前言
摸到了组里配备的多卡服务器,对于一个习惯单卡环境的穷学生来说,就像是鸟枪换炮,可惜这炮一时还不会使用,因此就有了此番学习。
pycharm远程开发
在pycharm中,连接远程服务器非常容易,在解释器中选择远程服务器环境路径,以及项目同步文件夹即可。
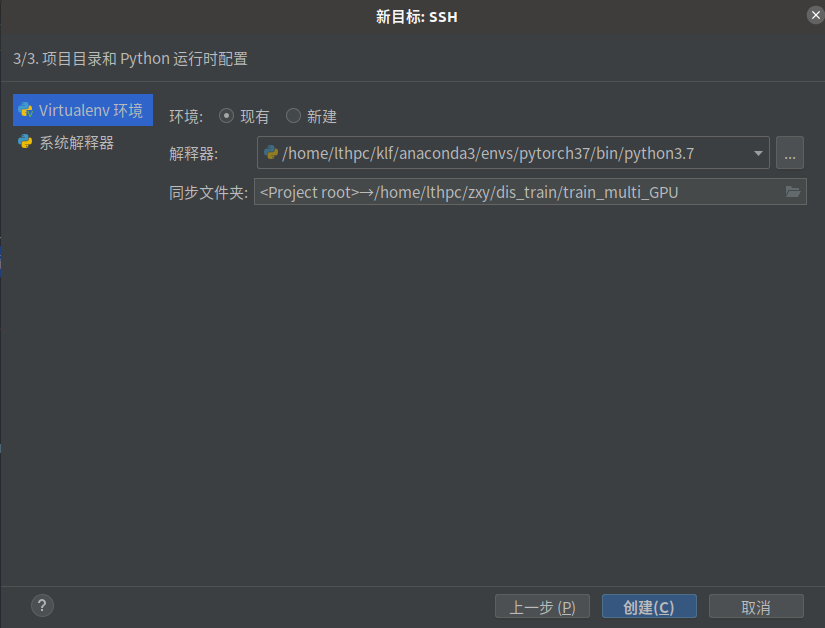
创建完成之后,系统会自动将本项目中所有的代码克隆上传到服务器中的相应路径。之后,每次修改,文件都会实时进行上传。
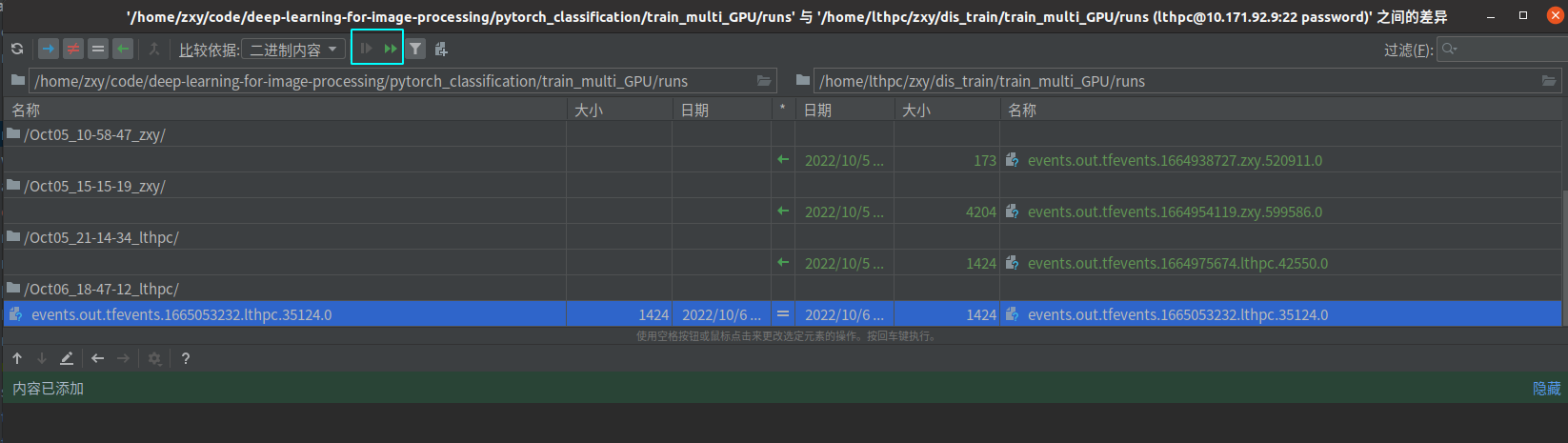
从服务器上下载文件也比较容易,以同步runs文件夹为例,选中runs文件夹,工具->部署->版本同步,点击下图中两个三角形。
第一个三角形是下载选中的文件,第二个三角形是下载全部文件。
分布式训练
本文使用的代码主要参考自霹雳吧啦Wz-pytorch多GPU并行训练教程
所用花蕊分类数据集:https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
测试代码通过构建ResNet34分类网络,解决花蕊数据集的5分类问题。为了加快测试效率,我只设定10个epoch进行比较。由于数据集比较简单,因此下面仅比较单卡和多卡的训练速度,整体精度差异不大。
单卡训练
单卡训练比较常规,所使用的服务器的环境是单卡TITAN Xp显卡。训练代码如下:
import os
import math
import argparse
import torch
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import torch.optim.lr_scheduler as lr_scheduler
from model import resnet34
from my_dataset import MyDataSet
from utils import read_split_data
from multi_train_utils.train_eval_utils import train_one_epoch, evaluate
import time
def main(args):
begin_time = time.time()
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
print(args)
print('Start Tensorboard with "tensorboard --logdir=runs", view at http://localhost:6006/')
tb_writer = SummaryWriter()
if os.path.exists("./weights") is False:
os.makedirs("./weights")
train_info, val_info, num_classes = read_split_data(args.data_path)
train_images_path, train_images_label = train_info
val_images_path, val_images_label = val_info
# check num_classes
assert args.num_classes == num_classes, "dataset num_classes: {}, input {}".format(args.num_classes,
num_classes)
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
# 实例化训练数据集
train_data_set = MyDataSet(images_path=train_images_path,
images_class=train_images_label,
transform=data_transform["train"])
# 实例化验证数据集
val_data_set = MyDataSet(images_path=val_images_path,
images_class=val_images_label,
