gihub代码
论文-Arxiv-High-Resolution Image Synthesis with Latent Diffusion Models
参考视频:【渣渣讲课】试图做一个正常讲解Latent / Stable Diffusion的成年人
中文翻译论文(这篇翻译得很好)
文章目录
简要概述生成模型
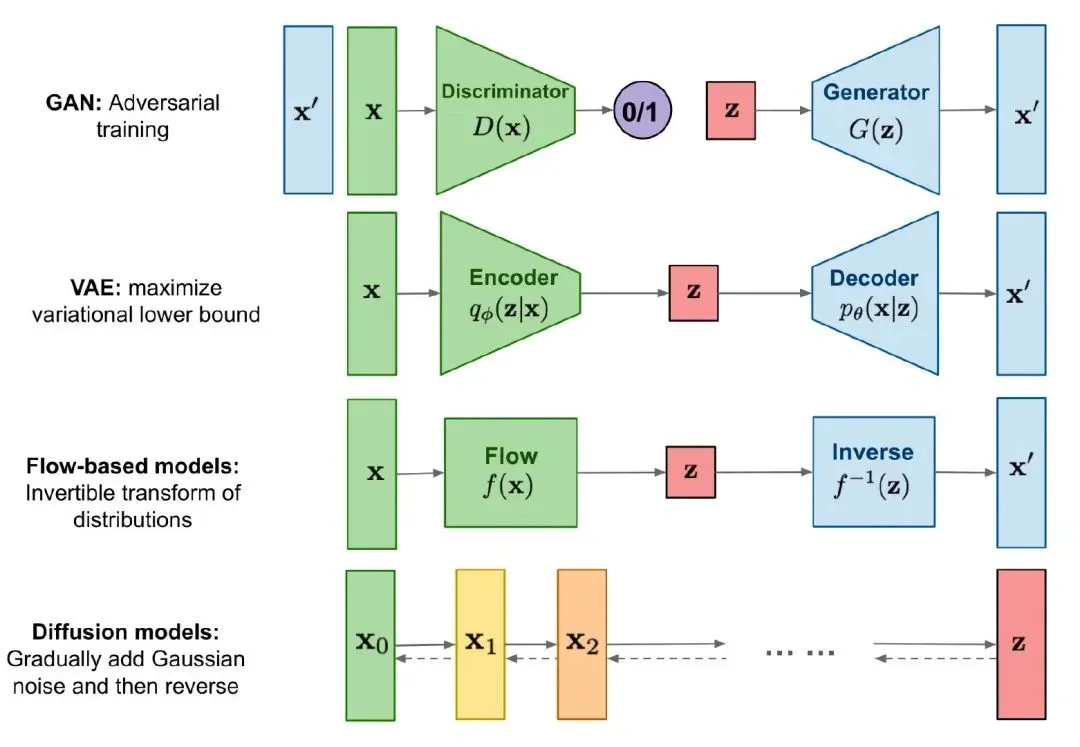
第一个GAN生成对抗网络,可以分为判别器和生成器两个部分,总体思想就是:我们先对判别器进行训练,让其判断给出的input 是否为生成器所生成的(二分类问题判断real or fake),在一段时间的训练后,判别器的准确度会达到很高的水准。接下来我们再训练生成器使其骗过判别器,然后生成器的效果会越来越强,直到最后判别器的准确率趋近于50%,也就是随机猜对的几率。
VAE我们讲过了,本质上也不算生成模型,他是按照加噪后的图像进行去噪得到一个新的输出。
流模型和VAE类似,不过是根据我们给出的前向flow得到latent variable ,然后逆运算inverse
得到
,看起来很美好,很简单,只需要得到
就能算出
了,关键在于这个
不好得到,整个逆转过程可能复杂的多。
最后也就是我们讲过的Diffusion model,本质上是一个马尔科夫链,先前向加噪得到最后的t时刻,再逆向去噪训练得到
优缺点分析
