复现KM3D:Monocular 3D Detection with Geometric Constraints Embedding and Semi-supervised Training
时间:2022年5月27日
1.下载官方代码
到github中,搜索KM3D找到官方代码,下载。网址如下:
https://github.com/Banconxuan/RTM3D
2. 安装环境(install)
查看install.md,按照里面的内容进行环境的安装。
2.1 安装pytorch环境
官方要求安装的pytorch环境太老了。我没有按照官方的。我的环境如下:
Ubuntu 18.04.3 LTS
conda + python 3.7 + cuda10.1
pytorch1.6.0
torchvision0.7.0
显卡:Quadro P4000 8GB
conda create -n km3d python=3.7 -y
conda activate km3d
conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=10.1 -c pytorch -y
既然选择了较新的环境,意味着后面要修改代码bug,以适应环境。
2.2 Install the requirements
进入km3d路径下,执行如下命令:
pip install -r requirements.txt
2.3 安装DCN v2.
参考知乎《单目3D目标检测RTM3D》作者:Vision 连接:https://zhuanlan.zhihu.com/p/415084925
没有用官方github提供的方法,提供的DCNv2版本太老了,不适用。所以,在github上搜索DCN v2找到适合pytorch的版本并安装。
我的环境pytorch1.6,所以安装的DCNv2要适配pytorch1.6
github搜索DCNv2,找到DCNv2_latest,作者jinfagang,使用pytorch1.6分支,按照说明进行安装即可,连接:https://github.com/jinfagang/DCNv2_latest/tree/pytorch1.6
2.4 安装 iou3d
参考知乎《单目3D目标检测RTM3D》作者:Vision 连接:https://zhuanlan.zhihu.com/p/415084925
进入src\lib\utils\iou3d\src,编辑iou3d.cpp
在所有#include<>后面添加3行代码即可:
#ifndef AT_CHECK
#define AT_CHECK TORCH_CHECK
#endif
整体就是:
#include <torch/serialize/tensor.h>
#include <torch/extension.h>
#include <vector>
#include <cuda.h>
#include <cuda_runtime_api.h>
#ifndef AT_CHECK
#define AT_CHECK TORCH_CHECK
#endif
#define CHECK_CUDA(x) AT_CHECK(x.type().is_cuda(), #x, " must be a CUDAtensor ")
#define CHECK_CONTIGUOUS(x) AT_CHECK(x.is_contiguous(), #x, " must be contiguous ")
#define CHECK_INPUT(x) CHECK_CUDA(x);CHECK_CONTIGUOUS(x)
#define DIVUP(m,n) ((m) / (n) + ((m) % (n) > 0))
#define CHECK_ERROR(ans) { gpuAssert((ans), __FILE__, __LINE__); }
inline void gpuAssert(cudaError_t code, const char *file, int line, bool abort=true)
{
if (code != cudaSuccess)
{
fprintf(stderr,"GPUassert: %s %s %d\n", cudaGetErrorString(code), file, line);
if (abort) exit(code);
}
}
const int THREADS_PER_BLOCK_NMS = sizeof(unsigned long long) * 8;
后面的代码省略,要不然太长了
后面的代码省略,要不然太长了
后面的代码省略,要不然太长了
后面的代码省略,要不然太长了
修改好iou3d.cpp后,执行如下命令,即可成功安装:
cd $KM3D_ROOT/src/lib/utiles/iou3d
python setup.py install
3.处理kitti数据集
kitti数据集按照km3d要求来处理
KM3DNet
├── kitti_format
│ ├── data
│ │ ├── kitti
│ │ | ├── annotations /kitti_val.json kitti_train.json
│ │ │ ├── calib /000000.txt .....
