一、Image Classification
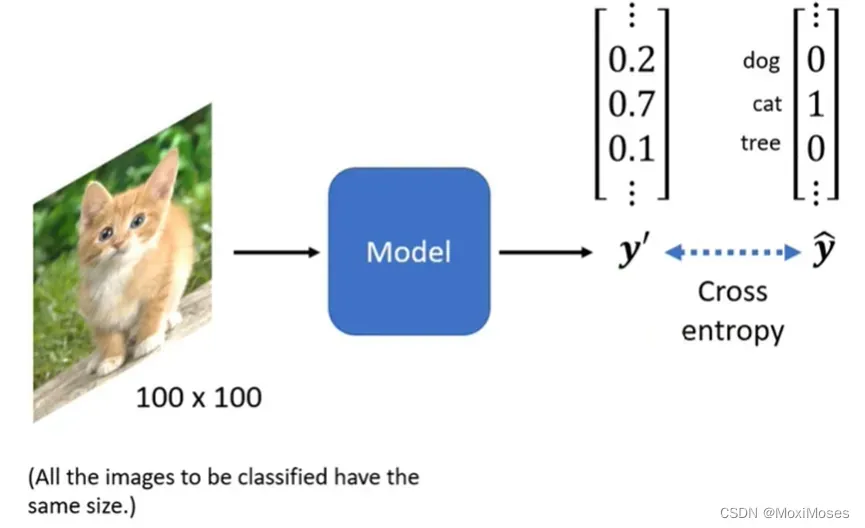
1. 给机器一张图片,看这张图片有什么内容,输入要固定图片的大小,最后我们希望y’与ŷ之间的Cross entropy越小越好。
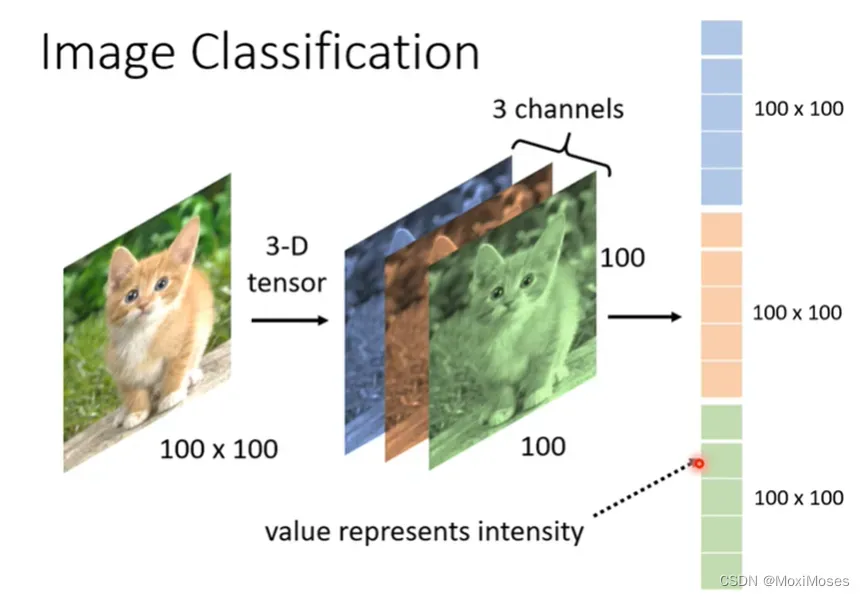
2. 一张图片是3维的tensor,分别为长、宽、channel。长和宽代表了图片的解析度,代表了图片中像素的数目, 图中的channel代表了RGB三个颜色。3维的tensor是由1001003个数字组成,把它们整理出来,排成一排,就成了向量。在这个向量里面每一维的数值代表就代表某一个位置的强度。
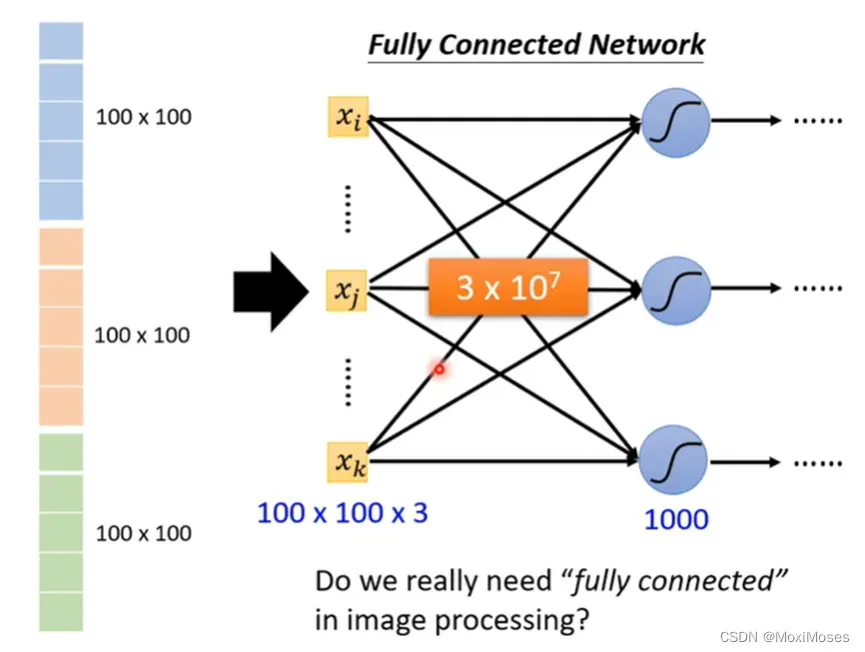
3. 这个向量可以当作network的输入。随着参数地增多,可以增加模型的弹性,但是这样也增加了overfitting的风险。
二、Observation 1
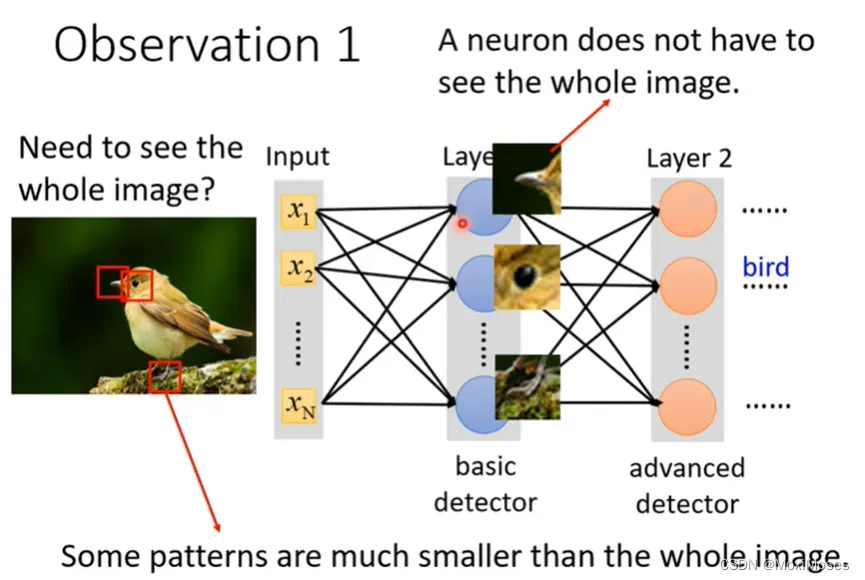
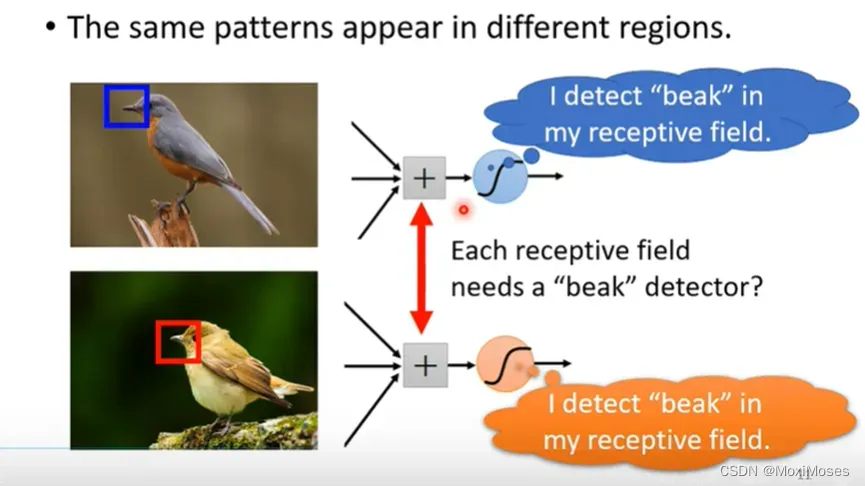
