遗传算法Genetic Algorithm
参考视频:https://www.bilibili.com/video/BV14a411C7s8
文章原文: https://gitee.com/fakerlove/machine-learning
属于智能优化算法
1. 简介
1.1 简介
遗传算法(Genetic Algorithm,GA)最早是由美国的 John holland于20世纪70年代提出,该算法是根据大自然中生物体进化规律而设计提出的, 是一种随机全局搜索优化方法。
它模拟了自然选择和遗传中发生的复制、交叉(crossover)和变异(mutation)等现象,从任一初始种群(Population)出发,通过随机选择、交叉和变异操作,产生一群更适合环境的个体,使群体进化到搜索空间中越来越好的区域,这样一代一代不断繁衍进化,最后收敛到一群最适应环境的个体(Individual),从而求得问题的优质解。
1.2 相关概念介绍

由于遗传算法是由进化论和遗传学机理而产生的搜索算法,所以在这个算法中会用到一些生物遗传学知识,下面是我们将会用一些术语:
-
染色体(Chromosome):染色体又可称为基因型个体(individuals),一定数量的个体组成了群体(population),群体中个体的数量叫做群体大小(population size)。
-
位串(Bit String):个体的表示形式。对应于遗传学中的染色体。
-
基因(Gene):基因是染色体中的元素,用于表示个体的特征。例如有一个串(即染色体)S=1011,则其中的1,0,1,1这4个元素分别称为基因。
-
特征值( Feature):在用串表示整数时,基因的特征值与二进制数的权一致;例如在串 S=1011 中,基因位置3中的1,它的基因特征值为2;基因位置1中的1,它的基因特征值为8。
-
基因型(Genotype):或称遗传型,是指基因组定义遗传特征和表现。对于于GA中的位串。
-
表现型(Phenotype):生物体的基因型在特定环境下的表现特征。对应于GA中的位串解码后的参数。
-
进化(evolution):种群逐渐适应生存环境,品质不断得到改良。生物的进化是以种群的形式进行的。
1.2.1 选择(复制)
选择(selection):以
一定的概率从种群中选择若干个个体。一般,选择过程是一种基于适应度的优胜劣汰的过程。另一种说法复制(reproduction):细胞分裂时,遗传物质DNA通过复制而转移到新产生的细胞中,新细胞就继承了旧细胞的基因。
在自然界中,一个种群中并不是所有个体都能“有幸地”成为父母然后顺利“传宗接代”的,足够强大的个体会有更高的概率生成下一代。因此,选择其实也是存在概率的,选择概率由该个体的适应度来决定。
有各种各样的选择方法
- 将个体适应度大小映射为概率进行复制:
适应度高的个体有更大概率复制,且复制的份数越多-轮盘赌法。 - 对适应度高的前N/4的个体进行复制,然后用这些个体把后N/4个体替换掉-
精英产生精英。 - 一定是将当前个体的复制体将下一个个体替换掉吗?随机可以吗?是的!
- —定只能把“坏解”替换掉吗?把随机某个适应度高的解替换掉呢?YES!