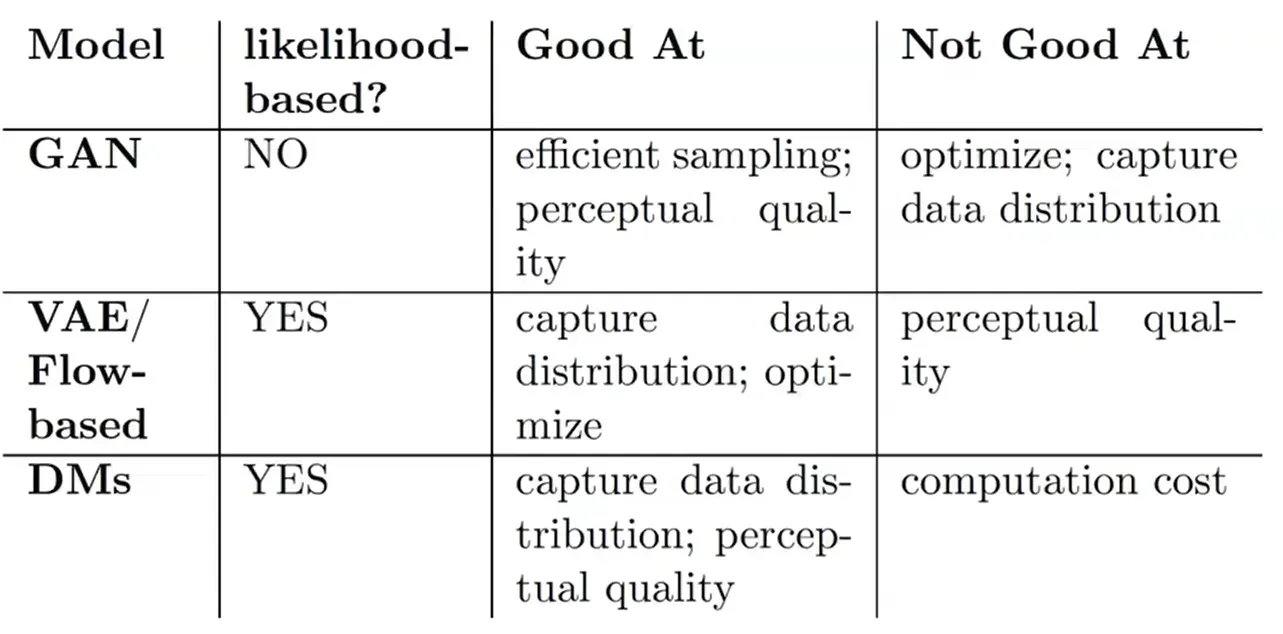
如果换成其他描述的话:
捕获完全的数据分布——就是指能生成一些未观察到的样本,例如一些荒谬的照片,例如GAN不能生成一张狗遛人的照片,因为它没见过,但是DM就可以。
感知质量——是否能生成一些准确的,看起来具有真实性,富含细节的图像。
优化——是否能稳定训练,是否便于优化。
Text2Image的历史
现在我们能够根据文字来生成图像,实际上也是有一个历史过程的,例如2015的Automated Image Captioning实现了让NN使用一些较为丰富词汇来描述一张图像(image2text),例如人遛狗,它不是给出“人,狗”这样简单的词汇组合,而是“一个人在海滩上遛狗”这样完整的表述。
而在2016的Images from Captions中,NN甚至实现了text2image,例如美国的校车只有黄色的,但是如果给出“蓝色的校车”。image真的生成了“蓝色的校车”(虽然很模糊,但确实做到了),其伟大之处在于现实中根本没有“蓝色的校车”,因此也不会存在于数据集,但是NN生成了这个结果。

2022的开年之作DALL·E-2实现了一些更完善的功能,例如更好的效果,更准确的语义理解,此外还加上了一个抠图功能。这个模型让我们在某种程度上了解了“AI是怎么理解我们所说的”。
