各位同学好,今天和大家分享一下目标检测算法中常用的图像数据增强方法 Mosaic。先放张图看效果。将四张图片缩放后裁剪拼接在一起,并调整检测框的坐标位置,处理位于图像边缘的检测框。文末有完整代码

1. 方法介绍
Mosaic 数据增强算法将多张图片按照一定比例组合成一张图片,使模型在更小的范围内识别目标。Mosaic 数据增强算法参考 CutMix数据增强算法。CutMix数据增强算法使用两张图片进行拼接,而 Mosaic 数据增强算法一般使用四张进行拼接,但两者的算法原理是非常相似的。
方法步骤:
(1)随机选取图片拼接基准点坐标(xc,yc),另随机选取四张图片。
(2)四张图片根据基准点,分别经过 尺寸调整 和 比例缩放 后,放置在指定尺寸的大图的左上,右上,左下,右下位置。
(3)根据每张图片的尺寸变换方式,将映射关系对应到图片标签上。
(4)依据指定的横纵坐标,对大图进行拼接。处理超过边界的检测框坐标。
方法优点:
(1)增加数据多样性,随机选取四张图像进行组合,组合得到图像个数比原图个数要多。
(2)增强模型鲁棒性,混合四张具有不同语义信息的图片,可以让模型检测超出常规语境的目标。
(3)加强批归一化层(Batch Normalization)的效果。当模型设置 BN 操作后,训练时会尽可能增大批样本总量(BatchSize),因为 BN 原理为计算每一个特征层的均值和方差,如果批样本总量越大,那么 BN 计算的均值和方差就越接近于整个数据集的均值和方差,效果越好。
(4)Mosaic 数据增强算法有利于提升小目标检测性能。Mosaic 数据增强图像由四张原始图像拼接而成,这样每张图像会有更大概率包含小目标。
2. 代码展示
2.1 加载图片及标签
我以四张图片及其标签文件为例,导入 xml.etree 库解析XML标签文件,这里我只读取检测框的左上和右下角坐标信息,我习惯使用opencv方法处理图片,当然也可以使用Image库处理。将读取的图片及其对应的坐标信息保存在同一个列表中。

代码如下:
# 主函数,获取图片路径和检测框路径
if __name__ == '__main__':
# 给出图片文件夹和检测框文件夹所在的位置
image_dir = 'D:/deeplearning/database/VOC2007/picture/'
annotation_dir = 'D:/deeplearning/database/VOC2007/annotation/'
image_list = [] # 存放每张图像和该图像对应的检测框坐标信息
# 读取4张图像及其检测框信息
for i in range(4):
image_box = [] # 存放每张图片的检测框信息
# 某张图片位置及其对应的检测框信息
image_path = image_dir + str(i+1) + '.jpg'
annotation_path = annotation_dir + str(i+1) + '.xml'
image = cv2.imread(image_path) # 读取图像
# 读取检测框信息
with open(annotation_path, 'r') as new_f:
# getroot()获取根节点
root = ET.parse(annotation_path).getroot()
# findall查询根节点下的所有直系子节点,find查询根节点下的第一个直系子节点
for obj in root.findall('object'):
obj_name = obj.find('name').text # 目标名称
bndbox = obj.find('bndbox')
left = eval(bndbox.find('xmin').text) # 左上坐标x
top = eval(bndbox.find('ymin').text) # 左上坐标y
right = eval(bndbox.find('xmax').text) # 右下坐标x
bottom = eval(bndbox.find('ymax').text) # 右下坐标y
# 保存每张图片的检测框信息
image_box.append([left, top, right, bottom]) # [[x1,y1,x2,y2],[..],[..]]
