Self-Attention机制学习
注意力机制解决问题
- CNN网络用输入是 一个向量 比如图像处理之后 3x224x224 所有图片大小一致
- 但是输入可以是一排向量 并且每行长度都不一样
- 文字处理–句子长度不一样 vector set 长度不一样 常规做法one-hot encoding 问题:向量里面没有语义 另一个方法: word embedding
- 一段语音 每个window包含的语音信息都是不一样的
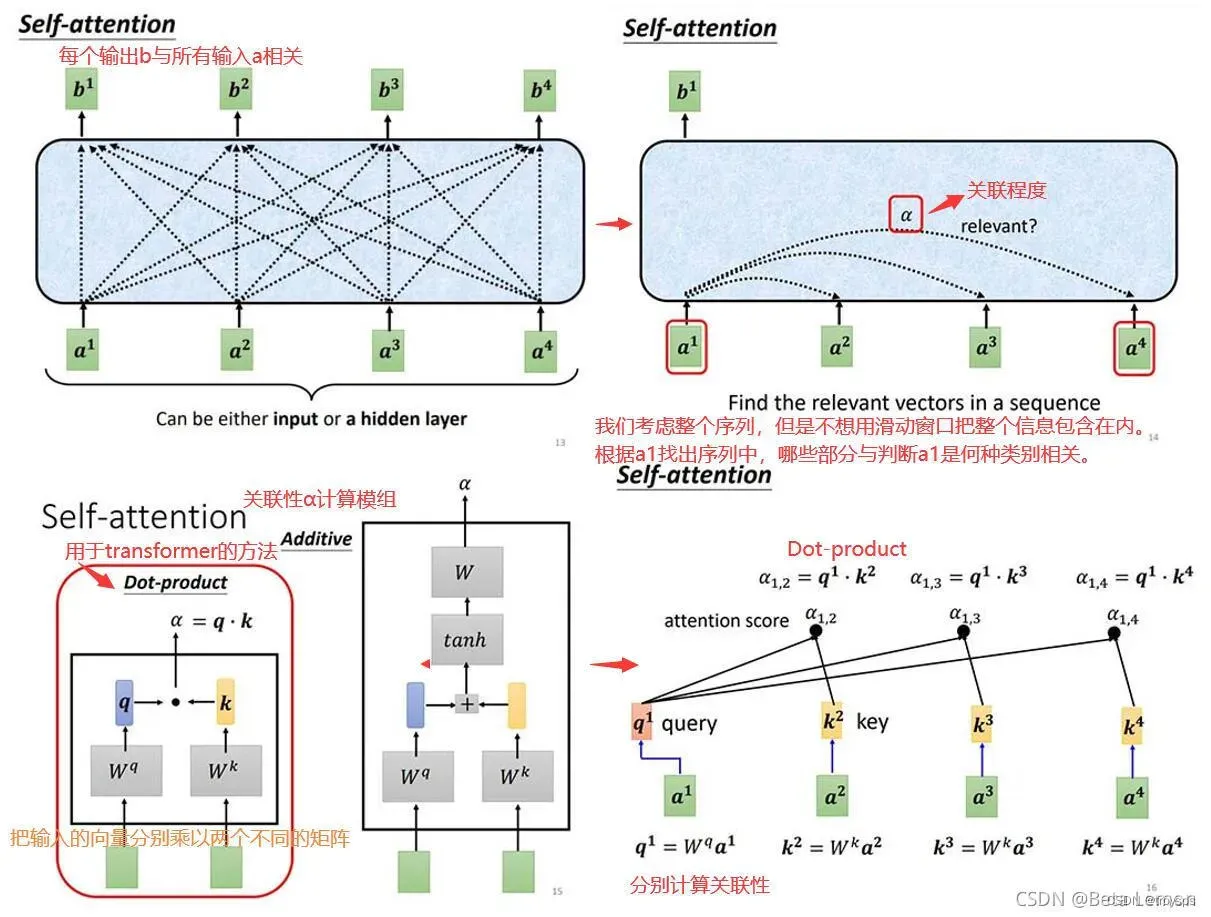
- 关联图 其实每个节点可以看作一个向量
对应输出
-
each vector has a label(输出和输入一样) 比如说: 词性标注