│ │ │ ├── image(left[0-7480] right[7481-14961] input augmentatiom)
│ │ │ ├── label /000000.txt .....
| | | ├── train.txt val.txt trainval.txt
calib是left image training集的。kitti自带。
image是left image training和right image training在一起的。kitti自带。其中,right image training集图片的名称要修改一下,修改脚本如下:
import os
import cv2
original_path = './image_3/'
process_path = './process_right_image/'
original_name = os.listdir(original_path)
for i, ori_name in enumerate(original_name):
ori_image = cv2.imread(original_path + ori_name)
ori_num = ori_name.replace('.png', '')
ori_num = int(ori_num)
new_num = ori_num + 7481
if new_num > 9999:
new_name = '0' + str(new_num) + '.png'
else:
new_name = '00' + str(new_num) + '.png'
cv2.imwrite(process_path + new_name, ori_image)
print(i+1)
print(ori_num)
print(new_num)
print(new_name)
label是left image training 的标签。kitti自带。
train.txt val.txt trainval.txt 是KM3D自带。
annotations文件夹要自己新建,然后里面的kitti_val.json和kitti_train.json需要运行代码生成!!!生成方法如下:
python src/tools/kitti.py
如果没有annotations和kitti_val.json文件的话,后面运行程序会报错:
No such file or directory: '../kitti_format/data/kitti/annotations/kitti_val.json'
4.训练
参考官方文档Getting Started部分。
根据自己的显卡调整训练的参数。
ResNet-18骨干网络:
python ./src/main.py --data_dir ./kitti_format --exp_id KM3D_res18 --arch res_18 --batch_size 8 --master_batch_size 16 --lr 1.5625e-5 --gpus 0 --num_epochs 200
执行上述命令,会出现如下错误:
报错1
Traceback (most recent call last):
File "./src/main.py", line 111, in <module>
main(opt)
File "./src/main.py", line 73, in main
log_dict_train, _ = trainer.train(epoch, train_loader)
File "/root/RTM3D/src/lib/trains/base_trainer.py", line 162, in train
return self.run_epoch('train', epoch, data_loader,unlabel_loader1,unlabel_loader2,unlabel_set,iter_num,uncert)
File "/root/RTM3D/src/lib/trains/base_trainer.py", line 97, in run_epoch
output, loss, loss_stats = model_with_loss(batch,phase=phase)
File "/root/anaconda3/envs/open-mmlab/lib/python3.7/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/root/RTM3D/src/lib/trains/base_trainer.py", line 33, in forward
loss, loss_stats = self.loss(outputs, batch,phase)
File "/root/anaconda3/envs/open-mmlab/lib/python3.7/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/root/RTM3D/src/lib/trains/car_pose.py", line 52, in forward
coor_loss, prob_loss, box_score = self.position_loss(output, batch,phase)
File "/root/anaconda3/envs/open-mmlab/lib/python3.7/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/root/RTM3D/src/lib/models/losses.py", line 332, in forward
cys = (batch['ind'] / self.opt.output_w).int().float()
RuntimeError: Integer division of tensors using div or / is no longer supported, and in a future release div will perform true division as in Python 3. Use true_divide or floor_divide (// in Python) instead.
版本问题,tensor和int之间的除法不能直接用’/‘,用torch.true_divide()代替。修改’/src/lib/models/losses.py’中的第332行,修改后:
cys = torch.true_divide(batch['ind'], self.opt.output_w).int().float()
报错2
Traceback (most recent call last):
File "./src/main.py", line 111, in <module>
main(opt)
File "./src/main.py", line 73, in main
log_dict_train, _ = trainer.train(epoch, train_loader)
File "/root/RTM3D/src/lib/trains/base_trainer.py", line 162, in train
return self.run_epoch('train', epoch, data_loader,unlabel_loader1,unlabel_loader2,unlabel_set,iter_num,uncert)
File "/root/RTM3D/src/lib/trains/base_trainer.py", line 97, in run_epoch
output, loss, loss_stats = model_with_loss(batch,phase=phase)
File "/root/anaconda3/envs/open-mmlab/lib/python3.7/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/root/RTM3D/src/lib/trains/base_trainer.py", line 33, in forward
loss, loss_stats = self.loss(outputs, batch,phase)
File "/root/anaconda3/envs/open-mmlab/lib/python3.7/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/root/RTM3D/src/lib/trains/car_pose.py", line 52, in forward
coor_loss, prob_loss, box_score = self.position_loss(output, batch,phase)
File "/root/anaconda3/envs/open-mmlab/lib/python3.7/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/root/RTM3D/src/lib/models/losses.py", line 440, in forward
dim_mask_score_mask = 1 - (dim_mask_score_mask > 0)
File "/root/anaconda3/envs/open-mmlab/lib/python3.7/site-packages/torch/tensor.py", line 396, in __rsub__
return _C._VariableFunctions.rsub(self, other)
RuntimeError: Subtraction, the `-` operator, with a bool tensor is not supported. If you are trying to invert a mask, use the `~` or `logical_not()` operator instead.