# 保存图像及其对应的检测框信息
image_list.append([image, image_box])
# 分割、缩放、拼接图片
get_random_data(image_list, input_shape=[416,416])2.2 图像分割
输入图片的尺寸是 (iw, ih) ;指定图片的尺寸是 (w, h) ,其中w=h=416;缩放后的图片的尺寸是 (nw, nh)
(1)先通过cv2.resize()将图片尺寸从(iw, ih) 变成 (w, h);再乘以缩放比例 scale,是0.6至0.8之间的一个随机数;得到压缩后的图像尺寸 (nw, nh)
(2)生成一个尺寸为 (w, h) 的画板 np.zeros((h,w,3), np.uint8),将第一张压缩后的图片放在画板的左上方,第二张放在右上方,第三张放在左下方,第四张放在右下方。
(3)h-nh 代表y轴方向上画板边界距离缩放后图片边界的距离,w-nw 代表x轴方向上画板边界距离缩放后图片边界的距离
(4)检测框中心点坐标为 (cx, cy),坐标调整比例是 nw/iw,但需要分开调整位于不同位置的四张图的检测框。
代码如下:
def get_random_data(image_list, input_shape):
h, w = input_shape # 获取图像的宽高
'''设置拼接的分隔线位置'''
min_offset_x = 0.4
min_offset_y = 0.4
scale_low = 1 - min(min_offset_x, min_offset_y) # 0.6
scale_high = scale_low + 0.2 # 0.8
image_datas = [] # 存放图像信息
box_datas = [] # 存放检测框信息
index = 0 # 当前是第几张图
#(1)图像分割
for frame_list in image_list:
frame = frame_list[0] # 取出的某一张图像
box = np.array(frame_list[1:]) # 该图像对应的检测框坐标
ih, iw = frame.shape[0:2] # 图片的宽高
cx = (box[0,:,0] + box[0,:,2]) // 2 # 检测框中心点的x坐标
cy = (box[0,:,1] + box[0,:,3]) // 2 # 检测框中心点的y坐标
# 对输入图像缩放
new_ar = w/h # 图像的宽高比
scale = np.random.uniform(scale_low, scale_high) # 缩放0.6--0.8倍
# 调整后的宽高
nh = int(scale * h) # 缩放比例乘以要求的宽高
nw = int(nh * new_ar) # 保持原始宽高比例
# 缩放图像
frame = cv2.resize(frame, (nw,nh))
# 调整中心点坐标
cx = cx * nw/iw
cy = cy * nh/ih
# 调整检测框的宽高
bw = (box[0,:,2] - box[0,:,0]) * nw/iw # 修改后的检测框的宽高
bh = (box[0,:,3] - box[0,:,1]) * nh/ih
# 创建一块[416,416]的底版
new_frame = np.zeros((h,w,3), np.uint8)
# 确定每张图的位置
if index==0: new_frame[0:nh, 0:nw] = frame # 第一张位于左上方
elif index==1: new_frame[0:nh, w-nw:w] = frame # 第二张位于右上方
elif index==2: new_frame[h-nh:h, 0:nw] = frame # 第三张位于左下方
elif index==3: new_frame[h-nh:h, w-nw:w] = frame # 第四张位于右下方
# 修正每个检测框的位置
if index==0: # 左上图像
box[0,:,0] = cx - bw // 2 # x1
box[0,:,1] = cy - bh // 2 # y1
box[0,:,2] = cx + bw // 2 # x2
box[0,:,3] = cy + bh // 2 # y2
if index==1: # 右上图像
box[0,:,0] = cx - bw // 2 + w - nw # x1
box[0,:,1] = cy - bh // 2 # y1
box[0,:,2] = cx + bw // 2 + w - nw # x2
box[0,:,3] = cy + bh // 2 # y2
if index==2: # 左下图像
box[0,:,0] = cx - bw // 2 # x1
