前言
- 本文是之前做云计算实验整理的内容,借博客保存一下!
- 使用不同方法对算法加速还是很有意思的!
实验题目
-
自选一张图片,按照实验指南说明在jetson05节点上基于OpenMP和CUDA对图片进行边缘提取实验,记录梯度向量幅度的最小值和最大值,比较串行算法和并行算法的运行时间,并提交处理后的边缘提取结果图片。试一下:如果编译时开启优化选项(比如选择“-O3”级别的优化),串行算法和并行算法的运行时间分别有什么变化。
-
使用提供的opencl-examples源码在你自己的计算机上进行基于OpenCL的GPU并行算法实验,记录你的实验环境参数(包括CPU和GPU相关参数等,可从实验程序日志中获取)以及各个算法的串行版本和GPU并行版本的运行时间,并进行简单的对比分析。
1. 基于OpenMP和CUDA对图片进行边缘提取实验
1.1 处理图片

1.2 基于OpenMP
1)串行算法
a. 运行命令
zz@jetson05:~/examples$ g++ -fopenmp -o sobel sobel.cpp -lfreeimage
zz@jetson05:~/examples$ ./sobel IBM_Blue_Gene_P_supercomputer.jpg
Filtering of input image start ...
the minimum value: 0
the maximum value: 1052.84
The total time for execution is 7.66395s
b. 运行截图

c. 图片处理结果

2)并行算法
a. 运行命令
zz@jetson05:~/examples$ g++ -fopenmp -o sobel_omp sobel_omp.cpp -lfreeimage
zz@jetson05:~/examples$ ./sobel_omp IBM_Blue_Gene_P_supercomputer.jpg
Filtering of input image start ...
the minimum value: 0
the maximum value: 1052.84
actual threads number: 8
The total time for execution is 2.20083s
b. 运行截图

c. 图片处理结果

3)线程数从8改成16
a. 修改代码

zz@jetson05:~/examples$ g++ -fopenmp -o sobel_omp16 sobel_omp.cpp -lfreeimage
zz@jetson05:~/examples$ ./sobel_omp16 IBM_Blue_Gene_P_supercomputer_out.jpg
Filtering of input image start ...
the minimum value: 0
the maximum value: 1001.81
actual threads number: 16
The total time for execution is 1.84612s
b. 运行截图及结果

4)编译算法时开启优化选项
a. 串行算法
选择“-O3”级别的优化
- 运行命令
zz@jetson05:~/examples$ g++ -fopenmp -O3 sobel sobel.cpp -lfreeimage
zz@jetson05:~/examples$ ./sobel IBM_Blue_Gene_P_supercomputer.jpg
Filtering of input image start ...
the minimum value: 0
the maximum value: 1052.84
The total time for execution is 7.65937s
- 运行截图及结果
结果:运行时间和1)差不多

b. 并行算法
选择“-O3”级别的优化
- 运行命令
zz@jetson05:~/examples$ g++ -fopenmp -O3 sobel_omp16 sobel_omp.cpp -lfreeimage
zz@jetson05:~/examples$ ./sobel_omp16 IBM_Blue_Gene_P_supercomputer_out.jpg
Filtering of input image start ...
the minimum value: 0
the maximum value: 1001.81
actual threads number: 16
The total time for execution is 0.741739s
- 运行截图及结果
如下图所示,运行时间为0.741739s 比 3)运行结果1.84612s快

1.3 基于CUDA
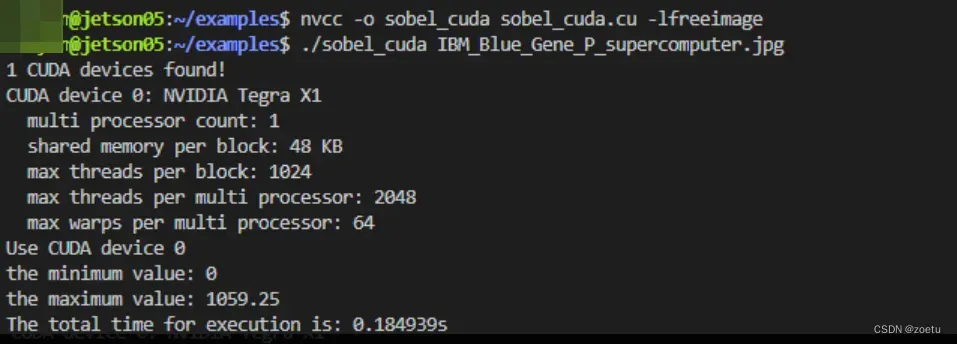
1) 运行命令
zz@jetson05:~/examples$ nvcc -o sobel_cuda sobel_cuda.cu -lfreeimage
zz@jetson05:~/examples$ ./sobel_cuda IBM_Blue_Gene_P_supercomputer.jpg
1 CUDA devices found!
CUDA device 0: NVIDIA Tegra X1
multi processor count: 1
shared memory per block: 48 KB
max threads per block: 1024
max threads per multi processor: 2048
max warps per multi processor: 64
Use CUDA device 0
the minimum value: 0
the maximum value: 1059.25
The total time for execution is: 0.184939s
2) 运行截图及结果
3) 图片处理结果

1.4 对比OpenMP和CUDA实验结果

显然,并行算法比串行要快,CUDA并行比OpenMP并行快。
2. 基于OpenCL的GPU并行算法实验
使用提供的opencl-examples源码在你自己的计算机上进行基于OpenCL的GPU并行算法实验,记录你的实验环境参数(包括CPU和GPU相关参数等,可从实验程序日志中获取)以及各个算法的串行版本和GPU并行版本的运行时间,并进行简单的对比分析。
2.1 实验环境参数
- opencl-example源码版本:opencl-examples-1.1.0-win-bin-x64
- CPU:Inte i5-8250U
- GPU:NVIDIA GeForce MX150
- CUDA版本:OpenCL 1.2 CUDA 11.0.228
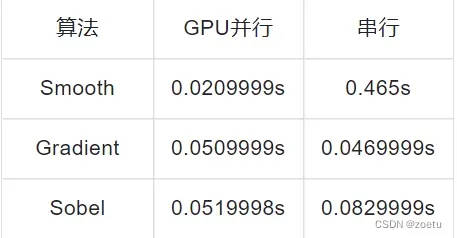
2.2 算法运行时间对比
- 运行截图及结果
实验源码参考:https://github.com/jianxuecn/cccourse-examples
文章出处登录后可见!
已经登录?立即刷新