作者:YAN左使
本文基于openGauss在VLDB2021上最新发表的论文《openGauss: An Autonomous Database System》,从学术的角度来探究openGauss如何基于各种AI技术构建一个智能的自治数据库系统。论文作者是清华大学李国良教授,他同时也是openGauss的总架构师。本文主要是对论文的阅读笔记和个人见解,如有错误,欢迎各位指正!
1. 摘要
虽然近年来基于学习的数据库优化技术在学术界得到了广泛的研究,但很多技术还没有被广泛部署到商业数据库系统中。这篇论文的作者探讨如何将基于AI的数据库技术整合到openGauss中,从而构建一个自治数据库系统架构。这些基于AI的数据库技术主要包括四个方面:
- Learned Optimizer:包括基于学习的查询重写、代价/基数估计、连接顺序选择和物理运算符选择等;
- Learned Advisors:包括基于学习的自监控、自诊断、自配置和自优化等;
- Validation Model:用于验证AI模型的有效性;
- Training Data Management:用于收集、存储和选择训练数据;
- Model Management:用于高效和统一地管理各种AI模型。
2. 挑战
要将基于AI的数据库技术整合到openGauss的架构中,构建基于学习的端到端数据库系统存在以下挑战:
- (1) 模型选择。AI算法模型非常多,选择一个最合适的模型是非常重要的,我们需要为不同的数据库组件设计有效的模型。例如,深度学习模型适用于代价和基数估计等任务,因为可以捕获数据列之间的相关性;而深度强化学习模型则一般用于索引推荐、视图推荐或者knobs tuning等任务,因为利用深度强化学习可以解决高维连续空间中最优解的探索问题。
(2) 模型验证。 我们需要设计一个验证模型来评估基于学习的模型是否有效,且是否优于非学习的传统方法。例如,基于DRL的knob tuning、index recommendation和view recommendation等模型是否真的适用于真实的工作负载,是否优于传统的方法。
(3) 模型管理。由于不同的数据库组件可能使用不同的ML模型,因此我们需要一个平台来实现统一的资源调度和统一的模型管理。
(4) 训练数据管理。有效的模型需要高质量的训练数据,因此我们需要一个自动化的平台来自动收集和管理训练数据。
为了应对这些挑战,论文构建了一个自治的数据库框架,并将其集成到openGauss中,主要包含5个组件,包括Learned Optimizers、Learned Database Advisors、Model Validation 、Model Management和Training Data Management,如下图所示。
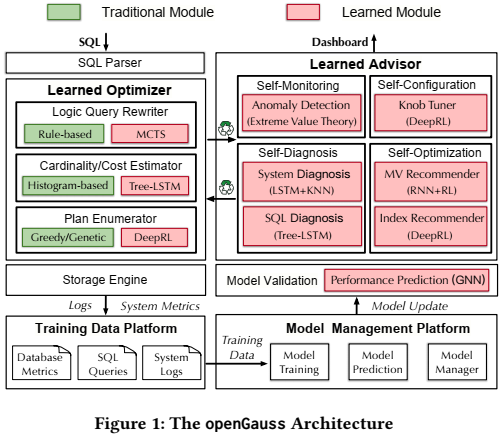
3. 基于学习的优化器:Learned Optimizer
优化器是数据库最核心的组件之一,负责解析SQL语句生成高效的执行计划给执行引擎执行。基于学习的优化器主要包括三个重要的组件:基于MCTS的查询重写,基于Tree-LSTM的代价和基数估计器,以及基于DRL的查询计划生成器。
3.1 基于MCTS的查询重写
查询重写的目的是将一个速度较慢的SQL查询转换为具有更高性能的等价查询,这是查询优化中的一个基本问题。如果以适当的方式重写(例如,删除冗余操作符,交换两个操作符),缓慢的SQL查询(由于冗余或低效的操作)的性能可以提高几个数量级。
论文中给了一个例子,如下图所示。通过消除冗余聚合MAX(c_custkey)并且将ANY操作符里的子查询pull up到最外层的WHRER子句中,可以将查询Q重写为等效的查询Q’,查询重写后可以实现超过600倍的查询加速(查询执行时间从20多分钟降为1.941秒)。