原因是pytorch最新版本中,不支持bool型与int型减法,如果需要对bool变量进行反转,则使用“~”操作。修改’/src/lib/models/losses.py‘中第440行,修改后
dim_mask_score_mask = ~ (dim_mask_score_mask > 0)
5 Results generation
python ./src/faster.py --demo ./kitti_format/data/kitti/val.txt --data_dir ./kitti_format --calib_dir ./kitti_format/data/kitti/calib/ --load_model ./kitti_format/exp/KM3D_res18/model_last.pth --gpus 0 --arch res_18
报错1:
Traceback (most recent call last):
File "./src/faster.py", line 55, in <module>
demo(opt)
File "./src/faster.py", line 46, in demo
ret = detector.run(image_name)
File "/root/RTM3D/src/lib/detectors/base_detector.py", line 139, in run
output, dets, forward_time = self.process(images,meta,return_time=True)
File "/root/RTM3D/src/lib/detectors/car_pose.py", line 57, in process
output['hm'], output['hps'], output['dim'], output['rot'], prob=output['prob'],K=self.opt.K, meta=meta, const=self.const)
File "/root/RTM3D/src/lib/models/decode.py", line 788, in car_pose_decode_faster
scores, inds, clses, ys, xs = _topk(heat, K=K)
File "/root/RTM3D/src/lib/models/decode.py", line 109, in _topk
topk_ys = (topk_inds / width).int().float()
RuntimeError: Integer division of tensors using div or / is no longer supported, and in a future release div will perform true division as in Python 3. Use true_divide or floor_divide (// in Python) instead.
版本问题,tensor和int之间的除法不能直接用’/’,用torch.true_divide()代替。
topk_ys = torch.true_divide(topk_inds, width).int().float()
后面还有类似的bug,这里只列举一个。
报错2:
参考https://blog.csdn.net/long_songs/article/details/124736338?ops_request_misc=&request_id=&biz_id=102&utm_term=Overload%20resolution%20failed:%20>%20&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-0-124736338.nonecase&spm=1018.2226.3001.4187