transform=data_transform["val"])
batch_size = args.batch_size
# num_workers 从CPU数量(16)、batch_size、8 中选取最小值
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_data_set,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=nw,
collate_fn=train_data_set.collate_fn)
val_loader = torch.utils.data.DataLoader(val_data_set,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=nw,
collate_fn=val_data_set.collate_fn)
# 如果存在预训练权重则载入
model = resnet34(num_classes=args.num_classes).to(device)
if args.weights != "":
if os.path.exists(args.weights):
weights_dict = torch.load(args.weights, map_location=device)
# 由于官方提供的resnet34是在ImageNet上进行训练,最后一层连接层个数为1000
# 因此这里进行比较,只有每一层模型权重数和model一致时,再载入,舍弃最后一层权重
load_weights_dict = {k: v for k, v in weights_dict.items()
if model.state_dict()[k].numel() == v.numel()}
print(model.load_state_dict(load_weights_dict, strict=False))
else:
raise FileNotFoundError("not found weights file: {}".format(args.weights))
# 是否冻结权重
if args.freeze_layers:
for name, para in model.named_parameters():
# 除最后的全连接层外,其他权重全部冻结
if "fc" not in name:
para.requires_grad_(False)
# 提取没有冻结的层
pg = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.SGD(pg, lr=args.lr, momentum=0.9, weight_decay=0.005)
# Scheduler https://arxiv.org/pdf/1812.01187.pdf
lf = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - args.lrf) + args.lrf # cosine
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
for epoch in range(args.epochs):
# train
mean_loss = train_one_epoch(model=model,
optimizer=optimizer,
data_loader=train_loader,
device=device,
epoch=epoch)
scheduler.step()
# validate
sum_num = evaluate(model=model,
data_loader=val_loader,
device=device)
acc = sum_num / len(val_data_set)
print("[epoch {}] accuracy: {}".format(epoch, round(acc, 3)))
tags = ["loss", "accuracy", "learning_rate"]
