

任务1.1
1、数据导入
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import random
plt.rcParams['font.family'] = 'SimHei' # 正常显示中文
plt.rcParams['axes.unicode_minus'] = False
data1 = pd.read_csv('data1.csv',sep=',',encoding='gbk')
data1.columns =['序号','校园卡号','性别','专业名称','门禁卡号']
data2 = pd.read_csv('data2.csv',sep=',',encoding='gbk')
data2.columns=['流水号','校园卡号','学号','消费时间','消费金额','充值金额','余额',
'消费次数','消费类型','消费项目编码','消费项目序号','消费操作编码','操作编码','消费地点']
data3 = pd.read_csv(r'data3.csv',sep=',',encoding='gbk')
data3.columns =['序号','门禁卡号','出入日期','出入地点','进出成功编号','通过权限']data1:
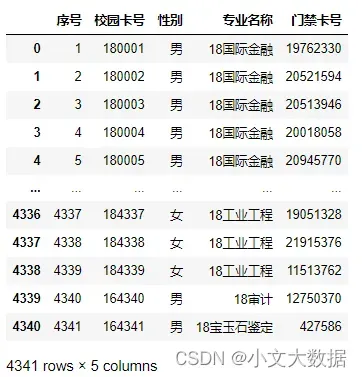
data2:
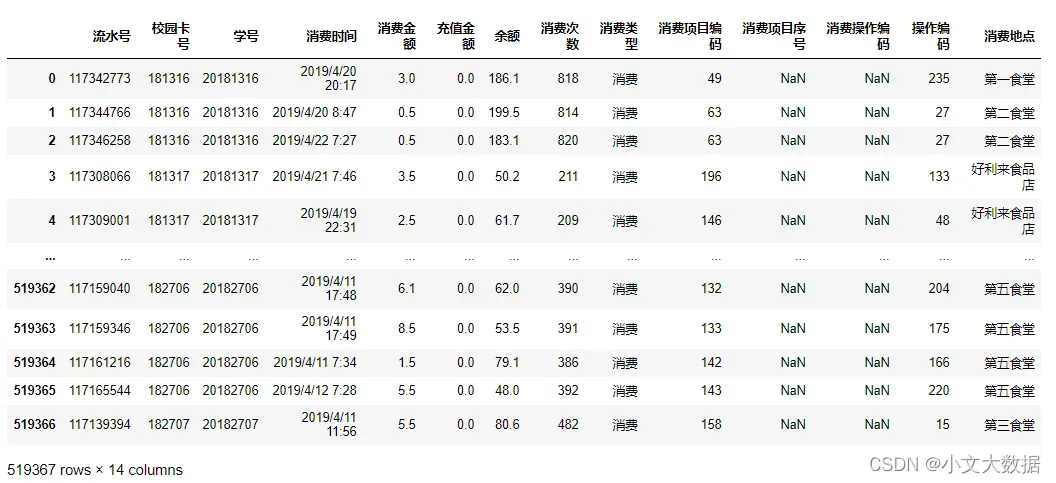
data3:
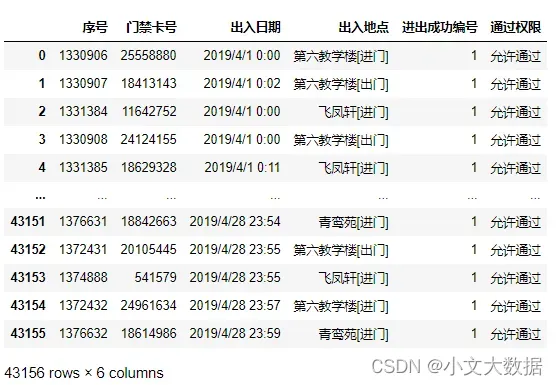
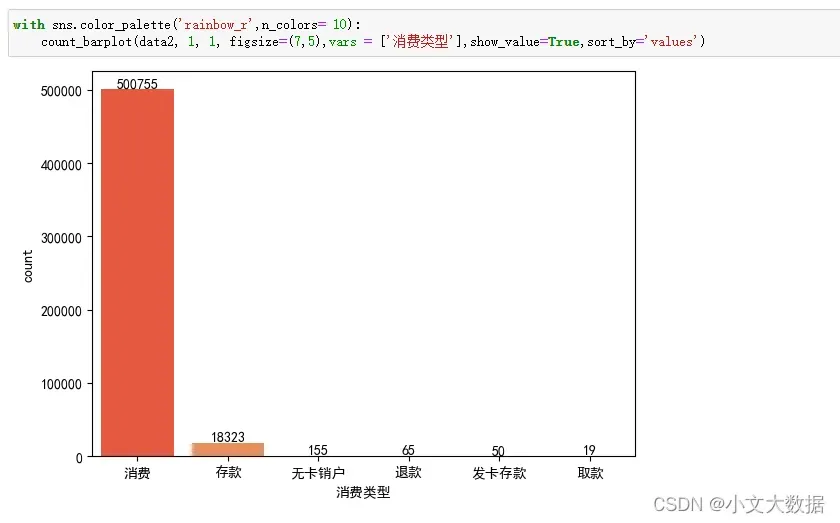
2、缺失值分析:

data2数据的消费项目序号、消费项目编码缺失超过九成,已无实际分析意义,将其去除:
# 删除缺失值过多的列
data2 = data2.drop(['消费项目序号','消费操作编码'],axis = 1)3、异常值分析:
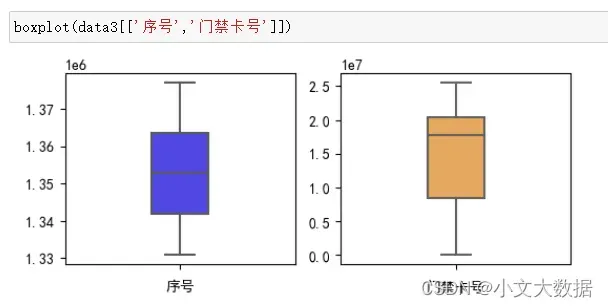
data1箱线图分析:
def boxplot(data):
fig = plt.figure(figsize = (20,20))
for i,col in enumerate(data.columns):
plt.subplot(4,3,i+1)
data[[col]].boxplot()
plt.show()
boxplot(data1[['校园卡号','门禁卡号']])
探索校园卡号异常数据:
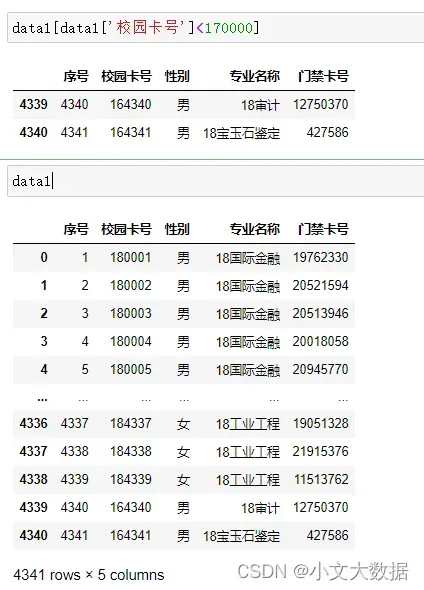
由以上我们可知异常的两个校园卡号很可能是原本为18开头而变成了16,将其修改即可。
data1['校园卡号'].replace({164340:184340,164341:184341},inplace=True)针对门禁卡号异常数据:
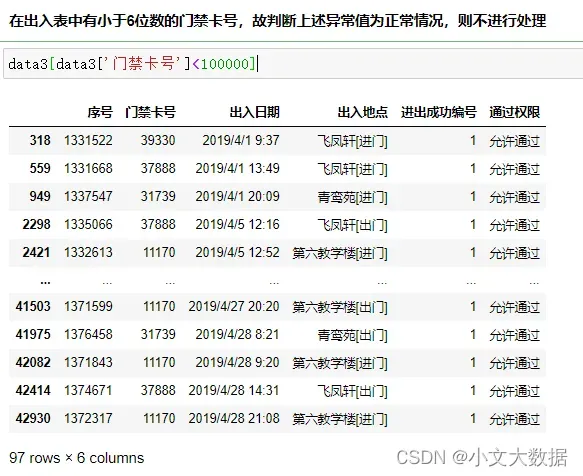
data2箱线图分析:
def get_colors(color_style):
cnames = sns.xkcd_rgb
if color_style =='light':
colors = list(filter(lambda x:x[:5]=='light',cnames.keys()))
elif color_style =='dark':
colors = list(filter(lambda x:x[:4]=='dark',cnames.keys()))
elif color_style =='all':
colors = cnames.keys()
colors = list(map(lambda x:cnames[x], colors))
return colors
# 封装箱线图
def boxplot(data, rows = 3, cols = 4, figsize = (13, 8), vars =None, hue = None, width = 0.25,
color_style ='light',subplots_adjust = (0.2, 0.2)):
fig = plt.figure(figsize = figsize)