最后就是Latent Diffusion Model,这个模型近几年是非常火的,其原因不在于效果好,而在于开源(万恶的私有制)。使得许多AI社区用户可以训练,构建自己的Text2Image。
直至目前最火热的也就三个模型:DALL·E-2,midjourney,DM,其中DM在二刺螈涩涩领域大放异彩;midjourney的效果最好因此用来生成恶搞川普的图像,但并无论文。DALL·E-2没有开源代码,不过有人根据其论文作出了山寨版的模型。看来大家都有光明的未来。😅
Latent Diffusion Model
结构
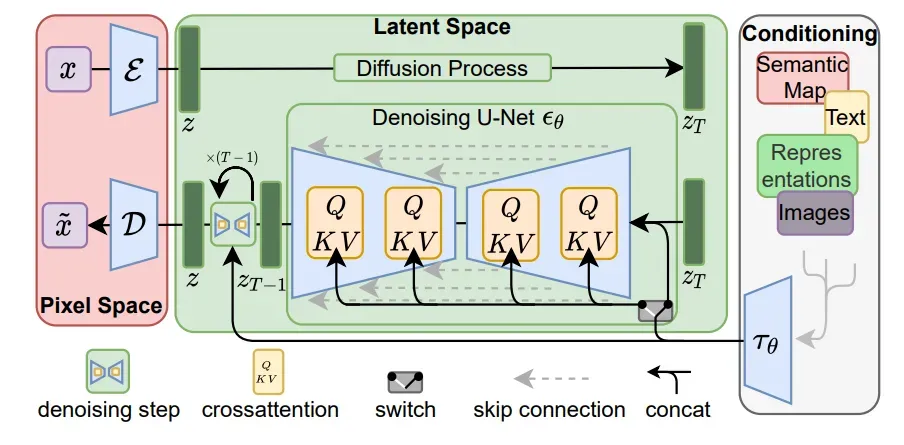
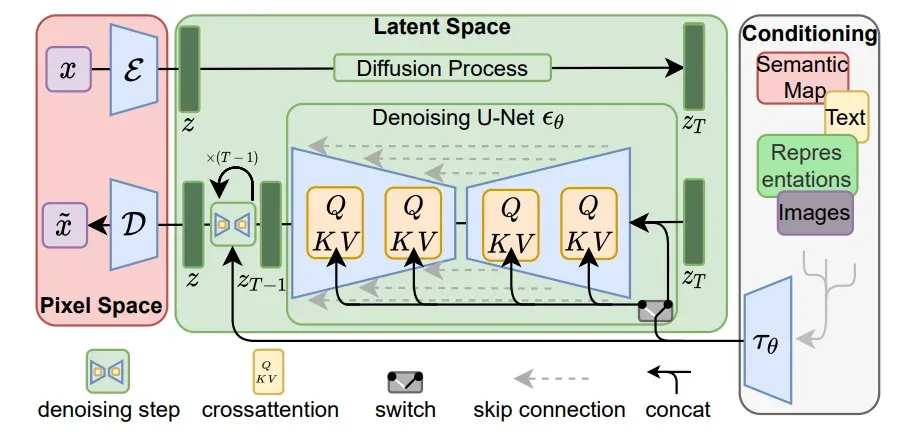
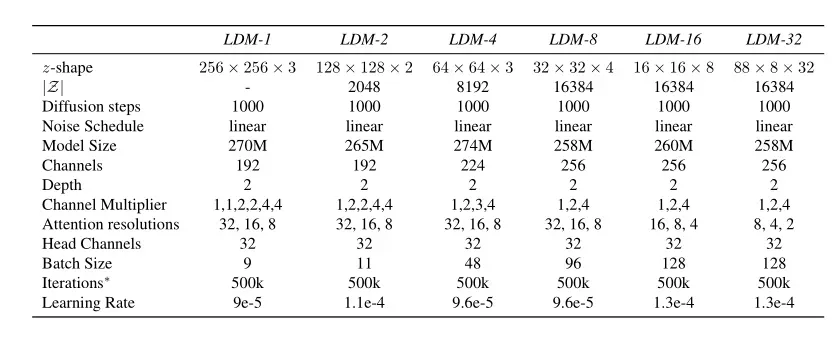
什么是DM请看这篇文章:Probabilistic Diffusion Model概率扩散模型,下面我们给出LMDs的结构图:
Costly Training :Unet如果有800M参数的话,模型可能要花费数百个GPU日来训练,并且倾向于在建模那些难以察觉的细节上花费过多的容量,这是没必要的。
Costly Evaluation:成本上来看即使真的训练完了,那么花这么多时间和内存来实现这样的结构,并且还要在每一步denosing加上这个Unet层,成本实在太高了。
我们总不能为了训练模型花个一两年时间来实现吧?