tb_writer.add_scalar(tags[0], mean_loss, epoch)
tb_writer.add_scalar(tags[1], acc, epoch)
tb_writer.add_scalar(tags[2], optimizer.param_groups[0]["lr"], epoch)
torch.save(model.state_dict(), "./weights/model-{}.pth".format(epoch))
end_time = time.time()
print("程序花费时间{}秒".format(end_time-begin_time))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--num_classes', type=int, default=5)
parser.add_argument('--epochs', type=int, default=10)
parser.add_argument('--batch-size', type=int, default=16)
parser.add_argument('--lr', type=float, default=0.001, help="初始学习率")
parser.add_argument('--lrf', type=float, default=0.1, help="最终学习率会变为初始*0.1")
# 数据集所在根目录
# https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
parser.add_argument('--data-path', type=str,
default="dataset/flower_photos")
parser.add_argument('--weights', type=str, default='',
help='initial weights path')
parser.add_argument('--freeze-layers', type=bool, default=False)
parser.add_argument('--device', default='cuda', help='device id (i.e. 0 or 0,1 or cpu)')
opt = parser.parse_args()
main(opt)
终端输入:
python train_single_gpu.py
程序花费时间共141.53秒
单机多卡训练
多卡分布式训练主要可分成数据并行和模型并行。
数据并行就是多卡分别载入同一个模型,对于一个数据集分别采样不同的数据,然后进行训练,这是大多数多卡训练的使用场景。
模型并行主要应对模型过大,单张卡无法进行加载,因此需要将模型切割成多个部分,载入不同的模型,比如AlexNet就是将一个模型放在两张卡上进行训练。这个实现起来较为麻烦,需要对网络的forward部分单独进行修改。
在Pytorch中, 单机多卡训练主要可以有DataParallel和DistributedDataParallel
DataParallel
DataParallel是最早出现的方式,它的原理是先根据batch_size将数据分发到各块GPU上,每次做前向传播时,将模型复制到各块GPU上,然后各GPU将计算得到的梯度传回到第一块GPU进行梯度更新。
相关使用命令[1]:
### 第一步:构建模型
'''
module 需要分发的模型
device_ids 可分发的gpu,默认分发到所有看见GPU(环境变量设置的)
output_device 结果输出设备 通常设置成逻辑gpu的第一个
'''
module=your_simple_net() #你的模型
Your_Parallel_Net=torch.nn.DataParallel(module,device_ids=None,output_device=None)
### 第二步:数据迁移
inputs=inputs.to(device)
labels=labels.to(device)
#此处的device通常应为模型输出的output_device,否则无法计算loss