hue = data[hue] if isinstance(hue,str) and hue in data.columns else hue
data = data if not vars else data[vars]
colors = get_colors(color_style)
ax_num = 1
for col in data.columns:
if isinstance(data[col].values[0],(np.int64,np.int32,np.int16,np.int8,np.float16,np.float32,np.float64)):
plt.subplot(rows, cols, ax_num)
sns.boxplot(x = hue,y = data[col].values,color=random.sample(colors,1)[0],width= width)
plt.xlabel(col)
# data[col].plot(kind = 'box',color=random.sample(colors,1)[0])
ax_num+=1
plt.subplots_adjust(hspace = subplots_adjust[0],wspace=subplots_adjust[1])
plt.show()
boxplot(data2)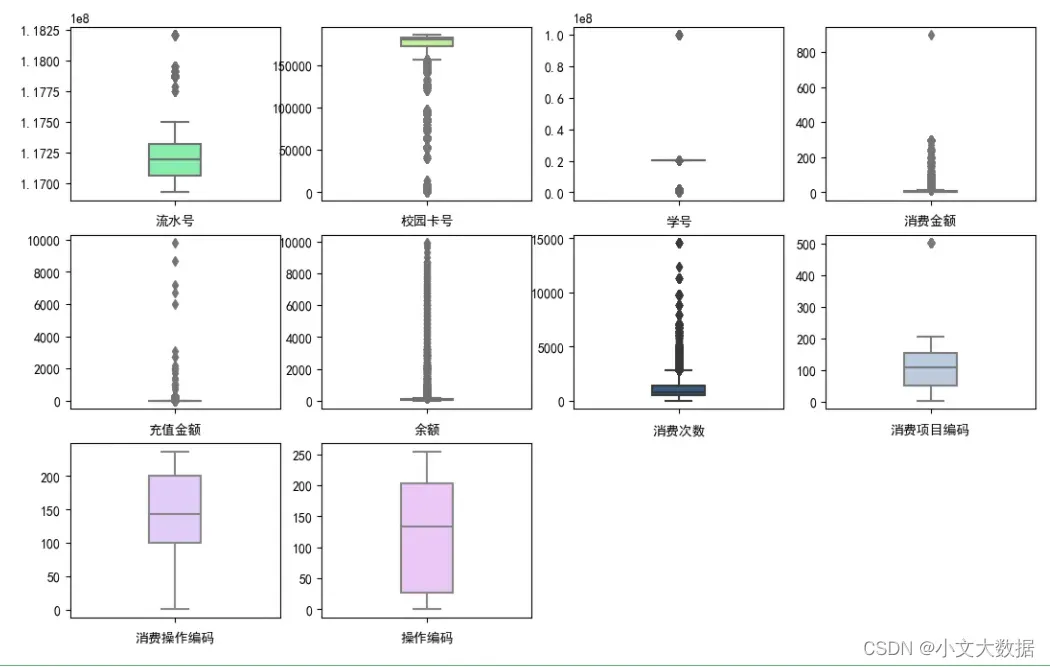
对data2数据结合现实场景主观决定否去除异常值。
对消费时间特征进行分析:
# 将消费时间特征转换为datetime类型数据
time = pd.to_datetime(data2['消费时间']).dt.time
# 对消费时间点进行统计并按照时间排序后进行可视化分析
time.value_counts().sort_index().plot()
plt.title('消费记录统计')
plt.show()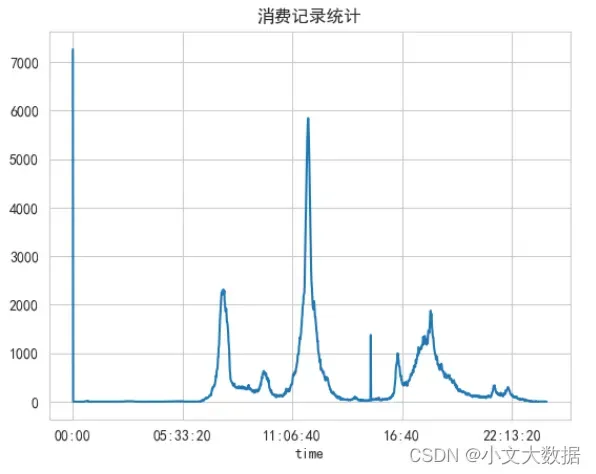
如上可知消费时间在0点的数据量最多,明显不符合显示情况,推测可能是录入时间时出现错误等系统情况导致时间为默认的0点整点。
0点的数据量占有7000多条,且基于这些数据对后续分析仍有价值,因此暂时不进行删除等的处理。
data3箱线图分析:
time = pd.to_datetime(data3['出入日期']).dt.time
time.value_counts().sort_index().plot()
plt.title('门禁出入统计')
plt.show() 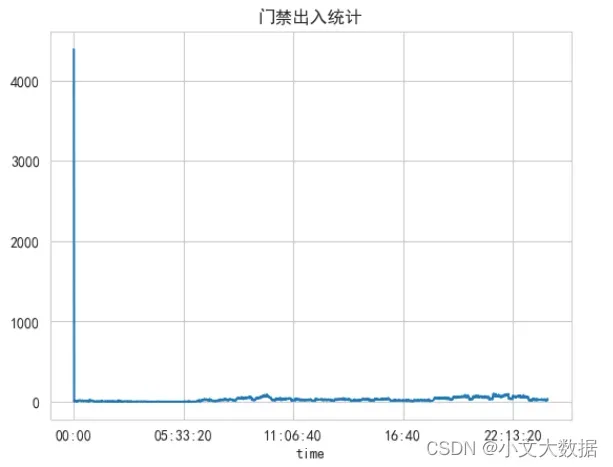
分析与data2一致,暂不处理。
保存数据:
data1.to_csv('task1_1_1.csv')
data2.to_csv('task1_1_2.csv')
data3.to_csv('task1_1_3.csv')任务1.2
1、联结表
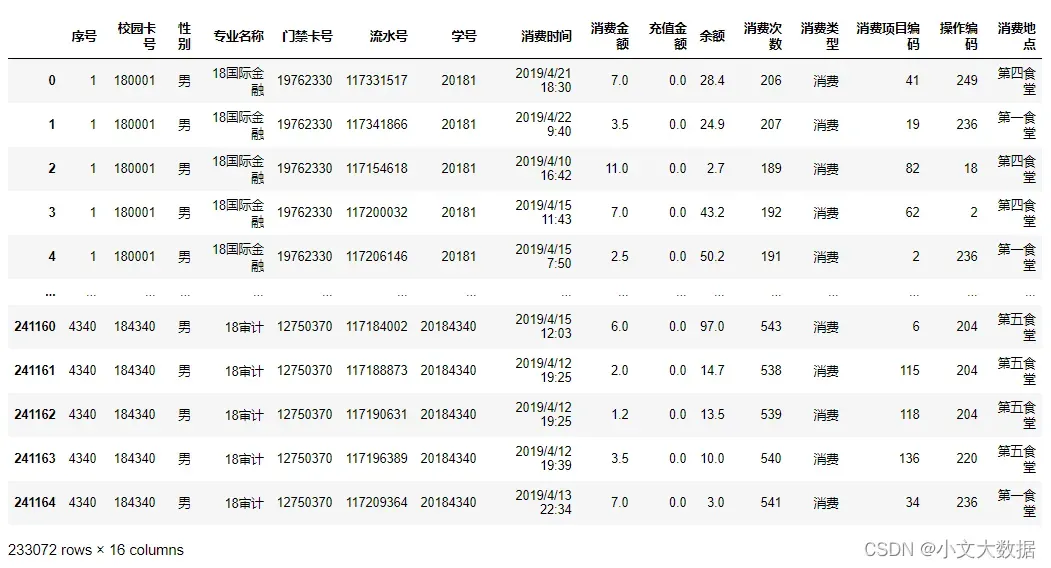
对data1与data2根据校园卡号进行联结,并取出为消费记录的数据。
data_2_1 = pd.merge(data1,data2,left_on='校园卡号')
data_2_1 = data_2_1[data_2_1['消费类型']=='消费']
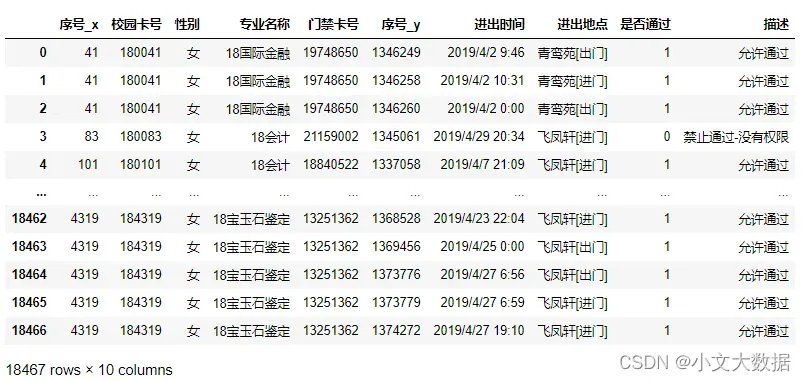
data_2_2 = pd.merge(data1,data3,on = '门禁卡号')
简单根据校园卡号分析学生数量:
a = data_2_1.校园卡号.unique().size
b = data2.校园卡号.unique().size
sns.set_style('whitegrid',rc = {'font.family': 'SimHei'})
AxesSubplot = sns.barplot(x = ['总校园卡号','为消费类型的校园卡号'],y = [b,a])
plt.bar_label(AxesSubplot.containers[0])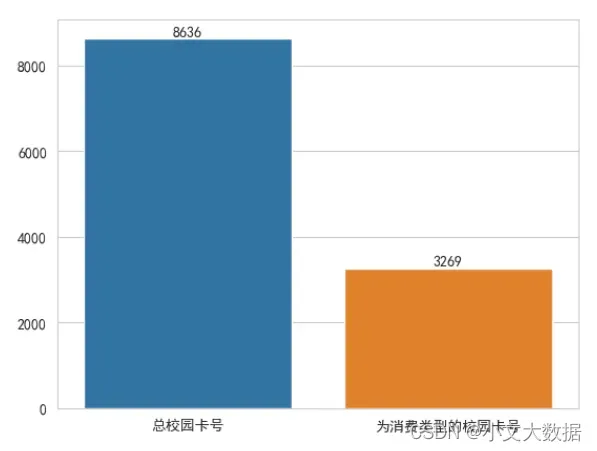
可知在提供的现实某时段消费记录数据内,约有3200多名学生拥有消费记录。
