最近断断续续读了一下YOLOv3的论文、代码,并做了模型训练和推理。趁周五没有紧急任务,空出一点时间来整理一下YOLOv3的模型结构和PyTorch实现。
YOLO并不是精度最高的目标检测算法,其关注点在于速度和精度之间的平衡,很适合在精度损失不多的情况下做实时检测。
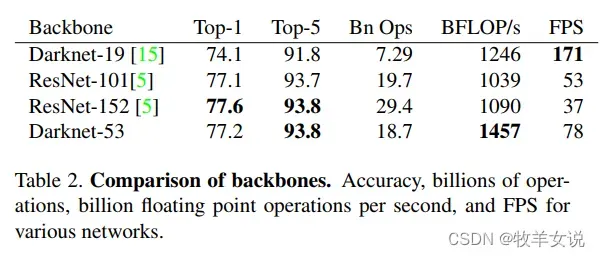
YOLOv3相较于YOLOv2(使用Darknet-19作为主干网络),使用了更深层的特征提取网络Darknet-53,并引入了残差结构,这使得网络参数量较YOLOv2更大,但其精度也更高,尤其对于一些YOLOv2难以检测出的小物体。
Darknet-53的网络架构如下图所示:
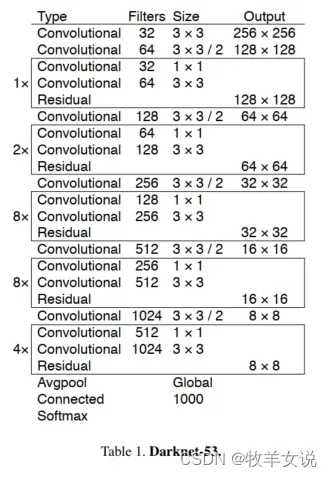
该网络比Darknet-19强大得多,但在运行效率上比ResNet-101和 ResNet-152更加高效。
YOLOv3在DarkNet-53作为主干网络的基础上,又增加了53层做目标检测任务,网络结构如下:
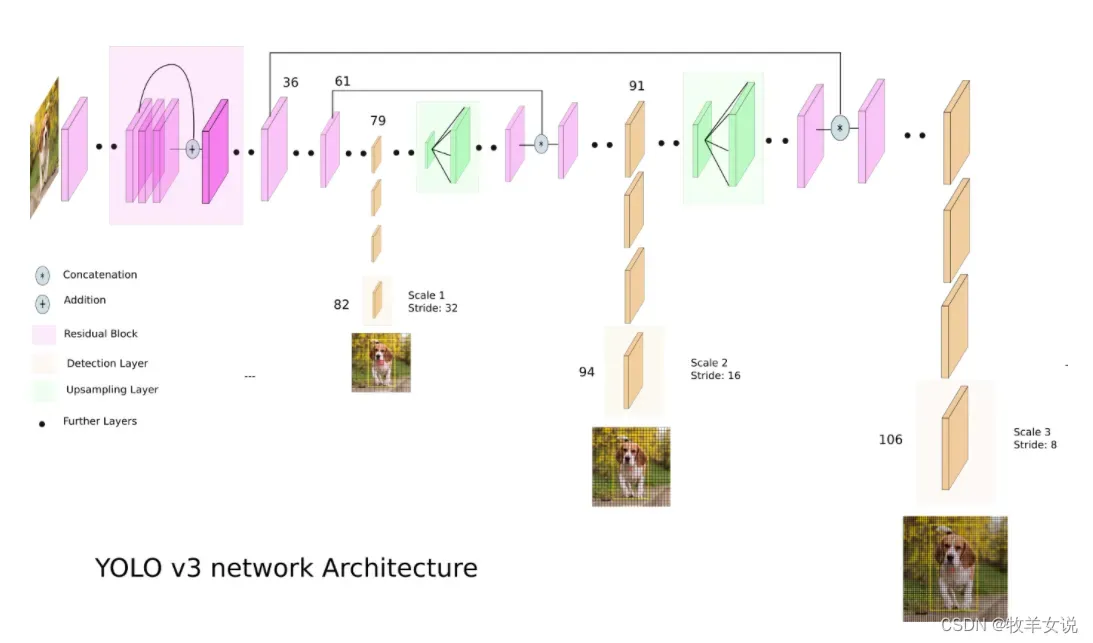
检测核的维度为1 x 1 x (B x (5 + C) ),B为每个单元可以预测的bounding boxes的数量,在YOLOv3中,B=3;5表示4个bounding box的属性(左上角坐标、宽、高),和1个目标置信度;C为目标类别的数目,在COCO数据集上,C=80。所以,在COCO数据集上,YOLOv3每个预测单元的kernel size为1x1x(3x(5+80))=255,具体可参考下图。

