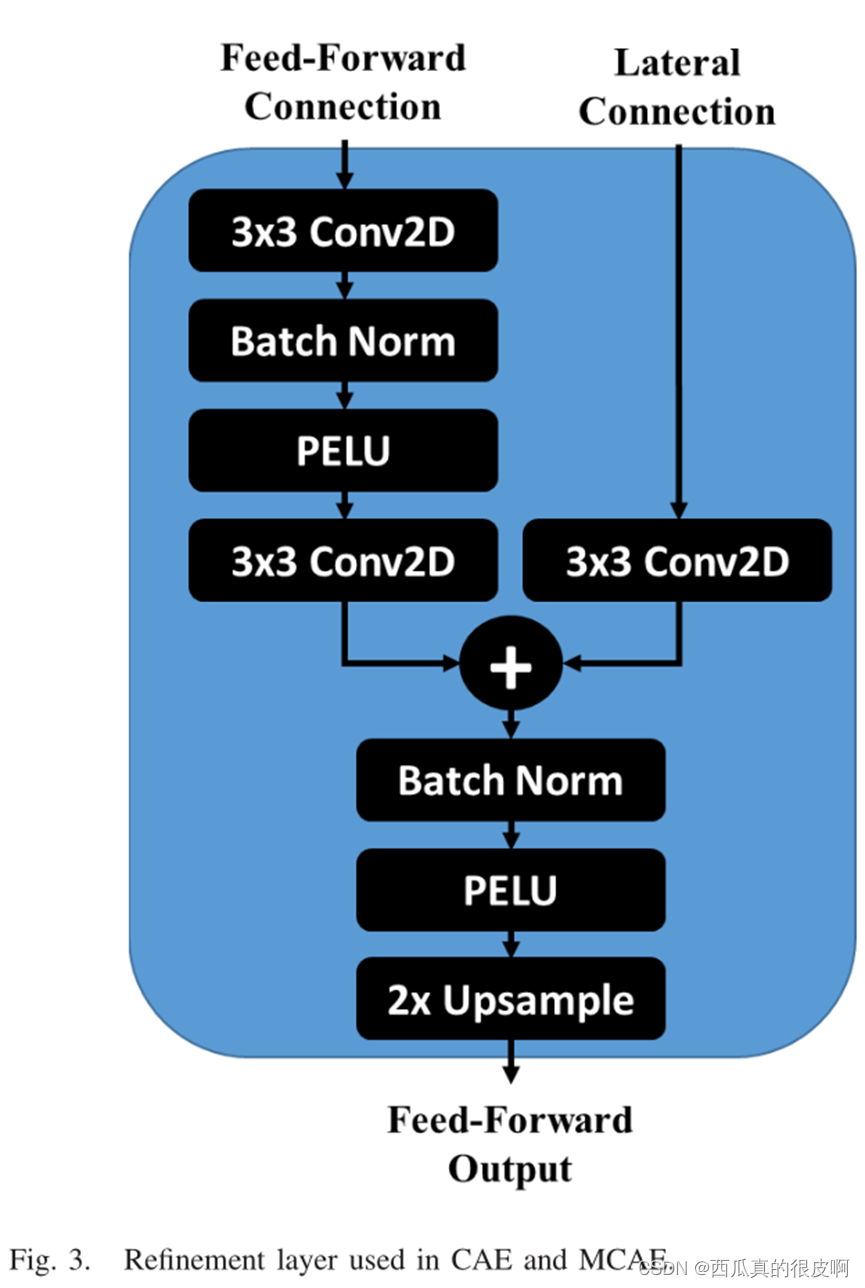
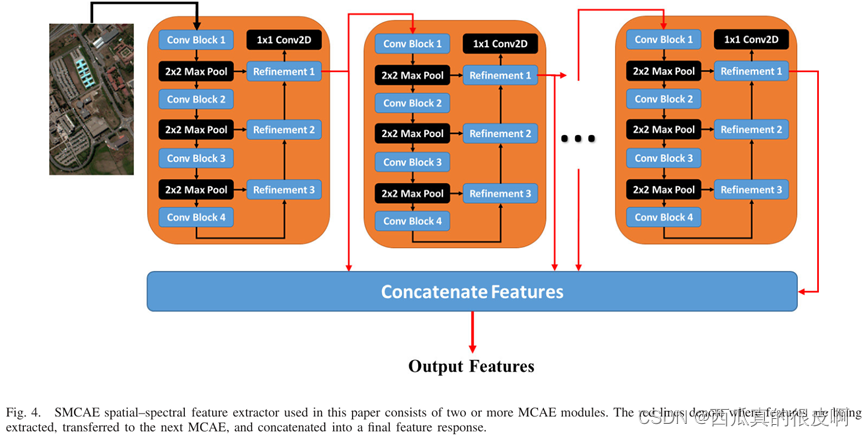
在上述基础上,该论文所做的系列改进,堆栈多损耗卷积自动编码器(stacked multi-loss convolutional autoencoder, SMCAE),每一个自编码块的输入是上一层最后一个隐藏层的输出,将其堆叠起来。
如下图所示:
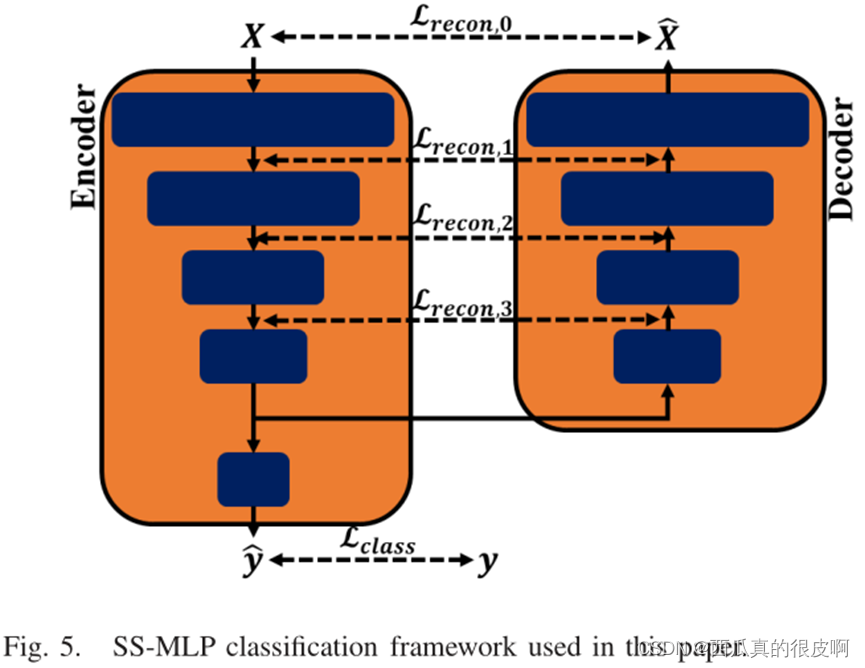
(4)半监督多层感知器神经网络Semisupervised Multilayer Perceptron Neural Network
SS-MLP具有对称的编码器-解码器框架。前馈编码器网络对原始输入进行分段,解码器重构原始输入的压缩特征表示。重建作为一种额外的正则化操作,可以防止在训练样本较少的情况下模型过拟合。SS-MLP通过最小化总监督和无监督损失来训练。