data_2_1:
data_2_2:
任务2.1
绘制各食堂就餐人次的占比饼图,分析学生早中晚餐的就餐地点 是否有显著差别,并在报告中进行描述。(提示:时间间隔非常接近的多次刷卡 记录可能为一次就餐行为)
定义早中晚餐:
import datetime
from datetime import time
# 取出食堂的消费记录数据
data_shitang = data2[(data2['消费地点'].map(lambda x:'食堂' in x)) & (data2['消费类型'] =='消费')]
data_shitang['消费时间'] = pd.to_datetime(data_shitang.消费时间)
def eating_time(x):
y = []
for i in x:
if time(5,0)<=i.time()<time(10,30):
y.append('早餐')
elif time(10,35)<=i.time()<time(16,30):
y.append('午餐')
elif time(16,30)<=i.time()<time(23,30):
y.append('晚餐')
else :
y.append('不明确')
return y
data_shitang['就餐类型'] = eating_time(data_shitang['消费时间'])统计分析每个食堂的早午晚餐刷卡次数。
fig, axes = plt.subplots(2, 3, figsize = (12, 7))
ax = axes.ravel()
labels = data_shitang['消费地点'].unique()
colors = list(map(lambda x:sns.xkcd_rgb[x], sns.xkcd_rgb.keys()))
colors = np.random.choice(colors,5)
ax_num = 0
for label in labels:
data_ = data_shitang[data_shitang['消费地点']==label] # 取出一个类别的数据
# 对该类别数据每个特征进行统计
d = data_['就餐类型'].value_counts()
ax[ax_num].pie(labels = d.index, x = d.values, autopct='%.1f%%',colors = colors)
# ax.pie(d.values, labels = d.values)
ax[ax_num].set_title(label, fontsize = 13)
ax_num+=1
plt.subplots_adjust(0.2,0.2)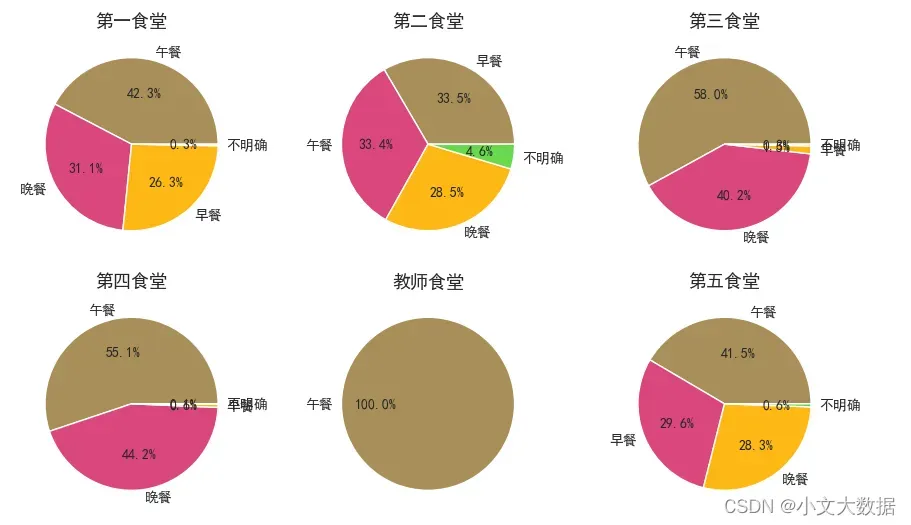
由上可分析每个食堂的刷卡消费情况以及出餐类型,如教师食堂只提供午餐、学生在第三、第四食堂主要消费午餐、晚餐。
分析早中晚的各食堂就餐行为并绘制饼图:
该任务难点主要在于就餐次数的确定(依题意不能直接将刷卡次数当作就餐次数),结合题意及现实,定义30分钟内同个食堂的多次刷卡为一次消费行为即一次就餐次数,不同食堂30分钟内的多次刷卡仍视为多次就餐次数。
# 使30分钟内的多次刷卡为一次刷卡记录
def time_filter(x):
import datetime
# 初始化消费次数为刷卡次数
consums = len(x)
# 对消费时间进行降序
x = x.sort_values(ascending= False)
# 定义变量使得能跳出datetime1已经计算过的在十分钟内的datetime2
position = 0
for num,datetime1 in enumerate(x):
if position != 0:
position -= 1
continue
for datetime2 in x[num+1:]:
# 当时间小于30分钟时,consums消费次数-1
if datetime1-datetime2<datetime.timedelta(seconds = 1800):
consums -= 1
position +=1
else:
break
# 返回总消费次数
return consums