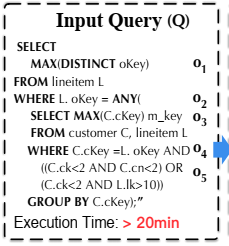

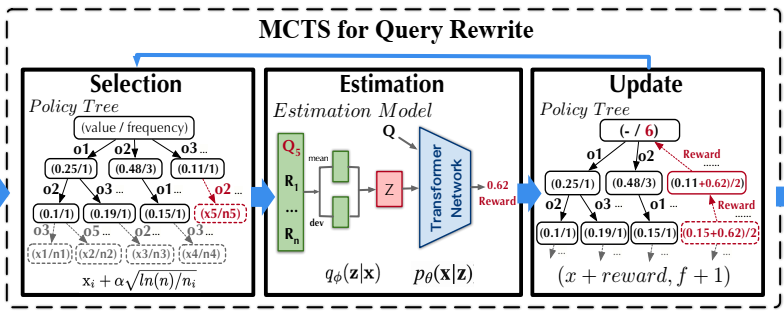
为了解决这个问题,论文采用蒙特卡洛树搜索(MCTS)来搜索最优的等价查询。整个查询重写模块由三部分组成,如上图所示。
- 首先,Selection部分是一个策略树policy tree,根节点是原始的SQL查询,而非根节点是通过重写规则重写后的查询。在这个policy tree上可以利用MCTS来探索和找到最优的等价查询(执行时间最短的等价查询)。作者通过在这个policy tree上使用置信上限(Upper Confidence bounds, UCB)来选择有希望的或未覆盖的树分支,以此来展开策略树,以便找到最优的重写查询。在强化学习中,exploration和exploitation是两个重要的方面(探索和利用通常是相互制约的,需要进行trade-off,称为探索-利用困境)。我们希望强化学习可以快速找到最佳策略,但是在没有充分探索的情况下就盲目地选择某个策略会带来一定的问题,因为这会导致模型陷入局部最优甚至完全不收敛。UCB是一种经典的探索算法,智能体通过选择当前状态下的最优动作来最大化置信区间上界。本文的一个关键问题是就是构建了策略树以后,如何去高效地explore查询重写的空间,从而快速找到最优的等价查询,所以本文利用MCTS和UCB的方法来解决这个问题。传统的MCTS采用RolloutPolicy的策略,而将UCB应用于MCTS是一种变种的MCTS算法。MCTS非常适合用于解决查询重写这个问题,这个问题非常类似AlphaGo中的落子问题,每一步落子前,MCTS都会模拟游戏的发展方向,来判断和计算每一步可以落子的位置是否会导致最终胜利,并根据模拟结果预测最有希望的落子动作。
- 其次,Estimation部分是一个deep estimation model, 用于估计树节点被重写后的潜在好处(即节点上的查询被重写后能带来多少好处)。如果能准确估计出每一个树节点处的查询重写能带来的好处,就能更加高效地找到最优的重写查询。
- 第三,为了提高搜索效率,特别是当查询具有多个逻辑运算符时(这会导致搜索空间的爆炸性增长),论文提出了一种多智能体MCTS并行算法,该算法可以并行地探索策略树上不同的重写顺序,从而加快搜索速度。
更多具体的细节,可以参考论文《A Learned Query Rewrite System using Monte Carlo Tree Search》。
3.2 基于Tree-LSTM的基数和代价估计
传统的基数估计方法存在很大的误差,特别是当涉及多个列的时候,这是因为传统方法很难捕捉不同列之间的相关性。例如,基于直方图的方法只捕获单个列的分布;对于高维数据,基于采样的方法存在0元组问题。基数估计的误差会传递到代价估计中,因为代价模型除了和代价因子有关以外还受到基数估计的影响,比如PsotgreSQL中的代价模型是基数估计值和各种代价常数因子的线性组合,如下所示:
cost = Cs * Ns + Cr * Nr + Ct * Nt + Ci * Ni + Co * No
其中Cs,Cr,Ct,Ci,Co表示各种操作的代价因子,而Ns,Nr,Nt,Ni,No则表示相应的基数值大小。
- Cs表示seq_page_cost,即顺序访问一个page的I/O cost;
- Cr表示random_page_cost,即随机访问一个page的I/O cost;
- Ct表示cpu_tuple_cost,即处理一个tuple的CPU cost;
- Ci表示cpu_index_tuple_cost,即通过索引处理一个tuple的CPU cost;