1. 对于影像辨识而言,假设我们想要知道这个图片里面的动物是一只鸟,我们需要侦测这张图片有没有出现特别重要的pattern,而这个pattern是代表了某种物件。
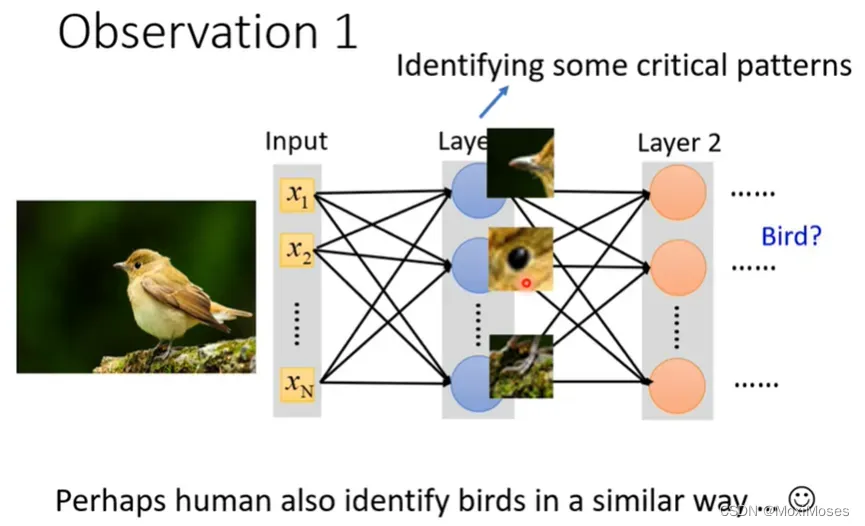
2. 对于人来说,我们会通过某些特征来直觉地判断这是什么物件。如下图所示,我们的第一直觉以为这是乌鸦,但其实它是一只猫。

3. 我们其实并不需要看一张完整的图片,通过图片的一小部分,我们就可以判断这张图片的内容是什么。
三、Simplification 1
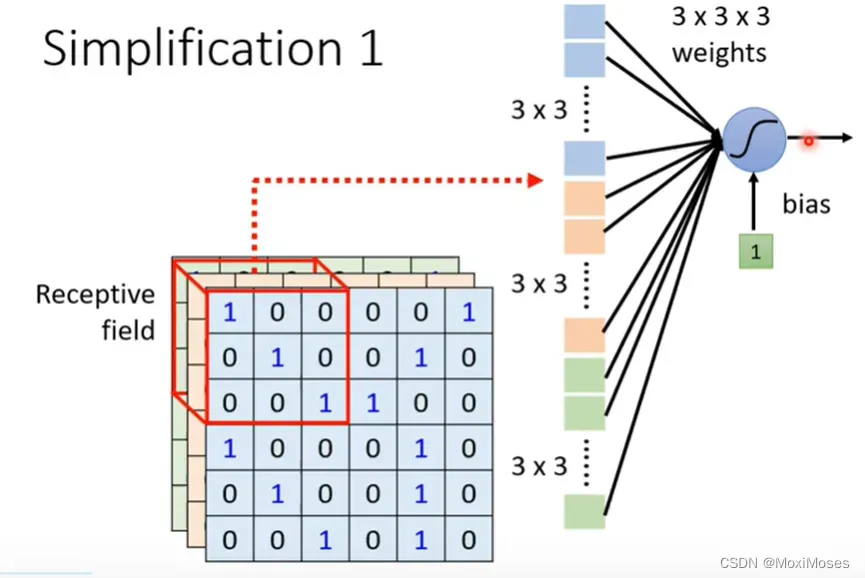
1. 我们会设定一个区域Receptive field,每一个neuron只需要关心自己的Receptive field就好了。
2. Receptive field之间可以是重叠的,而且多个neurons可以去守备同一个Receptive field。
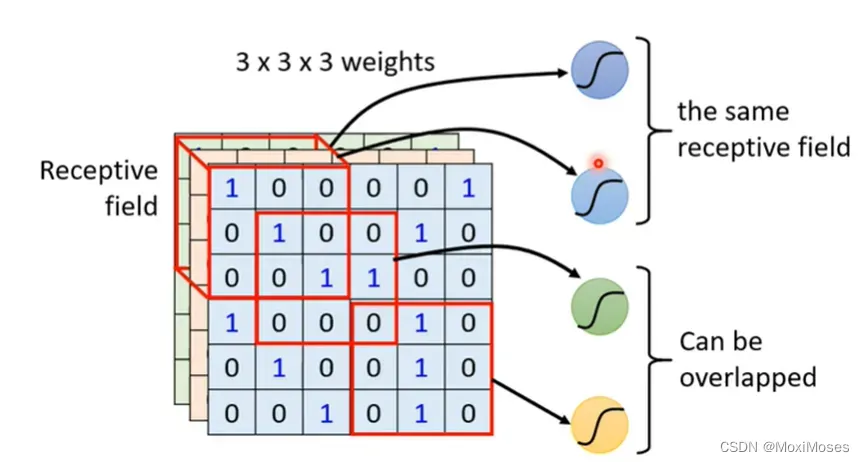
3. Receptive field是可以有大有小的,也可以只有一个channel。Receptive field可以不只是图中的正方体,也可以是长方体。Receptive field是可以不相连的,比如它可以一部分在左上角,一部分在右下角,主要取决于你想怎么做。
