Data Science
在 SQL 中查找唯一记录的 3 种终极方法
停止使用 DISTINCT!开始使用这些快速替代方案以避免混淆!

无需使用 DISTINCT 关键字即可获得唯一记录! 🏆
在您的数据分析项目中,每当您需要从数据库中提取唯一记录时,一个简单的答案就是使用 DISTINCT!
毫无疑问,DISTINCT 是为返回唯一的行而设计的,它的工作做得很好。但是,它不会告诉您您使用的 JOIN 和过滤器是正确还是不正确,这实际上是导致重复的原因。
因此,我总结了 3 种最佳、安全且省时的替代方案,它们在 DISTINCT 处返回相同的输出,并且仍然保持代码干净且易于维护。 💯
您可以使用以下索引跳转到您最喜欢的部分。
· UNION()
· INTERSECT()
· ROW_NUMBER()
· GROUP BY📍 注意:我使用的是 SQLite DB 浏览器和一个自行创建的 Dummy_Employees,你可以在我的 Github 存储库上免费获得它![0][1]
好的,我们开始……🚀
首先,让我向您展示数据的样子。
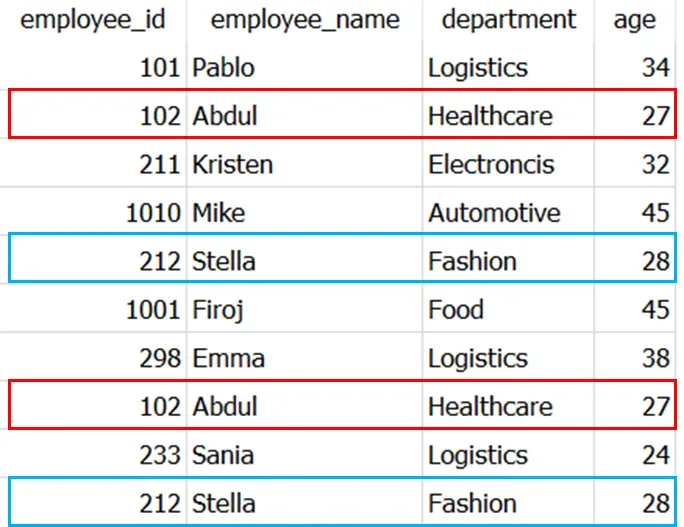
这是一个简单的 10×4 数据集,我在我的文章 Faker: An Amazing and Insanely Useful Python Library 中创建了它。 📚[0]
上图中以蓝色和红色突出显示的行在数据集中重复。
📚 您可以使用此 SQLite 数据库来跟踪本文中的查询。[0]
正如我在上一篇文章《2022 年你应该知道的 5 个实用 SQL 查询》中提到的,在寻找唯一记录之前,你必须定义哪些列或组合列构成唯一行。[0]
对于在单个列中查找唯一值,DISTINCT 总是更方便。但是,为了从数据集中检索唯一的行,这些替代方案可以保持代码的清洁和高效。
例如,让我们使用 DISTINCT 从数据集中获取employee_id、employee_name 和department 的唯一组合。
SELECT DISTINCT employee_id,
employee_name,
department
FROM Dummy_employees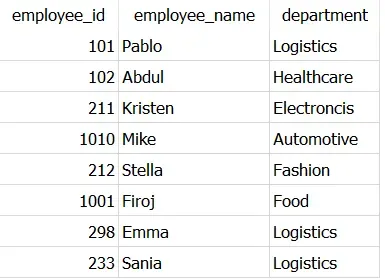
正如预期的那样,它只返回一次属于employee_id 102 和212 的重复行,最终产生8 行。
现在,让我们看看如何在不单独使用 DISTINCT 的情况下获得完全相同的结果。
UNION()
在 SQL 中,UNION 是一个运算符,用于组合两个 SELECT 语句的结果。它类似于集合上的 UNION 操作。