- Co表示cpu_operator_cost,即执行一个操作(比如哈希或聚合操作)的CPU cost。
这些代价因子都是常数值,比如Cs=1.0,Cr=4.0,暗含的意思是随机读取一个page的IO代价是顺序读取的4倍。注意:PostgreSQL的官方文档建议不要随意修改这些常数的代价因子。

所以,从上面的例子可以看出,一个查询计划的代价的估计是由两个因素共同决定的:基数估计值和相应的常数代价因子。相比代价因子,基数估计值对于代价估计的影响更大,基数估计错误可能会导致生成的查询计划不是最优的(因为更优的查询计划可能被错误的估计了一个更大的代价值而被舍弃了)。
为了解决上面的这些问题,论文采用了一种树状结构的LSTM模型来同时估计查询的基数和代价。同时估计出基数和代价是这个模型最大的创新点,因为很多其他的基于AI的论文都只能估计基数或者代价。
论文采用的Tree-LSTM模型主要包括3个layer:embedding layer, representation layer和estimation layer,如下图所示。
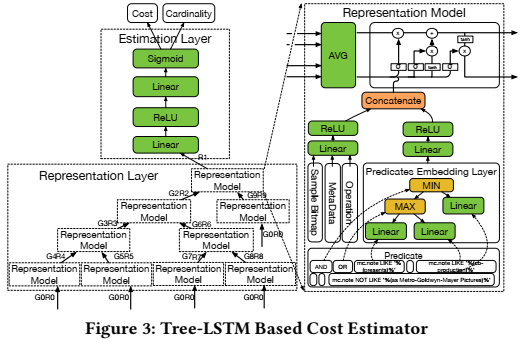
- Embedding layer :这一层的作用是embeds a sparse vector to a dense vector,使用各种编码技术对query的谓词、元数据、操作符以及samples进行编码,生成feature vectors。
- Representation Layer :表示层的目的是捕获从叶节点到根节点的全局代价,并避免信息丢失(例如,列之间的相关性),Embedding层的输出会作为representation层的输入。
- Estimation Layer :估计层是最后一层,它根据计划结构的表示来计算代价/基数结果,估计层采用的是一个two-layer fully connected neural network。
更多具体的细节,可以参考论文《An End-to-End Learning-based Cost Estimator》。
3.3 基于DRL的查询计划生成器
查询计划生成中最重要的是join oder和physical operation的选择。传统的方法是在代价估计模型的基础上,通过搜索解空间来寻找合适的查询计划方案,比如动态规划和启发式算法。动态规划通过枚举解空间来找到最佳的查询计划,但其时间复杂度为指数级。启发式方法通过剪枝解空间的方式来加快搜索速度,但由于剪枝操作通常很难找到最优的查询计划。
将查询计划的生成过程建模为马尔可夫决策过程(MDP)后,就可以应用深度强化学习(DRL)来生成查询计划。但是,很多DRL方法采用固定长度来表示join tree,如果shcema有更新或者查询中存在表别名,这些方法就会失效。为了解决这些问题,论文提出了一种基于学习的查询计划枚举器,可以生成执行时间最短的查询计划,而且可以handle schema update。使用的深度强化学习模型是一个DQN+Tree-LSTM,如下图所示。
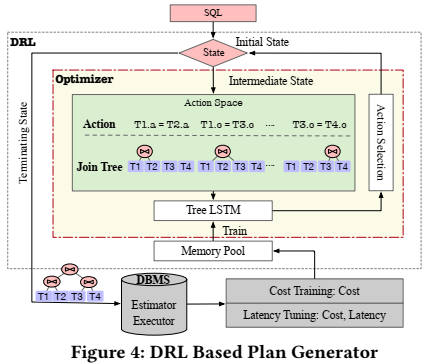
其工作流程如下:
- 给定一个SQL查询,查询计划枚举器首先初始化一个空状态S0,它只包含基本的查询信息。中间状态Si是包含多个partial plan tree的plan forest。
- RL策略的每一步需要做两件事:1)选择接两个表Ti1、Ti2进行join,2)选择要使用哪种join的操作Oi(比如hashjoin、nestloop等)。
- 动作Ai是join和operation的一个组合,即Ai = (Ti1, Ti2, Oi),意思是每一步的动作需要指定是哪两个table进行join,以及使用什么样的join方法。
