前言
马上要找工作了,想总结下自己做过的几个小项目。
之前已经总结过了我做的第一个项目:xxx病虫害检测项目,github源码地址:HuKai97/FFSSD-ResNet。CSDN讲解地址:
- 【项目一、xxx病虫害检测项目】1、SSD原理和源码分析
- 【项目一、xxx病虫害检测项目】2、网络结构尝试改进:Resnet50、SE、CBAM、Feature Fusion
- 【项目一、xxx病虫害检测项目】3、损失函数尝试:Focal loss
第二个项目:蜂巢检测项目,github源码地址:https://github.com/HuKai97/YOLOv5-ShuffleNetv2。CSDN讲解地址:
【项目二、蜂巢检测项目】一、串讲各类经典的卷积网络:InceptionV1-V4、ResNetV1-V2、MobileNetV1-V3、ShuffleNetV1-V2、ResNeXt、Xception。
【项目二、蜂巢检测项目】二、模型改进:YOLOv5s-ShuffleNetV2。
如果对YOLOv5不熟悉的同学可以先看看我写的YOLOv5源码讲解CSDN:【YOLOV5-5.x 源码讲解】整体项目文件导航,注释版YOLOv5源码我也开源在了Github上:HuKai97/yolov5-5.x-annotations,欢迎大家star!
之前一直在学习OCR相关的东西,就想着能不能做一个车牌识别的项目出来,刚好车牌检测也好做,直接用v5就可以了。我的打算是做一个轻量级的车牌识别项目,检测网络用的是YOLOv5s,识别网络有的是LPRNet。
这一节主要介绍下怎么训练LPRNet车牌识别模型。
车牌识别项目所有讲解:
- 【项目三、车牌检测+识别项目】一、CCPD车牌数据集转为YOLOv5格式和LPRNet格式
- 【项目三、车牌检测+识别项目】二、使用YOLOV5进行车牌检测
- 【项目三、车牌检测+识别项目】三、LPRNet车牌识别网络原理和核心源码解读
- 【项目三、车牌检测+识别项目】四、使用LPRNet进行车牌识别
代码已全部上传GitHub:https://github.com/HuKai97/YOLOv5-LPRNet-Licence-Recognition
这篇博客写的我好难受,写好了,忘保存了,又重新写一遍…
一、LPRNet网络介绍
LPRNet是一个非常经典的车牌识别算法,论文是Intel于2018年发表的: LPRNet: License Plate Recognition via Deep Neural Networks,整个网络结构设计高度轻量化,只用1.5M,瞄准的就是在嵌入式设备中使用,但是识别率却毫不逊色,Intel已经在自己的嵌入式设备中应用了。
网络特点/优点:
- 不需要对字符进行预分割,是一个端到端的轻量化字符识别模型,速度快,精度还不错;这里主要是因为仿照squeezenet和inception的思想设计了一个轻量化的卷积模块。