为了满足大、中、小目标的检测,YOLOv3在3个尺度上来预测目标。三个尺度分别是对输入图像的尺寸进行32、16和8倍下采样获得。
这里我们默认输入图像大小为416×416。如架构图所示,第一个预测由第82层给出,输出的feature map为13×13,即原始图像经过32倍下采样的大小,该尺度对应图像中的较大目标物体。在这里会用1×1的kernel进行一次检测,因此整个检测的feature map为13x13x255。
第79层的feature map经过几个卷积层后,被2倍上采样到26×26,该特征图会与第61层特征图进行深度拼接(depth concatenation),拼接后的特征图经过一系列1×1的卷积层进行融合。接下来,在第94层进行第二个检测,该检测主要针对中等大小的目标物体,最终的检测feature map大小为26x26x255。
第三个scale的检测与之前一样,第91层的特征图经过几个卷积层之后,与第36层进行拼接,并经过一些1×1卷积层进行特征融合。之后,在第106层进行第三个检测,该检测主要针对小目标物体,最终的检测feature map大小为52x52x255。
对于416×416的输入图像大小,YOLOv3预测框的总数为10647(13x13x3 + 26x26x3 + 52x52x3)。该数量是之前YOLOv2的10倍,因此YOLOv3的运算速度也比YOLOv2要慢一些。但对比其他一些较先进的检测器(如RetinaNet),在表现相差不大的前提下,YOLOv3依然要快得多,下面是论文中那张很著名的、画得相当过分的对比图:
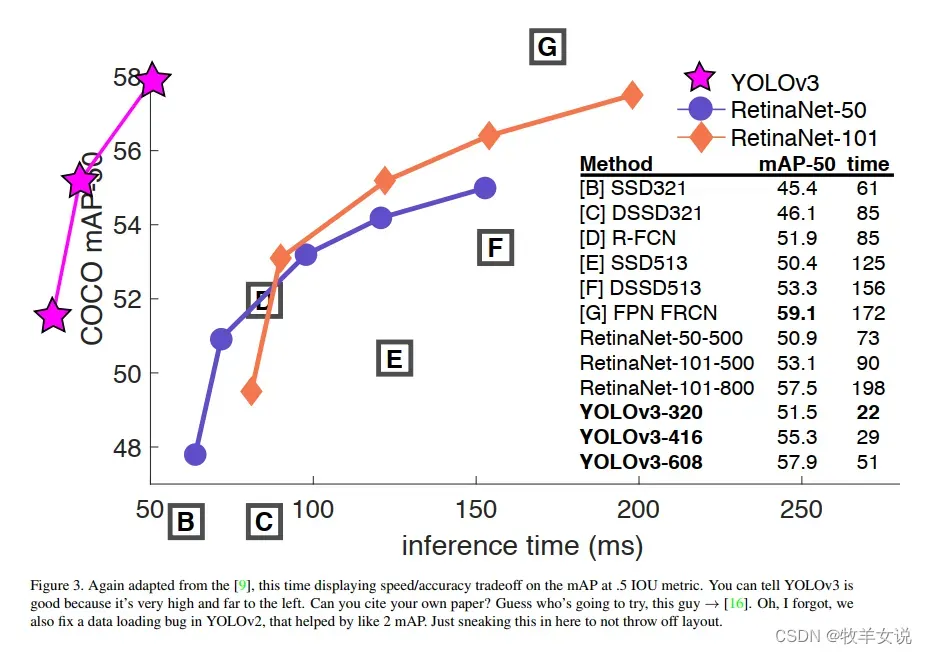
时间关系,今天就更新这么多,更多内容,且待续集。
文章出处登录后可见!