# 获取每个食堂中每个客户的消费次数
d = data_shitang.groupby(['消费地点','校园卡号'],as_index =False)['消费时间'].agg(time_filter)
print(d)
# 统计每个食堂的消费次数
xiaofei_counts=d.groupby('消费地点')['消费时间'].sum()
xiaofei_counts.name = '消费次数'
print(xiaofei_counts)
plt.pie(labels = xiaofei_counts.index,x = xiaofei_counts, autopct='%.1f%%')
plt.title('各食堂总就餐人次占比饼图')
plt.show() 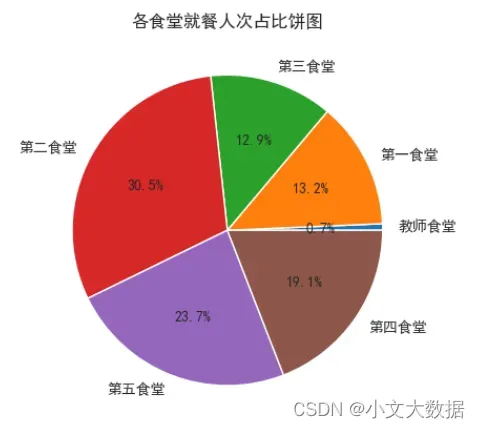
data_shitang_zaocan = data_shitang[data_shitang['就餐类型'] =='早餐']
data_shitang_wucan = data_shitang[data_shitang['就餐类型'] =='午餐']
data_shitang_wancan = data_shitang[data_shitang['就餐类型'] =='晚餐']
data_shitang_ = [data_shitang_zaocan, data_shitang_wucan, data_shitang_wancan]
data_leixing = ['早餐', '午餐', '晚餐']
fig,axes = plt.subplots(1,3, figsize = (14,6))
counts = [] # 存储早午晚餐统计数据
for d, title, ax in zip(data_shitang_, data_leixing, axes):
d = d.groupby(['消费地点','校园卡号'],as_index =False)['消费时间'].agg(time_filter)
xiaofei_counts=d.groupby('消费地点')['消费时间'].sum()
xiaofei_counts.name = '消费次数'
counts.append(xiaofei_counts)
ax.pie(labels = xiaofei_counts.index,x = xiaofei_counts, autopct='%.1f%%')
ax.set_title(f'{title}各食堂就餐人次占比饼图')
plt.show()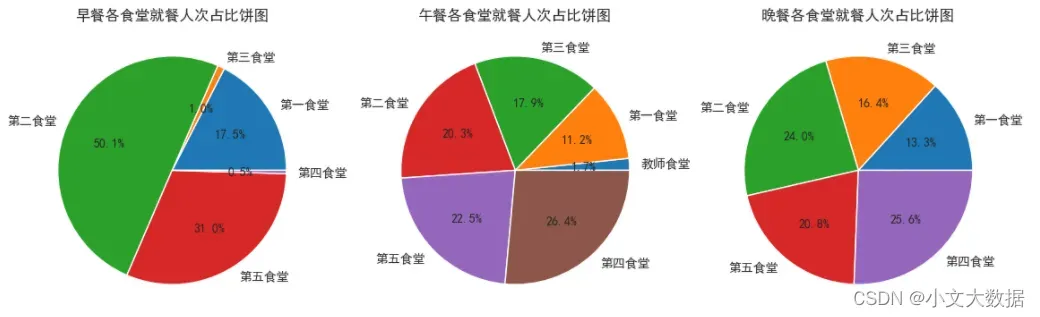
使用pyecharts绘制饼图:
from pyecharts.charts import Pie
from pyecharts import options as opts
def pie_(xiaofei_counts, label):
pie = Pie()
pie.add('就餐次数统计',[list(z) for z in zip(xiaofei_counts.index,xiaofei_counts)],radius = ['50%','70%'],
rosetype = 'are',center=["50%", "53%"])
pie.set_global_opts(title_opts = opts.TitleOpts(title=f'{label}行为分析饼图'),
legend_opts=opts.LegendOpts(pos_bottom = 0))
# formatter中 a表示data_pair,b表示类别名,c表示类别数量,d表示百分数
pie.set_series_opts(label_opts=opts.LabelOpts(
position="outside",
formatter="{a|{a}}{abg|}\n{hr|}\n {b|{b}: }{c} {per|{d}%} ",
background_color="#eee",
border_color="#aaa",
border_width=1,
border_radius=4,
rich={
"a": {"color": "#999", "lineHeight": 22, "align": "center"},