- 仿照的还是经典的CRNN+CTC的思路,不过LPRNet首次将RNN删除了,整个网络只有CNN+CTC Loss。但是也不是说不要上下文信息,只是舍弃了BiLSTM那样的RNN提取上下文,而是在backbone的末尾使用了一个13×1的卷积模块提取序列方向(w)的上下文信息。而且在backbone外还额外使用一个全连接层进行全局上下文特征提取,提取之后再和backbone进行concat特征融合,再输入head。
- 损失使用的CTC Loss、推理应用了贪心算法,搜索取每个位置上类概率的最大值。
二、LPRNet网络结构
2.1、STN定位网络
论文中设计了一个图像预处理网络,将车牌图像进行变换(如偏移、旋转车牌图片),得到比较正的最佳车牌图片再输入CNN中。这部分有点像仿射变换(图像处理方法),不同的是这里是用了一个CNN小网络进行转换,原论文使用的是LocNet网络自动学习最佳的转换参数。LocNet模型结构如下:
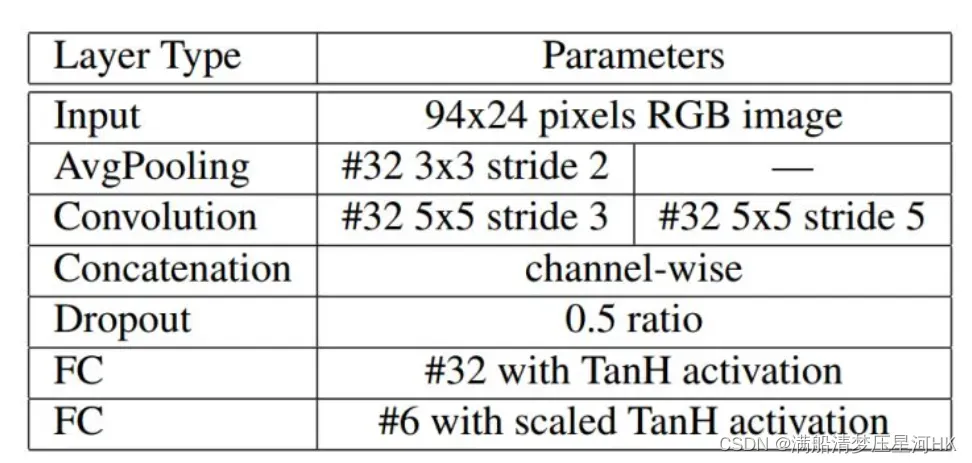
不过这里为了简便,我用YOLOv5s检测到车牌区域后,我是直接裁剪下来输入车牌识别网络的CNN当中,并没有做这一步的图像矫正模块,感兴趣可以去github搜搜看,应该是能找到的。
2.2、Backbone
作者原话:

LPRNet的backbone模块是自行设计的一个轻量化的backbone,其中自己设计的一个Small basic block其实就是一个瓶颈型的结构(有点像去掉shortcut分枝的bottleneck),下面来好好说说。
Small basic block结构如下(思路:squeezenet/bottleneck+inception):
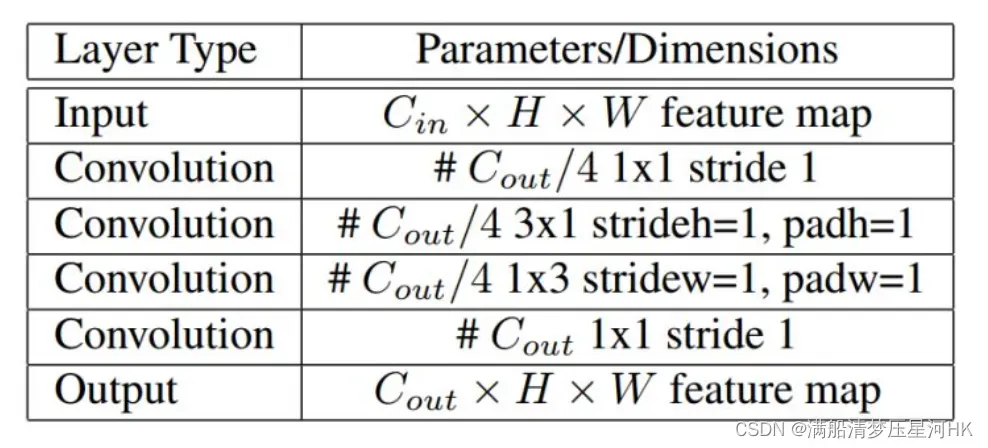
以第一个Small basic block结构为例子,先经过第一个1×1卷积进行降维,再用一个3×1和一个1×3卷积进行特征提取,最后再用1个1×1卷积进行升维,这不就是一个squeezenet中的fire module嘛,先使用1×1卷积对输入特征进行squueze,缩小channel,降低参数,再提取特征,最后再用expand对增大输出特征channel(这个和resnet中的bottleneck也很像)。而中间的3×1和1×3是用的inceptionv2的结论:不对称卷积可以代替对称矩阵,3×1+1×3产生和3×3一样的效果,参数量还更少了,而且还多了一个ReLU激活函数,增加了非线性。
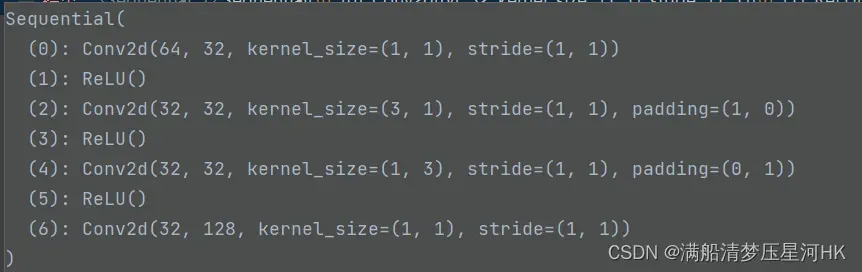
代码也比较简单,就照着顺序搭建就是了:
class small_basic_block(nn.Module):
def __init__(self, ch_in, ch_out):
super(small_basic_block, self).__init__()
self.block = nn.Sequential(
nn.Conv2d(ch_in, ch_out // 4, kernel_size=1),
nn.ReLU(),