1) 轮盘赌选择法
(roulette wheel selection)
出发点是适应度值越好的个体被选择的概率越大。
如下图所示,可以在选择时生成一个[0,1]区间内的随机数,若该随机数小于或等于个体的累积概率(累计概率就是个体列表该个体前面的所有个体概率之和)且大于个体1的累积概率,选择个体进入子代种群。
2) 随机遍历抽样法
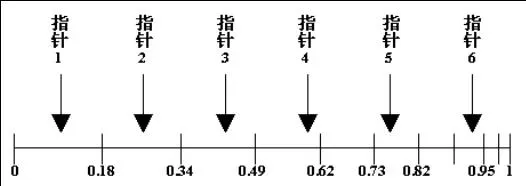
(stochastic universal sampling)
像轮盘赌一样计算选择概率,只是在随机遍历选择法中等距离的选择体,设npoint为需要选择的个体数目,等距离的选择个体,选择指针的距离是1/npoint,第一个指针的位置由[0,1/npoint]的均匀随机数决定。
3) 锦标赛选择法
(tournament selection)
锦标赛方法选择策略每次从种群中取出一定数量个体(成为竞赛规模),然后选择其中最好的一个进入子代种群。重复该操作,直到新的种群规模达到原来的种群规模。
4) 比例选择
按比例的适应度选择(proportional fitness assignment):完全由适应度大小来决定选择概率:
某个个体,其适应度为
,则其被选中的概率
为:
如,在求解最大化问题时,可以直接用适应度/总适应度来计算个体的选择概率,然后直接通过概率对个体进行选择。如果是求解最小化问题,那么就要对适应度函数进行转换,转化为最大化问题。
5) 排序选择
按排序的适应度选择(Rank-based fitness assignment):选择过程考虑了个体在种群中的排序位置,意思是如果按上面的三种例子所示的计算方法得到的适应度虽然值很低,但是你在种群中排前五,证明这个个体还是很好的。
1.2.2 交叉
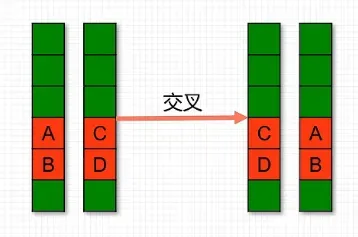
交叉(crossover):两个染色体的某一相同位置处DNA被切断,前后两串分别交叉组合形成两个新的染色体。也称基因重组或杂交;

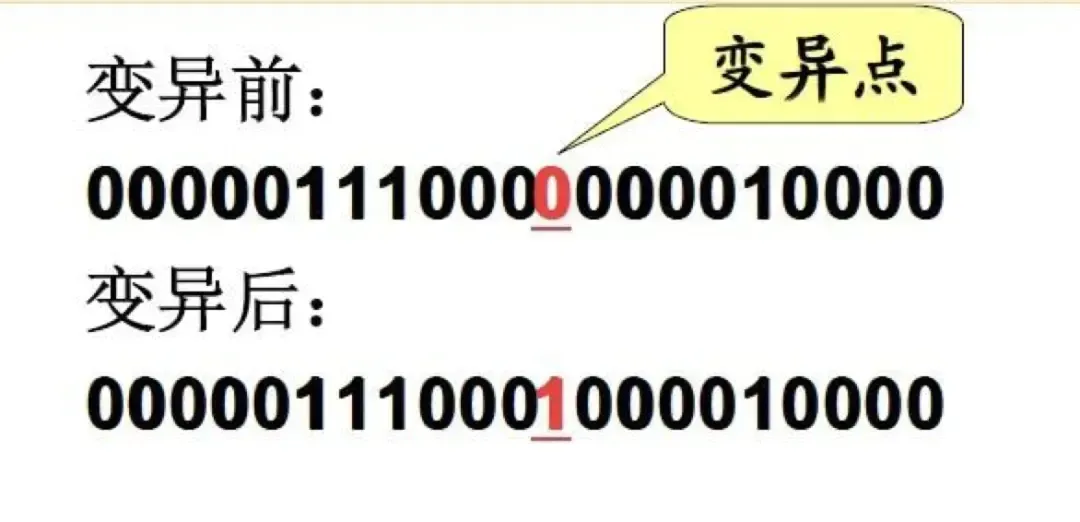
1.2.3 变异
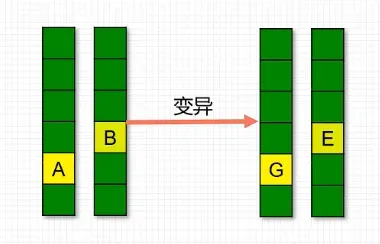
变异(mutation):复制时可能(很小的概率)产生某些复制差错,变异产生新的染色体,表现出新的性状。
变异也有很多种策略
- 每个个体都进行变异
- 只对适应度低的后
的,或者后
个个体变异,YES
- 必须都变异吗?按适应度大小映射为概率变异?YES!
- 一定是只有一个位点变异?多个位点呢?YES!