很明显,这种方式效率很低,每次复制模型需要消耗大量通信资源,造成GPU使用率不足,同时0卡会作为主卡来进行计算汇总,会导致0卡的显存占用率比其它各卡都高。因此这种方法基本被弃用。
DistributedDataParallel
DistributedDataParallel简称DDP,分布式训练,是目前主流训练方式。
DDP采用多进程控制多GPU,共同训练模型,一份代码会被pytorch自动分配到n个进程并在n个GPU上运行。 DDP运用Ring-Reduce通信算法在每个GPU间对梯度进行通讯,交换彼此的梯度,从而获得所有GPU的梯度。对比DP,不需要在进行模型本体的通信,因此可以加速训练[2]。
下面给出了三种DDP的实现方式:
方式一:torch.distributed.launch
相关代码为train_multi_gpu_using_launch.py
代码大部分和单卡训练相同,主要有下面一些细节差异:
开始训练前,需要初始化各进程环境:
# 初始化各进程环境
init_distributed_mode(args=args)
def init_distributed_mode(args):
if 'RANK' in os.environ and 'WORLD_SIZE' in os.environ:
args.rank = int(os.environ["RANK"])
args.world_size = int(os.environ['WORLD_SIZE'])
args.gpu = int(os.environ['LOCAL_RANK'])
elif 'SLURM_PROCID' in os.environ:
args.rank = int(os.environ['SLURM_PROCID'])
args.gpu = args.rank % torch.cuda.device_count()
else:
print('Not using distributed mode')
args.distributed = False
return
args.distributed = True
torch.cuda.set_device(args.gpu)
args.dist_backend = 'nccl' # 通信后端,nvidia GPU推荐使用NCCL
print('| distributed init (rank {}): {}'.format(
args.rank, args.dist_url), flush=True)
dist.init_process_group(backend=args.dist_backend, init_method=args.dist_url,
world_size=args.world_size, rank=args.rank)
dist.barrier() # 等待各GPU初始化完成
相关参数[3]:
- node:物理实例或容器;
- worker:分布训练环境中的 worker;
- group:进程组,所有进程的子集,用于集体通信等;
- backend(后端):进程通信库,PyTorch 支持 NCCL,GLOO,MPI;
- world_size:进程组中的进程数,可以认为是全局进程个数,即总共有几个 worker;(world_size可以视作有几块GPU)
- rank:分配给进程组中每个进程的唯一标识符,这个 worker 是全局第几个 worker;(rank可以视作第几块GPU)
- local_rank:进程内的 GPU 编号,一般由 torch.distributed.launch 内部指定;(local_rank可以视作本机上第几块GPU,主要是多几多卡上需要考虑)
学习率需要一定程度进行扩大,因为DDP相当于每个epoch完成以往多轮的学习量,因此学习率要适当增大,这里比较简单的采用学习率乘以GPU数量的方式:
args.lr *= args.world_size # 学习率要根据并行GPU的数量进行倍增
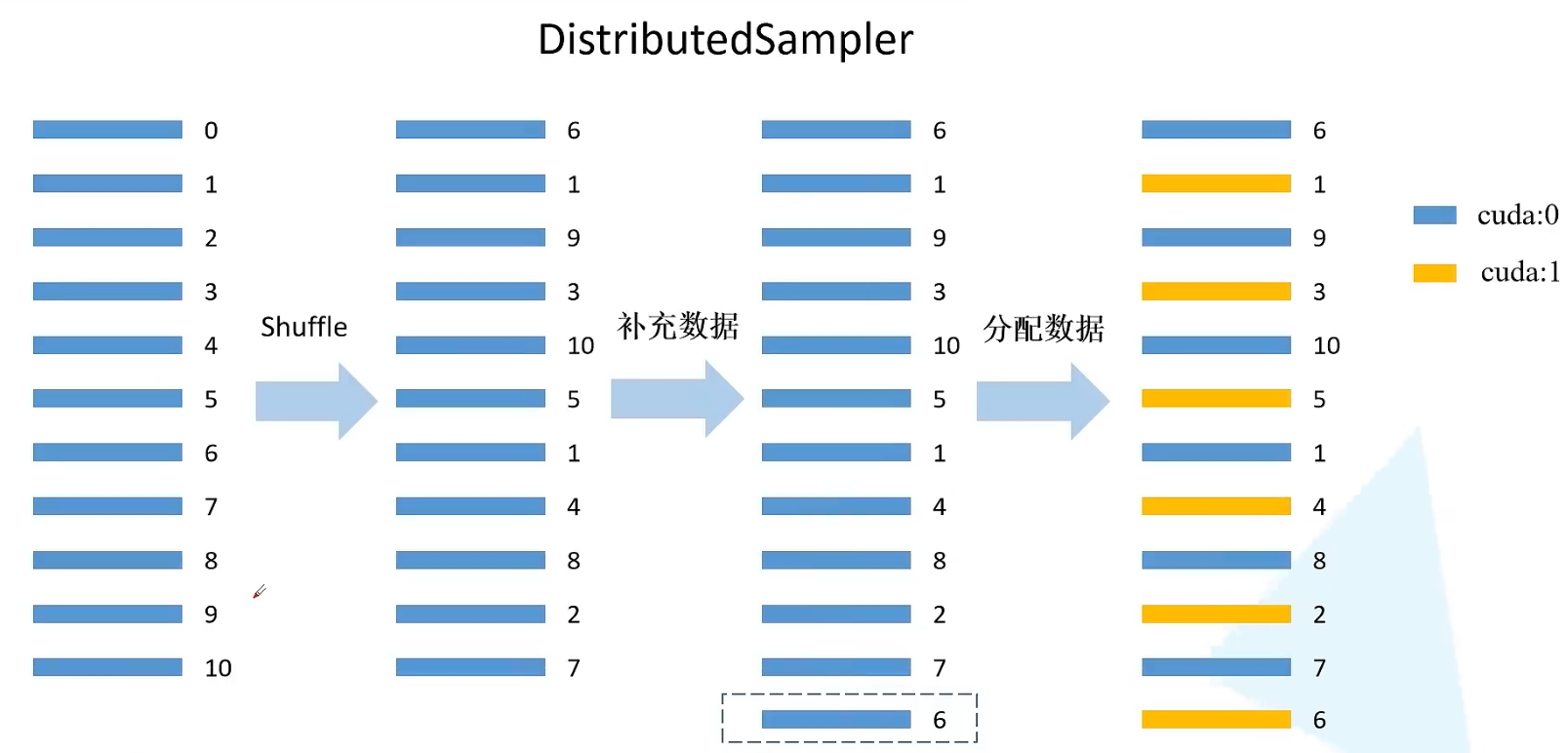
DPP在载入数据前,需要给每块GPU分配样本索引,这里主要使用的是DistributedSampler