- I saw a saw pos tagging: N V DET N
-
输出只有一个label
- 比如情感分类之类的
-
输入N个 输出M个 : seq2seq
- 比如翻译任务
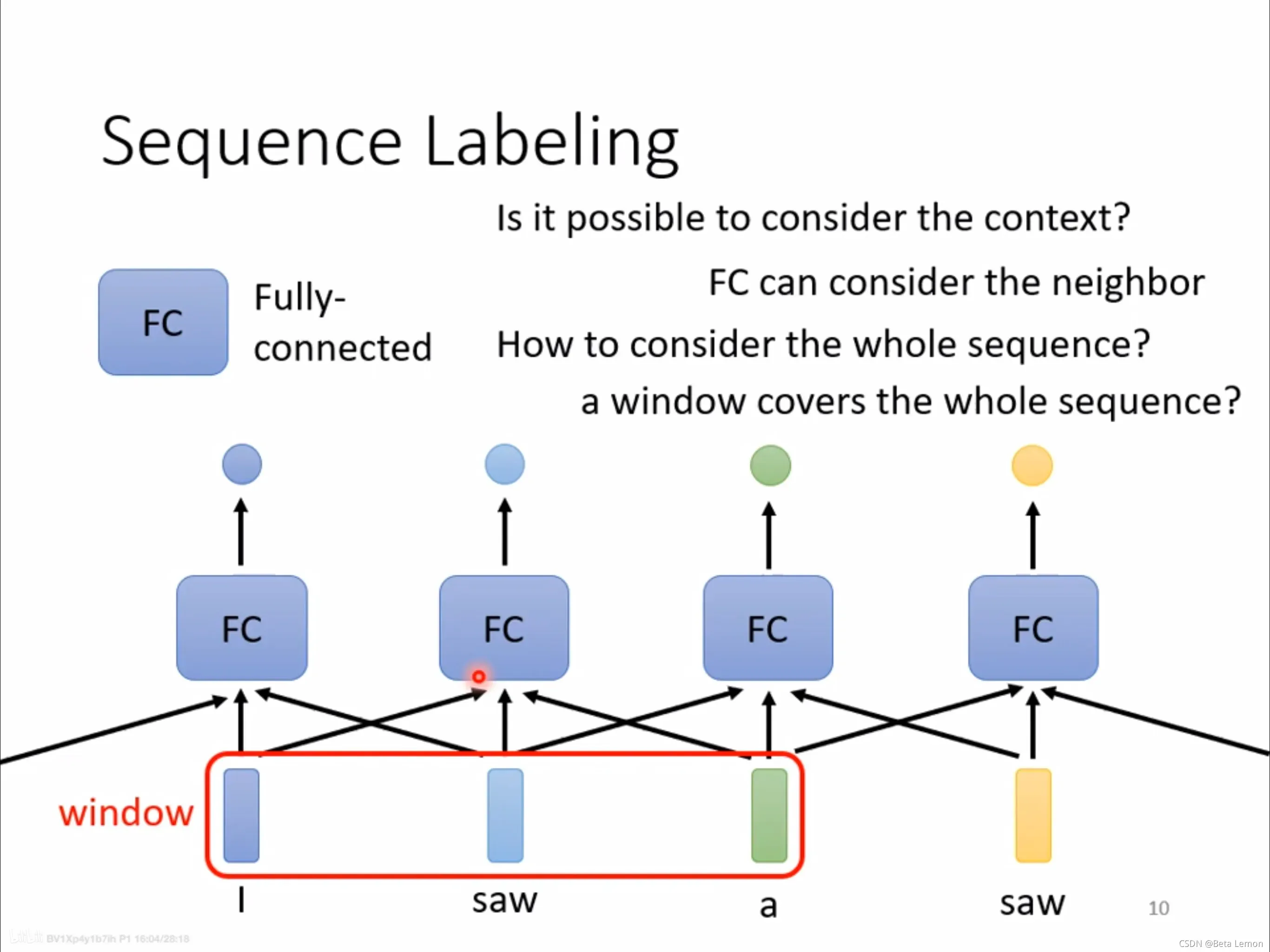
Sequence labeling(序列标注问题)
利用全连接网络,输入一个句子,输出对应单词数目的标签。当一个句子里出现两个相同的单词,并且它们的词性不同(例如:I saw a saw. 我看见一把锯子),这个时候就需要考虑上下文:利用滑动窗口,每个向量查看窗口中相邻的其他向量的性质。
- is it possible to consider the context ?