有两种优化方法:第一种就是类似DDIM的权重方法,给loss函数加上一个权重系数,不过没有几个数量级的缩减的话,cost依旧是expensive的
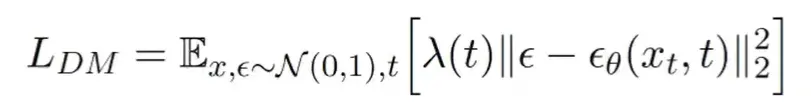
两阶段图像合成
Latent Diffusion model在上一种方法上进行了改进,也就是将像素空间上的图像处理搬到了latent space上,这样我们就能重建压缩数据,摆脱一些无用的特征转而关注那些重要的特征,大大减少了我们的训练负担。一个好处就是less costly:我们能更快采样,更高效地训练。另一个好处就是More Flexibility更灵活了,在latent space上我们添加condition或者signal都会更加方便。LDMs由于其卷积backbone,可以更方便地扩展到更高维度的潜空间。因此,我们可以自由地选择压缩水平,在学习一个强大的第一阶段之间进行最佳调整,而不把太多的感知压缩留给生成性扩散模型,同时保证高保真重建。
组件
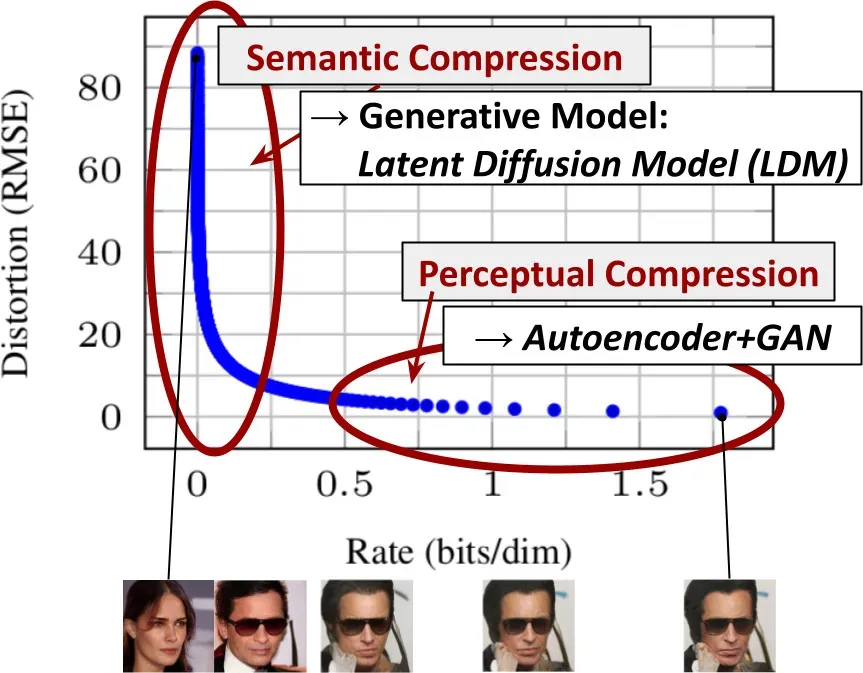
为了降低训练扩散模型对高分辨率图像合成的计算要求(例如上述的像素空间计算导致的Costly Training,Costly Evaluation的问题)我们建议通过引入明确的压缩性学习和生成性学习阶段的分离来规避这一缺点(如上图)。为了实现这一点,论文利用了一个自动编码模型,该模型学习了一个在感知上与图像空间相当的空间,但大大降低了计算的复杂性。
这种方法有几个优点:
(i)通过离开高维图像空间,我们得到的DM在计算上更有效率,因为采样是在低维空间进行的。
(ii) 我们利用了从UNet架构中继承下来的DMs的归纳偏置(inductive bias,这是一种神经网络的归纳性偏好,例如一些相似的结果神经网络可以应该选择它偏好的那一类,使得其具有泛化性),这使得它们对具有空间结构的数据特别有效,因此减轻了以前的方法要求的激进的、降低质量的压缩水平。
(iii) 最后,我们获得了通用的压缩模型,其潜在空间可用于训练多个生成模型,也可用于其他下游应用,如单幅图像的CLIP引导合成。
整个LDMs可以分为三个主要组件,意味着我们可以分离地来训练这三部分:
1.Autoencoder,一个VAE的自编码器,用于处理感知图像压缩,也就是使用VAE将pixal sapce 转换到latent space。(左边红色框框部分):
其包含了一个编码器和一个解码器
,
的作用是将RGB图像
转化为隐表示(latent representation)
,其中h代表行,w代表列,c为常数,随后我们将解码用
来重建
应用一些正则化项(例如自适应KL惩罚系数KL-penalty会趋向正态分布),可以避免高方差
2.Denoiser:上图绿色部分,也就是LDM的主体部分,其中包含了 time-conditional attention UNet
3.Conditioning Encoder:条件编码器,上图白色部分,一个可以生成tokens序列的编码器