具体的报错信息忘了截图了,类似于下面的错误
cv2.error: OpenCV(4.5.2) :-1: error: (-5:Bad argument) in function 'pointPolygonTest'
> Overload resolution failed:
> - Can't parse 'pt'. Sequence item with index 0 has a wrong type
> - Can't parse 'pt'. Sequence item with index 0 has a wrong type
这种就是因为不是int,在能加int的地方全给 int()上就完事了!。
/src/lib/utils/ddd_utils.py中的draw_bos_3d()函数中cv2.line()函数的参数修改成int()类型。
修改前:
def draw_box_3d(image, corners, c=(0, 0, 255)):
face_idx = [[0,1,5,4],
[1,2,6, 5],
[2,3,7,6],
[3,0,4,7]]
for ind_f in range(3, -1, -1):
f = face_idx[ind_f]
for j in range(4):
cv2.line(image, (corners[f[j], 0], corners[f[j], 1]),
(corners[f[(j+1)%4], 0], corners[f[(j+1)%4], 1]), c, 2, lineType=cv2.LINE_AA)
if ind_f == 0:
cv2.line(image, (corners[f[0], 0], corners[f[0], 1]),
(corners[f[2], 0]),corners[f[2], 1]), c, 1, lineType=cv2.LINE_AA)
cv2.line(image, (corners[f[1], 0], corners[f[1], 1]),
(corners[f[3], 0], corners[f[3], 1]), c, 1, lineType=cv2.LINE_AA)
return image
修改后:
def draw_box_3d(image, corners, c=(0, 0, 255)):
face_idx = [[0,1,5,4],
[1,2,6, 5],
[2,3,7,6],
[3,0,4,7]]
for ind_f in range(3, -1, -1):
f = face_idx[ind_f]
for j in range(4):
cv2.line(image, (int(corners[f[j], 0]),int(corners[f[j], 1])),
(int(corners[f[(j+1)%4], 0]), int(corners[f[(j+1)%4], 1])), c, 2, lineType=cv2.LINE_AA)
if ind_f == 0:
cv2.line(image, (int(corners[f[0], 0]), int(corners[f[0], 1])),
(int(corners[f[2], 0]),int(corners[f[2], 1])), c, 1, lineType=cv2.LINE_AA)
cv2.line(image, (int(corners[f[1], 0]), int(corners[f[1], 1])),
(int(corners[f[3], 0]), int(corners[f[3], 1])), c, 1, lineType=cv2.LINE_AA)
return image
6 Visualization