1.2.4 适应度
**适应度(Fitness):**各个个体对环境的适应程度叫做适应度(fitness)。为了体现染色体的适应能力,引入了对问题中的每一个染色体都能进行度量的函数,叫适应度函数。这个函数通常会被用来计算个体在群体中被使用的概率。
如果对于一个求最大值的函数来讲,求的值越大,适应度越大。
如果对于一个求最小值的函数来讲,求的值越小,适应度越大。
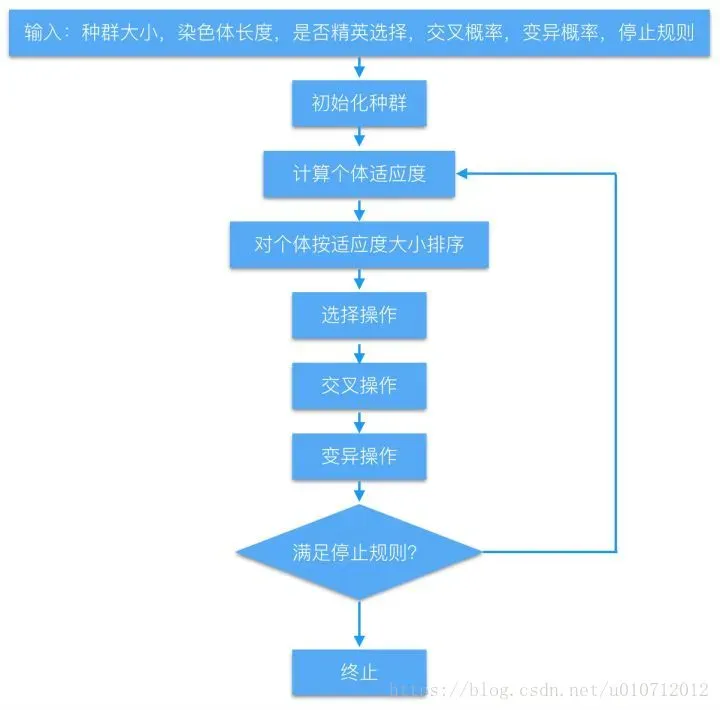
2. 算法
1.编码-》2. 初始化种群-》3.计算个体适应度-》4.复制,交叉,变异等操作-》5.是否满足规则-》6.解码
其中个体适应度,复制,交叉,变异都在上面相关概念介绍过了。现在重点内容是编码和解码。得学习一下啥叫解码和编码
2.1 流程
1) 编码
- 将问题的候选解用染色体表示,实现解空间向编码空间的映射过程。遗传算法不直接处理解空间的决策变量,而是将其转换成由基因按一定结构组成的染色体。
- 利用遗传算法求解问题时,首先要确定问题的目标函数和变量,然后
对变量进行编码,这样做主要是因为在遗传算法中,问题的解是用数字串来表示的,而且遗传算子也是直接对串进行操作的。- 编码方式有很多,如
二进制编码、实数向量编码、整数排列编码、通用数据结构编码等等。本文将采用
二进制编码的方式,将十进制的变量转换成二进制,用0和1组成的数字串模拟染色体,可以很方便地实现基因交叉、变异等操作。
下面讲一下二进制编码过程
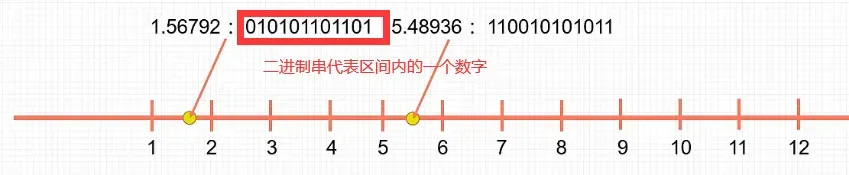
二进制编码:用一个二进制串表示这个十进制数值
- 给定数值解的区间范围[1,10]
- 给定精度:1e-5,两个数值解的间隔
- 进行编码,给
每个数值分配一个独一无二的二进制串
啥意思呢??人话就是,把一个数学问题抽象成一个数字
一段区间上的数是无数个的,所以我们不能都表示出来,所以得选择一些数字,使用二进制的串来代表这些数。
一个长度为n的串,你呢小时多少个数呢??:
区间范围为[1,10],长度为2的串提供的精度为多少?对应的精度为
如果想达到
的精度,对于区间长度为10,串的长度
应该满足
。
当n=20时,串提供的精度约为0.00000954
这样子,就实现了编码,每个数字都对应了一串二进制数
2) 种群初始化
产生代表问题可能潜在解集的一个初始群体(编码集合)。种群规模设定主要有以下方面的考虑:从群体多样性方面考虑,群体越大越好,避免陷入局部最优;从计算效率方面考虑,群体规模越大将导致计算量的增加。应该根据实际问题确定种群的规模。产生初始化种群的方法通常有两种:一是完全随机的方法产生;二是根据先验知识设定一组必须满足的条件,然后根据这些条件生成初始样本。
3) 计算个体适应度
利用适应度函数计算各个个体的适应度大小。适应度函数(Fitness Function)的选取直接影响到遗传算法的收敛速度以及能否找到最优解,因为在进化搜索中基本不利用外部信息,仅以适应度函数为依据,利用种群每个个体的适应程度来指导搜索。
个体适应度计算函数
单值、连续、非负、最大化、合理、一致性、计算量尽可能小、通用新尽可能强等。
下面例子都是针对但目标优化函数,并且设计都是越大证明个体越好
对于求最大值的
取
对于
取
4) 进化计算
通过选择、交叉、变异,产生出代表新的解集的群体W。选择(selection):根据个体适应度大小,按照优胜劣汰的原则,淘汰不合理的个体;交叉(crossover):编码的交叉重组,类似于染色体的交叉重组;变异(mutation):编码按小概率扰动产生的变化,类似于基因突变。
5) 解码
末代种群中的最优个体经过解码实现从编码空间向解空间的映射,可以作为问题的近似最优解。这是整个遗传算法的最后一步,经过若干次的进化过程,种群中适应度最高的个体代表问题的最优解,但这个最优解还是一个由0和1组成的数字串,要将它转换成十进制才能供我们理解和使用。
之前我们完成了编码,现在我们需要对编码信息,进行解码
二进制串的索引:就是在问当前串是第几个串,可以使用二进制转十进制得到的。
以[1,0]为例,其十进制转换结果为
对应的数值为
,
其中
就是
左端点数值,就是
十进制转换结果,就是
每一段的长度

一般的,区间范围为,区间长度为
,即
,串长为
,当前串对应十进制为
,则该串对应的
实值解为
书上的公式比较复杂。和上面的思想差不多
其中,为某个个体的第
段,每段段长都为
,每个
都是0或者1,
和
是第段分量
的定义域的两个端点.
2.2 优缺点
优点:
- 不盲目穷举, 是启发式搜索
- 与问题的领域无关,可快速切换
- 可并行计算一组种群
缺点:
- 计算量大, 不适合纬度高的问题
- 算法稳定性差
3. 代码
3.1 python
题目
假设有一个旅行商人要拜访n个城市,他必须选择所要走的路径,路径的限制是每个城市只能拜访一次,而且最后要回到原来出发的城市。路径的选择目标是要求得的路径路程为所有路径之中的最小值。