其原理如下图[1]所示,首先会根据epoch和seed进行一个打乱操作,然后根据GPU的数量来补充数据,保证每个GPU都有相等的数据量,最后分配索引供不同的GPU进行数据选择,保证让各GPU训练到不同的数据。
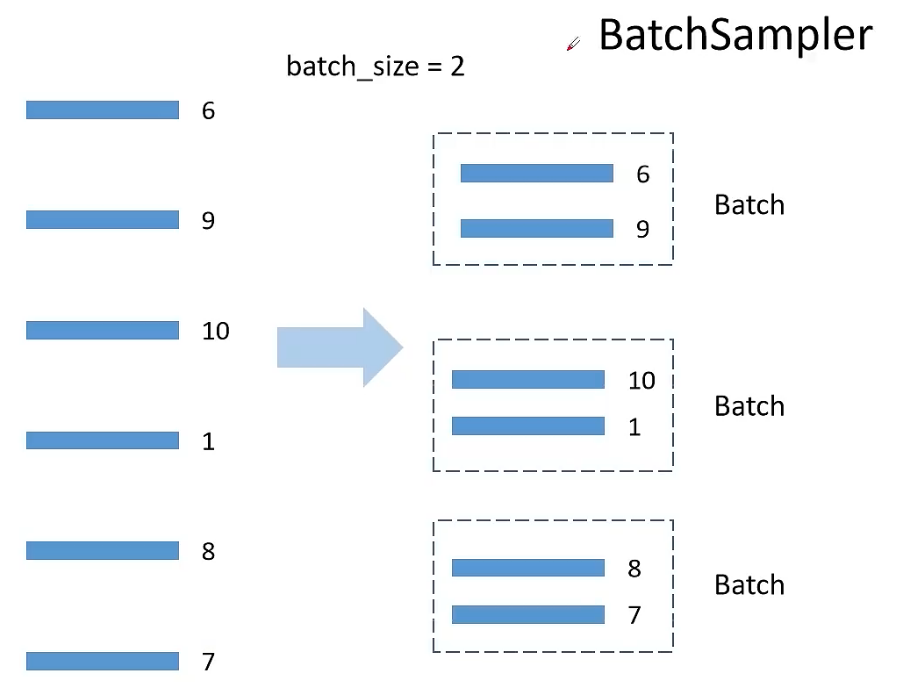
分配完之后,需要使用BatchSampler来将各GPU根据分配的索引来读取数据,这里可以设定drop_last参数,如果为True,则最后一个batch小于batch_size,会进行舍弃。
# 给每个rank对应的进程分配训练的样本索引
train_sampler = torch.utils.data.distributed.DistributedSampler(train_data_set)
val_sampler = torch.utils.data.distributed.DistributedSampler(val_data_set)
# 将样本索引每batch_size个元素组成一个list
train_batch_sampler = torch.utils.data.BatchSampler(
train_sampler, batch_size, drop_last=True)
载入模型有个小细节,由于多卡训练需要保证各卡训练的起点相同,即初始权重相同,因此若不是加载预训练权重,则需要将第一块GPU中的初始化权重进行保存,然后再让其它模型加载。(事实上DDP默认完成模型权重同步的操作,因此这一步不做也可以)
# 如果存在预训练权重则载入
if os.path.exists(weights_path):
weights_dict = torch.load(weights_path, map_location=device)
load_weights_dict = {k: v for k, v in weights_dict.items()
if model.state_dict()[k].numel() == v.numel()}
model.load_state_dict(load_weights_dict, strict=False)
else:
checkpoint_path = os.path.join(tempfile.gettempdir(), "initial_weights.pt")
# 如果不存在预训练权重,需要将第一个进程中的权重保存,然后其他进程载入,保持初始化权重一致
if rank == 0:
torch.save(model.state_dict(), checkpoint_path)
dist.barrier()
# 这里注意,一定要指定map_location参数,否则会导致第一块GPU占用更多资源
model.load_state_dict(torch.load(checkpoint_path, map_location=device))
DDP中引入了一个新的参数syncBN来控制在每一个epoch中,各GPU是否同步BN层,因为BN层相当于是在计算每一个batch数据的均值和方差,同步BN层之后,相当于扩大了整体的batchsize,让结果更精确,同时也会带来新的通讯消耗量,减缓网络训练时间。
# 只有训练带有BN结构的网络时使用SyncBatchNorm采用意义
if args.syncBN:
# 使用SyncBatchNorm后训练会更耗时
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
创建模型时,需要将模型转换成DDP模型:
# 转为DDP模型
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu])
训练时,需要在每轮训练时,调用 train_sampler.set_epoch(epoch),这样是和之前的DistributedSampler配合使用,确保每轮各卡采集到不同的数据。
再反向传播时,最终结果返回的是各卡的累计结果,因此需要除以卡的数量来进行取平均。
@torch.no_grad()
def evaluate(model, data_loader, device):
model.eval()
# 用于存储预测正确的样本个数
sum_num = torch.zeros(1).to(device)
