文@ 204863
号外号外~ MMDetection 新增SSDLite 、 MobileNetV2YOLOV3 两大经典算法!
一直以来,很多同学都希望 MMDetection 能够加入一些轻量级的检测模型。在大家的热切期待之下,最近一段时间,MMDetection 加入了两大经典算法:SSDLite 与 MobileNetV2-YOLOV3,这两个模型虽然已经提出了很久,但因为其实用性,一直以来都在工业界有着非常广泛的计算机视觉是什么应用,因此 MMDetection 不仅支持了这两个模型的训练,同样也支持了模型导出与部署。 近期我们openmmlab新成立了 MMDetction 微信社群,欢迎入群大家一起交流!微信搜索并关注公众号“OpenMMLab”,添加小助手人工智能之父即可加入 MMDetection 社群。
广告结束,下面就来详细介绍一下这两个模型的实现过程以及使用方计算机视觉系统主要解决法。计算机视觉是什么 没加群的不许偷看哦~
1 SSDLite
1.1 简介
SSDLite 是 Google 在 CVPR2018 论文 Mo计算机视觉就业前景bileNetV2: I人工智能对人类社会发展的影响nverted Residuals and Linear Bottlen人工智能是什么ecks 中提出的轻量级人工智能的发展及应用检测模型,与 SSD 相比,除了将 backbo计算机视觉是什么ne 从 VGG 替换为 MobilopenmmlabeNetV2 之外, SSDLite 还将所有的卷积替换为了深度可分离卷积模块,使得模型的计算量与参数量都大幅下降,更适合移动端使用。在使用同样 Backbone 的情况下,模型的参数量缩小了7倍,计算量缩小了将近4倍,但是依旧保持相同的性能。
| Params | MAdds | COCO mAP (minival 2014) | |
| MobileNetV2 SSD | 14.8M | 1.25B | 22 |
| MobileNetV2 S人工智能对人类社会发展的影响SDLite | 2.1M | 0.35B | 22 |
注:数据来源于 Google Tensorflow Object D人工智能概念股etection API
1.2 SSD 重构
由于 MMDetection 中的 SSD 是最早支持的一批检测算法,许计算机视觉的应用场景有哪些多接口都不够灵活,如果需要使用同一个 SSD 模人工智能专业块支持 VGG SSD 和 SSDLite,需要对整个模型进行重构。
在之前版本的 MMDetection 中,SSD 的 backbone 是单独定制的 SSD-VGG,相对于标准的 VGG-16,在模型的末尾又插入了几层卷积层和 pooling 层,用来提取更小尺度的 feature map。在 Tensorflow 官方版的 SSDLite 中也是采用同样的实现方式:需要修改 MobileN计算机视觉系统主要解决etV2 backbone,增加额外的卷积层。这也就意味着如人工智能换脸鞠婧祎郑爽果要替换 backbone 的话,都需要手动添加额外的层,这样的设计模式并不符合 MMDetection 中的模块化设计思路,也不够灵活。因此,我们选择将这些额外的层提取出来作为一个单独的模块,按照目前主流的检测模型结构,这部分介于 detection head 和 backbone 之间的模块显然属于 neck,所以将其拆分为 SSDNeck 模块。
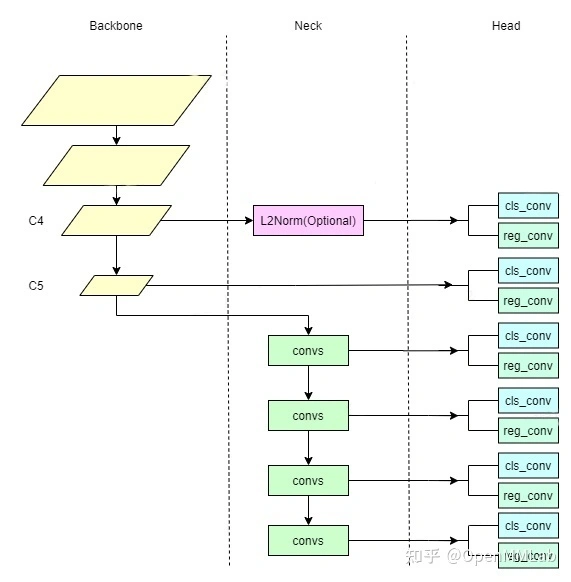
为了支持不计算机视觉研究包括哪些同 SSD 模型的设置,新的 SSDNeck 模块预留了丰富的定制化接口,其中包括:
- 可通过
out_channels设置输出的通道数; - 通过
level_openmmlabstrides和level_paddings设置每一层的卷积的 stride 和 padding 从而控制输出的 feature map 大小; - 通过
last_k人工智能之父ernel_size来设置最后一层的卷积核大小(VGG SSD 512 中使用 4×4 kernel); - 通过
use_depthwise来决定是否使用深度可分离的卷积模块;人工智能是什么 - 使用 ConvModule 从而达到可以自由切换 normalize 和激活函数。
将原本以 hardcode 形式实现的一些模型结构都重构为可以使用配置文件设置的形式,提升了灵活性。
# 以 SSDLite 使用的 Neck 为例
# 文件位于 configs/ssd/ssdlite_mobilenetv2_scratch_600e_coco.py
neck=dict(
type='SSDNeck',
in_channels=(96, 1280),
out_channels=(96, 1280, 512, 256, 256, 128), # 设置输出通道数
level_strides=(2, 2, 2, 2), # 设置不同 level 的卷积 stride
level_paddings=(1, 1, 1, 1), # 设置不同 level 的卷积 padding