四、Simplification 1 – Typical Setting
1. Receptive field最经典的安排方式是要看所有的channel,我们只需要讲它的高和宽,这里不用去考虑深度。高和宽就组成了kernel size,kernel size不需要设置太大。
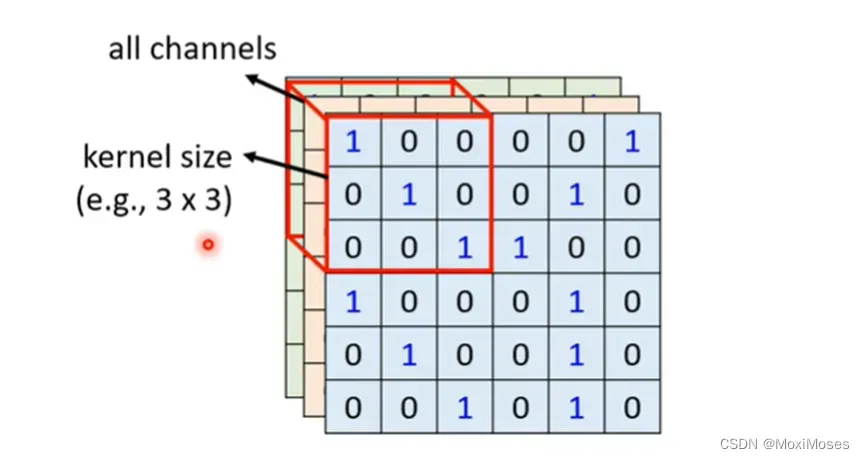
2. 每一个Receptive field有一组neurons,去守备它的范围。如下图所示,我们现在把Receptive field向右移动2格,就会形成新的Receptive field。因为我们希望Receptive field之间有一定的联系(有重叠部分),所以不会把stride(步长)设的过大。
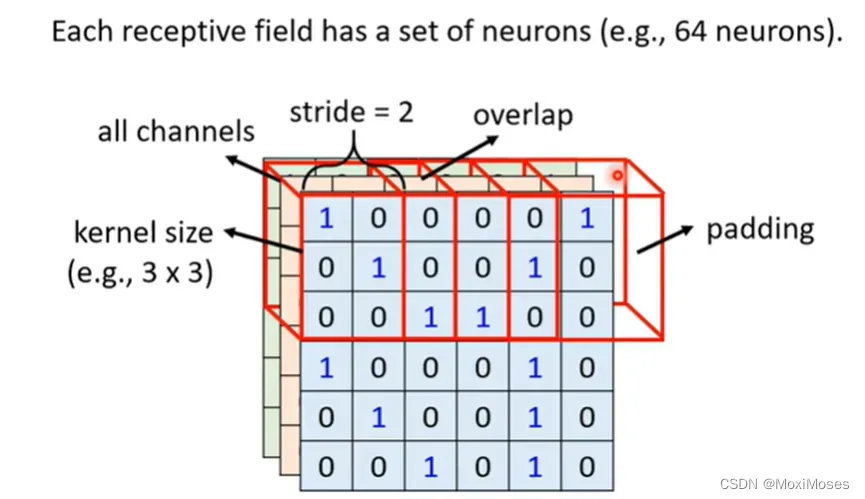
3. 在上图中Receptive field会一直向右移动到超出范围,现在我们就对超出的部分做padding,padding在这里的意思就是补0。
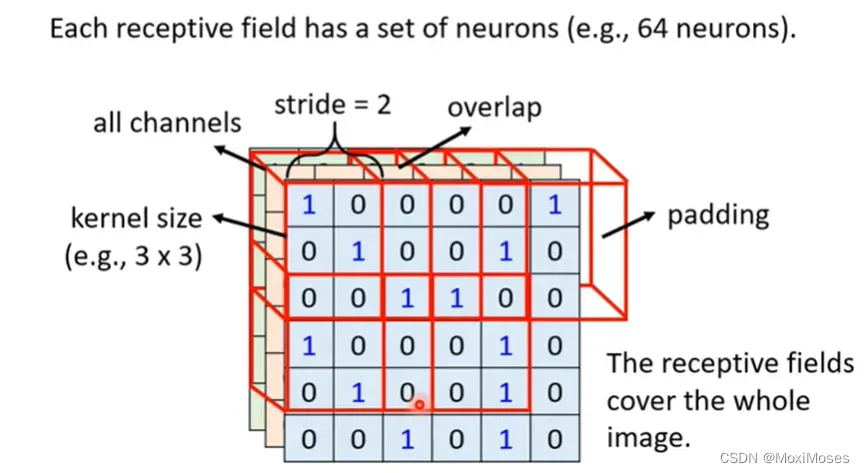
4. 整张图片都会被Receptive field覆盖,也就是图片中的每一个位置都有一群neurons在侦测这里有没有出现某些pattern。