nn.Conv2d(ch_out // 4, ch_out // 4, kernel_size=(3, 1), padding=(1, 0)),
nn.ReLU(),
nn.Conv2d(ch_out // 4, ch_out // 4, kernel_size=(1, 3), padding=(0, 1)),
nn.ReLU(),
nn.Conv2d(ch_out // 4, ch_out, kernel_size=1),
)
def forward(self, x):
return self.block(x)
不过我有个疑问:为什么backbone都使用了bn,这个模块反而不适应bn呢?有知道的小伙伴可以在评论区讨论下?
backbone的整体架构:
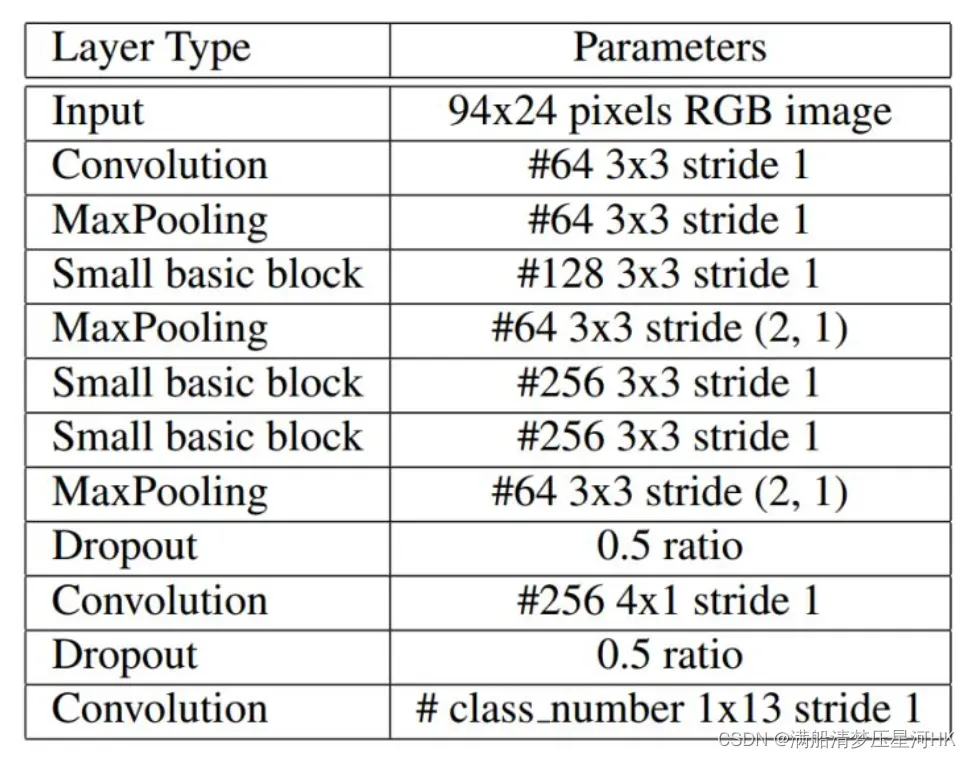
仔细数下发现只用11个,怪不得这么轻便,代码依葫芦画瓢就是了:
# __init__
self.backbone = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1), # 0 [bs,3,24,94] -> [bs,64,22,92]
nn.BatchNorm2d(num_features=64), # 1 -> [bs,64,22,92]
nn.ReLU(), # 2 -> [bs,64,22,92]
nn.MaxPool3d(kernel_size=(1, 3, 3), stride=(1, 1, 1)), # 3 -> [bs,64,20,90]
small_basic_block(ch_in=64, ch_out=128), # 4 -> [bs,128,20,90]
nn.BatchNorm2d(num_features=128), # 5 -> [bs,128,20,90]
nn.ReLU(), # 6 -> [bs,128,20,90]
nn.MaxPool3d(kernel_size=(1, 3, 3), stride=(2, 1, 2)), # 7 -> [bs,64,18,44]
small_basic_block(ch_in=64, ch_out=256), # 8 -> [bs,256,18,44]
nn.BatchNorm2d(num_features=256), # 9 -> [bs,256,18,44]
nn.ReLU(), # 10 -> [bs,256,18,44]
small_basic_block(ch_in=256, ch_out=256), # 11 -> [bs,256,18,44]
nn.BatchNorm2d(num_features=256), # 12 -> [bs,256,18,44]
nn.ReLU(), # 13 -> [bs,256,18,44]
nn.MaxPool3d(kernel_size=(1, 3, 3), stride=(4, 1, 2)), # 14 -> [bs,64,16,21]
nn.Dropout(dropout_rate), # 0.5 dropout rate # 15 -> [bs,64,16,21]