- 根据Tree-LSTM神经网络的Q值Q(Si, Ti1, Ti2, Oi)来决定下一步的动作。
- RL不断选择下一个动作,直到生成一个完整的查询计划树。
更多具体的细节,可以参考论文《Reinforcement Learning with Tree-LSTM for Join Order Selection》。
4. Learned Database Advisor
4.1 自监控Self-Monitoring
在数据库的运行中检测异常是非常重要,如果不能及时检测出异常并采取措施,那么这些异常(比如slow SQL)可能会占用大量的系统资源,影响数据库的整体性能。靠人工来完成显然是非常困难的,因此需要一个自监控模块来实时监测数据库状态并主动发现异常。
通过检测数据库和操作系统的指标来检测异常,可以监视指标包括响应时间、CPU使用情况、内存使用情况、磁盘使用空间、缓存命中率等500多个metrics。如果这些指标存在异常则说明数据库出现了异常,这时自监控模块需要进一步找出root cause,才能采取相应的措施来修复异常。
由于要实时监控,所以监测数据形成了连续的时间序列数据(Time-Series Data)。传统的基于统计的异常检测算法是针对一维数据设计的,这些方法忽略了时间序列数据之间的相关性,无法获得较高的精度。基于深度学习的算法虽然能获取数据间的相关性,但需要对数据进行标记。
为了解决这些问题,论文采用一种基于重构的算法来检测异常,因为正常的时间序列数据总是表现出有规律的patterns,如果出现了异常模式patterns,则有很大的概率是数据库出现了异常。论文采用的是一个LSTM-based auto-encoder with an attention layer(包含一个注意力层的基于LSTM的自动编码器),如下图所示。
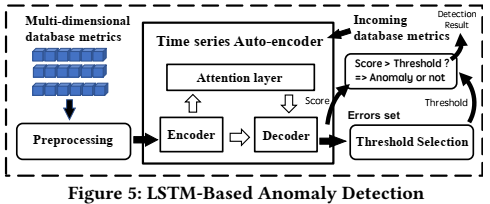
原始的多维时间序列数据通过预处理后会被Encoder编码成low-dimensiaonal representation,然后Decoder会解析表示并试图恢复原始的时间序列数据。如果能正确地重构出原始数据则说明没有异常,反之如果无法重构原始数据(重构误差超过一定地阈值),则说明数据库出现了异常。
如何确定一个合理的阈值是非常关键的,因为如果阈值太低则可能会经常报异常(类似于雷达检测中的虚警,即本来没有目标却认为有目标),阈值太高则可能漏检很多异常。因此论文采用了一种称为Extreme Value Theory的统计学方法来确定动态阈值。当用户指定系统灵敏度(1%或5%)后,系统会根据历史数据计算出相应的阈值。
4.2 自诊断Self-Diagnosis
Root-cause diagnosis对于自治数据库来说是至关重要的,需要同时考虑系统级诊断和SQL级诊断。前者分析系统异常的根本原因,比如IO争用、网络拥塞、磁盘空间不足等;后者分析慢SQL的根本原因,比如锁冲突或者缺少索引。
4.2.1 系统级诊断System-Level Diagnosis
在系统级诊断框架中,将诊断视为一个classification problem,并通过使用metric data中的特征来查找root cause。这个诊断模型是轻量级的,不会对数据库性能产生影响。通过对历史数据的分析,可以对诊断模型进行优化,这样只需对少数异常cases进行标注即可。系统级自诊断框架由offline和online两个部分组成,如下图所示。
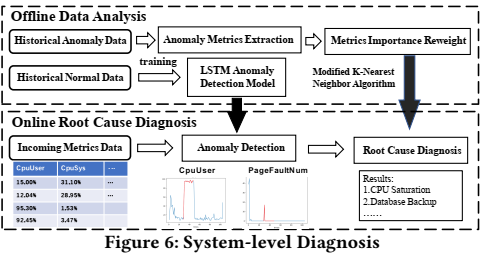