(can be arbitrary encoder that produces a sequence of tokens),所谓的sequence of tokens就是用于描述自然语言的一个tokens序列,一个句子就能被理解为一个tokens序列。
现在让我们详细讲解这三个部分。
Autoencoder——感知性图像压缩
感知压缩模型包括一个由感知损失和patch-based的对抗性目标组合训练的自动编码器。这确保了重建是通过(执行)局部真实性被限制在图像流形(image manifold)上,避免了仅仅依靠像素空间损失(如L1 Loss或L2 Loss,即平均绝对值误差和均方误差,或者说1-范式和2-范式)
而引入的模糊性。
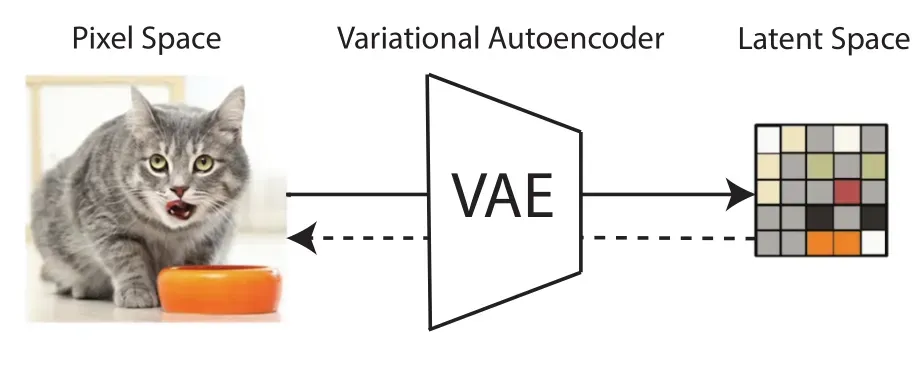
我们用编码器将RGB图像
转化为隐表示(latent representation)
,其中h代表行,w代表列,c为常数,随后我们将解码用解码器D来重建
,得到
。重要的是,编码器对图像进行下采样,系数
,一般下采样系数为
为了避免高方差的潜在空间,论文实验了两种不同的正则化,第一种正则化变体,KL-reg,引入轻微的KL惩罚项,在一开始会得到一个标准的学习速率,非常接近变分自编码器的效果。而VQ-reg,解码器使用的是一个向量量化层。这个模型可以被称为VQGAN,但他的量化层被解码器所接收。因为我们后面的DM模型是被设计成学习隐空间,基于双维度的,我们可以通过相对温柔的压缩率,取得较好的重建效果。
隐扩散模型
我们说DM是一个概率模型,旨在通过逐步去噪正态分布变量来学习数据分布,这相当于学习长度为T的固定马尔科夫链的反向过程。这些模型可以被解释为同等权重的去噪自动编码器
,它们被训练来预测其输入
的去噪变体,相应的loss函数可以简化为:
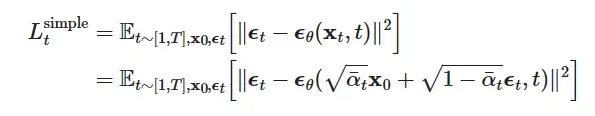
通过和
组成的自编码器的预训练的感知压缩模型,我们获得了一个有效的低维的latent space,其中原空间高频的、一些不易察觉的细节被抽象掉了。与高维像素空间相比,这个隐空间更适合基于似然的生成模型,因为它们现在可以:
(i)专注于数据的重要语义位
(ii)在一个低维的、计算上更有效的空间中进行训练。
与以前的工作不同的是,在这个高度压缩的离散隐空间中,依赖于attention-based transformer models(基于attention的transformer模型),我们可以利用我们的模型提供的图像特定的归纳偏置。这包括主要从二维卷积层建立底层UNet的能力,以及使用重新加权的约束将目标进一步集中在感知上最相关的位上,现在读作:
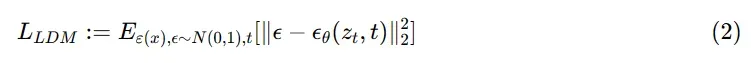
最后获得的去噪结果{也就是
}再经过解码器
就可以回归到图像空间。
条件机制
与其他类型的生成模型类似,扩散模型原则上能够对形式的条件分布进行建模(也就是原来去噪过程的p(z)我们附加上了条件y)。这可以用条件去噪自动编码器
来实现,并为通过输入y控制合成过程铺垫好前提条件,如文本、语义图或其他图像到图像的翻译任务。
