Spatial Dual-Modality Graph Reasoning for Key Information Extraction
基本信息
- 论文链接:arxiv
- 发表时间:2021
- 应用场景:文档关键信息抽取
摘要
| 存在什么问题 | 解决了什么问题 |
|---|---|
| 1. 先前的文档关键信息抽取大都不鲁棒(新的模板或者ocr识别结果错误),导致了其泛化性不高的缺陷。 | 1. 提出了一个端到端文档关键信息抽取模型SDMGR,将文档图像看做成一个双模态图网络,该网络融合了visual以及text信息,进而完成关键信息抽取功功能。并且该网络在泛化性很高,能够直接用于没见过的文档版式的关键信息抽取任务。 2. 提出了一个新的且更具挑战性的用于关键文档信息抽取数据集WildReceipt,包含25中kv,这其中包括了一些易混淆kv对。并且数据量是SROIE的两倍。 3. SDMGR在SROIE以及WildReceipt数据集上均取得了SOTA。 |
模型结构
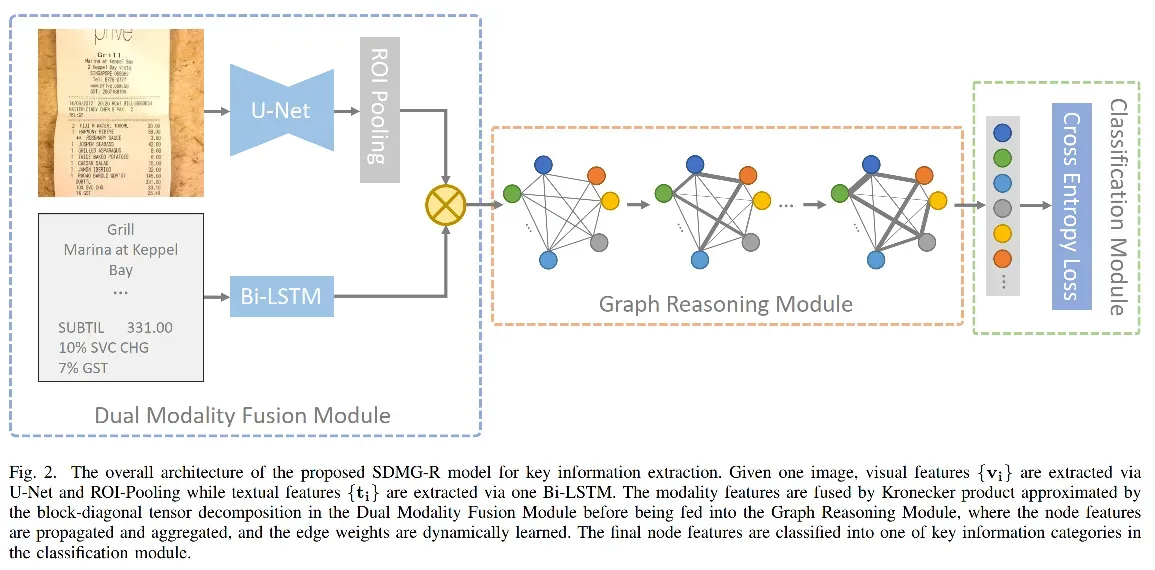
背景
对于一个OCR输出框,可以用来表示,目的是将
分类成某个既定类别y。
该模型由于使用到了图神经网络,因此将其视作图节点(OCR框)分类任务以及图中边的分类任务(key、value是成pair出现的,因此需要边预测,一个二分类即可)
Dual-Modality Fusion Module
对于每一个OCR输出框(index=i,总框数=n):
视觉模态通过UNet抽取,去上采样阶段最后一个feature map再通过ROIPooling算子输出固定长度的向量,称其为视觉特征,用来表示,shape=[n, d1]
文本模态通过LSTM抽取,对于框内的每个字符(注意是字符level),先将它们做embedding(embedding matrix shape=[vocab_size, d],然后从左到右输入给LSTM cell,拿到其最后一个step的输出,即为文本模态特征。shape=[n, d2]
对两种模态的特征通过kronecker product做融合,此时shape=[nxn,d1xd2]。再通过一个fc层做降维,此时维度设为。即:
![]()
作者任务这么求比较耗费内存与计算资源,采取了一种优化策略来计算
,没太看懂,就不列了…反正就是把
求出来就对了。
Graph Reasoning Module
将所有OCR框看成是图中的节点,那么此时节点已经具备了上面抽出来的融合特征,对于边的特征,总共有5维(通过concat操作连接起来的),确定规则如下:

message passing策略:

Graph reasoning
每个节点的信息更新策略如下:

注意边的特征、节点特征以及随着图神经网络的加深都是在不断进行迭代的。
Loss
采用CEloss即可:

实验
SROIE数据集上取得SOTA:
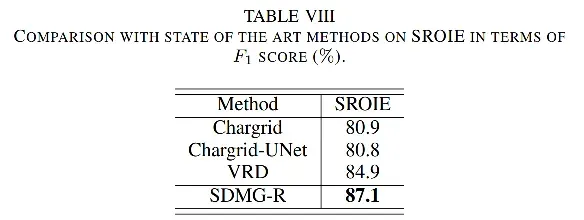
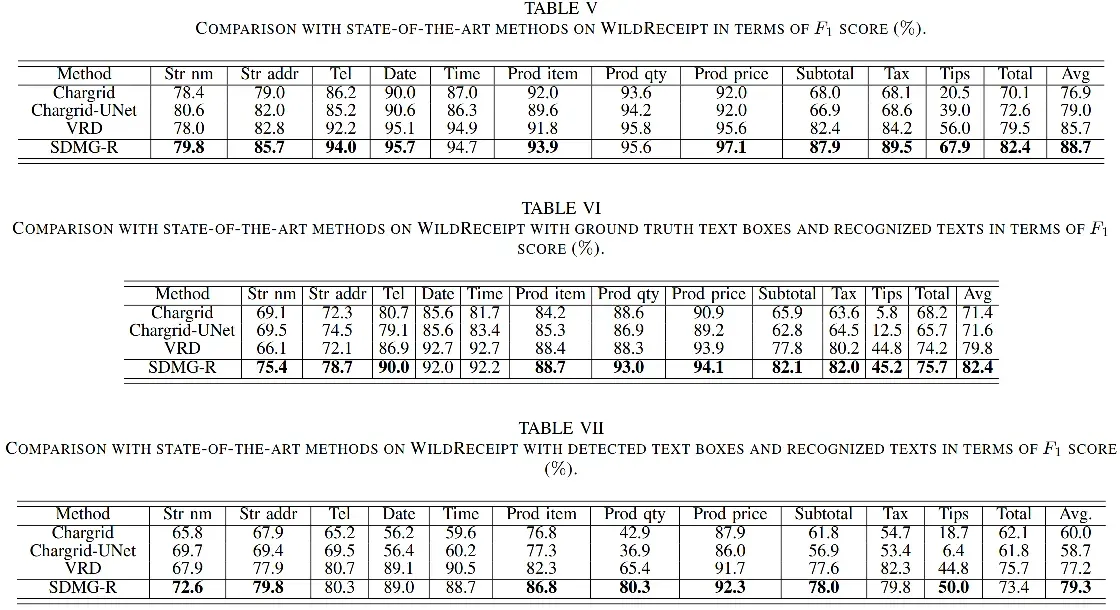
WildReceipt数据集上不同GT来源时的对比,多数kv抽取精度达到SOTA:
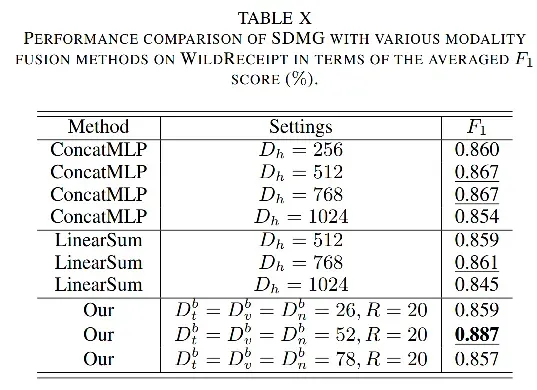
消融实验,验证了通过kronecker product做特征融合的效果是最好的:
总结
- 提出了一个基于CNN+LSTM+GNN的端到端文档关键信息抽取模型SDMGR,通过Kronecker product算子融合两种模态特征,并对其进行计算量以及内存占用上的优化,并构建了一个规模更大的同于文档关键信息抽取的数据集WildReceipt。
- 个人感觉基于图神经网络的关键信息抽取模型在抽取性能上应该不如后来的transformer-based模型,毕竟采取了一些手工特征,相当于加入了比较多的归纳偏置。另外也没有大规模无标注数据做预训练,在特征表达上可能没有transformer-based模型那么丰富。
- 优化Kronecker product那块没太看懂,需要看看代码…
文章出处登录后可见!