"abg": {
"backgroundColor": "#e3e3e3",
"width": "100%",
"align": "right",
"height": 18,
"borderRadius": [4, 4, 0, 0],
},
"hr": {
"borderColor": "#aaa",
"width": "100%",
"borderWidth": 0.3,
"height": 0,
},
"b": {"fontSize": 14, "lineHeight": 33},
"per": {
"color": "#eee",
"backgroundColor": "#334455",
"padding": [2, 4],
"borderRadius": 2,
},
},
),legend_opts =opts.LegendOpts(type_ = 'scroll',
orient = 'horizontal',align ='left',
item_gap = 10,item_width = 25,item_height = 15,
inactive_color = 'break'))
pie.set_colors(['red',"orange", "yellow", "Cyan", "purple" ,"green","blue","#61e160","#d0fe1d"])
return pie.render_notebook()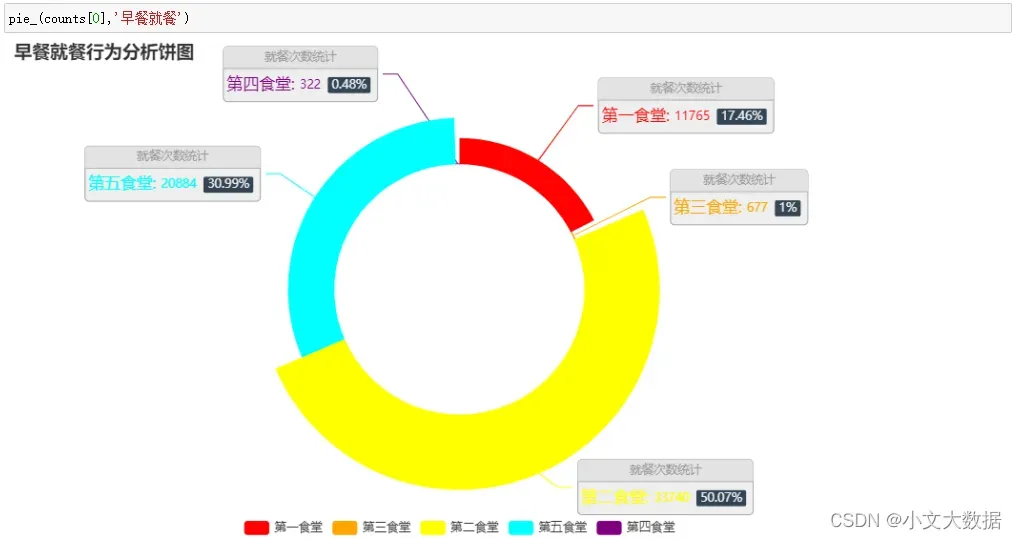
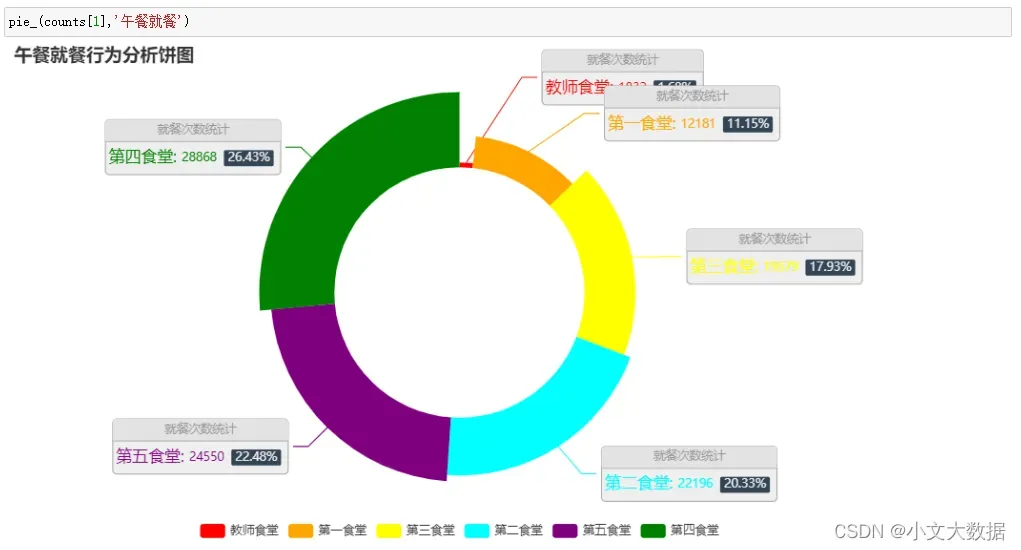
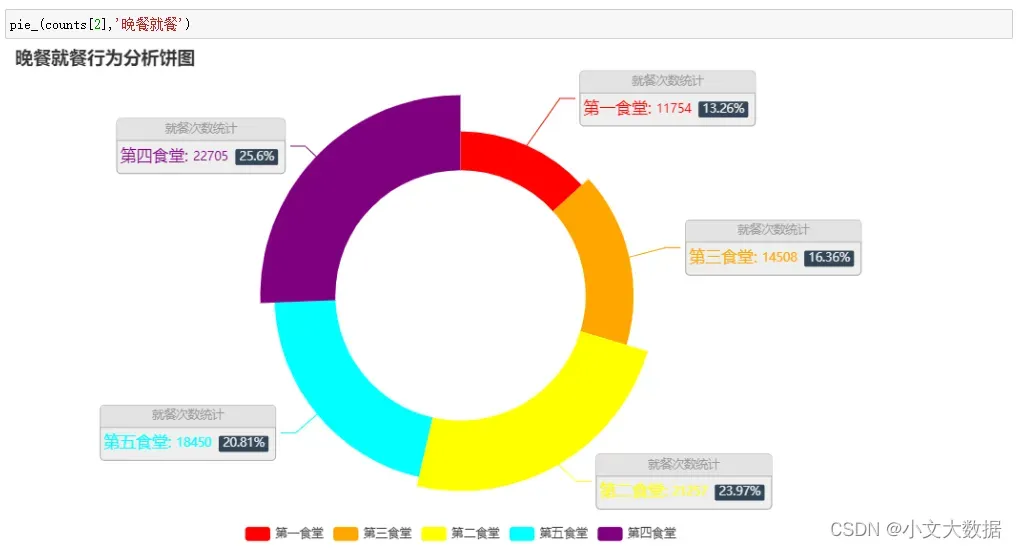
大致分析:
任务 2.2 通过食堂刷卡记录,分别绘制工作日和非工作日食堂就餐时间曲 线图,分析食堂早中晚餐的就餐峰值,并在报告中进行描述。
统计:
# 获取小时数据
data_shitang['就餐时间'] = data_shitang['消费时间'].apply(lambda x:x.hour)
# 获取是否工作日
from chinese_calendar import is_workday,is_holiday
data_shitang['是否工作日'] = data_shitang['消费时间'].apply(lambda x: '工作日' if is_workday(x) else '非工作日')
# 获取工作日与非工作日的每个时间刷卡次数统计
data_isor_workday = data_shitang.groupby(['就餐时间','是否工作日']).size().unstack()
print(data_isor_workday)
# 工作日除以21天,非工作日除以9,得到日均刷卡次数
data_isor_workday = data_isor_workday/np.array([21,9])
# 缺失值填0处理(有的时段无刷卡次数,如凌晨)
data_isor_workday = data_isor_workday.fillna(0).astype(np.int)
可视化:
plt.plot(data_isor_workday.index,data_isor_workday['工作日'], label = '工作日')
plt.plot(data_isor_workday.index,data_isor_workday['非工作日'], label = '非工作日')
plt.xlabel('时间')
plt.ylabel('日均刷卡次数')
plt.xticks(range(24))
plt.legend()
plt.show()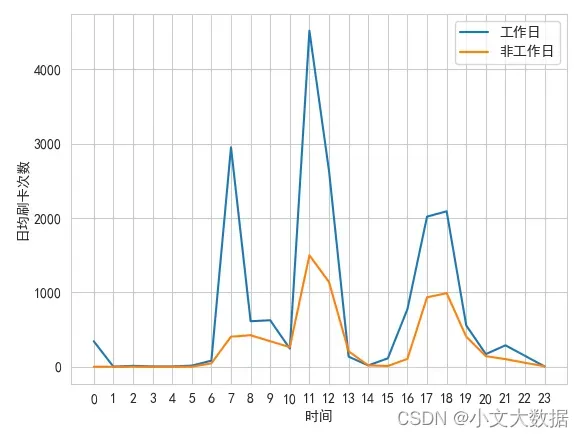
pyecharst可视化:
import pyecharts
from pyecharts.charts import Line
from pyecharts import options as opts
from pyecharts.globals import ThemeType
from pyecharts import *