我们通过用交叉注意力机制增强其底层UNet主干,将DM变成更灵活的条件图像生成器,该机制对学习各种输入模态的基于注意力的模型很有效。为了预处理来自各种模态(如语言提示,语义图,表达,图片等)的,论文引入了一个特定领域的编码器
,它将
投射到一个中间表示
(d的下标是
不是r)。然后通过交叉注意力层将其映射到UNet的中间层,实现:
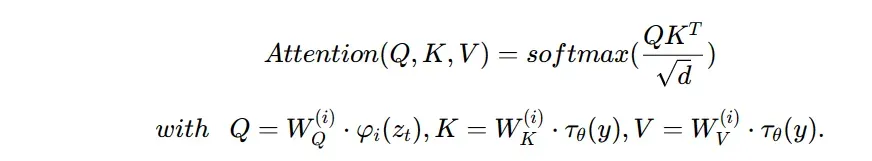
LDMs提出用交叉注意机制来实现UNet的骨干。上面的Q、 K,V分别是
、
和
的投影,其中
是表示实现
的U-Net的(扁平化)中间表示。而
是可学习的投影矩阵,视觉描述见下图:
基于图像条件组,我们再通过条件LDM学习:
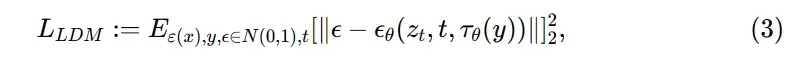
实现细节
图像引导机制
扩散模型的一个耐人寻味的特点是,无条件的模型可以在测试时进行调节。特别是,[15](原论文的引用)提出了一种算法,用一个分类器引导在ImageNet数据集上训练的无条件和有条件模型,该分类器在扩散过程的每个
上训练。我们直接在这个公式的基础上,引入了post-hoc图像引导。
对于具有固定方差的epsilon参数化模型,如[15]中介绍的指导算法为:
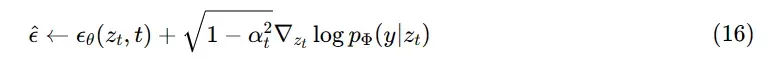
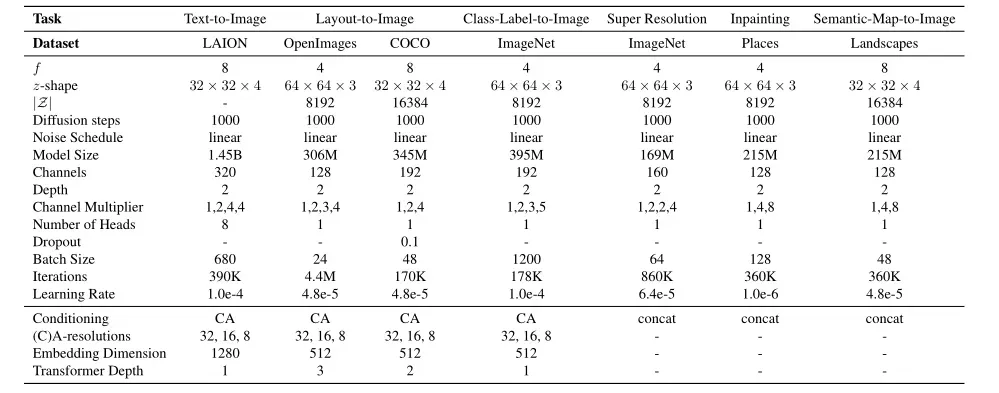
到目前为止,这种情况只被应用于单类分类模型。我们通过给定一个目标图像y把引导分布重写为一个通用的图像到图像的翻译任务,其中T可以是任何可微变换,用于现成的图像到图像的转换任务,如 T 可以是identity的下采样操作或其他类似的。
作为一个例子,我们可以假设一个具有固定方差的高斯引导,从而
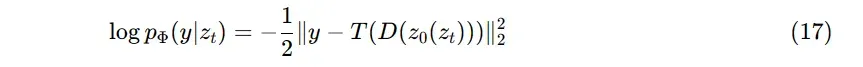

图14展示了这个公式如何作为在256×256的图像上训练的无条件模型的上采样机制,其中256×256大小的无条件样本指导了右侧512×512图像的卷积合成,此处T是一个2 x bicubic的下采样。根据这一动机,我们还实验了感知相似性的引导,并用LPIPS[106]指标取代L2 objective,见第4.4节。
条件性LDM的 的实现
的实现
对于文本到图像和布局(layout)到图像(原文第4.3.1节)的合成实验,我们将条件器实现为一个无掩码的转化器transformer,它处理输入y的标记化版本并产生一个输出
(:=是定义为),其中
。更具体地说,转化器transformer是由N个转化器块transformer blocks实现的,这些转化器块由全局自我注意层global self-attention layers、层归一化layer-normalization和position-wise的多层感知机MLPs(逐位置MLPs)组成,如下所示(adapted from x-transformers):
(上述的这些都是attention机制里的内容)