- Offline stage: 收集两种类型的指标:正常数据和异常数据,然后利用正常数据来训练一个基于LSTM的自编码器。异常数据由anomaly cases组成,每个case包含:database metrics data和the root cause label。对于异常数据,提取具有代表性的metrics data,并将其存储为knowledge base(知识库)。然后采用Kolmogorov-Smirnov test对每个维度的metrics data的状态进行定量度量,将这些信息统一到一个模型中。最终的结果是将每一个anomaly case编码成一个vector,这个vector中的每个维度就可以表示数据库的一个指标状态。
- Online stage: 一旦检测到数据库异常,就会调用root cause模块,该模块首先对每个数据库指标进行Kolmogorov-Smirnov test,生成anomaly vector,最后在知识库中找到类似的异常案例,并定位到root casue。
4.2.2 SQL级诊断SQL-Level Diagnosis
SQL级诊断的目的是在没有实际运行SQL的情况下找到SQL语句中特别耗时的operator。
SQL级的诊断存在以下挑战:
- (1) 由于是在没有运行SQL的情况下进行诊断,此时执行计划是不存在的。所以想要在日志文件中记录执行计划会非常耗时,因此SQL查询的执行计划并没有保存在metric中。
- (2) 由于SQL查询多种多样,而且实际中dataset和workload也在变化,所以需要一种one-model-fits-all的方法。
- (3) 由于系统状态会对SQL性能产生影响,所以SQL级别的诊断需要考虑系统的因素。即需要区分到底是系统状态带来的性能下降,还是SQL本身的影响带来的性能下降。比如,系统级别的IO contention会导致SQL语句中的sequence scan operator变得很慢,这时根本原因在于系统状态,而不是SQL本身。
下图显示了SQL级的诊断框架,其工作流程包含两个阶段:
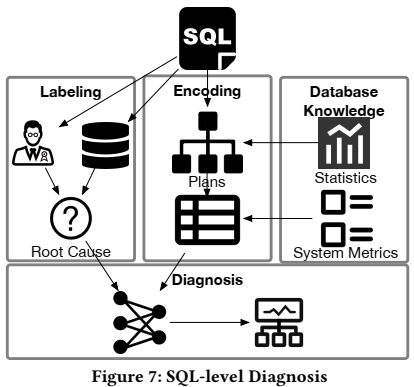
- Offline model training阶段:首先,openGauss会通过运行日志或者专家标记的方法来对queries进行标记,这一步是收集训练数据,每个query中最慢的operator会被标记为root cause。然后,plan generator使用数据库统计信息(例如,索引列直方图、表基数等)将SQL query转换为执行计划。接下来,通过深度优先搜索计划树的节点,将每个执行计划编码成一个vector,并与实时系统指标(例如,CPU/IO负载)连接变成一个更长的vector,然后将vecto输入训练模型进行训练。
- Online diagnosing阶段:将输入的query通过plan generator转换为执行计划,并将计划编码为计划结构向量,在feature encoder中与实时system metrics进行连接,最后计算输出SQL查询的root cause。
4.3 自配置Self-Configuration
数据库一般都有数百个tunable knobs(例如,openGauss中有超过400个knobs),DBA需要为这些knobs设置适当的值来保证数据库的性能,比如内存管理、日志记录、并发控制。然而,手动调节knobs非常耗时,其他自动调节方法(如启发式采样或机器学习方法)不能有效地调节knobs。例如,有些ML方法在小数据集上训练,如果想要迁移到大数据集则需要重新训练。
为了解决这些问题,论文提出了一个混合调优模块如下图所示,该模块由四个部分组成:

- (1) DB Side: DB_Agent提取数据库实例的特征,包括内部状态和当前旋钮设置。