五、Observation 2
同样的pattern会出现在不同的区域。
六、Simplification 2
1. 在影像处理上,我们可以让不同Receptive field的neuron共享参数。
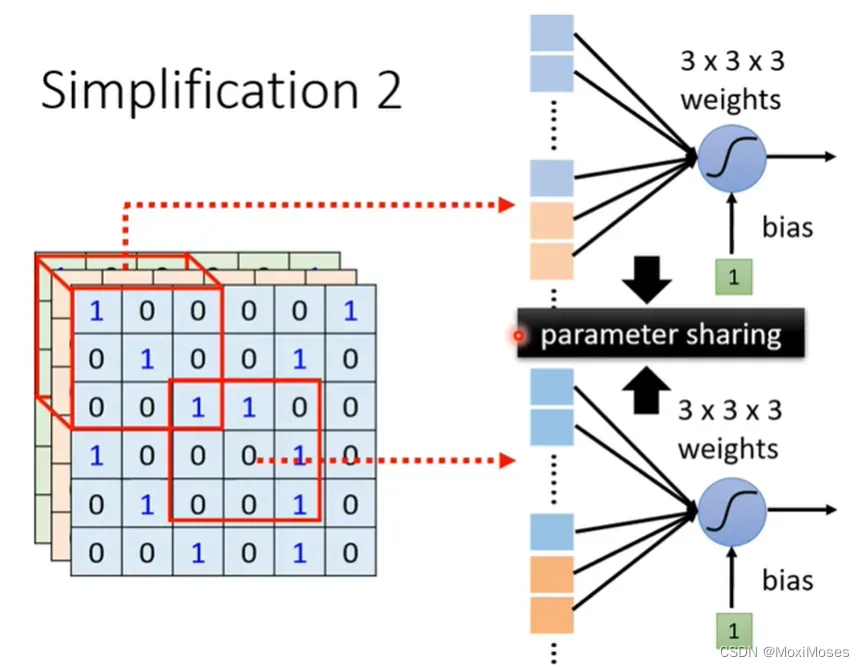
2. 如下图所示,共享参数就是这两个neurons的weight完全一样。虽然它们的参数是一样的,但它们的输出不会永远一样,因为它们的输入不一样。因此我们不会让两个Receptive field一样的neurons共享参数。
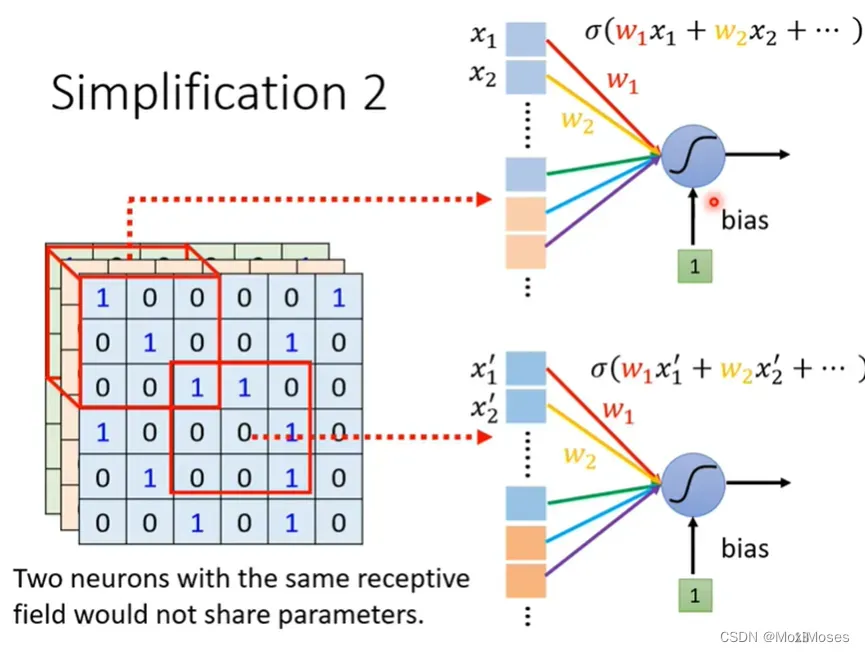
七、Simplification 2 – Typical Setting
每一个Receptive field都只有一组参数,这组参数叫做filter。
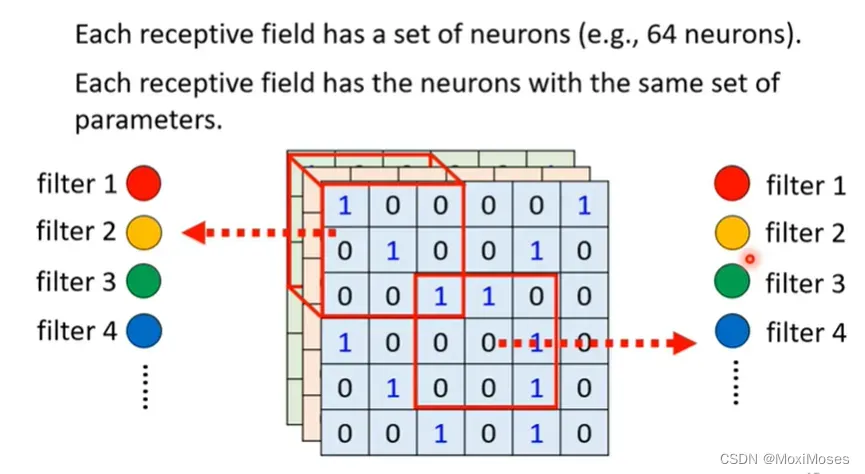
八、Benefit of Convolutional Layer
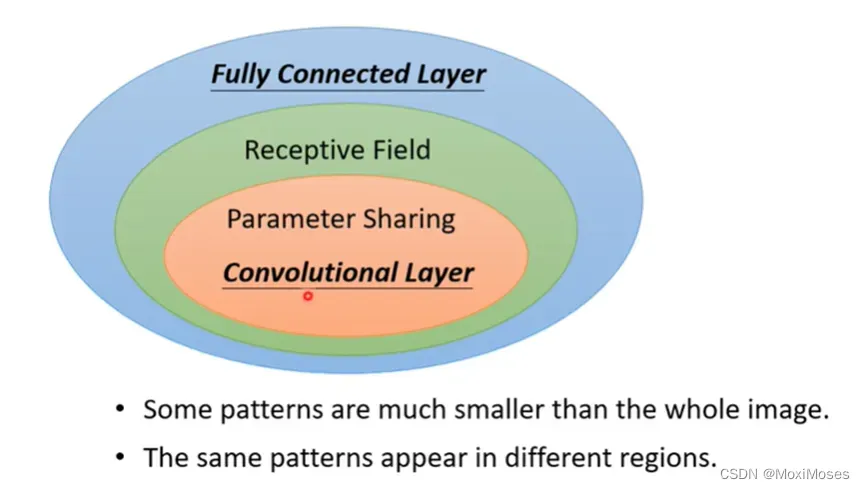