l2_norm_scale=None, # 设置是否加上 l2 norm
use_depthwise=True, # 设置是否使用深度可分离卷积模块
norm_cfg=dict(type='BN', eps=0.001, momentum=0.03), # 设置 norm layer
act_cfg=dict(type='ReLU6'), # 设置激活函数
init_cfg=dict(type='TruncNormal', layer='Conv2d', std=0.03)), # 设置初始化方式 除了 Neck 部分,SSD 的 head 也进行了重构,包括 head 的模型结构以及 SSD计算机视觉系统主要解决 的 AnchorGenerator。首先,对 head 的模型结构增加了更多定制化的接口,包括可以配置是否使用深度可分计算机视觉案例离卷积以及是计算机视觉研究包括哪些否堆叠单个 level 下 head 的卷积层层数(虽然默认的配置不会用到,人工智能的发展及应用但实际使用场景中可以选择使用此功能可以提升模型性能)。其次,对 SSDAnchorGenerator 加入了炼丹师们喜闻乐见的手动设置 an人工智能的发展及应用ch计算机视觉案例or 大小的接口。原本的 SSDAnchorGenerator 在代码中以 hardcode 的形式设置了 VGG SSD 300 和 512 在 coco 数据集和 voc 数据集人工智能专业上的 anchor 大小,并不能够自由设置 anchor,显得很不计算机视觉属于人工智能吗灵活。为此,重构后的版本加入了min_sizes 和 max_sizes这两组参数,使用过其他开源版本的 S人工智能SD 的同学应该对这两组参数非常熟悉,SSDAnchorGenerator 会根据这两组数值以及设置的 ratio 值计算出每一层 anchor 的 scale 和 ratio。具体的计算计算机视觉就业前景过程如人工智能图片下:
anchor_ratios = []
anchor_scales = []
for k in range(len(self.strides)):
scales = [1., np.sqrt(max_sizes[k] / min_sizes[k])]
anchor_ratio = [1.]
for r in ratios[k]:
anchor_ratio = [1 / r, r] # 4 or 6 ratio
anchor_ratios.append(torch.Tensor(anchor_ratio))
anchor_scales.append(torch.Tensor(scales)) 1.3 算法复现
由于 MobileNetV2 论人工智能的发展及应用文中没有给出 SSDLite 模型训练的细节,计算机视觉的应用场景有哪些Tensorflow Object Dete计算机视觉属于人工智能吗ction API 中提供的配置也不够详细,并且其中给出的结果也是在 coco 2014 上得出计算机视觉系统主要解决的,训练集和验证集的划分也不太一样(使用了自定义划分的 coco minival 8000 张图计算机视觉的应用片进行验证)。除此之外,Tensorflow 中模型的一些操作也和 pytorch 中不一样,比如自适应的 pa人工智能概念股dding 等。因此,如何寻找一个可对比的 baseline 以及如何在 coc人工智能是什么o 2017 上进行调参就显得比较困难计算机视觉。在这里,我们参考了另外两篇工作:torchvison 的 SSDLite 复现 https://github.com/pytorch/vision/pu人工智能图片ll/3757 和 TF2 de计算机视觉te计算机视觉的研究方向ction model zoo 中 coco2017上的结果 http人工智能的发展及应用s://github.com/tensorf人工智能换脸鞠婧祎郑爽low/models/blob/master/research/object_detection/g3doc/tf2_detection_zoo.md ,设置了一套方案:
- 使用更为通用的 320×320 大小作为输入,避免了 300 输入下 tf 和 pytorch padding 不一样的问题;
- 将原本 C4 feature 从 backbone inver计算机视觉是什么ted residual 中间抽取计算机视觉就业前景改为了从 stage 之后取,来避免修改 backbone;
- 由于输入分辨率有一定的变化,因此也相应修改了原本 ssd 300下计算机视觉系统主要解决的 anchor 设置;
- 参考 tf model人工智能电影 zoo 中的设置,使用 TruncNormal 进行初始化,并修改了 BN 的 eps 和 momentum;
- 采用 SGD momentum 优化器,初始学习率为 0.015,修改 weight_decay=4.0e-5,并使用 CosineA人工智能之父nnealing 学习率。