代码如下
# -*- encoding: utf8 -*-
import random
import math
import matplotlib.pyplot as plt
class GA:
def __init__(self, scale, num, max_gen, pc, elite):
# 种群规模
self.scale = scale
# 染色体数量(城市数量)
self.num = num
# 运行代数
self.max_gen = max_gen
# 交叉率
self.pc = pc
# 每代多少胜出者
self.elite = elite
def crossover(self, tour1, tour2, data):
# 交叉
c1 = random.randint(0, len(tour1['tour']) - 1)
c2 = random.randint(0, len(tour1['tour']) - 1)
while c1 == c2:
c2 = random.randint(0, len(tour1['tour']) - 1)
if c1 > c2:
c1, c2 = c2, c1
tour_part = tour1['tour'][c1:c2]
new_tour = []
index = 0
for i in range(len(tour2['tour'])):
if index == c1:
for item in tour_part:
new_tour.append(item)
if tour2['tour'][i] not in tour_part:
new_tour.append(tour2['tour'][i])
index += 1
return self.get_tour_detail(new_tour, data)
def mutate(self, tour, data):
# 变异
c1 = random.randint(0, len(tour['tour']) - 1)
c2 = random.randint(0, len(tour['tour']) - 1)
while c1 == c2:
c2 = random.randint(0, len(tour['tour']) - 1)
new_tour = []
for i in range(len(tour['tour'])):
if i == c1:
new_tour.append(tour['tour'][c2])
elif i == c2:
new_tour.append(tour['tour'][c1])
else:
new_tour.append(tour['tour'][i])
return self.get_tour_detail(new_tour, data)
def sort(self, tours):
# 排序
tours_sort = sorted(tours, key=lambda x: x['score'], reverse=True)
return tours_sort
def get_distance(self, c1, c2):
# 获取距离
xd = abs(c1['x'] - c2['x'])
yd = abs(c1['y'] - c2['y'])
distance = math.sqrt(xd * xd + yd * yd)
return distance
def get_score(self, distance):
# 适应性函数 距离越小适应值越大
return 1 / (distance + 1)
def get_tour(self, data):
# 随机获得一条路径
tour = []
for key, value in data.items():
tour.append(key)
random.shuffle(tour)
return self.get_tour_detail(tour, data)
def get_tour_detail(self, tour, data):
tmp = None
distance = 0
for item in tour:
if tmp is not None:
distance_tmp = self.get_distance(data[tmp], data[item])
distance += distance_tmp
tmp = item
return {'tour': tour, 'distance': distance, 'score': self.get_score(distance)}
def initialise(self, data):
# 初始种群
tours = []
for i in range(self.scale):