python ./src/faster.py --vis --demo ./kitti_format/data/kitti/val.txt --data_dir ./kitti_format --calib_dir ./kitti_format/data/kitti/calib/ --load_model ./kitti_format/exp/KM3D_res18/model_last.pth --gpus 0 --arch res_18
报错1:
Traceback (most recent call last):
File "./src/faster.py", line 55, in <module>
demo(opt)
File "./src/faster.py", line 46, in demo
ret = detector.run(image_name)
File "/root/RTM3D/src/lib/detectors/base_detector.py", line 163, in run
self.show_results(debugger, image, results, calib_numpy)
File "/root/RTM3D/src/lib/detectors/car_pose.py", line 113, in show_results
debugger.show_all_imgs(pause=self.pause)
File "/root/RTM3D/src/lib/utils/debugger.py", line 364, in show_all_imgs
cv2.imshow('{}'.format(i), v)
cv2.error: OpenCV(4.5.5) /io/opencv/modules/highgui/src/window.cpp:1268: error: (-2:Unspecified error) The function is not implemented. Rebuild the library with Windows, GTK+ 2.x or Cocoa support.
If you are on Ubuntu or Debian, install libgtk2.0-dev and pkg-config, then re-run cmake or configure script in function 'cvShowImage'
解决方法参考:
https://blog.csdn.net/tudou2013goodluck/article/details/108402055?ops_request_misc=&request_id=&biz_id=102&utm_term=If%20you%20are%20on%20Ubuntu%20or%20Debian&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-1-108402055.nonecase
conda remove opencv
conda install -c menpo opencv
pip install --upgrade pip
pip install opencv-contrib-python
效果图:
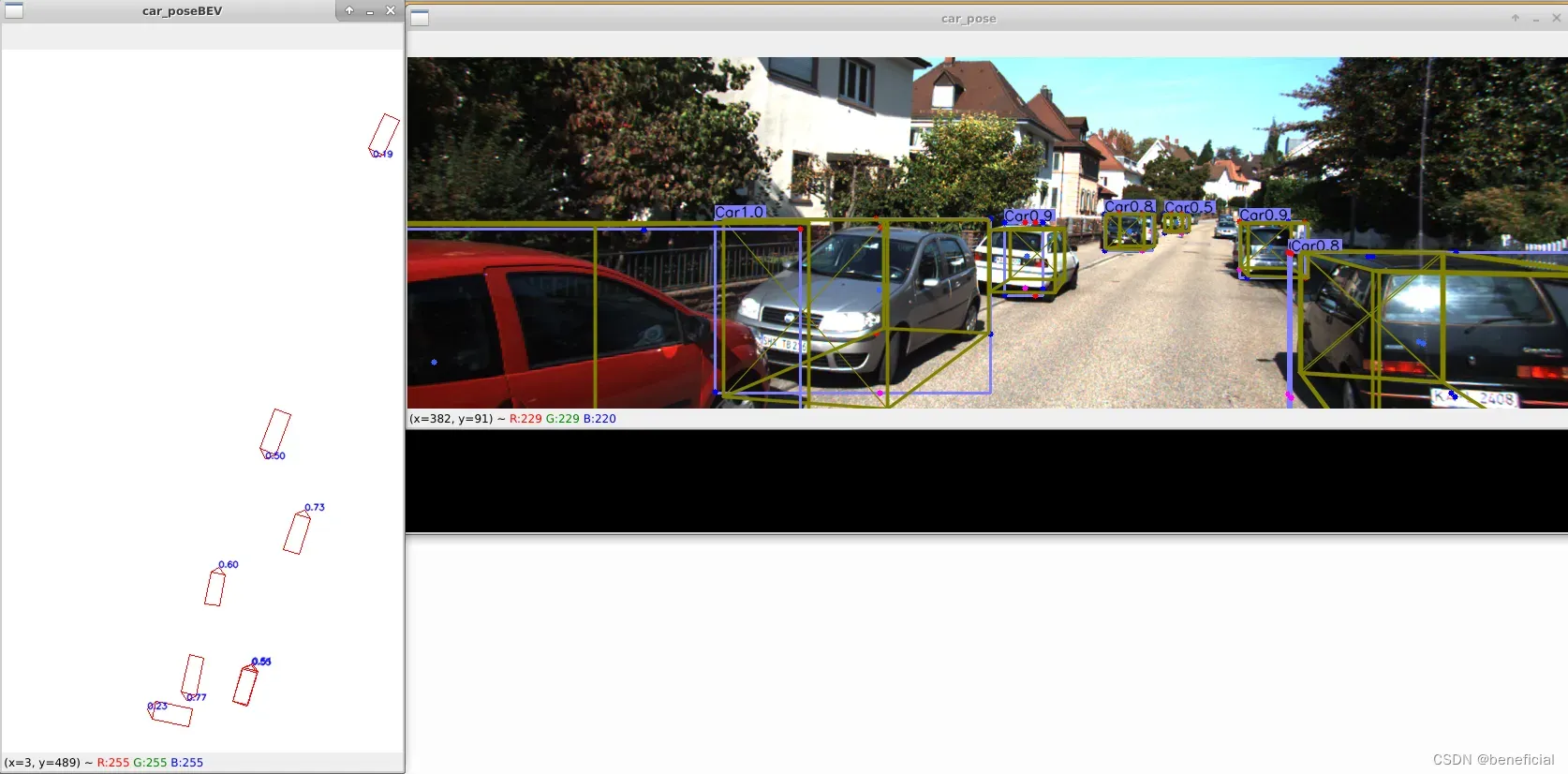
按键盘上的上下左右键可以切换图片。
注意这张图片中的黑色部分是终端黑窗口,截图的时候截下来了,不是图片显示错误。
7. All-in-one fashion
Generating results in all-in-one fashion. It simultaneously generates main center, 2D bounding box, regressed keypoints, heatmap keypoint, dim, orientation, confidence.