1. Full Connected Layer弹性是很大,当它加入了Receptive field和Parameter Sharing后,它们会限制Full Connected Layer的弹性,让弹性变得很小,这就是Convolutional Layer。
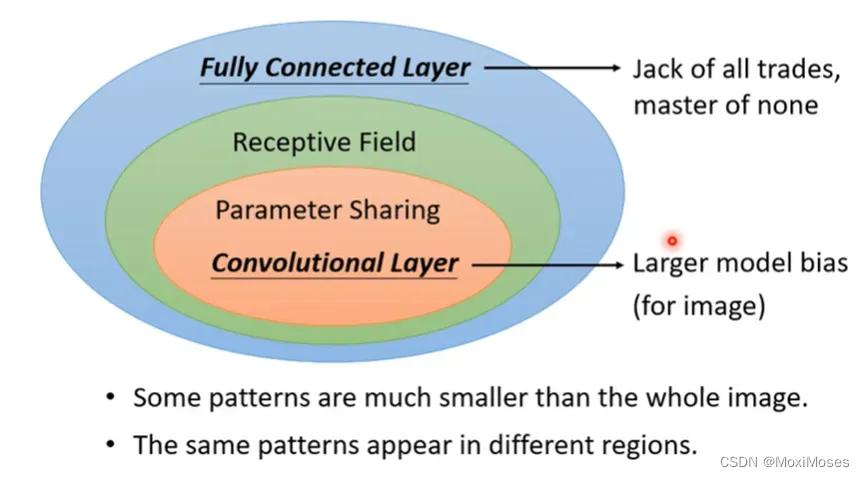
2. 如下图所示,CNN的model bias很大,但这里model bias大不是一件坏事,因为当model bias比较小时,会出现overfitting,但仅限于用在图像上。
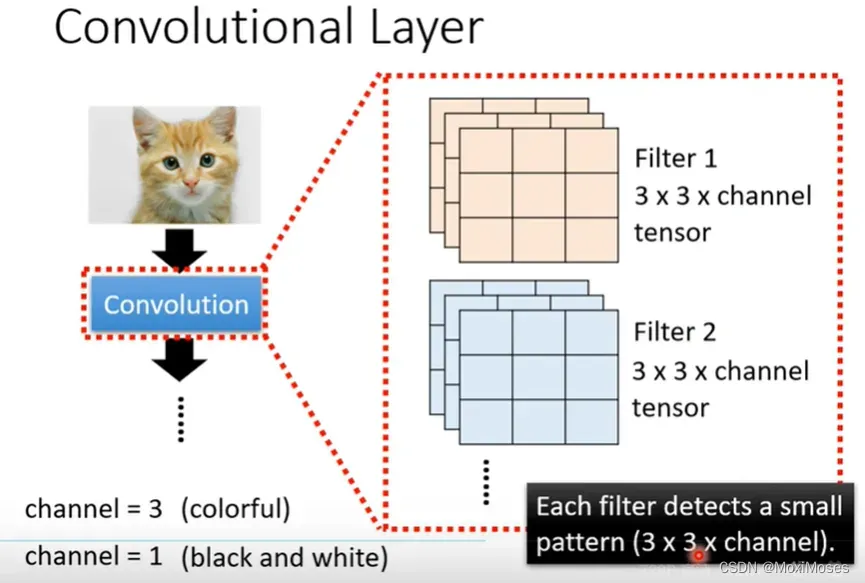
九、Convolutional Layer
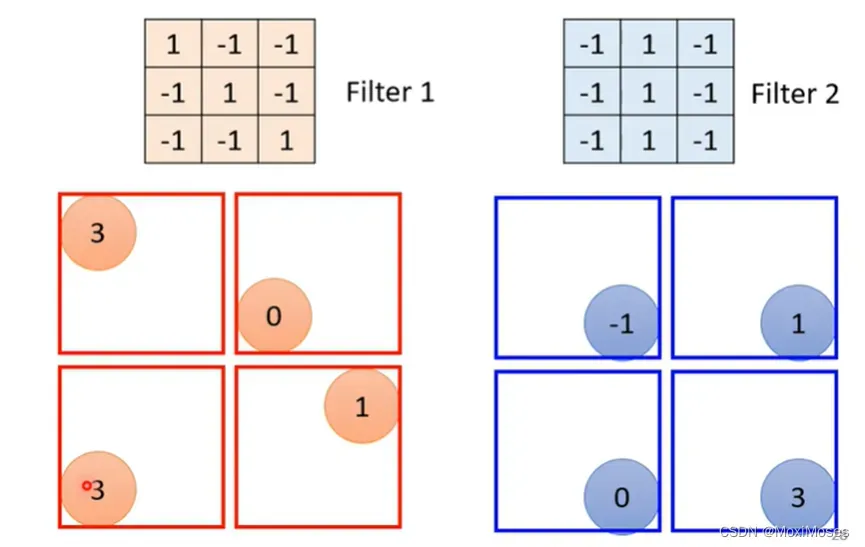
1. 如下图所示,Convolutional Layer是指它里面有一排filter,filter的作用是去到图片里面抓取某一个pattern,pattern的大小要在filter的范围内。
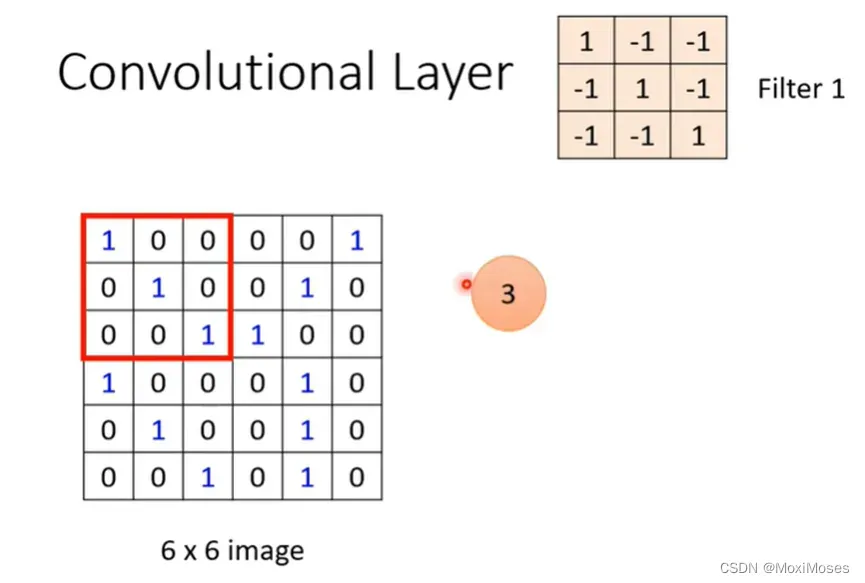
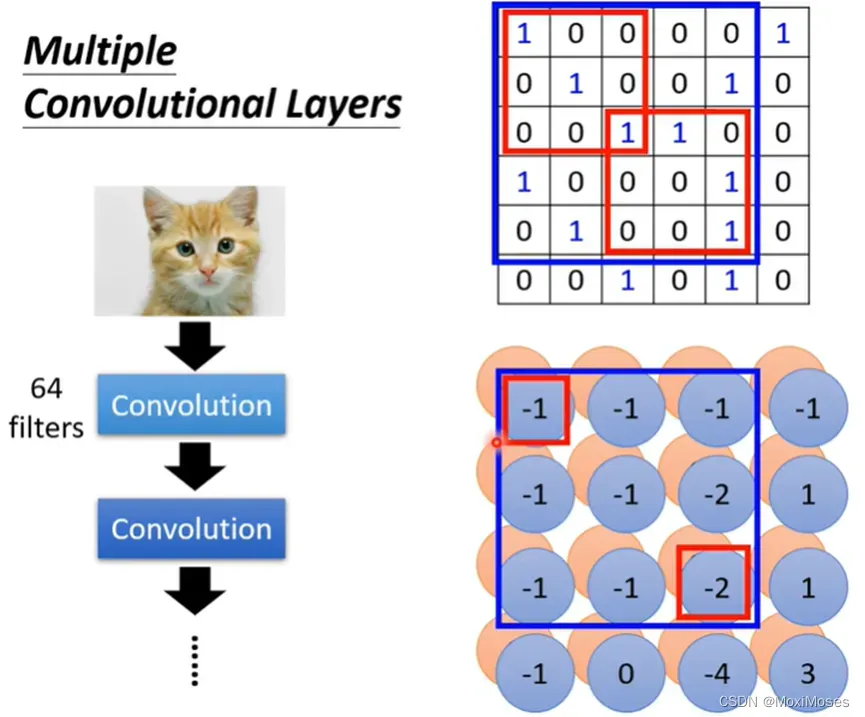
