资源下载地址:https://download.csdn.net/download/sheziqiong/85638156
1.背景及目的
疫情爬取及数据可视化
2020年的疫情对于全世界来说都是一个痛苦的回忆,3月份开始首先在我国爆发,后期在国外更是呈现指数式增长,截至今日,全球的疫情还未根除!为了有效的观察世界疫情局势的变化,我们通过Python爬虫和简单的数据可视化将疫情情况通过图片的形式展示出来从而更方便的帮助大家了解局势,以及做好应对措施!
数据资源的获取与分析
本次采用python的requests模块从腾讯疫情网站抓取世界每日疫情变化数据,抓取的数据包括新增死亡、新增治愈、新增确诊以及对应的日期,另外我们也关注世界累计人数,这对于宏观调控也有很大的帮助,抓取的数据有累计死亡、累计治愈、累计确诊以及对应的日期信息!
2.Python程序方案设计
包括以下内容:
-
Python程序设计总体目标
首先会抓取页面的相关数据信息,将所有信息抓取到后,通过调用对应的函数画出对应的折线图和柱状图,然后存放到新建的文件夹(疫情图片)中!
-
Python程序设计总体方案(附总体方案流程图)
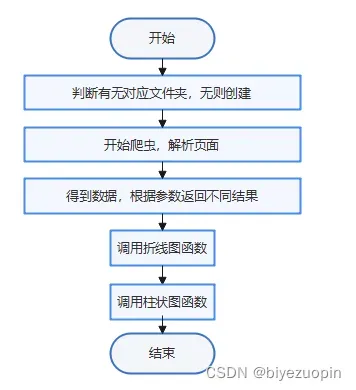
- 总体方案中各组成部分的功能说明
3.Python程序编程实现
Python编程环境说明 (Python程序开发平台及开发工具)
Python程序设计功能实现
数据导入
通过requests爬取腾讯疫情页面以及通过response.json()按照字典规则进行提取对应属性的数据,通过append()方法把所有同属性的数据存放到一个相同的列表中,方面后面return给别画图函数进行画图!
数据预处理
因为疫情时间太长,如果把每天的数据都保存的话,画图的时候会导致画布整体密集,融合在一起,非常不雅观!于是使用if (I % 30 == 0)语句来每隔30个数据选取一个,这样做既能保证疫情发展总体趋势不变,同时方便画图清晰的展示坐标轴情况!
整体性能测试
因为爬取的数据量不大,加上腾讯疫情的反爬机制不强,所以没有采用多线程以及其他的反爬策略,整个程序运行时间也就20s左右!
4.Python程序设计总结
系统运行环境配置
计算机配置:Windows10/Pycharm
系统实现方式和结果
爬取相应数据及返回处理后数据
程序代码及详细注释
def data_spyder(number):
# 定义新变量,接收传进的参数
num = number
# 经过分析网页获取到的数据接口
url = 'https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=chinaDayList,chinaDayAddList,cityStatis,nowConfirmStatis,provinceCompare'
response = requests.get(url=url)
# 万能解码,使中文不会以乱码的形式展现
response.encoding = response.apparent_encoding
# 接口的数据是json格式的
html = response.json()
"""下面的代码是获取每天的新增的数目"""
day_add_datas = html['data']['chinaDayAddList']