三、样本较少
对于深度学习来说,数据集是深度学习的重中之重,为了应对样本较少的情况,现有方法分类如下:

1. 数据合成、数据增广
关于数据合成,有一些专门的合成软件,这里不赘述。数据增广一般是一些常用的增广方法:
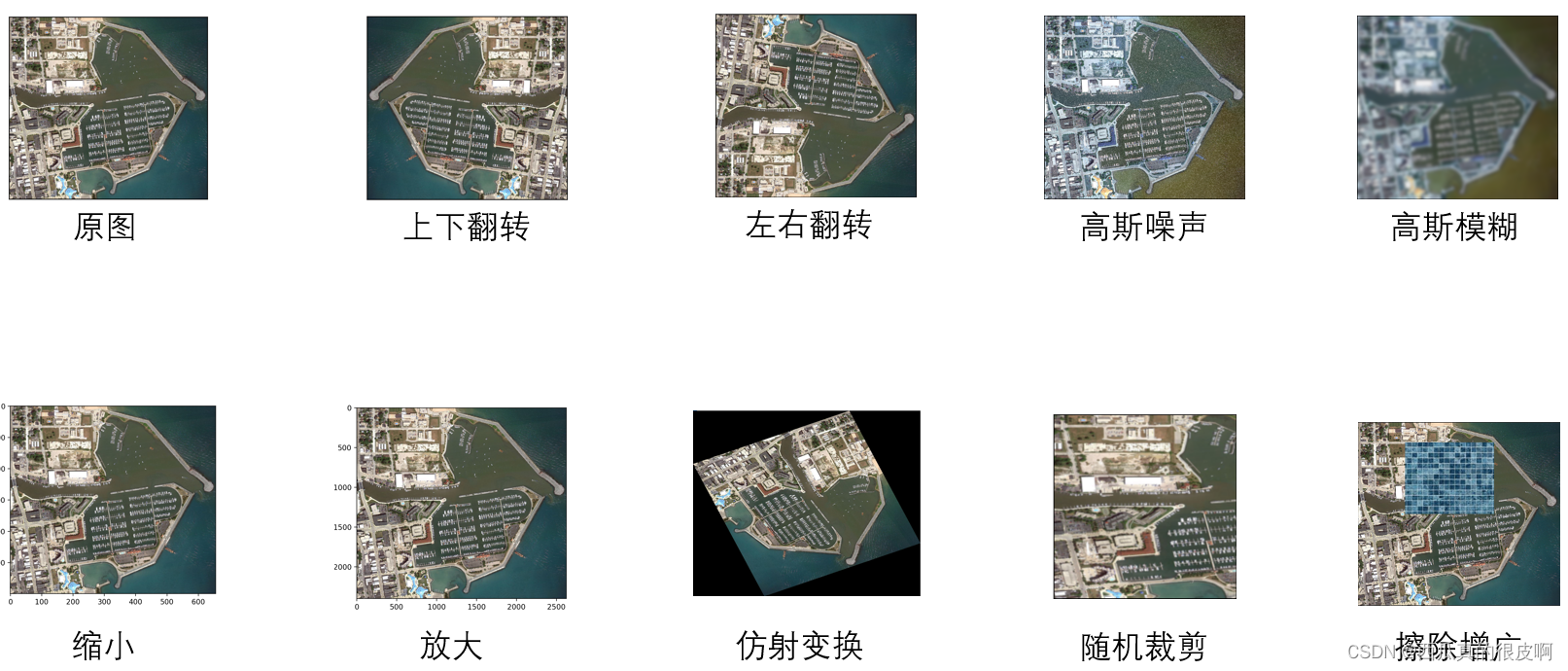
2.半监督
这一块主要参考了一篇论文,以及该论文作者写的一篇知乎,写的非常好:[CVPR 2021] CPS: 基于交叉伪监督的半监督语义分割 – 知乎 (zhihu.com)
2.1半监督知识学习
我们将半监督分割的工作总结为两种:self-training和consistency learning(一致性学习)。一般来说,self-training是离线处理的过程,而consistency learning是在线处理的。
(1)Self-training