tours.append(self.get_tour(data))
return tours
def get_fittest(self, tours):
# 获取当前种群中最优个体
tmp = None
for item in tours:
if tmp is None or item['score'] > tmp['score']:
tmp = item
return tmp
def run(self, data):
# 随机初始化种群 。初始化的数值为 50
# data 为{1: {'x': 3, 'y': 8}, 2: {'x': 89, 'y': 37}, 3: {'x': 39, 'y': 71}}
# 表示城市的地点为位置
pop = self.initialise(data)
# print(pop)
# pop 为50组 初始种群的解
old_fittest = self.get_fittest(pop)
topelite = int(self.scale * self.elite)
same_num = 0
max_same_num = 30
max_score = 0
# 开始迭代
for i in range(self.max_gen):
# 对每个
ranked = self.sort(pop)
pop = ranked[0:topelite]
fittest = self.get_fittest(pop)
# 如果得到的最优解,比之前记录的最优解高。则进行更新
if fittest['score'] > max_score:
same_num = 0
max_score = fittest['score']
else:
same_num += 1
# 最大分数保持n次一直没有变化则退出
if same_num > max_same_num:
break
while len(pop) < self.scale:
if random.random() < self.pc:
c1 = random.randint(0, topelite)
c2 = random.randint(0, topelite)
while c1 == c2:
c2 = random.randint(0, topelite)
tour = self.crossover(ranked[c1], ranked[c2], data)
else:
c = random.randint(0, topelite - 1)
tour = self.mutate(ranked[c], data)
pop.append(tour)
print('total gen:', i)
print('before fittest:')
print(old_fittest)
print('after fittest:')
new_fittest = self.get_fittest(pop)
print(new_fittest)
return new_fittest
def init_data(num):
data = {}
def get_random_point():
# 随机生成坐标
return {
'x': random.randint(1, 99),
'y': random.randint(1, 99)
}
for i in range(num):
data[i + 1] = get_random_point()
return data
def show(citys, tour):
# 绘图
plt.bar(x=0, height=100, width=100, color=(0, 0, 0, 0), edgecolor=(0, 0, 0, 0))
plt.title(u'tsp')
plt.xlabel('total distance: %s m' % tour['distance'])
x = []
y = []
i = 0
for item in tour['tour']:
city = citys[item]
x.append(city['x'])
y.append(city['y'])
i += 1
if i == 1:
plt.plot(city['x'], city['y'], 'or')
else:
plt.plot(city['x'], city['y'], 'bo')
plt.plot(x, y, 'g')
plt.xlim(0.0, 100)
plt.ylim(0.0, 100)
plt.show()
if __name__ == '__main__':
scale, num, max_gen, pc, elite = 50, 10, 1000, 0.8, 0.2
data = init_data(num)
# 随机初始化种群为50个
# 城市数量10个
# 迭代次数为 1000次
ga = GA(scale, num, max_gen, pc, elite)