- FC can consider the neighbor
- how to consider the whole sequence ?
- a window covers the whole sequence?
- 每个input长度不一致
self-attention 基本步骤
[1706.03762] Attention Is All You Need (arxiv.org)
首先来看下整个过程
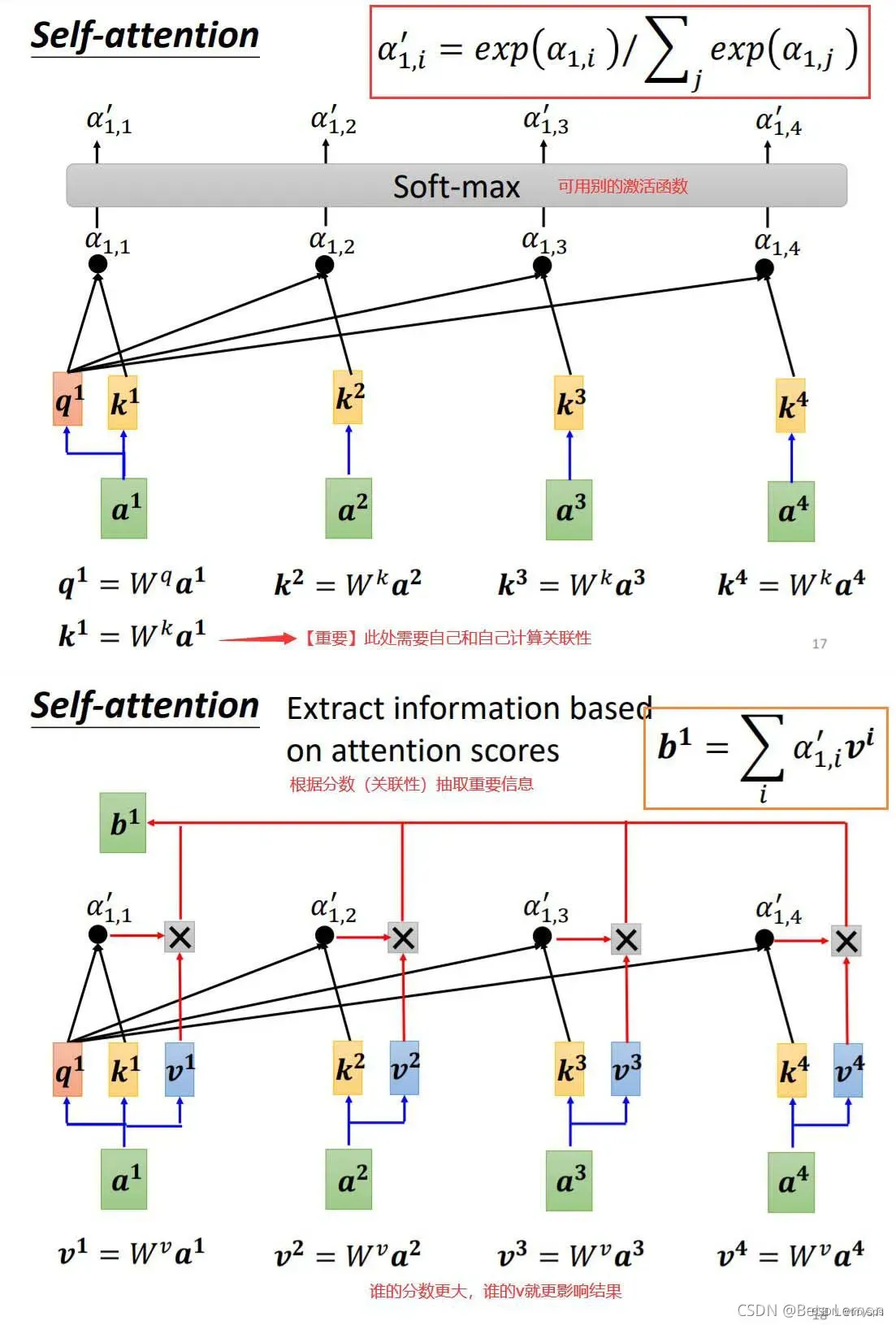
由此可以看出整个过程基本分为三步
**1.计算 Q 和 K 的 关联性 **
-
什么是Q,K?