nn.Conv2d(in_channels=64, out_channels=256, kernel_size=(1, 4), stride=1), # 16 -> [bs,256,16,18]
nn.BatchNorm2d(num_features=256), # 17 -> [bs,256,16,18]
nn.ReLU(), # 18 -> [bs,256,16,18]
nn.Dropout(dropout_rate), # 0.5 dropout rate 19 -> [bs,256,16,18]
nn.Conv2d(in_channels=256, out_channels=class_num, kernel_size=(13, 1), stride=1), # class_num=68 20 -> [bs,68,4,18]
nn.BatchNorm2d(num_features=class_num), # 21 -> [bs,68,4,18]
nn.ReLU(), # 22 -> [bs,68,4,18]
)
# __forward__
for i, layer in enumerate(self.backbone.children()):
x = layer(x)
结构很简单,唯一需要注意的是:最后一层conv用的是一个13×1的卷积代替了原先的BiLSTM来结合序列方向(W方向)的上下文信息。
疑问:为什么backbone要设置两个dropout层,据我所知现在用这个已经很少了,可能那时候才2018年,用的比较多吧。现在基本都是被BN代替了,BN+Dropout联合使用的话可能发生方差偏移问题,具体原因可以自己去搜搜一下,这里不展开细说了。
2.3、全局上下文嵌入
这部分论文是使用一个全连接层提取上下文信息的,只融合了两层,而这里是使用的avg pool层,而且还在4个尺度上进行了融合:
global_context = list()
# keep_features: [bs,64,22,92] [bs,128,20,90] [bs,256,18,44] [bs,68,4,18]
for i, f in enumerate(keep_features):
if i in [0, 1]:
# [bs,64,22,92] -> [bs,64,4,18]
# [bs,128,20,90] -> [bs,128,4,18]
f = nn.AvgPool2d(kernel_size=5, stride=5)(f)
if i in [2]:
# [bs,256,18,44] -> [bs,256,4,18]
f = nn.AvgPool2d(kernel_size=(4, 10), stride=(4, 2))(f)
f_pow = torch.pow(f, 2)
f_mean = torch.mean(f_pow)
f = torch.div(f, f_mean)
global_context.append(f)