- (2) Algorithm Side: 包含调优算法,包括基于搜索的算法(如贝叶斯优化、粒子群算法)和深度强化学习算法(如Q-Learning、DDPG)。
- (3) Tuning Side: 以迭代的方式进行旋钮调优,在每一步中,输入database status和query feature(状态向量),并使用Algorithm Side中的调优算法输出推荐的旋钮值。
- (4)Workload Side: 由客户机进行压力测试,客户机运行基准测试任务并反馈执行性能(例如,平均吞吐量)。
4.4 自优化Self-Optimization
4.4.1 视图推荐MV Recommender
什么是物化视图(Materialized Views)?
- 普通视图是根据基表查询结果建立一个虚拟表,从而可以隐藏查询的复杂性,并保证数据的安全。如果查询过于复杂,以及数据量过大,使用普通视图查询会出现效率瓶颈,此时可以用物化视图。
- 可以把物化视图看作是一个数据库对象,它包含查询的结果。物化视图可以是远程数据的一份本地拷贝,也可以是表或者关联查询结果子集的部分行或者列,也可是聚合函数的查询结果。
- 创建物化视图的过程叫做物化(Materialzation),这是缓存查询结果的一种形式,类似于缓存或者记忆化,或者提前计算。
- 普通的视图是一种虚拟(virtual)表,而物化视图是将视图的查询结果缓存(cached)到了具体(concrete/materialized)表中。但需要明白这种方式也是有代价的,而且物化视图的数据可能会过期,所以物化视图的更新也是一个需要研究的问题。
- 物化视图在数据仓库中经常被使用,对于那些必须要查询关联的数据或汇总数据,可以预先经过实体表存放起来。这样查询时就可以不去关联表,而是直接去查询物化视图。
- 物化视图是一种典型的以空间换时间的方法,使用时要根据业务应用场景考虑数据时效性,设置合理的更新频率,从而在时效性和查询效率达到平衡。
物化视图的创建通常由DBA来完成,但是即使是有经验的DBA也不能完成具有数百万实例和数百万用户的云数据库的视图推荐工作。关于MV推荐的研究有两个挑战:
- 有很多可用的MV,找到一个可选的MV集是很耗时的;
- 需要估计一个MV对于查询能带来的好处,而传统的估计方法不够精确。
为了应对这些挑战,论文采用基于学习的MV推荐方法,如下图所示:
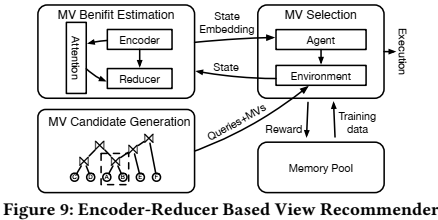
该方法主要包括三个部分:
- MV Candidate Generation :通过分析工作负载来找到common subqueries,那些具有较高频率和计算代价的common subqueries将被选择为候选视图。
- MV Benefit Estimation :为了选择最优的视图,非常关键的一步就是估计视图能带来多少好处(比如查询的执行时间能减少多少),论文中度量物化视图带来的好处也是通过节省的执行时间。论文中提出了一个Encoder-Reducer模型来预测使用视图的好处,模型的输入是查询和视图的features。同时,论文还估计了存储视图所需的空间成本和生成视图的时间成本。
- MV Selection :在给定space budget的情况下,通过选择一个合适的候选视图子集,在空间预算范围内最大化总收益(最大化减少执行时间)。作者将这个选择问题建模为一个整数规划问题,并提出利用强化学习模型来求解。
4.4.2 索引推荐Index Recommender
索引对于数据库系统实现高性能至关重要,使用合适的索引可以显著加快查询的执行速度。然而,索引推荐是一个复杂而具有挑战性的问题:
- 首先,多个索引之间存在相互作用,这种相互作用会影响最终的查询性能,因此想要准确地评估一个索引带来的收益是非常困难的。