# 在进程0中打印验证进度
if is_main_process():
data_loader = tqdm(data_loader, file=sys.stdout)
for step, data in enumerate(data_loader):
images, labels = data
pred = model(images.to(device))
pred = torch.max(pred, dim=1)[1]
sum_num += torch.eq(pred, labels.to(device)).sum()
# 等待所有进程计算完毕
if device != torch.device("cpu"):
torch.cuda.synchronize(device)
sum_num = reduce_value(sum_num, average=False)
return sum_num.item()
def reduce_value(value, average=True):
world_size = get_world_size()
if world_size < 2: # 单GPU的情况
return value
with torch.no_grad():
dist.all_reduce(value)
if average:
value /= world_size
return value
最后模型训练完之后,调用dist.destroy_process_group(),释放多线程资源。
下面来进行测试,终端输入:
python -m torch.distributed.launch --nproc_per_node=5 --use_env train_multi_gpu_using_launch.py
nproc_per_node指定的是卡的总数,我这是8卡设备,因为同门在使用编号5、6两张卡,因此这里仅仅使用5张卡。
程序花费时间84.19秒,这比单卡训练快了不少,然而这速度也不是随卡的数量进行线性增长,因为需要考虑到多卡之间的通讯开销。

如果强行使用0-5六张卡,会导致整体速度变慢,花费时间上升到127.15秒,可见当一个卡上再同时跑不同程序时,会拖慢整体的进程。
可以看到7号卡处于空闲状态,因此可以通过下面的命令指定多卡训练
CUDA_VISIBLE_DEVICES=0,1,2,3,4,7 python -m torch.distributed.launch --nproc_per_node=6 --use_env train_multi_gpu_using_launch.py
用时77.38秒
方式二:torchrun
如果用最新版的pytroch运行torch.distributed.launch,会有一个提示,大致是torch.distributed.launch将被废弃,推荐使用torchrun,torchrun是一种最新的DDP启动方式。
torchrun 包含了torch.distributed.launch的所有功能,还有以下三点额外的功能[2]:
1、worker的rank和world_size将被自动分配
2、通过重新启动所有workers来处理workers的故障
3、允许节点数目在最大最小值之间有所改变 即具备弹性
torchrun的启动方式也很简单,无需指定 –use_env参数:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,7 torchrun --nproc_per_node=6 train_multi_gpu_using_launch.py
用时77.93秒,和torch.distributed.launch差距不大。
方式三:multiprocessing
multiprocessing即python自带的多线程库,使用起来需要配置的参数更多,相当于手动去实现了torchrun封装好的一些功能,更加灵活也更加繁琐,用的不多。
核心代码:
# when using mp.spawn, if I set number of works greater 1,
# before each epoch training and validation will wait about 10 seconds
mp.spawn(main_fun,