Self-training主要分为3步。第一步,我们在有标签数据上训练一个模型。第二步,我们用预训练好的模型,为无标签数据集生成伪标签。第三步,使用有标注数据集的真值标签,和无标注数据集的伪标签,重新训练一个模型。
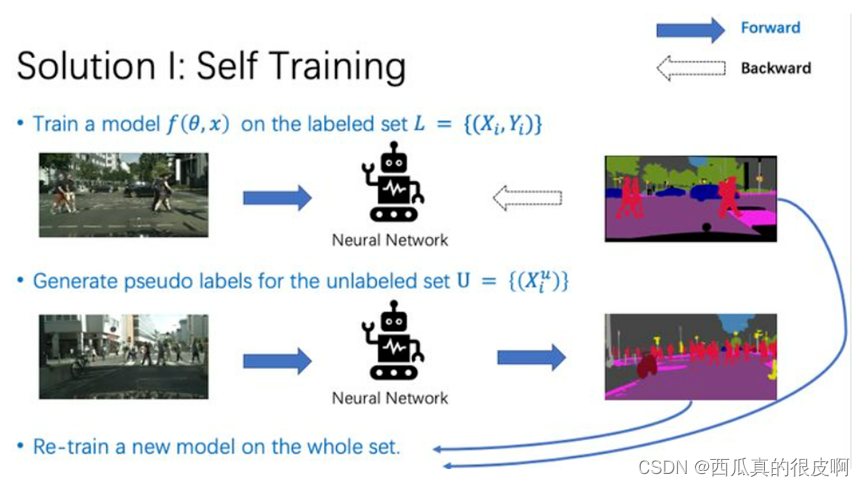
(2)Consistency learning
Consistency learning的核心idea是:鼓励模型对经过不同变换的同一样本有相似的输出。这里“变换”包括高斯噪声、随机旋转、颜色的改变等等。
Consistency learning基于两个假设:smoothness assumption 和 cluster assumption。
Smoothness assumption: samples close to each other are likely to have the same label.