2. 假设channel = 1,也就是图片是黑白的图片。如下图所示,现在把Filter 1中的9个值与图片中的红色框里的9个值做内积(两矩阵相乘)。
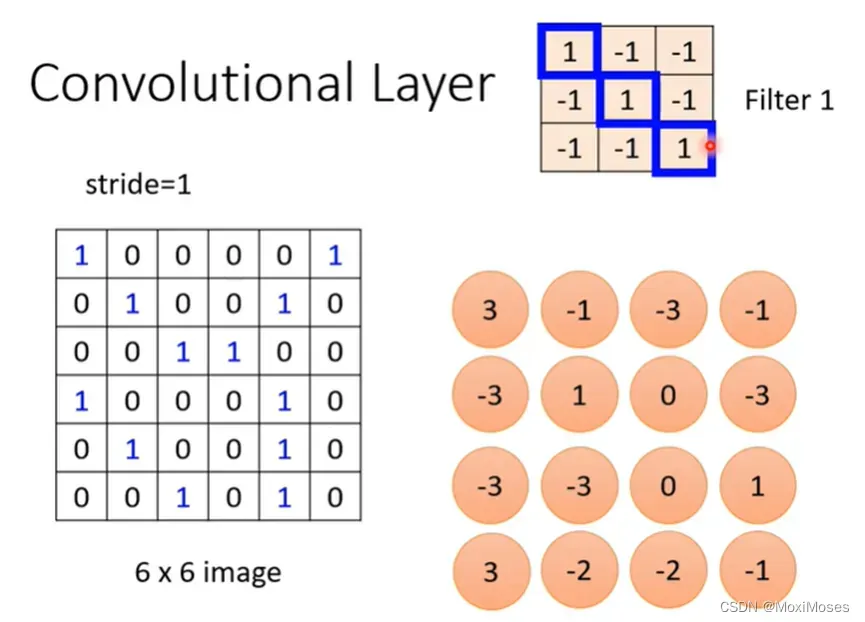
3. 在图片中定义一个stride来分步用图片中的红色区域与filter做内积,得到的结果以矩阵形式表示。
4. 换新的filter重复做上述操作,每一个filter会得到一群数字。如果我们有64个filter,我们就会得到64群的数字,这群数字的名字叫做Feature Map。
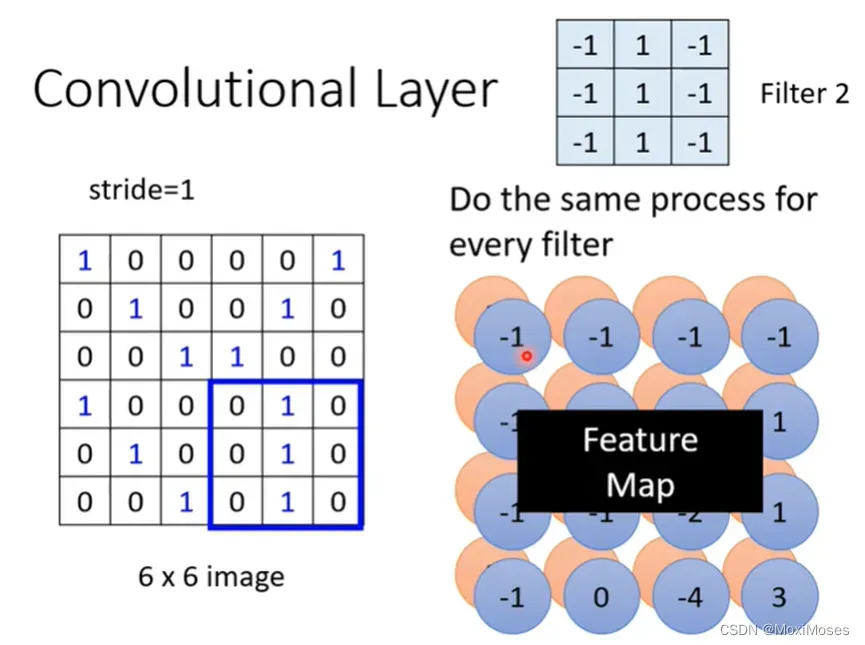
5. Feature Map可以看成一张新的图片,只是这张图片的channel不是RGB,但这张有64个channel,每一个channel对应一个filter。
十、Multiple Convolutional Layers
1. Convolution是可以叠很多层的,也有一堆的filter。
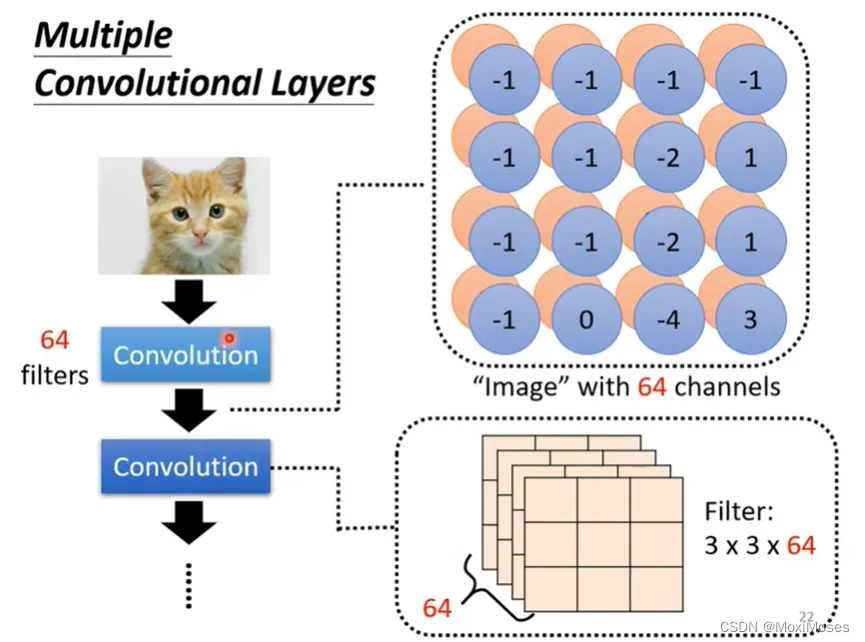
2. 如果filter的大小一直设3*3,是不会影响network看大范围的pattern。只要network够深,我们就不用怕会影响看大范围的pattern。