new_fittest = ga.run(data)
show(data, new_fittest)
3.2 matlab
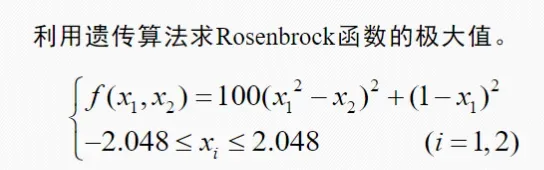
%Generic Algorithm for function f(x1,x2) optimum
clear all;
close all;
%Parameters
Size=80; %群体大小
G=100; %终止进化代数
CodeL=10;
umax=2.048;
umin=-2.048;
E=round(rand(Size,2*CodeL)); %Initial Code
%Main Program
for k=1:1:G
time(k)=k;
for s=1:1:Size
m=E(s,:);
y1=0;y2=0;
%Uncoding 解码
m1=m(1:1:CodeL);
for i=1:1:CodeL
y1=y1+m1(i)*2^(i-1);
end
x1=(umax-umin)*y1/1023+umin;
m2=m(CodeL+1:1:2*CodeL);
for i=1:1:CodeL
y2=y2+m2(i)*2^(i-1);
end
x2=(umax-umin)*y2/1023+umin;
F(s)=100*(x1^2-x2)^2+(1-x1)^2; % F(x1,x2)
end
Ji=1./F; %选个体适应度的倒数作为目标函数
%****** Step 1 : Evaluate BestJ ******
BestJ(k)=min(Ji);
fi=F; %Fitness Function
[Oderfi,Indexfi]=sort(fi); %Arranging fi small to bigger
Bestfi=Oderfi(Size); %Let Bestfi=max(fi)
BestS=E(Indexfi(Size),:); %Let BestS=E(m), m is the Indexfi belong to max(fi)
bfi(k)=Bestfi;
%****** Step 2 : Select and Reproduct Operation******
fi_sum=sum(fi);
fi_Size=(Oderfi/fi_sum)*Size;
fi_S=floor(fi_Size); %Selecting Bigger fi value
kk=1;
for i=1:1:Size
for j=1:1:fi_S(i) %Select and Reproduce
TempE(kk,:)=E(Indexfi(i),:);
kk=kk+1; %kk is used to reproduce
end
end
%************ Step 3 : Crossover Operation ************
pc=0.60;
n=ceil(20*rand);
for i=1:2:(Size-1)
temp=rand;
if pc>temp %Crossover Condition
for j=n:1:20
TempE(i,j)=E(i+1,j);
TempE(i+1,j)=E(i,j);
end
end
end
TempE(Size,:)=BestS;
E=TempE;
%************ Step 4: Mutation Operation **************
%pm=0.001;
%pm=0.001-[1:1:Size]*(0.001)/Size; %Bigger fi, smaller Pm
%pm=0.0; %No mutation
pm=0.1; %Big mutation
for i=1:1:Size
for j=1:1:2*CodeL
temp=rand;
if pm>temp %Mutation Condition
if TempE(i,j)==0
TempE(i,j)=1;
else
TempE(i,j)=0;
end
end
end
end
%Guarantee TempPop(30,:) is the code belong to the best individual(max(fi))
TempE(Size,:)=BestS;
E=TempE;
end
Max_Value=Bestfi
BestS
x1
x2
figure(1);
plot(time,BestJ);
xlabel('Times');ylabel('Best J');
figure(2);
plot(time,bfi);
xlabel('times');ylabel('Best F');
参考资料
(2条消息) 遗传算法(一) 遗传算法的基本原理_我叫辰辰啦的博客-CSDN博客_遗传算法
文章出处登录后可见!