Cluster assumption: Decision boundary should lie in low-density regions of the data distribution.
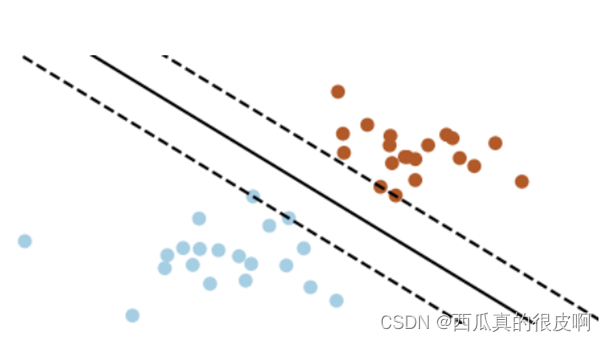
Smoothness assumption就是说靠的近的样本通常有相同的类别标签。比如下图里,蓝色点内部距离小于蓝色点和棕色点的距离。Cluster assumption是说,模型预测的决策边界,通常处于样本分布密度低的区域。怎么理解这个“密度低”?我们知道,类别与类别之间的区域,样本是比较稀疏的,那么一个好的决策边界应该尽可能处于这种样本稀疏的区域,这样才能更好地区分不同类别的样本。例如下图中有三条黑线,代表三个决策边界,实线的分类效果明显好于另外两条虚线,这就是处于低密度区域的决策边界。
那么,consistency learning是如何提高模型效果的呢?在consistency learning中,我们通过对一个样本进行扰动(添加噪声等等),即改变了它在feature space中的位置。但我们希望模型对于改变之后的样本,预测出同样的类别。这个就会导致,在模型输出的特征空间中,同类别样本的特征靠的更近,而不同类别的特征离的更远。只有这样,扰动之后才不会让当前样本超出这个类别的覆盖范围。这也就导致学习出一个更加compact的特征编码。
当前,Consistency learning主要有三类做法:mean teacher,CPC,PseudoSeg。
① mean teacher
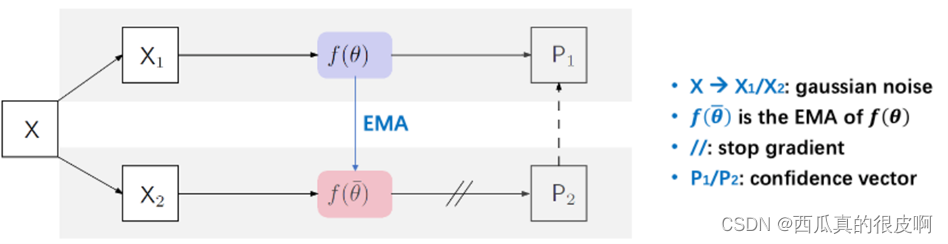