box[0,:,1] = cy - bh // 2 + h - nh # y1
box[0,:,2] = cx + bw // 2 # x2
box[0,:,3] = cy + bh // 2 + h - nh # y2
if index==3: # 右下图像
box[0,:,2] = cx - bw // 2 + w - nw # x1
box[0,:,3] = cy - bh // 2 + h - nh # y1
box[0,:,0] = cx + bw // 2 + w - nw # x2
box[0,:,1] = cy + bh // 2 + h - nh # y2
index = index + 1 # 处理下一张
# 保存处理后的图像及对应的检测框坐标
image_datas.append(new_frame)
box_datas.append(box)
# 取出某张图片以及它对应的检测框信息, i代表图片索引
for image, boxes in zip(image_datas, box_datas):
# 复制一份原图
image_copy = image.copy()
# 遍历该张图像中的所有检测框
for box in boxes[0]:
# 获取某一个框的坐标
x1, y1, x2, y2 = box
cv2.rectangle(image_copy, (x1,y1), (x2,y2), (0,255,0), 2)
cv2.imshow('img', image_copy)
cv2.waitKey(0)
cv2.destroyAllWindows()分割后的图像如下:
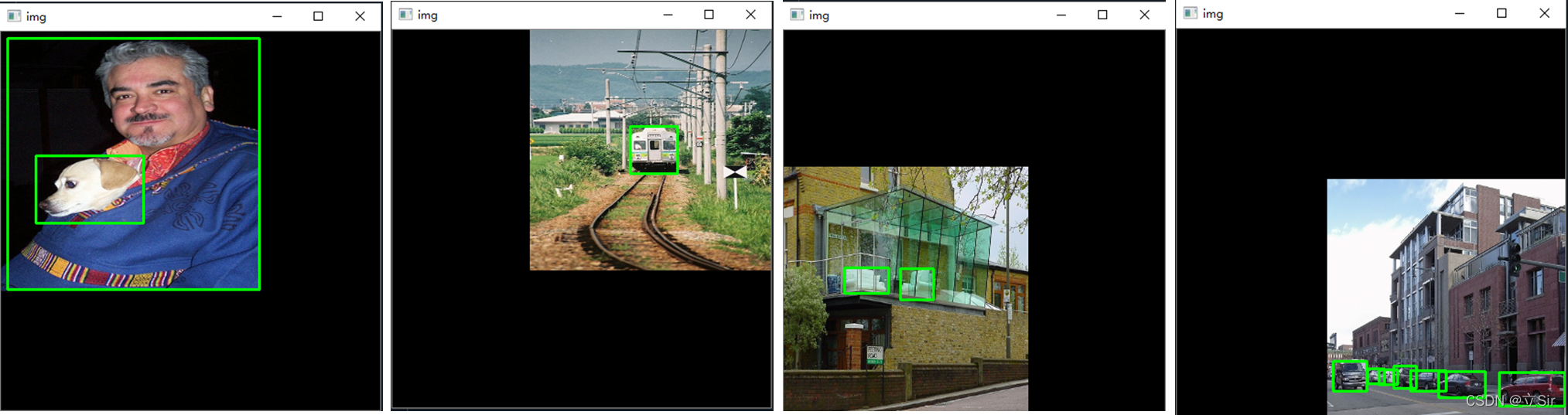
2.3 图像合并
首先设置拼接线,cutx代表x轴方向把图像分割成两块区域,cuty代表y轴方向把图片分割成两块。设置 (cutx, cuty) 代表四张图在何坐标下切割,如右上方的图只取 cutx左侧 且 cuty上侧 的区域。
创建一块新的画板new_image,大小为(416, 416),将切割后的四张图片组合在一起
#(2)将四张图像拼接在一起
# 在指定范围中选择横纵向分割线
cutx = np.random.randint(int(w*min_offset_x), int(w*(1-min_offset_x)))
cuty = np.random.randint(int(h*min_offset_y), int(h*(1-min_offset_y)))
# 创建一块[416,416]的底版用来组合四张图
new_image = np.zeros((h,w,3), np.uint8)
new_image[:cuty, :cutx, :] = image_datas[0][:cuty, :cutx, :]
new_image[:cuty, cutx:, :] = image_datas[1][:cuty, cutx:, :]
new_image[cuty:, :cutx, :] = image_datas[2][cuty:, :cutx, :]
new_image[cuty:, cutx:, :] = image_datas[3][cuty:, cutx:, :]
# 显示合并后的图像
cv2.imshow('new_img', new_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 复制一份合并后的原图
final_image_copy = new_image.copy()
# 显示有检测框并合并后的图像
for boxes in box_datas:
# 遍历该张图像中的所有检测框
for box in boxes[0]:
# 获取某一个框的坐标
x1, y1, x2, y2 = box
cv2.rectangle(final_image_copy, (x1,y1), (x2,y2), (0,255,0), 2)
cv2.imshow('new_img_bbox', final_image_copy)
cv2.waitKey(0)
cv2.destroyAllWindows()拼接后的图像如下:
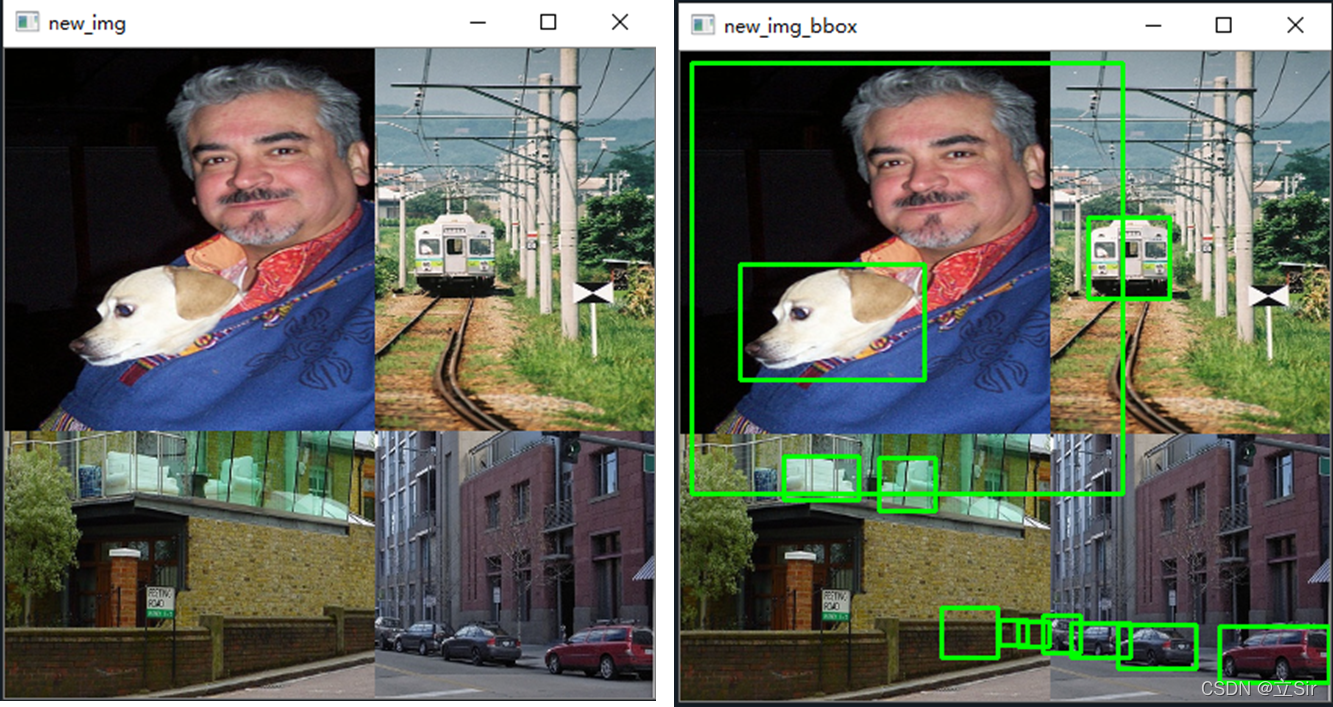
2.4 处理检测框边界
如上图,我们发现左上图的检测框伸展到了其他区域,右下图的部分检测车辆的框中没有目标。因为我们只对图片进行了拼接,而图片对应的检测框仍然是原来分割前的检测框坐标。
(1)将不在其对应图像所在区域内的检测框都剔除;如右下侧图中的检测车的框跑到左下侧图中去了。
(2)将检测框一部分在图像区域内,一部分不在图像区域内的,以该图的区域分界线(cutx, cuty)代替越界的检测框线条。如左上图人的检测框需要用边界线代替区域外的边缘线