- 其次,我们可以同时使用多个不同类型的索引,那么不同索引组合数量是十分巨大的。
- 而且,过滤掉无用的索引也是一项耗时费力的工作。
为了解决这些问题,论文提出了一种基于学习的索引推荐方法,如下图所示。
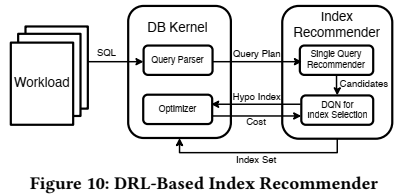
该方法主要分为三个步骤:
- 首先,为了降低计算成本,只提取具有代表性的查询来表示整个工作负载集(这相当于从整个训练数据集中抽样一部分来代表整个训练集),并为每个查询独立推荐索引。通过解析query并从不同的SQL clause中提取可能有用的列。然后根据table和column的统计信息,选择用哪些列并为它们打分。
- 其次,为了评估每一个index candidate的好处,我们使用hypothetical index来模拟真实索引的创建,这样做可以避免创建物理索引所需的时间和空间开销。基于这个hypothetical index,就可以通过调用数据库的优化器来评估索引对指定查询语句的性能影响。估计hypothetical index的actual cost时使用的指标包括磁盘空间使用、索引建立所需的时间和使用索引的总成本)。
- 第三,使用DQN来从index candidate set中选择使收益最大化(例如,执行时间降低最多)的索引。
5.几点思考
文中提到的这些论文解决的其实都是如何利用AI去改进甚至替代传统数据库的组件和模型,比如优化器中的查询重写和代价估计模型,然后作者想将这些都用于openGauss中构建一个自治数据库,我个人有以下几点思考:
- 实验部分:作者基于openGauss实现了上面提到的所有算法和模型,在真实的数据集上进行了评估,并且和PostgreSQL等开源数据库进行了对比,实验结果说明这些基于学习的算法模型的有效性。但是,目前大部分论文还是会选择基于PostgreSQL去实现算法和模型。从这个角度来说,希望openGauss以后能走向世界,让更多的人来基于openGauss上来验证自己的算法或系统原型。
- 自治框架:这篇论文只是简单地提出如何将这些基于AI的模型用于数据库中去增强或替代原有的系统。尽管本中提到的模型和算法都已经在github和gitee上开源,但是目前还没有完全融入openGauss中。而且,想要做到用基于AI的模型来完全替代数据库的各种组件和子系统,可能还有很长的一段路要走。我想这可能是openGauss,以及整个学术界和工业界需要进一步研究的内容。
- 缺失的部分:学术界和工业界已经提出了很多Autonomous Database Systems(也称为Self-Driving Database Systems),比如Oracle的Autonomous Database,CMU数据库组的Peloton [3]和NoisePage [4],MIT数据库组的SageDB等。我个人觉得,本文提出的自治数据库架构缺失了对于workload预测这一重要的系统组件。因为自治数据最重要的一个特性就是要对未来的工作负载进行预测,并提前做出合理的配置和调优,比如提前分配合理的系统资源,创建合适的索引来应对未来工作负载的变化。Andy Pavlo教授关于self-driving database的一个基本观点是一切的actions都应该基于workload forcasting,比如预测工作负载在未来何时变化(workload shift detection)以及有多少queries到来(arrival rate estimation)。可以看到下图显示的Peloton和NoisePgae框架中,workload forecasting都是第一步,接下来才是behavior modeling和action planning,所以我认为openGauss想实现完全自治,对于工作负载的预测也是很重要的一步。不过,我看到2019年华为CCF创新项目中有一个项目就是基于机器学习的数据库工作负载流预测,所以openGauss未来应该会考虑将工作负载预测的功能加入到自治框架中。