Token Embeddings是将输入的单词转化为向量表示,
Positional Embeddings是为了保留输入序列中单词的位置信息,
Layer Normalization是为了使得模型更加稳定,
Multi-Head Self-Attention是为了让模型关注不同方面的信息,
MLP是为了将模型的输出映射到目标空间
在可用的情况下,“条件Conditioning”通过交叉注意机制被映射到UNet,如我们多次给出的LDMs的结构图所示。我们修改了 “ablated UNet”结构,用一个浅层(无掩模的)transformer取代了自我注意层,该transformer由T块组成,交替为(i)自我注意层、(ii)逐位置MLP和(iii)交叉注意层。
(在UNet中,QKV是Transformer中的概念,是指Query、Key和Value。在UNet中,QKV被用于Self-Attention模块中,其中Query、Key和Value都是从同一个输入中计算得到的)
请注意,如果没有(ii)和(iii),这种结构就相当于 “ablated UNet”。
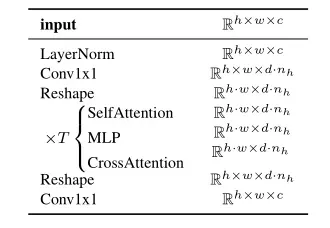
虽然可以通过额外调节time-step 来增加
的表示能力,但我们不追求这种选择,因为它降低了推断速度。我们将对这一修改进行更详细的分析,留待以后的工作。
对于文本到图像模型,我们依赖于公开可用的tokenizer[99]。布局到图像模型将边框的空间位置离散化,并将每个框编码为元组,其中l表示(离散的)左上角位置,b表示右下角位置。类信息包含在c中。

自动编码器模型的细节
我们以对抗性的方式训练所有的自动编码器模型,例如一个patch-based(翻译为块拼接?)的判别器被优化为一个用于区分原始图像和重建的
。为了避免任意缩放的潜在空间,我们通过引入正则化损失项
将latent z正则化为零中心,并获得小方差。
论文研究了两种不同的正则化方法:(i)和标准正态分布
之间的低加权Kullback-Leibler项作为一个标准变异自动编码器(ii)通过学习|Z|个不同典范的编码本,用矢量量化层正则化潜在空间。
为了获得高保真重建,我们在这两种情况下都只使用非常小的正则化,也就是说,我们要么将KL项的权重提高到 ,要么选择一个高编码本维度 |Z|。
(编码本大概就是一种压缩算法,用于得到每个像素的时间序列模型)
训练AE(ε,D)的公式:
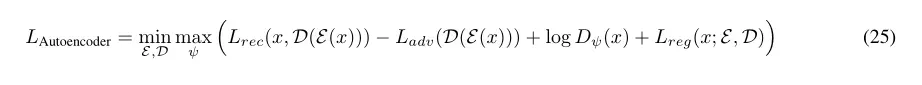
论文之外
如果只是解读论文的内容,那么到上面就结束了,论文内还有一些对于其他内容的扩充,感兴趣的可以去看看,主体部分是讲完了。
但是关于一些实现细节:例如U-net层,例如一些生成策略…我们还需要进行了解,特别是transformer&Attention的一些机制。
所以我决定先写这前半篇,简单地对论文进行一些解读,下一章将是对transformer&Attention的学习,之后再补齐后半篇来谈谈一些实现细节
文章出处登录后可见!