(3)如果修正后的检测框的高度或者宽度过于小,那么就没有意义,剔除这个修正后的框
代码如下:
#(4)处理超出边缘的检测框
def merge_bboxes(bboxes, cutx, cuty):
# 保存修改后的检测框
merge_box = []
# 遍历每张图像,共4个
for i, box in enumerate(bboxes):
# 每张图片中需要删掉的检测框
index_list = []
# 遍历每张图的所有检测框,index代表第几个框
for index, box in enumerate(box[0]):
# axis=1纵向删除index索引指定的列,axis=0横向删除index指定的行
# box[0] = np.delete(box[0], index, axis=0)
# 获取每个检测框的宽高
x1, y1, x2, y2 = box
# 如果是左上图,修正右侧和下侧框线
if i== 0:
# 如果检测框左上坐标点不在第一部分中,就忽略它
if x1 > cutx or y1 > cuty:
index_list.append(index)
# 如果检测框右下坐标点不在第一部分中,右下坐标变成边缘点
if y2 >= cuty and y1 <= cuty:
y2 = cuty
if y2-y1 < 5:
index_list.append(index)
if x2 >= cutx and x1 <= cutx:
x2 = cutx
# 如果修正后的左上坐标和右下坐标之间的距离过小,就忽略这个框
if x2-x1 < 5:
index_list.append(index)
# 如果是右上图,修正左侧和下册框线
if i == 1:
if x2 < cutx or y1 > cuty:
index_list.append(index)
if y2 >= cuty and y1 <= cuty:
y2 = cuty
if y2-y1 < 5:
index_list.append(index)
if x1 <= cutx and x2 >= cutx:
x1 = cutx
if x2-x1 < 5:
index_list.append(index)
# 如果是左下图
if i == 2:
if x1 > cutx or y2 < cuty:
index_list.append(index)
if y1 <= cuty and y2 >= cuty:
y1 = cuty
if y2-y1 < 5:
index_list.append(index)
if x1 <= cutx and x2 >= cutx:
x2 = cutx
if x2-x1 < 5:
index_list.append(index)
# 如果是右下图
if i == 3:
if x2 < cutx or y2 < cuty:
index_list.append(index)
if x1 <= cutx and x2 >= cutx:
x1 = cutx
if x2-x1 < 5:
index_list.append(index)
if y1 <= cuty and y2 >= cuty:
y1 = cuty
if y2-y1 < 5:
index_list.append(index)
# 更新坐标信息
bboxes[i][0][index] = [x1, y1, x2, y2] # 更新第i张图的第index个检测框的坐标
# 删除不满足要求的框,并保存
merge_box.append(np.delete(bboxes[i][0], index_list, axis=0))
# 返回坐标信息
return merge_box
#(3)处理超出图像边缘的检测框
new_boxes = merge_bboxes(box_datas, cutx, cuty)
# 复制一份合并后的图像
modify_image_copy = new_image.copy()
# 绘制修正后的检测框
for boxes in new_boxes:
# 遍历每张图像中的所有检测框
for box in boxes:
# 获取某一个框的坐标
x1, y1, x2, y2 = box
cv2.rectangle(modify_image_copy, (x1,y1), (x2,y2), (0,255,0), 2)
cv2.imshow('new_img_bbox', modify_image_copy)
cv2.waitKey(0)
cv2.destroyAllWindows() 效果图如下:
3. 完整代码
from xml.etree import ElementTree as ET # xml文件解析方法
import numpy as np
import cv2