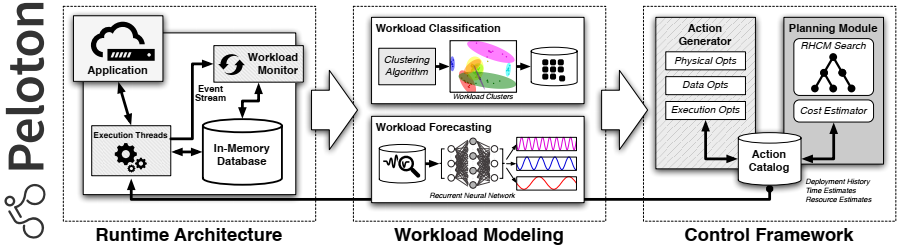
Peloton系统框架图
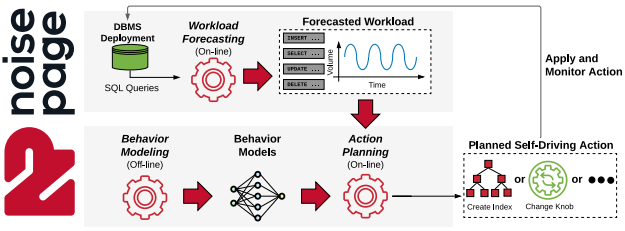
NoisePage系统框架图
参考文献:
[1] Li, G., Zhou, X., Sun, J., Yu, X., Han, Y., Jin, L., … & Li, S. (2021). openGauss: An Autonomous Database System. Proceedings of the VLDB Endowment, 14(12), 3028-3042.
[2] Zhou, X., Jin, L., Sun, J., Zhao, X., Yu, X., Feng, J., … & Liu, L. (2021). DBMind: A Self-Driving Platform in openGauss. Proceedings of the VLDB Endowment, 14(12), 2743-2746.
[3] Pavlo, A., Angulo, G., Arulraj, J., Lin, H., Lin, J., Ma, L., … & Zhang, T. (2017). Self-Driving Database Management Systems. In CIDR.
[4] Pavlo, A., Butrovich, M., Ma, L., Menon, P., Lim, W. S., Van Aken, D., & Zhang, W. (2021). Make Your Database System Dream of Electric Sheep: Towards Self-Driving Operation. Proceedings of the VLDB Endowment, 14(12), 3211-3221.
[5] Zhou, X., Li, G., Chai, C., & Feng, J. A Learned Query Rewrite System using Monte Carlo Tree Search.
[6] Sun, J., & Li, G. (2019) An End-to-End Learning-Based Cost Estimator. Proceedings of the VLDB Endowment, 13(3), 307–319.
[7] Yu, X., Li, G., Chai, C., & Tang, N. (2020, April). Reinforcement Learning with Tree-LSTM for Join Order Selection. In 2020 IEEE 36th International Conference on Data Engineering (ICDE) (pp. 1297-1308). IEEE.
[8] Zhou, X., Sun, J., Li, G., & Feng, J. (2020). Query Performance Prediction for Concurrent Queries using Graph Embedding. Proceedings of the VLDB Endowment, 13(9), 1416-1428.
文章出处登录后可见!