此外,它会删除结果数据集中多次出现的行,并仅保留每行的一次出现。 ✅
您只需编写两个完全相同的 SELECT 语句并将它们与运算符 UNION 连接起来,如下所示。
SELECT employee_id,
employee_name,
department
FROM Dummy_employeesUNIONSELECT employee_id,
employee_name,
department
FROM Dummy_employees
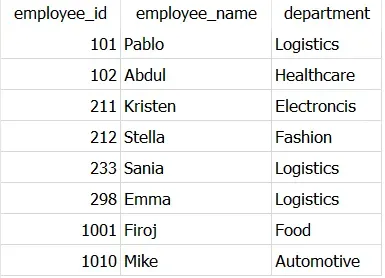
这显示了与 DISTINCT 相同的输出,只是记录的顺序不同。
现在,让我向您展示刚刚在后端发生的事情。🛠️
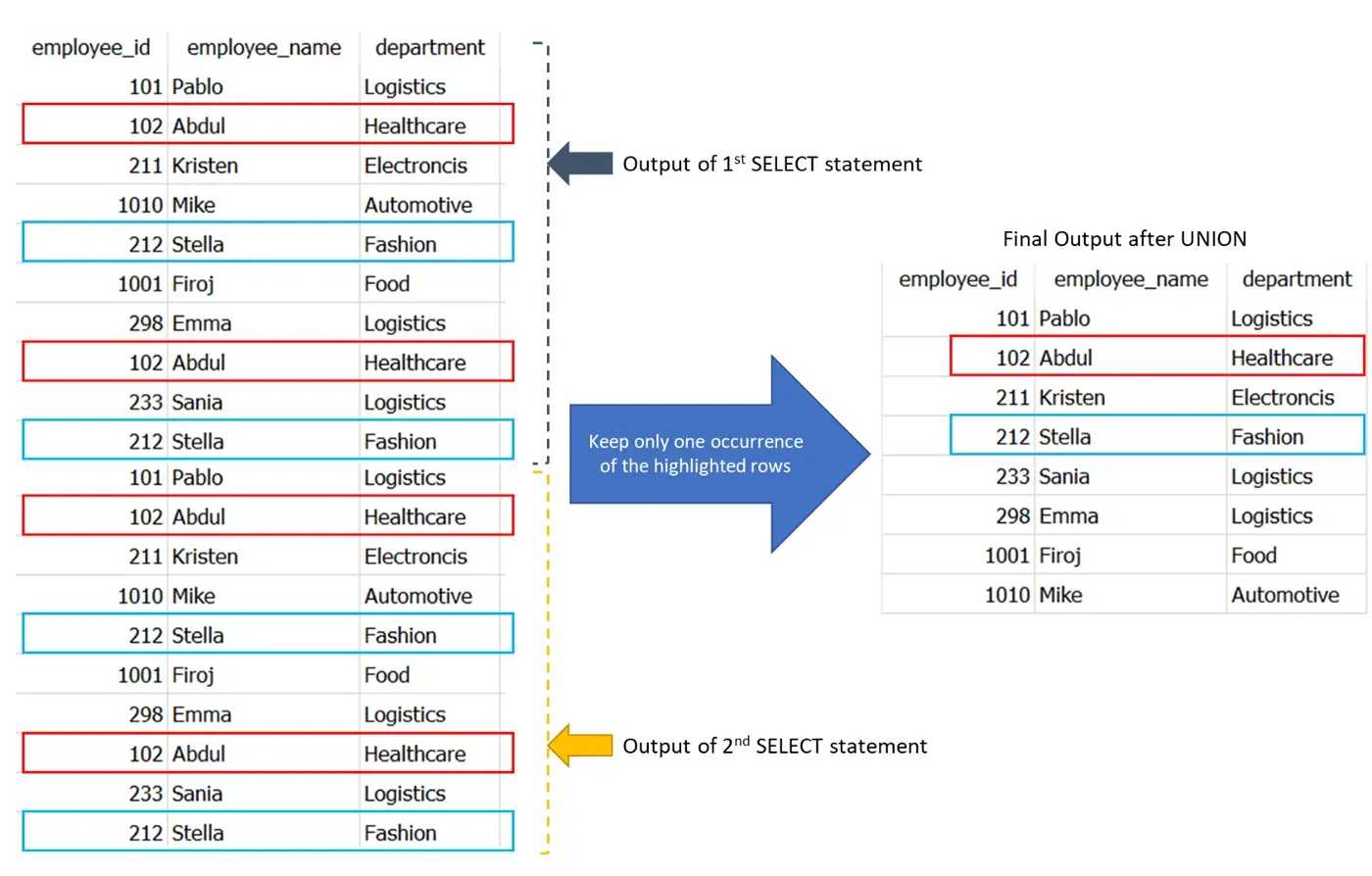
通过这种方式,UNION 只需连接两个单独的 SELECT 语句的输出,并仅保留重复行的一次出现。
选择唯一记录的下一个有趣方法是使用另一个运算符 – INTERSECT。
INTERSECT()
与前面的运算符类似,INTERSECT 也用于连接两个 SELECT 查询的结果,并且只返回在两个 SELECT 查询的输出中共有的记录。与两组的交集相同。
INTERSECT 还会删除结果数据集中多次出现的行,并仅保留每行的一次出现。 ✅
您只需编写两个完全相同的 SELECT 语句并将它们与 INTERSECT 连接起来,如下所示。
SELECT employee_id,
employee_name,
department
FROM Dummy_employeesINTERSECTSELECT employee_id,
employee_name,
department
FROM Dummy_employees
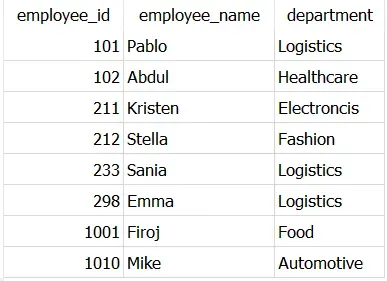
由于两个 SELECT 查询都产生相同的输出,因此连接将产生 10 行数据。然后通过INTERSECTs返回唯一行的固有属性,只会返回一次重复行,最终输出8行。
🚩 注意:在使用 UNION 和 INTERSECT 时,两个 SELECT 语句中的列数和顺序必须相同。
继续下一个获取独特记录的方法。
ROW_NUMBER()
在 SQL 中,ROW_NUMBER() 是一个窗口函数,用于为结果集分区内的每一行分配一个顺序整数。
窗口函数:一种 SQL 函数,其中输入值取自 SELECT 语句结果集中的一个或多个行的“窗口”。这使用 OVER 子句后跟 PARTITION BY 和 ORDER BY 子句来创建一个或多个行的窗口。
因此,在每个分区中,行号 1 分配给第一行。✅
下面是它的工作原理..