args=(opt.world_size, opt),
nprocs=opt.world_size,
join=True)
world_size = opt.world_size
processes = []
for rank in range(world_size):
p = Process(target=main_fun, args=(rank, world_size, opt))
p.start()
processes.append(p)
for p in processes:
p.join()
mp.spawn的主要参数如下:
- fn:派生程序入口;
- nprocs: 派生进程个数;
- join: 是否加入同一进程池;
- daemon:是否创建守护进程;
运行 train_multi_gpu_using_spawn.py:
python train_multi_gpu_using_spawn.py
程序花费时间81.20秒,这里手动将world-size设成了5,如果用6卡,和上面差异也不大。
多机多卡训练
多机多卡暂时没有这个硬件条件来进行实验,因此这里仅对相关知识进行记录。
多机多卡DDP有三种启动方法:torch.distributed.launch / torch.multiprocessing / Slurm Workload Manager
使用实例[2]:
########################## 第1步 ##########################
#初始化
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
torch.cuda.set_device(rank % torch.cuda.device_count())
dist.init_process_group(backend="nccl")
device = torch.device("cuda", local_rank)
########################## 第2步 ##########################
#模型定义
model = model.to(device)
model = DDP(model, device_ids=[local_rank], output_device=local_rank)
#数据集操作与DDP一致
#####运行
'''
exmaple: 2 node, 8 GPUs per node (16GPUs)
需要在两台机器上分别运行脚本
注意细节:node_rank master 为 0
机器1
>>> python -m torch.distributed.launch \
--nproc_per_node=8 \
--nnodes=2 \
--node_rank=0 \
--master_addr="master的ip" \
--master_port=xxxxx \
YourScript.py
机器2
>>> python -m torch.distributed.launch \
--nproc_per_node=8 \
--nnodes=2 \
--node_rank=1 \
--master_addr="master的ip" \
--master_port=xxxxx \
YourScript.py
'''
总结
单机多卡分布式训练基本使用torch.distributed.launch或torchrun即可,大多数开源项目提供了多卡训练的接口,比如mmdetection框架写好了多卡训练脚本tools/dist_train.sh,使用时,直接运行脚本再传参即可。
最后放一张八卡一起工作的截图:

References
[1]https://www.bilibili.com/video/BV1yt4y1e7sZ
[2]https://zhuanlan.zhihu.com/p/489011749
[3]https://blog.csdn.net/qq_41731861/article/details/121648790
文章出处登录后可见!