# 常用全局参数配置封装
def global_opts(line,x_name,y_name,title,bottom = None,left = None,split_line = False):
line.set_global_opts(title_opts=opts.TitleOpts(title = title),
xaxis_opts=opts.AxisOpts(name= x_name,type_='category', name_location='center',name_gap=25,max_interval =0),
yaxis_opts=opts.AxisOpts(name= y_name,type_='value', name_location='end',name_gap=15,
splitline_opts=opts.SplitLineOpts(is_show=split_line,
linestyle_opts=opts.LineStyleOpts(opacity=1)),),
legend_opts =opts.LegendOpts(type_ = 'scroll',
pos_bottom=bottom, pos_left = left,
orient = 'horizontal',align ='left',
item_gap = 10,item_width = 25,item_height = 15,
inactive_color = 'break'),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"),
)
def mul_line_plot(data_x,data_y,x_name,y_name,title,):
line =Line(init_opts=opts.InitOpts(theme=ThemeType.DARK,bg_color = '',width='900px',height = '550px'))
line.add_xaxis(data_x)
for i in data_y.columns:
line.add_yaxis(series_name = i,y_axis =data_y.loc[:,i],is_smooth =True,symbol_size = 6,
linestyle_opts=opts.LineStyleOpts( width=2, type_="solid"),
label_opts = opts.LabelOpts(is_show=True,position = 'top',font_size =12,
font_style = 'italic',font_family= 'serif',))
global_opts(line,x_name,y_name,title,bottom = 0,left = 20)
return line.render_notebook()mul_line_plot(data_x=(data_isor_workday).index.tolist(),data_y=(data_isor_workday),
x_name ='时间',y_name='日均刷卡次数',title ='就餐时间曲线图')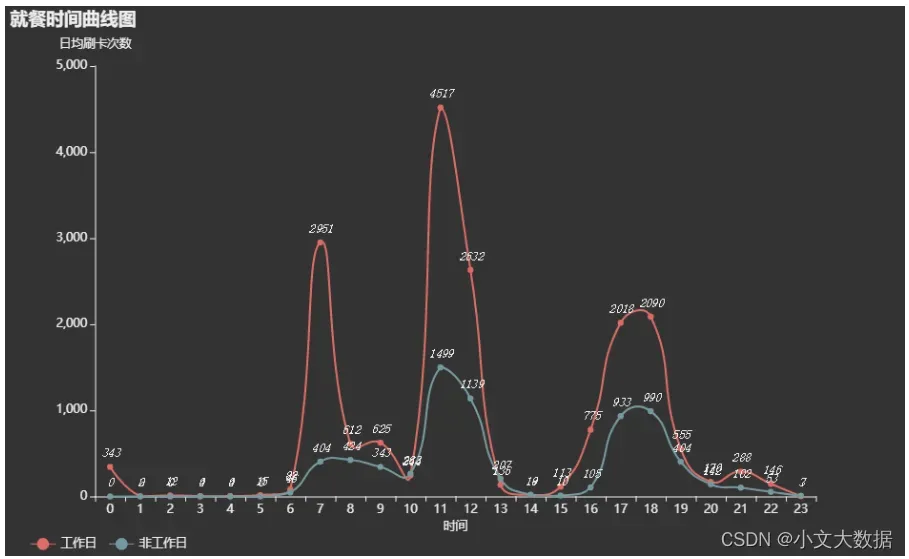
任务 3.1 根据学生的整体校园消费数据,计算本月人均刷卡频次和人均消 费额,并选择 3 个专业,分析不同专业间不同性别学生群体的消费特点。
d = data_2_1.groupby('校园卡号').agg({'消费次数':np.size,'消费金额':np.sum})[['消费金额','消费次数']]
# 封装箱线图
boxplot(data = d)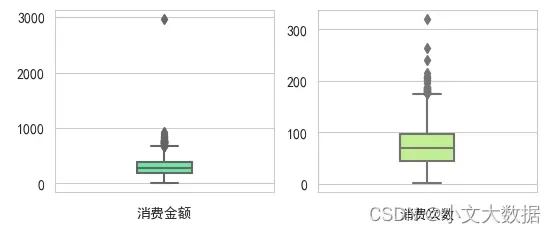
# 依据箱线图去除异常数据
d = d[ (d['消费金额'] < 800) & (d['消费次数'] < 180)]
# 本月人均刷卡次数约72次 、人均消费总额288
print(d.mean())选择三个专业进行消费行为分析:

不同专业不同性别人均刷卡金额对比图:
data_3_zhuanye = data_2_1.query("专业名称 in ['18产品艺术','18会计','18动漫设计']")