官方给的命令如下:
python ./src/faster.py --demo ./kitti_format/data/kitti/val.txt --calib_dir ./kitti_format/data/kitti/calib/ --load_model ./kitti_format/exp/KM3D_res18/model_last.pth --gpus 0 --arch res_18
执行命令会报错:
[ WARN:0@4.303] global /io/opencv/modules/imgcodecs/src/loadsave.cpp (239) findDecoder imread_('data/kitti/image/000001.png'): can't open/read file: check file path/integrity
Traceback (most recent call last):
File "./src/faster.py", line 57, in <module>
demo(opt)
File "./src/faster.py", line 48, in demo
ret = detector.run(image_name)
File "/root/RTM3D/src/lib/detectors/base_detector.py", line 127, in run
images, meta = self.pre_process(image, scale, meta)
File "/root/RTM3D/src/lib/detectors/base_detector.py", line 44, in pre_process
height, width = image.shape[0:2]
AttributeError: 'NoneType' object has no attribute 'shape'
注意报错信息的第一行,无法读取’data/kitti/image/000001.png’,显然路径是有问题的,无法读入图片,这才导致‘None Type’类型。
仔细观察这条命令,会发现这条命令和 上文中Results generation部分的命令只少了data_dir参数:
--data_dir ./kitti_format
个人感觉作者的命令是漏掉了这个参数,补上这个参数就能正常执行了,补上这个参数后路径就变成了./kitti_format/data/kitti/image/000001.png,这样路径才是正确的啊。
正确命令如下,同Results generation部分的命令:
python ./src/faster.py --demo ./kitti_format/data/kitti/val.txt --data_dir ./kitti_format --calib_dir ./kitti_format/data/kitti/calib/ --load_model ./kitti_format/exp/KM3D_res18/model_last.pth --gpus 0 --arch res_18
个人的理解就是这样的,愿意听听大家的理解。
8.Evaluation
python ./src/tools/kitti-object-eval-python/evaluate.py evaluate --label_path=./kitti_format/data/kitti/label/ --label_split_file ./kitti_format/data/kitti/val.txt --current_class=0,1,2 --coco=False --result_path=./kitti_format/exp/results/data/
结果如下:
Car AP@0.70, 0.70, 0.70:
bbox AP:84.86, 67.33, 57.84
bev AP:22.03, 15.89, 16.11
3d AP:11.93, 8.26, 6.63
aos AP:84.84, 66.52, 57.12
Car AP_R40@0.70, 0.70, 0.70:
bbox AP:86.85, 70.19, 60.34
bev AP:15.91, 9.66, 8.50
3d AP:11.40, 5.57, 4.38
aos AP:86.82, 69.23, 59.24
Car AP@0.70, 0.50, 0.50:
bbox AP:84.86, 67.33, 57.84
bev AP:48.56, 33.41, 31.73
3d AP:43.06, 27.55, 26.34
aos AP:84.84, 66.52, 57.12
Car AP_R40@0.70, 0.50, 0.50:
bbox AP:86.85, 70.19, 60.34
bev AP:45.02, 30.01, 26.71
3d AP:42.28, 25.16, 22.66
aos AP:86.82, 69.23, 59.24
Pedestrian AP@0.50, 0.50, 0.50:
bbox AP:24.48, 27.27, 27.27
bev AP:3.03, 4.55, 4.55
3d AP:3.03, 4.55, 4.55
aos AP:19.60, 22.03, 22.03
Pedestrian AP_R40@0.50, 0.50, 0.50:
bbox AP:19.23, 24.33, 24.33
bev AP:0.00, 1.93, 1.93
3d AP:0.00, 1.25, 1.25
aos AP:14.75, 18.41, 18.41
Pedestrian AP@0.50, 0.25, 0.25:
bbox AP:24.48, 27.27, 27.27
bev AP:9.09, 13.64, 13.64
3d AP:9.09, 13.64, 13.64
aos AP:19.60, 22.03, 22.03
Pedestrian AP_R40@0.50, 0.25, 0.25:
bbox AP:19.23, 24.33, 24.33
bev AP:2.60, 6.25, 6.25
3d AP:2.60, 6.25, 6.25
aos AP:14.75, 18.41, 18.41
Cyclist AP@0.50, 0.50, 0.50:
bbox AP:3.03, 3.03, 3.03
bev AP:2.27, 2.27, 2.27
3d AP:2.27, 2.27, 2.27
aos AP:3.00, 3.00, 3.00
Cyclist AP_R40@0.50, 0.50, 0.50:
bbox AP:0.83, 0.83, 0.83
bev AP:0.00, 0.00, 0.00
3d AP:0.00, 0.00, 0.00
aos AP:0.82, 0.82, 0.82
Cyclist AP@0.50, 0.25, 0.25:
bbox AP:3.03, 3.03, 3.03
bev AP:2.27, 2.27, 2.27
3d AP:2.27, 2.27, 2.27
aos AP:3.00, 3.00, 3.00
Cyclist AP_R40@0.50, 0.25, 0.25:
bbox AP:0.83, 0.83, 0.83
bev AP:0.00, 0.00, 0.00
3d AP:0.00, 0.00, 0.00
aos AP:0.82, 0.82, 0.82
文章出处登录后可见!