# 使用列表的append方法将对应种类的新增数目添加到各自的列表中,以便于后面的可视化操作
day_deads = [] # 新增死亡
day_heals = [] # 新增治愈
day_dates = [] # 日期
day_confirms = [] # 新增确诊
# 如果数据全部存在列表中,最后绘图时密密麻麻,于是隔30天写入一次
for i in range(len(day_add_datas)):
if (i % 30 == 0):
day_deads.append(day_add_datas[i]['dead'])
day_heals.append(day_add_datas[i]['heal'])
day_confirms.append(day_add_datas[i]['confirm'])
day_dates.append(day_add_datas[i]['date'])
"""下面的代码是获取当天的各种累计数目"""
day_datas = html['data']['chinaDayList']
# 同样的操作,将各种栏目的数据添加到对应的列表中
deads = []
heals = []
dates = []
confirms = []
运行结果及分析
成功爬取相应数据,通过给定number不同的值以获取不同的返回数据进行可视化展示
#### 画折线图
1.流程及操作步骤说明:
程序运行后可画出对应的新增/累计三项数据折线图
2.程序代码及详细注释
```python
day_dates, day_deads, day_heals, day_confirms = data_spyder(2)
titles = ['日期','新增死亡数','新增治愈数','新增确诊数']
datas = [day_dates,day_deads,day_heals,day_confirms]
for i in range(1,len(titles)):
plt.plot(day_dates,datas[i],label="每日{}".format(titles[i]),linewidth=3,color='r',marker='o',markerfacecolor='blue',markersize=12)
plt.xlabel('日期')
plt.ylabel(titles[i])
plt.title('每日{}'.format(titles[i]))
# 使中文可以正常显示出来
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.legend()
plt.savefig(path + '/' + titles[i] + '_折线图.jpg')
3.运行结果及分析
运行该程序后会在【疫情图集】文件夹下面生成柱状图
5.完整结果展现
Pycharm终端截图:
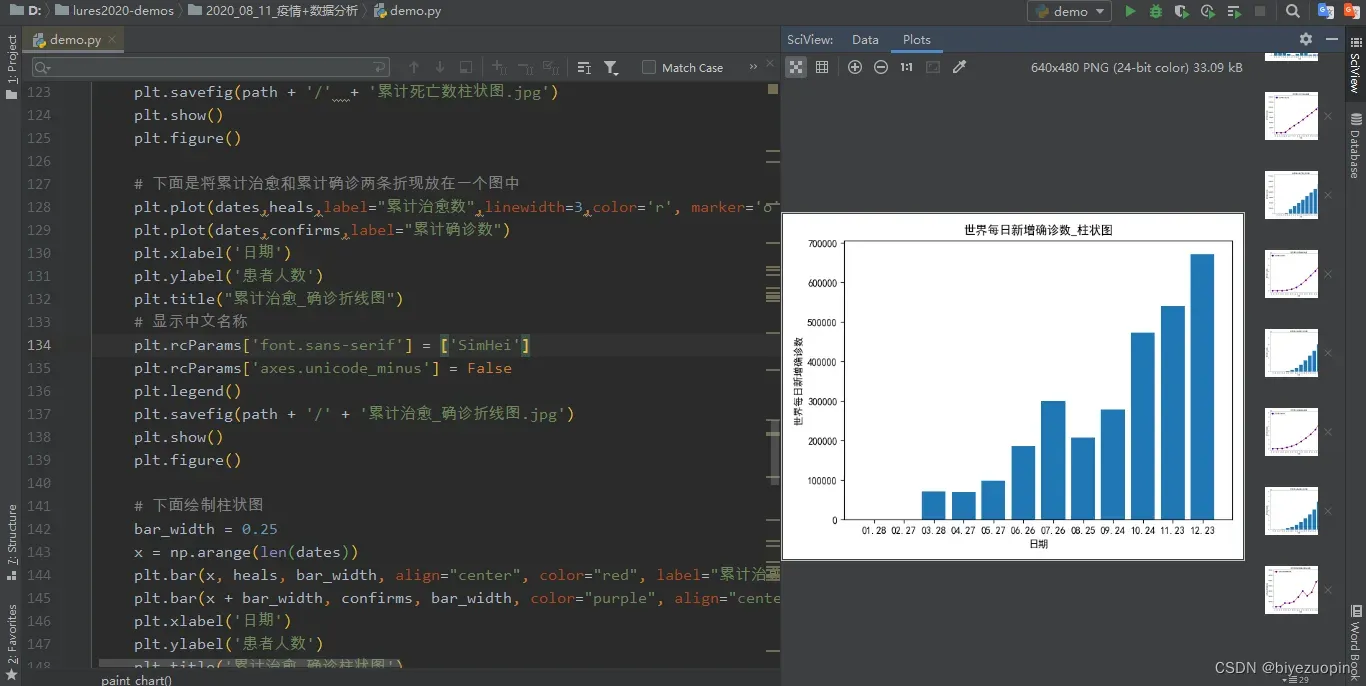
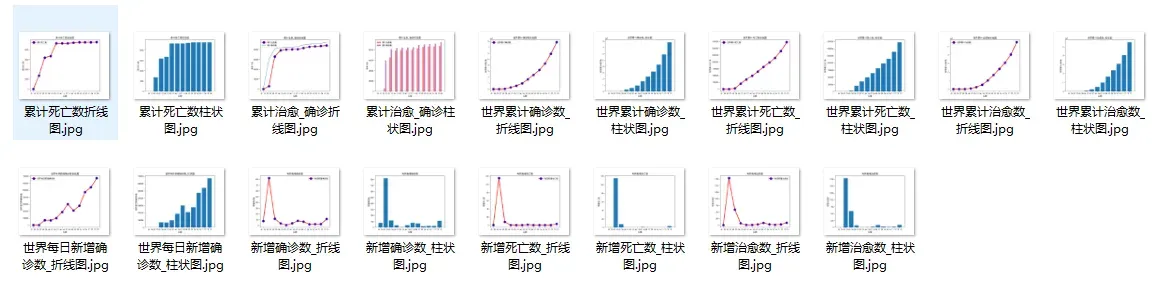
效果截图:
资源下载地址:https://download.csdn.net/download/sheziqiong/85638156
文章出处登录后可见!