a = data_3_zhuanye.groupby(['专业名称','性别'])['消费金额'].mean().unstack()
a = np.round(a,2) # 小数点两位且四舍五入
with sns.color_palette('rainbow_r'):
bar = a.plot.bar()
plt.xticks(rotation =0)
plt.title('平均每次刷卡金额')
for i in bar.containers:
plt.bar_label(i)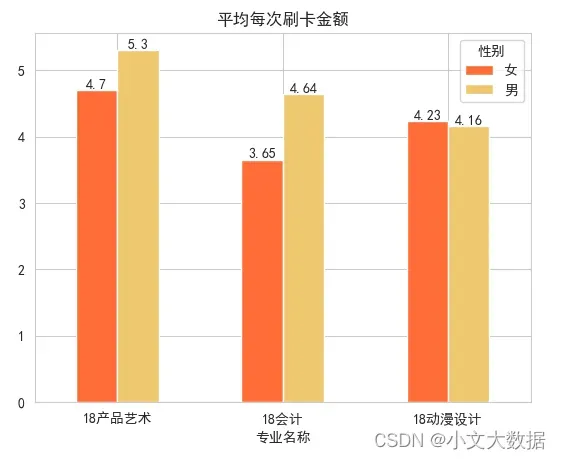
使用pyecharts:
bar = Bar()
bar.add_xaxis(a.index.tolist())
bar.add_yaxis('女',a.iloc[:,0].tolist(),itemstyle_opts=opts.ItemStyleOpts(color='red'))
bar.add_yaxis('男',a.iloc[:,1].tolist(),itemstyle_opts=opts.ItemStyleOpts(color='blue'))
global_opts(line = bar,title = '不同专业不同性别学生群体的关系',x_name = '专业',y_name = '平均刷卡金额/元')
bar.render_notebook() 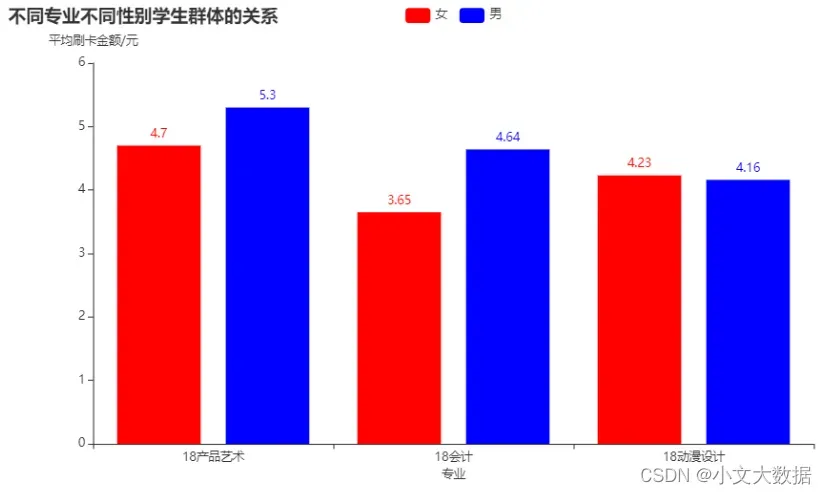
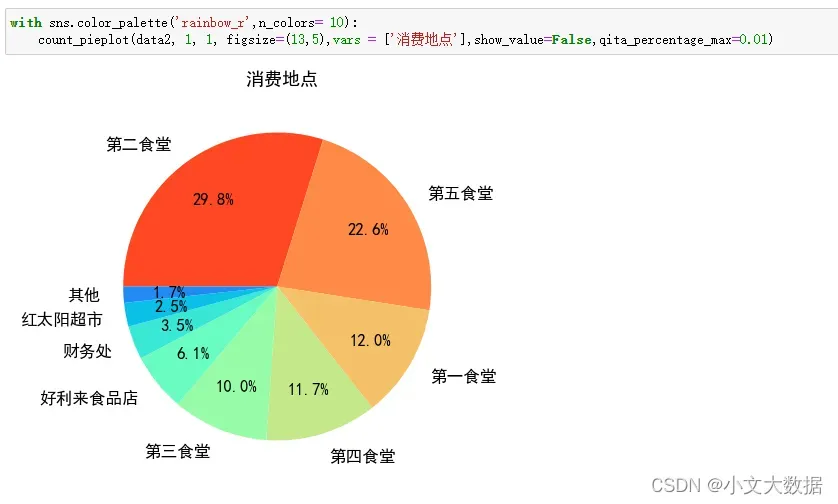
不同专业不同性别就餐地点对比饼图:
with sns.color_palette('rainbow'):
# 封装函数,源程序在作者博客seaborn封装中可以找到
count_pieplot(data_3_zhuanye,3,2,vars = ['消费地点','专业名称','性别'],hue = '专业名称',qita_percentage_max= 0.02,figsize=(6,11))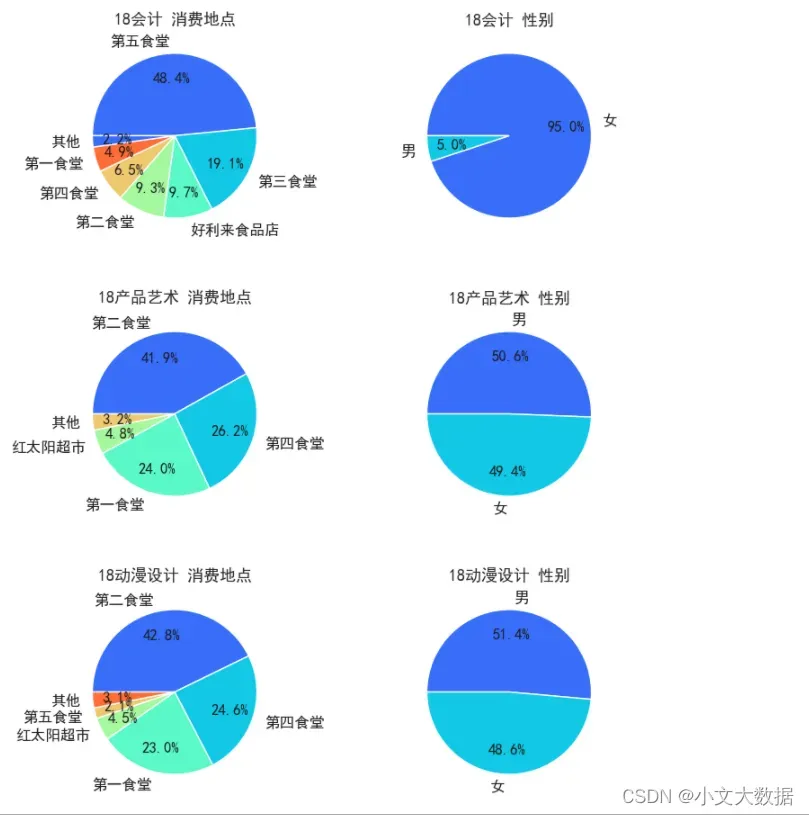
pyecharts:
d_ = pd.pivot_table(data =data_3_zhuanye ,index =['消费地点'],columns = '专业名称',aggfunc='size',).fillna(0)
pie_(d_['18产品艺术'].sort_values(ascending=False)[:8],'18产品艺术消费地点')
# pie_(d_['18会计'].sort_values(ascending=False)[:8],'18会计消费地点')
# pie_(d_['18动漫设计'].sort_values(ascending=False)[:8],'18动漫设计消费地点') 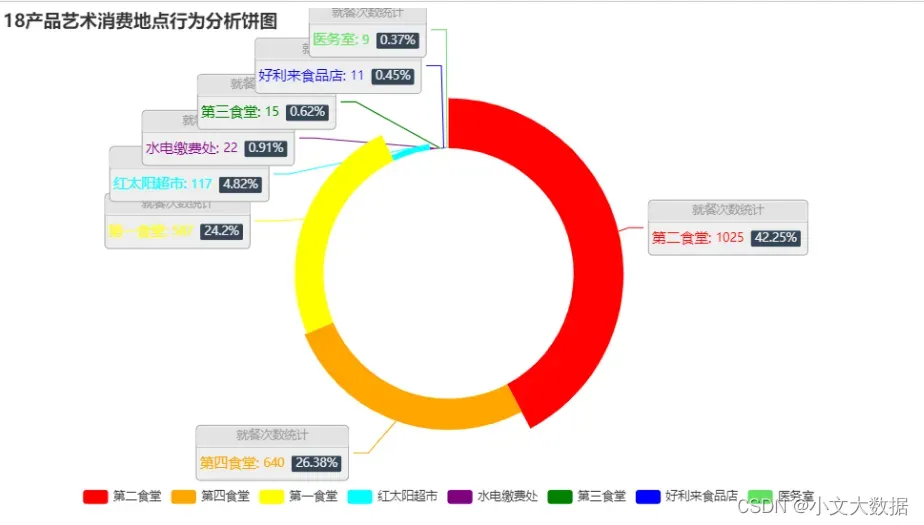
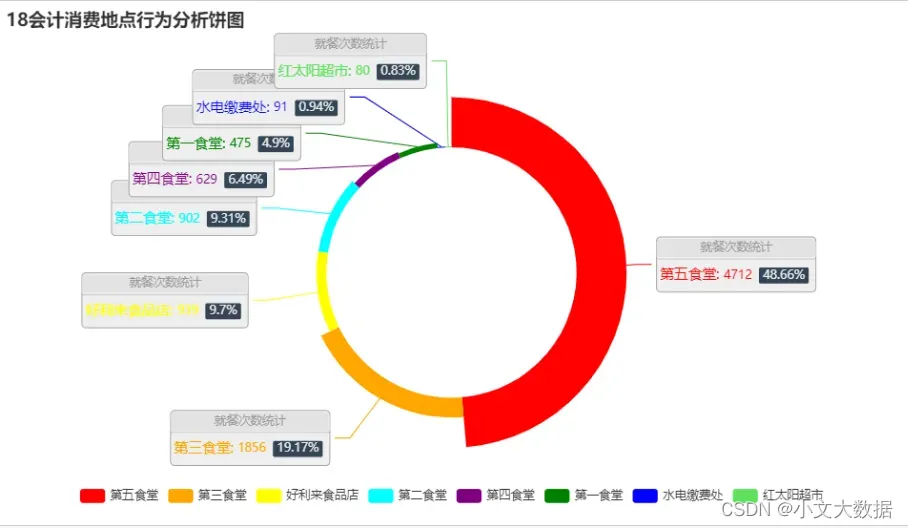
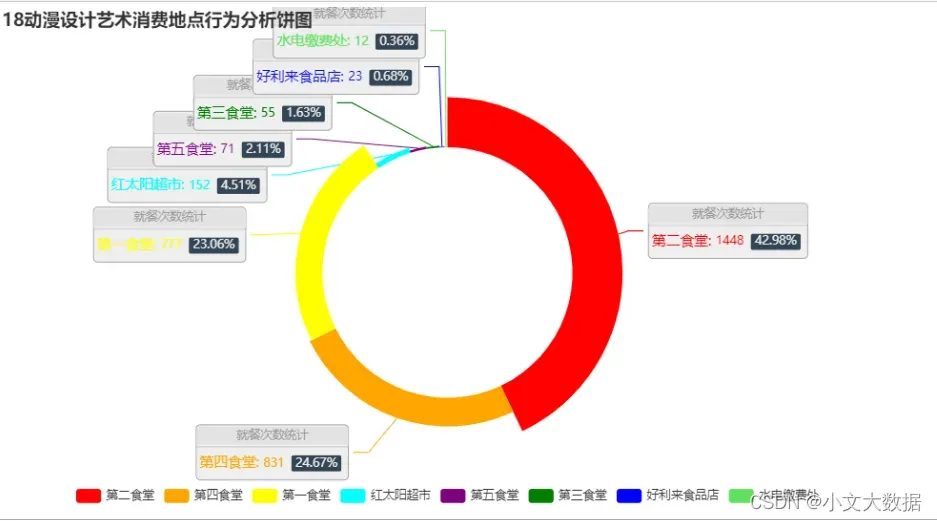
with sns.color_palette('rainbow'):
# 作者封装函数,需要源程序可在作者博客seaborn封装中寻找
count_pieplot(data_3_zhuanye,1,2,vars = ['消费地点'],hue = '性别',qita_percentage_max= 0.02,figsize=(10,4))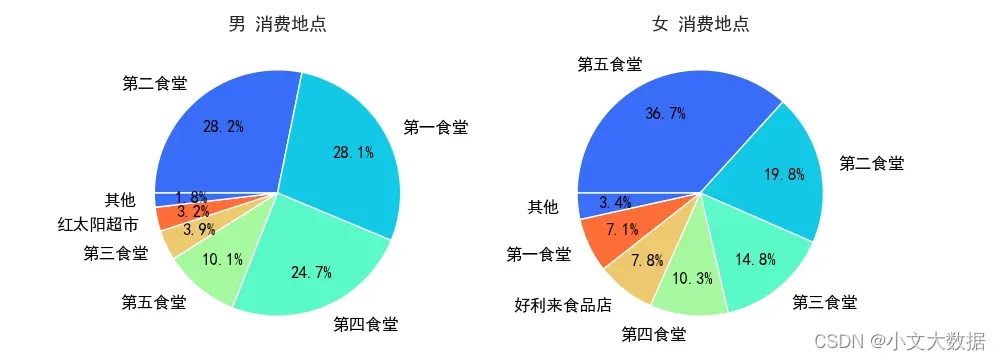
不同专业男生消费地点饼图:
with sns.color_palette('rainbow'):
count_pieplot(data_3_zhuanye.query("性别 == '男'"),1,3,vars = ['消费地点','专业名称'],hue = '专业名称',qita_percentage_max= 0.02,figsize=(16,4)) 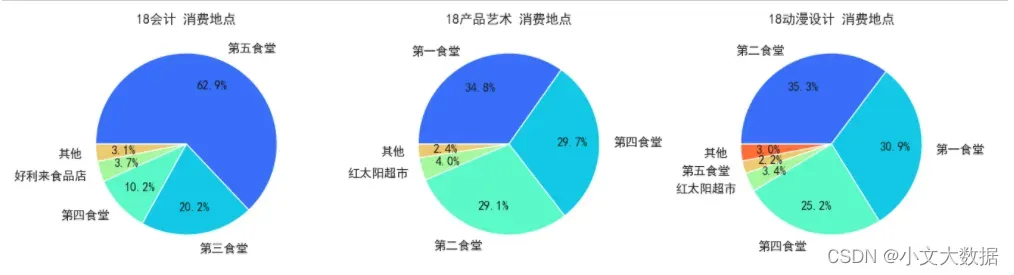
不同专业女生消费地点饼图:
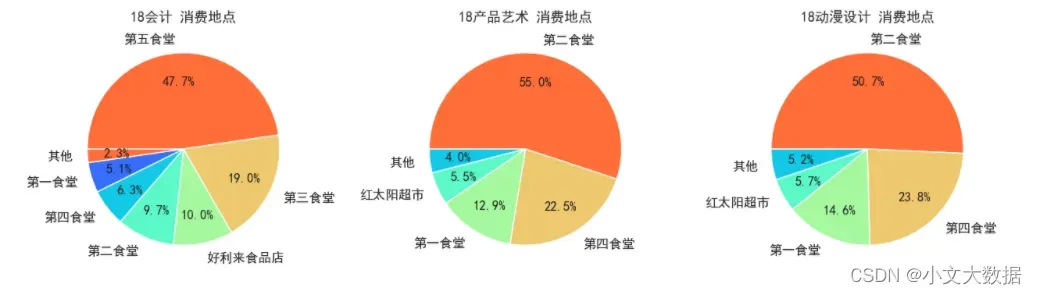