#(3)处理超出边缘的检测框
def merge_bboxes(bboxes, cutx, cuty):
# 保存修改后的检测框
merge_box = []
# 遍历每张图像,共4个
for i, box in enumerate(bboxes):
# 每张图片中需要删掉的检测框
index_list = []
# 遍历每张图的所有检测框,index代表第几个框
for index, box in enumerate(box[0]):
# axis=1纵向删除index索引指定的列,axis=0横向删除index指定的行
# box[0] = np.delete(box[0], index, axis=0)
# 获取每个检测框的宽高
x1, y1, x2, y2 = box
# 如果是左上图,修正右侧和下侧框线
if i== 0:
# 如果检测框左上坐标点不在第一部分中,就忽略它
if x1 > cutx or y1 > cuty:
index_list.append(index)
# 如果检测框右下坐标点不在第一部分中,右下坐标变成边缘点
if y2 >= cuty and y1 <= cuty:
y2 = cuty
if y2-y1 < 5:
index_list.append(index)
if x2 >= cutx and x1 <= cutx:
x2 = cutx
# 如果修正后的左上坐标和右下坐标之间的距离过小,就忽略这个框
if x2-x1 < 5:
index_list.append(index)
# 如果是右上图,修正左侧和下册框线
if i == 1:
if x2 < cutx or y1 > cuty:
index_list.append(index)
if y2 >= cuty and y1 <= cuty:
y2 = cuty
if y2-y1 < 5:
index_list.append(index)
if x1 <= cutx and x2 >= cutx:
x1 = cutx
if x2-x1 < 5:
index_list.append(index)
# 如果是左下图
if i == 2:
if x1 > cutx or y2 < cuty:
index_list.append(index)
if y1 <= cuty and y2 >= cuty:
y1 = cuty
if y2-y1 < 5:
index_list.append(index)
if x1 <= cutx and x2 >= cutx:
x2 = cutx
if x2-x1 < 5:
index_list.append(index)
# 如果是右下图
if i == 3:
if x2 < cutx or y2 < cuty:
index_list.append(index)
if x1 <= cutx and x2 >= cutx:
x1 = cutx
if x2-x1 < 5:
index_list.append(index)
if y1 <= cuty and y2 >= cuty:
y1 = cuty
if y2-y1 < 5:
index_list.append(index)
# 更新坐标信息
bboxes[i][0][index] = [x1, y1, x2, y2] # 更新第i张图的第index个检测框的坐标
# 删除不满足要求的框,并保存
merge_box.append(np.delete(bboxes[i][0], index_list, axis=0))
# 返回坐标信息
return merge_box
#(1)对传入的四张图片数据增强
def get_random_data(image_list, input_shape):
h, w = input_shape # 获取图像的宽高
'''设置拼接的分隔线位置'''
min_offset_x = 0.4
min_offset_y = 0.4
scale_low = 1 - min(min_offset_x, min_offset_y) # 0.6
scale_high = scale_low + 0.2 # 0.8
image_datas = [] # 存放图像信息
box_datas = [] # 存放检测框信息
index = 0 # 当前是第几张图
#(1)图像分割
for frame_list in image_list:
frame = frame_list[0] # 取出的某一张图像
box = np.array(frame_list[1:]) # 该图像对应的检测框坐标
ih, iw = frame.shape[0:2] # 图片的宽高
cx = (box[0,:,0] + box[0,:,2]) // 2 # 检测框中心点的x坐标