x = torch.cat(global_context, 1)
有人对这个结构提出了质疑(非官方版),发现验证时是有问题的,具体的话大家可以看下这里,这位作者也按照原论文的结构进行了一个复现,解决了上面的这个问题:LPRnet pytorch 实现 (参考官方版本)
由于我跑这个模型的时候并没有发现这个问题,所以,我用的还是原版的有问题的代码,有条件的可以试试这个博文的上这段代码,个人人为更合理一点,也和原论文结构一致,效果好像还更好,大家可以试试。
另外,如果用了我的代码跑的话,验证时bs尽量不要太小,否则会和训练结果相差很大。
2.4、head
head部分很简单,就是一个1×1卷积,控制下输出的shape:
# __init__
self.container = nn.Sequential(
nn.Conv2d(in_channels=448+self.class_num, out_channels=self.class_num, kernel_size=(1, 1), stride=(1, 1)),
# nn.BatchNorm2d(num_features=self.class_num),
# nn.ReLU(),
# nn.Conv2d(in_channels=self.class_num, out_channels=self.lpr_max_len+1, kernel_size=3, stride=2),
# nn.ReLU(),
)
# __forward__
x = self.container(x) # -> [bs, 68, 4, 18] head头
logits = torch.mean(x, dim=2) # -> [bs, 68, 18] # 68 字符类别数 18字符序列长度
return logits
三、CTC Loss
这部分在我的另一篇博文上有讲:【OCR入门】二、文本识别(CRNN+CTC)
这里简单的回顾以下
解决问题/目的:处理不定长序列对齐问题,即得到的预测序列长度和真实gt的序列是不一样长的,导致无法使用交叉熵等一些经典的loss函数。
解决办法/CTC Loss:采用动态规划的思想
现在已知模型对序列中每个位置对所有类别的概率,即得到网络输出【68,18】,这里舍去bs维度更好理解,其中68代表序列中每个位置字符为相应类别的概率,车牌字符共有68类,18代表字符序列长度;还知道这个序列对于的gt字符串,很明显这两者是不等长的。那么我们可以用动态规划算法,计算出在当前这个预测结果下,最终能得到这个gt字符串的总概率。因为肯定有很多条路可以走到最终的gt标签。这个总概率越大,说明这个模型越好。(刷题刷的多的很快可以反应过来,其中这就是一个动态规划的网格类问题)。得到这个总概率,再带入交叉熵损失函数,就得到了最终的CTC Loss
代码其实是掉包的,一行就解决了:
ctc_loss = nn.CTCLoss(blank=len(CHARS)-1, reduction='mean') # reduction: 'none' | 'mean' | 'sum'
...