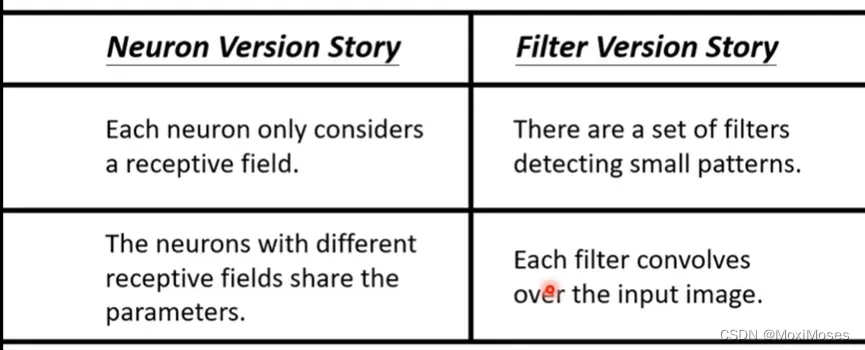
十一、They are the same story
对于neuron的故事而言,neuron只看图片的一小部分,neuron之间可以共用参数;对filter的故事而言,它只看一个小范围,一个filter要扫过整张图片。
十二、Observation 3
我们对图片做Subsampling是不会改变图片中的对象。

十三、Pooling – Max Pooling
每一个filter会产生一组数字,我们把这些数字几个几个分成一组,每一组里面选一个代表,这个代表是最大的那个。选择哪一个有自己决定。
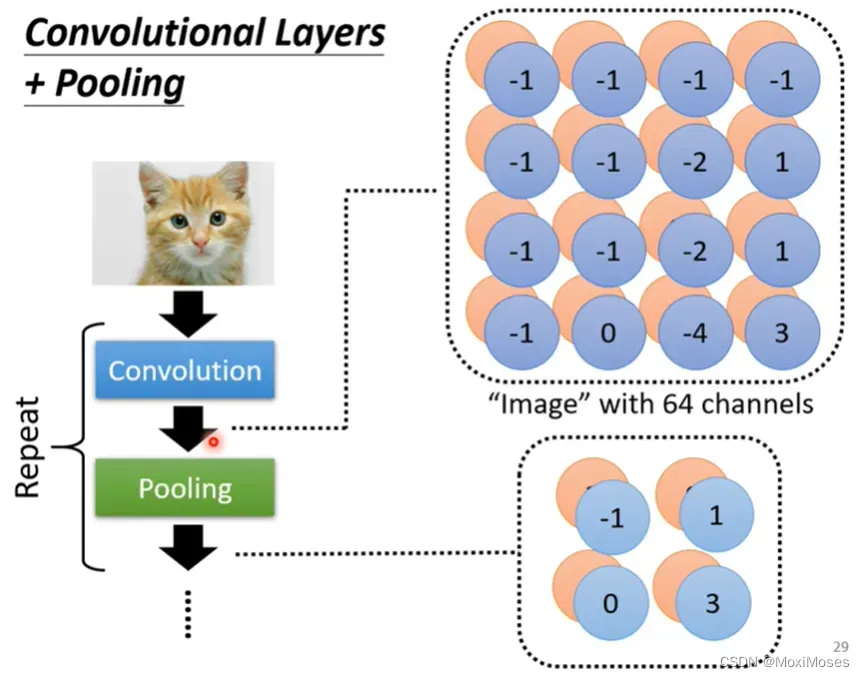
十四、Convolutional Layers + Pooling
如下图所示,pooling是要把图片变小。在实际情况中,convolution和pooling是交替使用的。但是随着计算能力地增强,其实我们不用做pooling。
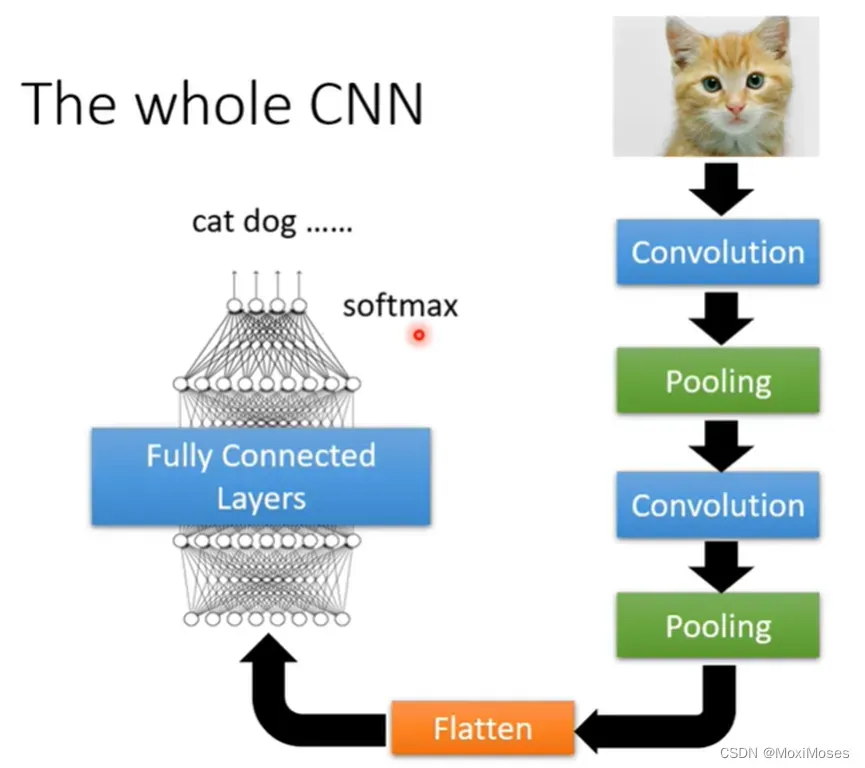
十五、The whole CNN