- Q:queries K:key Q表示查询 K表示关键词 借鉴推荐系统中的含义 根据Q与K计算关联性然后推荐V(但是self-attention的目标不是单纯的抽取V)
-
为什么Q*K计算自己的关联性
- 首先我们知道计算矩阵的内积
的意义在于表征一个向量在另一个向量上的投影, 也就是两个向量之间的关联性
- 首先我们知道计算矩阵的内积
-
为什么不用**
- 我认为有以下几点好处
- Q,K 通过空间变换矩阵 将输入分别变化为Q,K 解决了输入长度不一致的问题
- 通过中间的变换 减少了计算量 $(seqLen \times inputDim \times inputDim \times seqLen) \ 变换成了 Q(seqLen \times inputDim \times inputDim \times dimK) \ K(seqLen \times inputDim \times inputDim \times dimK) \ 最后QK(seqLen \times seqLen ) $
- 通过中间层 学习到了 非线性特征
2.对关联性进行softmax处理
- 为什么要除以
?
- 论文中提出的观点是 加性注意力在
维度较小的时候效果优于点积注意力, 怀疑是由于点积的跨度太大所以为了抵消影响除以
- 数学原理 假设
, 他们的点积为
- 论文中提出的观点是 加性注意力在
3.根据权重系数对Value进行加权求和,得到Attention Value
- 把自身作为Q,K之后为什么还要变换为V
- self-attention 中这里 key 和 value 都是输入序列本身的一个变换,可能这也是 self-attention 的另外一层含义吧:自身同时作为 key 和 value。其实也非常合理,因为在推荐系统中,虽然 key 和 value 属性原始的特征空间不同,但是它们是有强关联关系的,因此他们通过一定的空间变换,是可以统一到一个特征空间中。这也是为什么self-attention 要乘以 W 的原因之一。
参考:https://blog.csdn.net/yangyehuisw/article/details/116207892
- self-attention 中这里 key 和 value 都是输入序列本身的一个变换,可能这也是 self-attention 的另外一层含义吧:自身同时作为 key 和 value。其实也非常合理,因为在推荐系统中,虽然 key 和 value 属性原始的特征空间不同,但是它们是有强关联关系的,因此他们通过一定的空间变换,是可以统一到一个特征空间中。这也是为什么self-attention 要乘以 W 的原因之一。
self-attention 算法步骤
1.计算比较Q和K的相似度,用f来表示
2.将得到的相似度进行Softmax操作,进行归一化
3.针对计算出来的权重对V中所有的values进行加权求和计算,得到Attention向量
self-attention 代码实现
from math import sqrt
import torch
import torch.nn
class Self_Attention(nn.Module):
# input : batch_size * seq_len * input_dim
# q : batch_size * input_dim * dim_k
# k : batch_size * input_dim * dim_k
# v : batch_size * input_dim * dim_v
def __init__(self,input_dim,dim_k,dim_v):
super(Self_Attention,self).__init__()
self.q = nn.Linear(input_dim,dim_k)
self.k = nn.Linear(input_dim,dim_k)
self.v = nn.Linear(input_dim,dim_v)
self._norm_fact = 1 / sqrt(dim_k)
def forward(self,x):
Q = self.q(x) # Q: batch_size * seq_len * dim_k
K = self.k(x) # K: batch_size * seq_len * dim_k
V = self.v(x) # V: batch_size * seq_len * dim_v
atten = nn.Softmax(dim=-1)(torch.bmm(Q,K.permute(0,2,1))) * self._norm_fact # Q * K.T() # batch_size * seq_len * seq_len
output = torch.bmm(atten,V) # Q * K.T() * V # batch_size * seq_len * dim_v
return output
参考:
超详细图解Self-Attention – 知乎 (zhihu.com)
(36条消息) 如何理解 Transformer 中的 Query、Key 与 Value_yafee123的博客-CSDN博客_key query value
文章出处登录后可见!
已经登录?立即刷新