今天在把.pt文件转ONNX文件时,遇到此错误。
报错
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:0! (when checking argument for argument mat2 in method wrapper_mm)
原因
代码中的Tensor**,一会在CPU中运行,一会在GPU中运行**,所以最好是都放在同一个device中执行。
pytorch有两种模型保存方式:
一、保存整个神经网络的的结构信息和模型参数信息,save的对象是网络net
二、只保存神经网络的训练模型参数,save的对象是net.state_dict()
对应两种保存模型的方式,pytorch也有两种加载模型的方式。对应第一种保存方式,加载模型时通过torch.load(‘.pth’)直接初始化新的神经网络对象;对应第二种保存方式,需要首先导入对应的网络,再通过net.load_state_dict(torch.load(‘.pth’))完成模型参数的加载。
解决方案
在报错中寻找错误的哪一行,通过Print语句查看相关参数到底在那里运行
print(参数a.is_cuda,参数a.is_cuda)
然后把它们统一都放在CPU/GPU上就可以。
解决案例
案例1
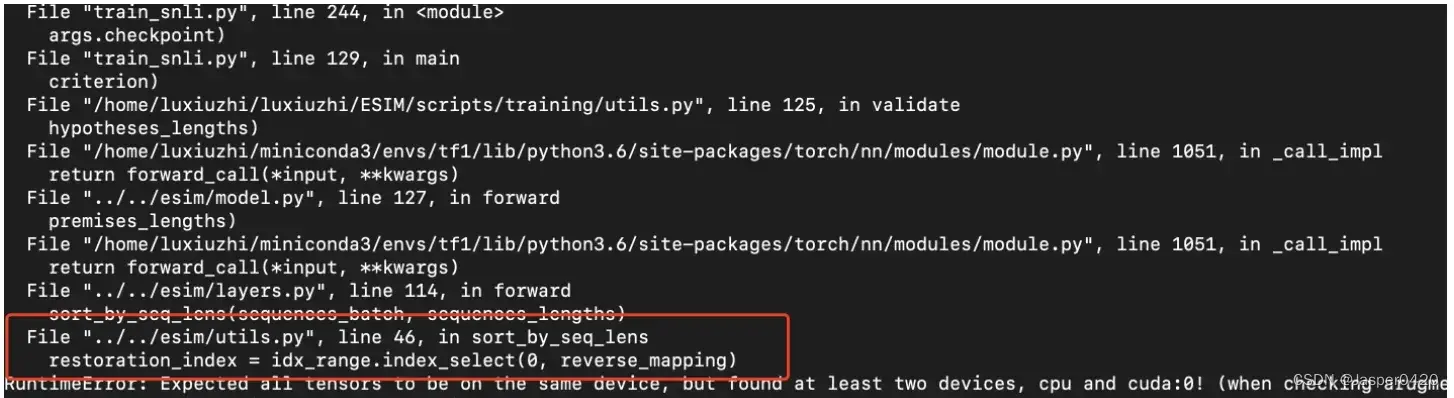
报错提示在utils.py 这个文件的问题
index = idx_ range.index_ select(0, reverse_ mapping )
使用print语句检查
print(index .is_cuda,idx_ range.is_cuda)
经过验证发现idx_range在cpu上,index在GPU上,把idx_range放在GPU即可。
idx_range.to(device)
如果遇到下面问题
NameError: name 'device' is not defined
请在开始加入语句
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
案例2
错误代码
if __name__ == '__main__':
model = Perception(2, 3, 2).cuda()
input = torch.randn(4, 2).cuda()
output = model(input)
# output = output.cuda()
label = torch.Tensor([0, 1, 1, 0]).long()
criterion = nn.CrossEntropyLoss()
loss_nn = criterion(output, label)
print(loss_nn)
loss_functional = F.cross_entropy(output, label)
print(loss_functional)
解决方案
将用到的Tensor都改为同一个device:Tensor.to(device)
if __name__ == '__main__':
#添加语句 device = torch.device('cuda:0')以及.to(device)
device = torch.device('cuda:0')
model = Perception(2, 3, 2).to(device)
input = torch.randn(4, 2).to(device)
output = model(input).to(device)
label = torch.Tensor([0, 1, 1, 0]).long().to(device)
criterion = nn.CrossEntropyLoss()
loss_nn = criterion(output, label).to(device)
print(loss_nn)
loss_functional = F.cross_entropy(output, label)
print(loss_functional)
完整代码:
import torch
from torch import nn
import torch.nn.functional as F
from torch.nn import Linear
class linear(nn.Module): # 继承nn.Module
def __init__(self, in_dim, out_dim):
super(Linear, self).__init__() # 调用nn.Module的构造函数
# 使用nn.Parameter来构造需要学习的参数
self.w = nn.Parameter(torch.randn(in_dim, out_dim))
self.b = nn.Parameter(torch.randn(out_dim))
# 在forward中实现前向传播过程
def forward(self, x):
x = x.matmul(self.w)
y = x + self.b.expand_as(x) # expand_as保证矩阵形状一致
return y
class Perception(nn.Module):
def __init__(self, in_dim, hid_dim, out_dim):
super(Perception, self).__init__()
self.layer = nn.Sequential(
nn.Linear(in_dim, hid_dim),
nn.Sigmoid(),
nn.Linear(hid_dim, out_dim),
nn.Sigmoid()
)
# self.layer1 = Linear(in_dim, hid_dim)
# self.layer2 = Linear(hid_dim, out_dim)
def forward(self, x):
# x = self.layer1(x)
# y = torch.sigmoid(x)
# y = self.layer2(y)
# y = torch.sigmoid(y)
y = self.layer(x)
return y
if __name__ == '__main__':
device = torch.device('cuda:0')
model = Perception(2, 3, 2).to(device)
input = torch.randn(4, 2).to(device)
output = model(input).to(device)
# output = output.cuda()
label = torch.Tensor([0, 1, 1, 0]).long().to(device)
criterion = nn.CrossEntropyLoss()
loss_nn = criterion(output, label).to(device)
print(loss_nn)
loss_functional = F.cross_entropy(output, label)
print(loss_functional)
补充
如果遇到错误:Tensor for argument #2 ‘mat1’ is on CPU, but expected it to be on GPU (while checking arguments for addmm)
代表着模型在GPU上进行计算,需要将变量和模型都增加.to(device),都搬到GPU上。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
g = g.to(device)
model=model.to(device)
更多Ai资讯:公主号AiCharm

文章出处登录后可见!
已经登录?立即刷新