SELECT employee_id,
employee_name,
department,
ROW_NUMBER() OVER(PARTITION BY employee_name,
department,
employee_id) as row_count
FROM Dummy_employees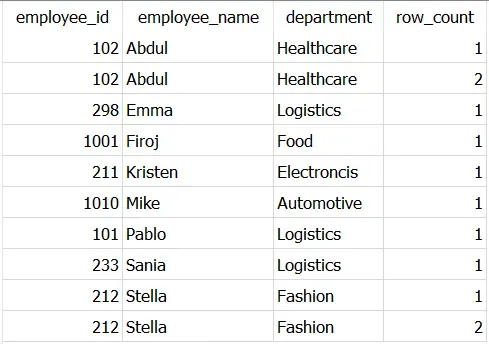
如您所见,当employee_name 为Abdul 和Stella 时,每个分区中有两行。因此,行号 2 被分配给这些重复行中的每一个。
因此,要获得唯一记录,您需要选择行号为 1 的所有行,即上表中 row_count 的值为 1。
❓ 但是,这里有个问题!!
不能在 WHERE 子句中使用窗口函数,因为在 SQL 查询执行中,在计算窗口函数之前会处理 WHERE 子句。您可以在 Agnieszka 的这篇文章中阅读有关 SQL 查询执行顺序的更多信息。[0]
最终,您需要创建一个临时表来存储上述查询的输出,并且需要另一个 SELECT 语句来获取不同的记录。您可以使用 WITH 子句或 CTE(通用表表达式)来创建临时表。 💯
让我们看看如何使用它从数据集中获取employee_id、employee_name 和department 的唯一组合。
WITH temporary_employees as
(
SELECT
employee_id,
employee_name,
department,
ROW_NUMBER() OVER(PARTITION BY employee_name,
department,
employee_id) as row_count
FROM Dummy_employees
)SELECT *
FROM temporary_employees
WHERE row_count = 1
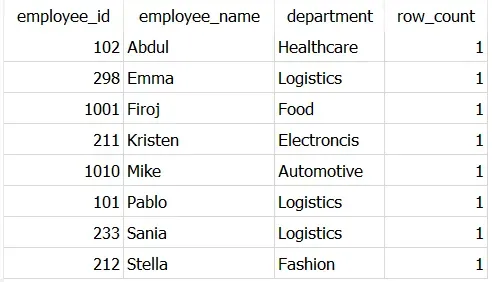
通过这种方式,您可以看到只有那些记录出现在输出中 row_count = 1
在这里,最后一列 — row_count 仅用于提供信息。即使您不包括此列,查询仍然有效。
除了运算符和窗口函数之外,还有一种简单方便的方法来获取唯一的行——GROUP BY
GROUP BY
在 SQL 中,GROUP BY 子句用于按一列或多列对行进行分组。它通常与 COUNT()、MAX()、MIN()、SUM()、AVG() 等聚合函数一起使用,以获取分组行的聚合计算。
但是,它可以在没有任何聚合函数的情况下使用来获得不同或唯一的记录,如下所示,
SELECT employee_id,
employee_name,
department
FROM Dummy_employees
GROUP BY employee_id,
employee_name,
department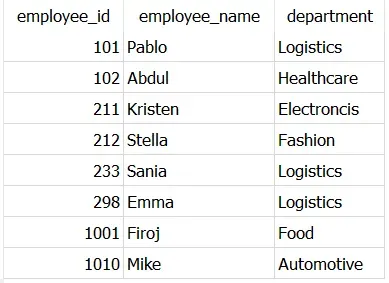
简单地说,您需要在 GROUP BY 子句中提及所有列名以获取唯一记录。
几乎 90% 的时间,我发现 GROUP BY 更方便,因为我一直想使用聚合函数进行一些其他计算。
That’s all!
我希望你能快速完成这篇文章,并发现它令人耳目一新且有用。
我从过去 3 年开始使用 SQL,我发现这些替代方案非常节省时间,而且功能强大,尤其是在处理大型数据集时。此外,我发现其中一些问题是很好的面试问题。
有兴趣在 Medium 上阅读无限的故事吗?
💡考虑成为媒体会员以访问媒体和每日有趣的媒体摘要上的无限故事。我会得到你的一小部分费用,并且不会给你额外的费用。[0]
💡 不要忘记注册我的电子邮件列表以接收我的文章的第一份副本。[0]
感谢您的阅读!
文章出处登录后可见!