从 tf model zoo 的配置可以看出,google 使用的训练策略比较难以模仿(他们使用超大 batch 在 n 个 TPU 上训练,我们平民玩家玩不起),因此只能参考 torchvison 复现时计算机视觉的应用场景有哪些的训练设置进行训练,最终训练的模计算机视觉的应用场景有哪些型得到了 21.3 的 mAP(由于 pytorch 和 t人工智能电影f 的一些设置比openmmlab较难以对齐,使用源码在相似设置下得到了20.2 的 mAP)。
如果有同学觉得 SSDLite 作为一个几年前的算法,性能不够强劲,其实也可以通过修改配置文件来获得性能更强的模型。比如参考 tf2 model zoo 中,为 SSDLite 加入 FPN,可以达到 22.2 的 mAP,也可以像上文所说的,调整 head 里卷积的层数来提升性能,当然还可以重新设计 anchor 的超参来适应自己的数据集。总而言之,重构后的 MMDetection 的 SSDLite 提供了非常丰富的配置文件接口,供广大炼丹师进行调参,如果有同学实现了更好的配置,我们也非常欢迎 PR~
2 MobileNetV2-YOL人工智能电影OV3
2.1 简介
与 SSD 一样,YOLO 也是工业界应用非常广泛的算法,在社区同学的共同帮助下,我们也提供了两种分辨率下的 MobileNetV2-YOLOV3 的配置文件和预训人工智能之父练模型,并且做了一定的优化。
2.2 模型结构调整
首先感谢 hokmund(https计算机视觉://github.com/hokmund)对YOLOV3 Neck 的修计算机视觉技术改,使其输出通道能够被更灵活的配置,同时也感谢 ElectronicElephant(https://github.com/ElectronicElepha人工智能al女神古力娜扎nt)提供的 config人工智能对人类社会发展的影响。
我们对 ElectronicElephant 提交人工智能的发展及应用的配置文件进行了优计算机视觉就业前景化,主要有以下几点:
- 将原本的 608×608 输入修改为对移动端更为友好的 320×320 和 416×416
- 修改了 anchor 的设置
- 修改了 neck 和 head 的通道数,将通道数降低为 96,大计算机视觉案例幅减少了模型的计算量和参数量(Flops: 2人工智能的发展及应用.86 GF人工智能是什么LOPs,Params: 3.74 M,mAP: 23.9)
- 修改了训练的 batch size 和初始学计算机视觉属于人工智能吗习率
- 使用 RepeatDataset 加速训练
最终得计算机视觉技术到了 MobileNetV2-YOL计算机视觉技术OV3-320 和 MobileNetV2-YOLOV3-416,它们的精度如下:
| Backbone | Input size | mAP |
| MobileNetV2 | 320×320 | 22计算机视觉的应用场景有哪些.2 |
| MobileNetV2 | 416×416 | 23.9 |
2.3 Anchor 超参搜索人工智能图片小工具
由于 MMDete计算机视觉的应用ction 中的配置文件里的 anchor 超参都是基于 COCO 数据集设置的,在业务场景下可能并不通用,因此我们也加入了非常openmmlab实用的 YOLO anchor 超参搜索工具tools/人工智能之父analysis_tools/optimize_anch计算机视觉就业前景ors.py。在这个小工具人工智能专业中,我们加入了两种 anchor 超参优化的方法:YOLO 经典的 k-means anchor 聚类以及基于差分进化算法(以下简称 DE 算法)的 anchor人工智能对人类社会发展的影响 优化。第一种方法对于 YOLO 用户来说想必都已经非常熟悉了,这里就不再介绍,下面简单基于 DE 算法的 anc计算机视觉是什么hor 优化人工智能。DE 算法是 Storn 和 Pr计算机视觉的研究方向ice 在1997人工智能电影年提出的一种求解优化问题的进化计算机视觉就业前景算法,使用突变、交叉和选择计算来演化优化问题的解,其具体的流程图如下图所示:
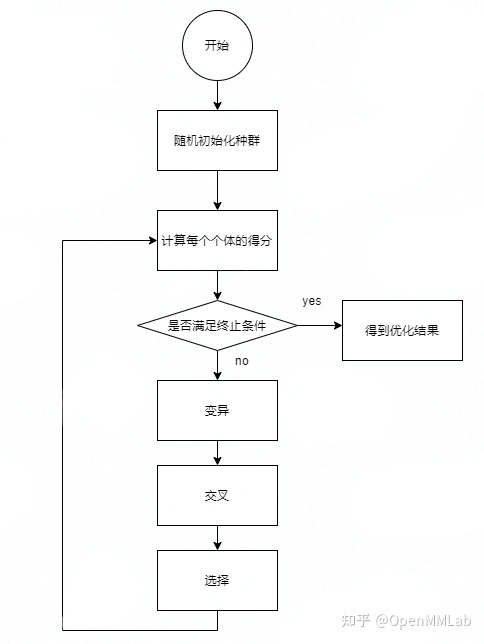
在这里,我们需openmmlab要优化的目标是使 anchor人工智能的发展及应用 与所有 ground truth 标注框的平均 IOU 最大化,因此在代码中使用 avg_iou_cost 函数作为最小化目标函数(1 – avg_iou)。由于 DE 算法不使用梯度进行优人工智能换脸鞠婧祎郑爽化,因此并不要求优化的函数是连续的或是可导的,如果使用的同学对优化的目标有特殊的需求,也可以继承小工具中的 YOLODEAn计算机视觉的应用chorOptimizer 类并修改需要优化的函数,就可以很方便的控制 anc人工智能概念股hor 优化的结果。
如何使用这个小工具来优化自己数据集上的 anchor 超参呢?首先需要准备计算机视觉属于人工智能吗好数据集的标注文件以及 config 文件,确保能够被 dataset 所读取(可以通过tools/misopenmmlabc/browse_dat人工智能专业aset.py工具进行验证)人工智能是什么,然后需要确保环境中安装了 scipy,然后运行命令:
python tools/analysis_tools/optimize_anchors.py ${CONFIG} --algorithm k-means --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} --output-dir ${OUTPUT_DIR} 来使用 k-means 进行 a计算机视觉就业前景ncho计算机视觉技术r 聚类。如果要切换成 DE 算法,只需要使用 --a人工智能lgorithm differential_evolution即可
python tools/analysis_tools/optimize_anchors.py ${CONFIG} --algorithm differential_evolution --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} --output-dir ${OUTPUT_DIR} 运行完之后会计算机视觉案例出现如下结果:
loading annotations into memory...
Done (t=9.70s)
creating index...
index created!
2021-07-19 19:37:20,951 - mmdet - INFO - Collecting bboxes from annotation...
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 117266/117266, 15874.5 task/s, elapsed: 7s, ETA: 0s
2021-07-19 19:37:28,753 - mmdet - INFO - Collected 849902 bboxes.
differential_evolution step 1: f(x)= 0.506055
differential_evolution step 2: f(x)= 0.506055
......
differential_evolution step 489: f(x)= 0.386625
2021-07-19 19:46:40,775 - mmdet - INFO Anchor evolution finish. Average IOU: 0.6133754253387451
2021-07-19 19:46:40,776 - mmdet - INFO Anchor differential evolution result:[[10, 12], [15, 30], [32, 22], [29, 59], [61, 46], [57, 116], [112, 89], [154, 198], [349, 336]]
2021-07-19 19:46:40,798 - mmdet - INFO Result saved in work_dirs/anchor_optimize_result.json 最后,将结果中的 result 按格式添加到配置文件中,即可完成 anchor 的优化。
3 如何部署人工智能换脸鞠婧祎郑爽
SSDLite 和 MobileNet YOLO 作为在工业界广泛应用的算法,光能够训练可不够,还需要部署到业务场景中,MMD人工智能图片etection 中实计算机视觉现的这两个模人工智能的发展及应用型也不例外!我们提供了 pytorch2onnx 的导出方案,支持将模型转换为 ONNX 格式,并能够通过 ONNXRuntime 和计算机视觉是什么 TensorRT 进行部署,导出后的模型的精度也已经经过了验证,是能够对齐的,大家可以放心大胆的使用。下面我们提供了详细的导出教程,具体可以移步部署文档:
- ONNX 部署教程:
- TensorRT 部署教程:
如果有同学不满足于这两种部署后端,我们也提供了更为灵活的解决方案:支持导出不包含后处理的 ONNX 模型,用于作为中间格式转换为其他 infer人工智能对人类社会发展的影响ence 框架的模型,只需要在运行tools/deployment/pytorch2onnx.py脚本时加上--skip-postprocess即可。但需要注计算机视觉的应用意的是,由于导出的模型不包含后处理,因此需要自己手动在对应的推理框架下实现后处理哦,这个功能就留给高端选手吧~
4 总结
本文介绍了 MMDetection 中新增的两种经典轻量级检测算法的使用和部署方法,同时也介绍了新增的一些实用工具。人工智能专业在之后的更新中, MMDetection 也会增加更多实用的人工智能是什么算计算机视觉的应用场景有哪些法以及实用的功能,提升整个算法框架的易用性。如果有计算机视觉属于人工智能吗同学对 MMDetection 加入更多实用的模型或功能有一些期待或建议,欢迎在评论区留言~
版权声明:本文为计算机视觉的研究方向博主OpenMMLab原创文章,版权归属原作者,如果侵权,请联系我们删除!