伊桑CHAT GPT 训练流程
第一步:监督学习
收集人工编写的期望模型是如何输出的数据集,
并使用其来训练一个生成模型(GPT3.5-based)
第二步:训练奖励模型
收集人工标注的模型多个输出之间的排序数据集。
并训练一个奖励模型,以预测用户更喜欢哪个模型输出。
第三步:基于强化学习loss持续迭代生成模型。
使用这个奖励函数,以PPO的方式,微调监督学习训练出来的生成模型。
先讲第一步:
我们需要搜集很多很多的问题,比如什么是香蕉这样的问题。
把这些收集来的问题放到标记者这里,让他们去写这个答案究竟是什么。
然后用这个答案放到superrisemodel.
最终通过GPT3.5微调 。

预计训练了16个epochs,标注了13000多条人工标注的数据,就训练出来了一个监督学习的模型。
第二步模型 ,尤其重要,借用奖励模型去 。
就是把这些标注出来的回答内容 ,拿去做问卷调查 ,把答案做排序。
因为我们知道每个人的想法都是不同的,只有大量的数据结合才能测出更接近人类的想法。
有了这些数据之后,再通过一个模型让他去学习怎么打分。


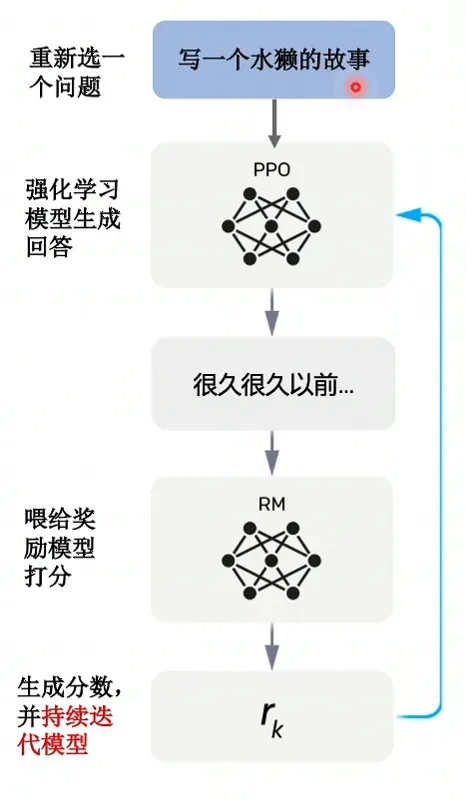
第三步 先去数据库里找到一个问题,比如写一个水獭的故事
接着就把指令喂给强化模型。那强化模型就会根据这段话写 很久很久以前….
接着这段话就会转到第二步,然后出来一个得分。这个得分就会返回去优化这个强化模型。
他就知道当前生成时好还是不好。以上
文章出处登录后可见!
已经登录?立即刷新