如下图所示,我们会对pooling的输出做Flatten,Flatten就是把影像里面排成矩阵的数字拉直变成向量,再把向量丢入Fully Connected Layers里面,最后可能做softmax,就会得到影像辨识的结果。
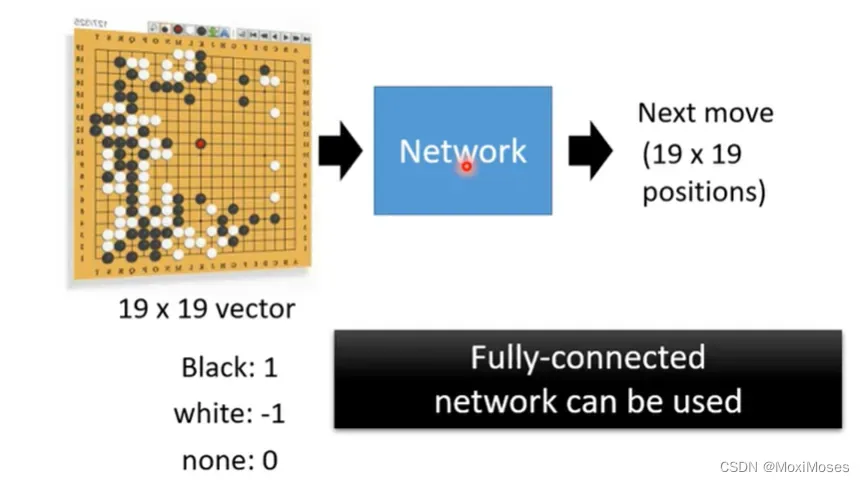
十六、Application:Playing Go
1. Network的输入是棋盘黑子和白子的位置,输出是下一步落子的位置。我们可以用19乘以19的向量来表示棋盘,然后让Network做分类问题,找到最好的位置落子。
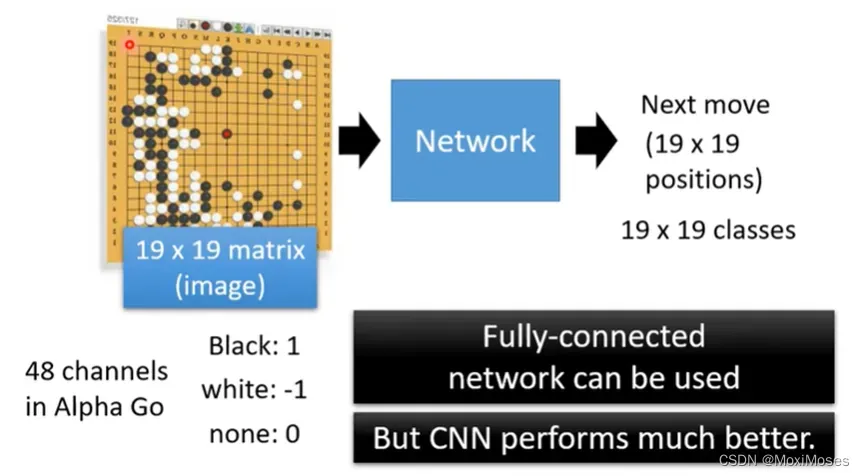
2. 其实用CNN表现会更好。棋盘是一个19乘以19解析度的图片,棋盘上的每一个位置用48个数字表示。
十七、Why CNN for Go playing?
1. 可以用CNN的原因是围棋和影像有共同的特性,很多重要的pattern只需要看小部分范围,相同的pattern可能会出现在不同的位置。
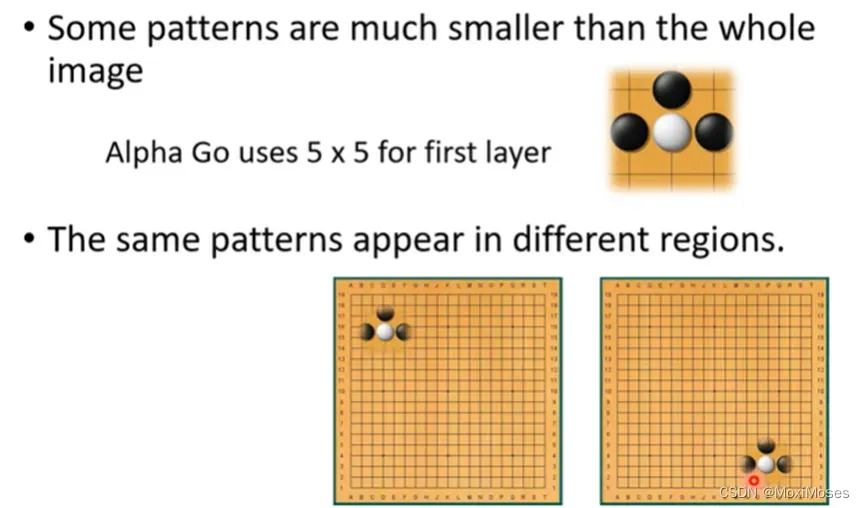
2. subsampling不会影响对图像的判断,但Alpha Go没有使用Pooling。

总结
CNN不能用在影像放大、缩小和旋转上面,需要我们做data augmentation。
文章出处登录后可见!