cy = (box[0,:,1] + box[0,:,3]) // 2 # 检测框中心点的y坐标
# 对输入图像缩放
new_ar = w/h # 图像的宽高比
scale = np.random.uniform(scale_low, scale_high) # 缩放0.6--0.8倍
# 调整后的宽高
nh = int(scale * h) # 缩放比例乘以要求的宽高
nw = int(nh * new_ar) # 保持原始宽高比例
# 缩放图像
frame = cv2.resize(frame, (nw,nh))
# 调整中心点坐标
cx = cx * nw/iw
cy = cy * nh/ih
# 调整检测框的宽高
bw = (box[0,:,2] - box[0,:,0]) * nw/iw # 修改后的检测框的宽高
bh = (box[0,:,3] - box[0,:,1]) * nh/ih
# 创建一块[416,416]的底版
new_frame = np.zeros((h,w,3), np.uint8)
# 确定每张图的位置
if index==0: new_frame[0:nh, 0:nw] = frame # 第一张位于左上方
elif index==1: new_frame[0:nh, w-nw:w] = frame # 第二张位于右上方
elif index==2: new_frame[h-nh:h, 0:nw] = frame # 第三张位于左下方
elif index==3: new_frame[h-nh:h, w-nw:w] = frame # 第四张位于右下方
# 修正每个检测框的位置
if index==0: # 左上图像
box[0,:,0] = cx - bw // 2 # x1
box[0,:,1] = cy - bh // 2 # y1
box[0,:,2] = cx + bw // 2 # x2
box[0,:,3] = cy + bh // 2 # y2
if index==1: # 右上图像
box[0,:,0] = cx - bw // 2 + w - nw # x1
box[0,:,1] = cy - bh // 2 # y1
box[0,:,2] = cx + bw // 2 + w - nw # x2
box[0,:,3] = cy + bh // 2 # y2
if index==2: # 左下图像
box[0,:,0] = cx - bw // 2 # x1
box[0,:,1] = cy - bh // 2 + h - nh # y1
box[0,:,2] = cx + bw // 2 # x2
box[0,:,3] = cy + bh // 2 + h - nh # y2
if index==3: # 右下图像
box[0,:,2] = cx - bw // 2 + w - nw # x1
box[0,:,3] = cy - bh // 2 + h - nh # y1
box[0,:,0] = cx + bw // 2 + w - nw # x2
box[0,:,1] = cy + bh // 2 + h - nh # y2
index = index + 1 # 处理下一张
# 保存处理后的图像及对应的检测框坐标
image_datas.append(new_frame)
box_datas.append(box)
# 取出某张图片以及它对应的检测框信息, i代表图片索引
for image, boxes in zip(image_datas, box_datas):
# 复制一份原图
image_copy = image.copy()
# 遍历该张图像中的所有检测框
for box in boxes[0]:
# 获取某一个框的坐标
x1, y1, x2, y2 = box
cv2.rectangle(image_copy, (x1,y1), (x2,y2), (0,255,0), 2)
cv2.imshow('img', image_copy)
cv2.waitKey(0)
cv2.destroyAllWindows()
#(2)将四张图像拼接在一起
# 在指定范围中选择横纵向分割线
cutx = np.random.randint(int(w*min_offset_x), int(w*(1-min_offset_x)))
cuty = np.random.randint(int(h*min_offset_y), int(h*(1-min_offset_y)))
# 创建一块[416,416]的底版用来组合四张图
new_image = np.zeros((h,w,3), np.uint8)
new_image[:cuty, :cutx, :] = image_datas[0][:cuty, :cutx, :]