Mean teacher是17年提出的模型。给定一个输入图像X,添加不同的高斯噪声后得到X1和X2。我们将X1输入网络f(θ)中,得到预测P1;我们对f(θ)计算EMA(更新权重),得到另一个网络,然后将X2输入这个EMA模型,得到另一个输出P2。最后,我们用P2作为P1的目标,用MSE loss约束。
② PseudoSeg
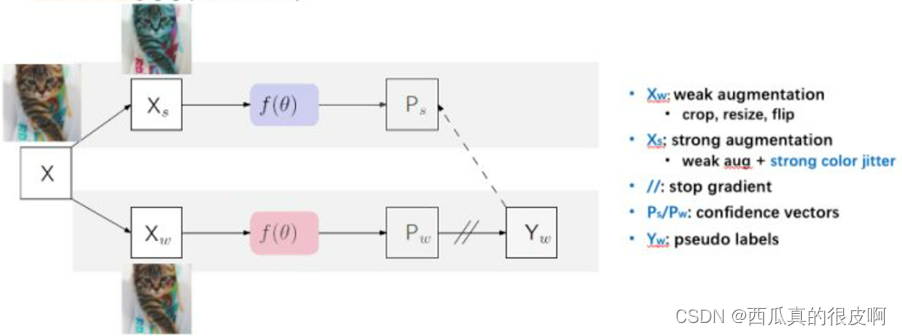
PseudoSeg是google发表在ICLR 2021的工作。他们对输入的图像X做两次不同的数据增强,一种“弱增强”(random crop/resize/flip),一种“强增强”(color jittering)。他们将两个增强后图像输入同一个网络f(θ),得到两个不同的输出。因为“弱增强”下训练更加稳定,他们用“弱增强”后的图像作为target。
③ CPC:Cross Probability consistency
CPC是发表在ECCV 2020的工作(Guided Collaborative Training for Pixel-wise Semi-Supervised Learning)的简化版本。在这里,只保留了他们的核心结构。他们将同一图像输入两个不同网络,然后约束两个网络的输出是相似的。这种方法虽然简单,但是效果很不错。

CPC
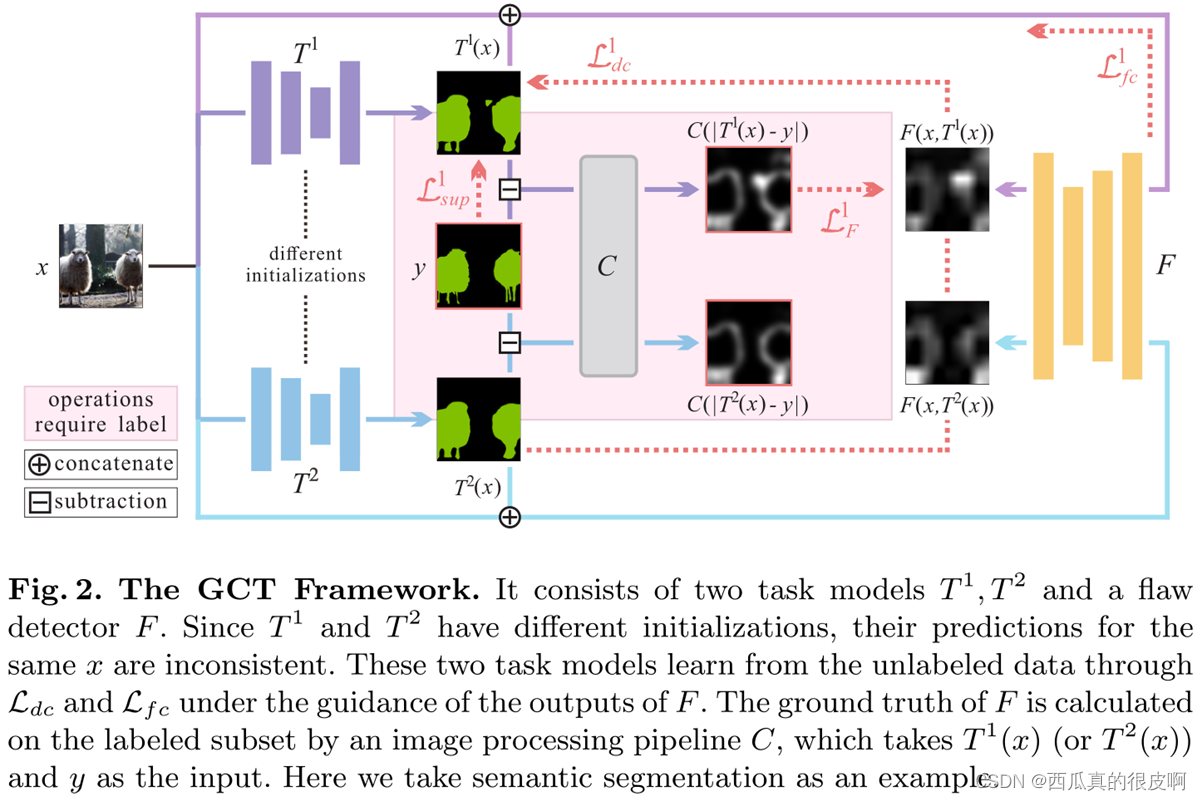
GTC(CPC简化之前的原网络)
2.2 大佬的论文
这篇文章是发表在2021CVPR的,有兴趣可以去看原论文。
示例:Chen X , Yuan Y , Zeng G , et al. Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision[C]// 2021.