# 网络输出 [bs,68,18]
# log_probs: 预测结果 [18, bs, 68] 其中18为序列长度 68为字典数
# labels: [93]
# input_lengths: tuple example: 000=18 001=18... 每个序列长度
# target_lengths: tuple example: 000=7 001=8 ... 每个gt长度
loss = ctc_loss(log_probs, labels, input_lengths=input_lengths, target_lengths=target_lengths)
四、后处理-解码
网络预测最终输出:[bs, 68, 18],其中68是字典中字符的个数也就是每个位置的分类数,18是序列的长度,对每张图片进行后处理,先用argmax找到序列中每个位置的最大概率对应的类别(贪婪搜索),得到一个长度为18的序列,再对这个序列进行去除空白(’-‘字符,表示序列的当前位置没有字符),去重重复(序列的相邻两个位置字符不能重复),得到一个最终的预测序列。
代码很简单:
def Greedy_Decode_Eval(Net, datasets, args):
# TestNet = Net.eval()
epoch_size = len(datasets) // args.test_batch_size
batch_iterator = iter(DataLoader(datasets, args.test_batch_size, shuffle=True, num_workers=args.num_workers, collate_fn=collate_fn))
Tp = 0
Tn_1 = 0
Tn_2 = 0
t1 = time.time()
for i in range(epoch_size):
# load train data
images, labels, lengths = next(batch_iterator)
start = 0
targets = []
for length in lengths:
label = labels[start:start+length]
targets.append(label)
start += length
targets = np.array([el.numpy() for el in targets])
imgs = images.numpy().copy()
if args.cuda:
images = Variable(images.cuda())
else:
images = Variable(images)
# forward
# images: [bs, 3, 24, 94]
# prebs: [bs, 68, 18]
prebs = Net(images)
# greedy decode
prebs = prebs.cpu().detach().numpy()
preb_labels = list()
for i in range(prebs.shape[0]):
preb = prebs[i, :, :] # 对每张图片 [68, 18]
preb_label = list()
for j in range(preb.shape[1]): # 18 返回序列中每个位置最大的概率对应的字符idx 其中'-'是67
preb_label.append(np.argmax(preb[:, j], axis=0))
no_repeat_blank_label = list()
pre_c = preb_label[0]
if pre_c != len(CHARS) - 1: # 记录重复字符
no_repeat_blank_label.append(pre_c)
for c in preb_label: # 去除重复字符和空白字符'-'
if (pre_c == c) or (c == len(CHARS) - 1):
if c == len(CHARS) - 1:
pre_c = c
continue
no_repeat_blank_label.append(c)
pre_c = c
preb_labels.append(no_repeat_blank_label) # 得到最终的无重复字符和无空白字符的序列
for i, label in enumerate(preb_labels): # 统计准确率
# show image and its predict label
if args.show:
show(imgs[i], label, targets[i])
if len(label) != len(targets[i]):
Tn_1 += 1 # 错误+1
continue
if (np.asarray(targets[i]) == np.asarray(label)).all():
Tp += 1 # 完全正确+1
else:
Tn_2 += 1
Acc = Tp * 1.0 / (Tp + Tn_1 + Tn_2)
print("[Info] Test Accuracy: {} [{}:{}:{}:{}]".format(Acc, Tp, Tn_1, Tn_2, (Tp+Tn_1+Tn_2)))
t2 = time.time()
print("[Info] Test Speed: {}s 1/{}]".format((t2 - t1) / len(datasets), len(datasets)))
五、其他注意的点
- 网络输入只能是 bsx3x24x94 ,对应网络输出是 bsx68x18,其中68是字典中字符总个数,18个预测序列长度;
六、总结
- 整体架构是CNN+CTC Loss,虽然去除了RNN,但是为了获得全局信息,在backbone会添加一个13×1的大卷积提取一个在序列维度h的全局信息(其实还是局部,不过卷积核接近feature map了);而且在cnn和head之间还添加了一个全连接层,用以提取全局信息。
- 网络之所以非常前量化,主要是因为backbone设计了一种超轻量的模块(Small basic block),灵感来源于SqueezeNet和Inception,先用1×1卷积进行降维,再接一个3×1和1×3卷积代替原先的3×3卷积进行特征提取,在效果差不多的情况下,不但可以降低模型参数量还能增加非线性表达。最后再接一个1×1卷积进行升维。
- 损失使用的CTC Loss、推理应用了贪心算法,搜索取每个位置上类概率的最大值。
Reference
CSDN: linux-mobaxterm-yolov5训练数据集ccpd–无数踩雷后
Github: https://github.com/ultralytics/yolov5
Github: https://github.com/sirius-ai/LPRNet_Pytorch
Gitee: https://gitee.com/reason1251326862/plate_classification
Github:https://github.com/kiloGrand/License-Plate-Recognition
知乎:LPRNet论文详解
文章出处登录后可见!