new_image[:cuty, cutx:, :] = image_datas[1][:cuty, cutx:, :]
new_image[cuty:, :cutx, :] = image_datas[2][cuty:, :cutx, :]
new_image[cuty:, cutx:, :] = image_datas[3][cuty:, cutx:, :]
# 显示合并后的图像
cv2.imshow('new_img', new_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 复制一份合并后的原图
final_image_copy = new_image.copy()
# 显示有检测框并合并后的图像
for boxes in box_datas:
# 遍历该张图像中的所有检测框
for box in boxes[0]:
# 获取某一个框的坐标
x1, y1, x2, y2 = box
cv2.rectangle(final_image_copy, (x1,y1), (x2,y2), (0,255,0), 2)
cv2.imshow('new_img_bbox', final_image_copy)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 处理超出图像边缘的检测框
new_boxes = merge_bboxes(box_datas, cutx, cuty)
# 复制一份合并后的图像
modify_image_copy = new_image.copy()
# 绘制修正后的检测框
for boxes in new_boxes:
# 遍历每张图像中的所有检测框
for box in boxes:
# 获取某一个框的坐标
x1, y1, x2, y2 = box
cv2.rectangle(modify_image_copy, (x1,y1), (x2,y2), (0,255,0), 2)
cv2.imshow('new_img_bbox', modify_image_copy)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 主函数,获取图片路径和检测框路径
if __name__ == '__main__':
# 给出图片文件夹和检测框文件夹所在的位置
image_dir = 'D:/deeplearning/database/VOC2007/picture/'
annotation_dir = 'D:/deeplearning/database/VOC2007/annotation/'
image_list = [] # 存放每张图像和该图像对应的检测框坐标信息
# 读取4张图像及其检测框信息
for i in range(4):
image_box = [] # 存放每张图片的检测框信息
# 某张图片位置及其对应的检测框信息
image_path = image_dir + str(i+1) + '.jpg'
annotation_path = annotation_dir + str(i+1) + '.xml'
image = cv2.imread(image_path) # 读取图像
# 读取检测框信息
with open(annotation_path, 'r') as new_f:
# getroot()获取根节点
root = ET.parse(annotation_path).getroot()
# findall查询根节点下的所有直系子节点,find查询根节点下的第一个直系子节点
for obj in root.findall('object'):
obj_name = obj.find('name').text # 目标名称
bndbox = obj.find('bndbox')
left = eval(bndbox.find('xmin').text) # 左上坐标x
top = eval(bndbox.find('ymin').text) # 左上坐标y
right = eval(bndbox.find('xmax').text) # 右下坐标x
bottom = eval(bndbox.find('ymax').text) # 右下坐标y
# 保存每张图片的检测框信息
image_box.append([left, top, right, bottom]) # [[x1,y1,x2,y2],[..],[..]]
# 保存图像及其对应的检测框信息
image_list.append([image, image_box])
# 缩放、拼接图片
get_random_data(image_list, input_shape=[416,416])文章出处登录后可见!