对于N个有标签的影像,M个无标签的影像,半监督语义分割任务的目的是通过对有标记图像和无标记图像的研究来学习分割网络。
交叉伪监督。该方法由两个并行分割网络组成:
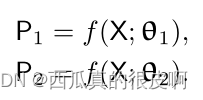
这两个网络具有相同的结构,其权值θ1和θ2初始化不同。输入X是相同的增宽,P1 (P2)是分割置信图,是softmax归一化后的网络输出。提出的方法在逻辑上说明如下:
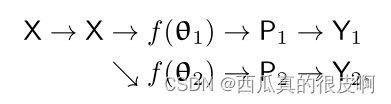
这里的Y1 (Y2)是预测的one-hot标签映射,称为伪分割映射。在每个位置i,标签向量y1i (y2i)是由相应的置信向量p1i (p2i)计算的one-hot向量。我们方法的完整版本如下图所示,我们没有在上述方程中包括损失监督:
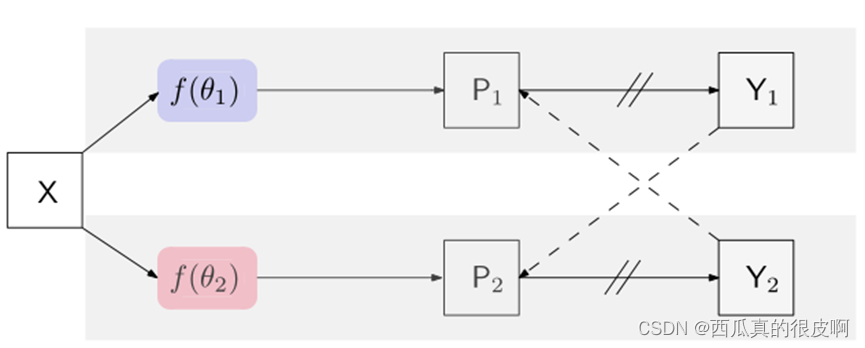
训练目标包含两个损失:监督损失Ls和交叉伪监督损失Lcps。监督损失Ls是利用两个并行分割网络上标记图像的标准像素交叉熵损失来制定的:
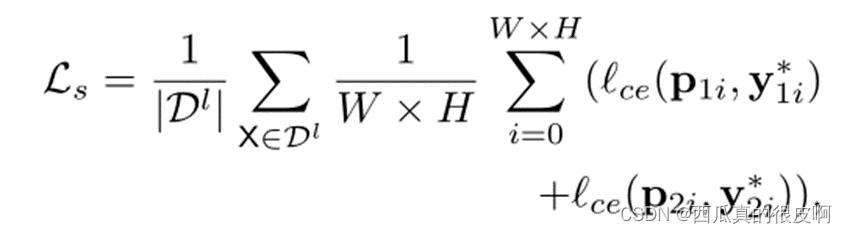
交叉伪监督损失是双向的:一是从f(θ1)到f(θ2)。我们使用一个网络f(θ1)输出的像素级单热标签图Y1来监督另一个网络f(θ2)的像素级置信度图P2,而另一个网络是从f(θ2)到f(θ1)。对未标记数据的交叉伪监督损失写为:
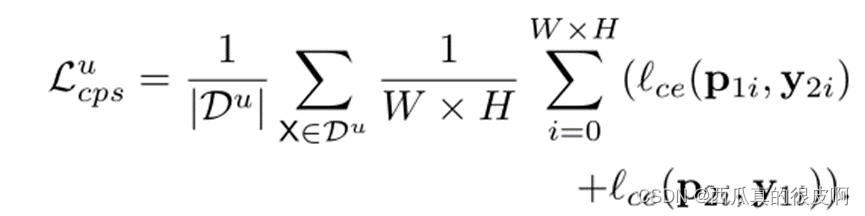
文章出处登录后可见!