pyecharts:
d_ = pd.pivot_table(data =data_3_zhuanye ,index =['消费地点'],columns = '性别',aggfunc='size',).fillna(0)
pie_(d_['男'].sort_values(ascending=False)[:10],'男生消费地点')
# pie_(d_['女'].sort_values(ascending=False)[:10],'女生消费地点') 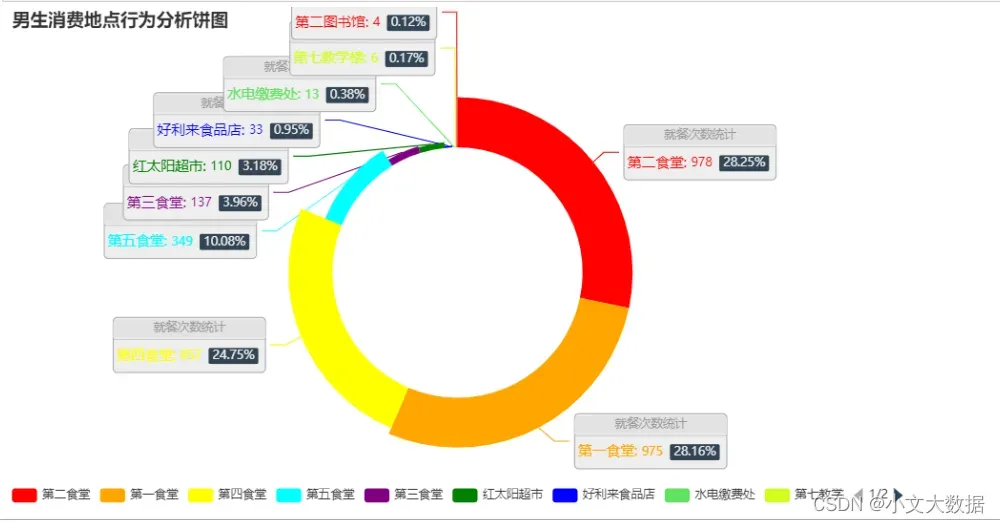
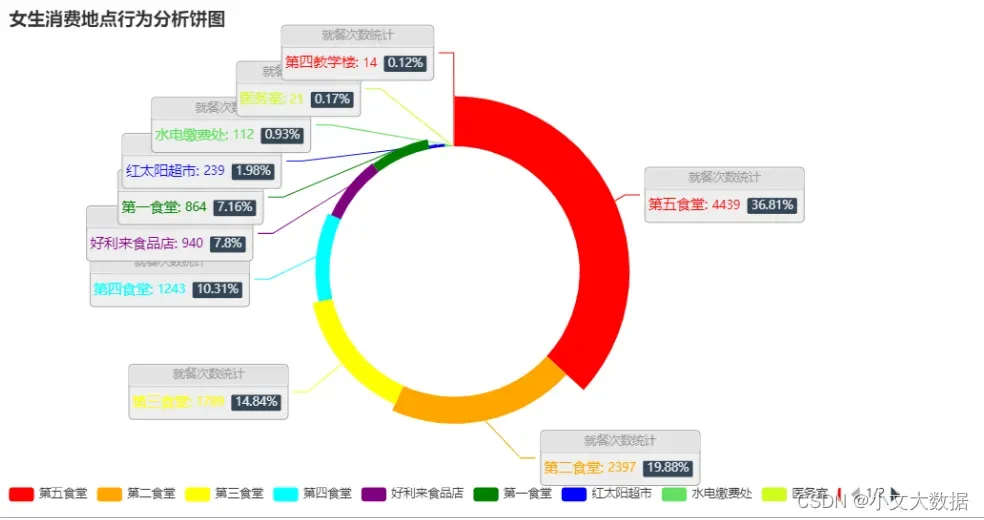
任务 3.2 根据学生的整体校园消费行为,选择合适的特征,构建聚类模型, 分析每一类学生群体的消费特点。
结合背景分析,取出每次刷卡平均消费金额、总消费次数、消费总金额三个特征进行聚类
import sklearn
from sklearn import cluster
from sklearn.preprocessing import StandardScaler
# 取出日常消费类型数据
data_2_1_1 = data_2_1.query("消费地点 in ['第四食堂','第一食堂','第二食堂', '红太阳超市','第五食堂','第三食堂', '好利来食品店']")
# 取出每次刷卡平均消费金额、总消费次数、消费总金额三个特征进行聚类
data = data_2_1_1.groupby(['校园卡号'],as_index=False)['消费金额'].mean()
data['本月内消费累计次数'] = data_2_1_1.groupby('校园卡号')['消费次数'].size().values
data['消费总金额'] = data_2_1_1.groupby('校园卡号')['消费金额'].sum().values
data = data.set_index('校园卡号')
data.columns = ['平均每次刷卡消费金额','本月内累计消费次数','消费总金额']
print(data)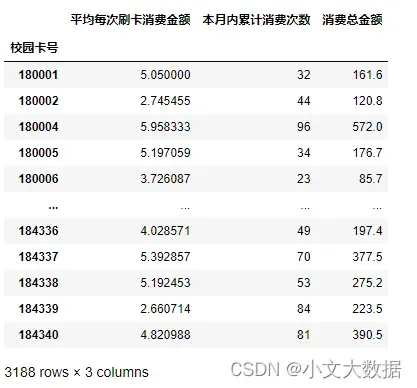
Kmeans聚类:
# Kmeans聚类模型,七个聚类簇
model = cluster.KMeans(n_clusters=7)
# 标准化模型
scaler = StandardScaler()
# 标准化
data_ = scaler.fit_transform(data.iloc[:,:])
# 模型训练
model.fit(data_)
# 对数据进行聚类得到标签
labels = model.predict(data_)
# 将标签加入到data数据中
data['labels'] = labels
可视化:
二维散点图
sns.set(font='SimHei')
sns.scatterplot(data =data , x = '本月内累计消费次数',y= '平均每次刷卡消费金额',hue = 'labels',palette = 'rainbow')
plt.title('七个消费群体散点图')
plt.show()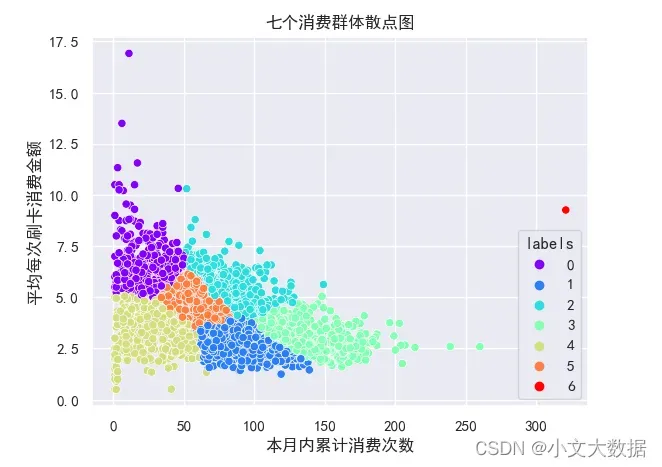
三维散点图:
colors = ['#a88f59', '#da467d', '#fdb915', '#69d84f', '#380282','r','b']
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(15,8))
ax = fig.add_subplot(121, projection='3d')
for i in data['labels'].unique():
d = data[data['labels']==i]
ax.scatter(d['本月内累计消费次数'],d['平均每次刷卡消费金额'],d['消费总金额'],c=colors[i],label =i)
ax.set_xlabel('本月内累计消费次数')
ax.set_ylabel('平均每次刷卡消费金额')
ax.set_zlabel('消费总金额')
plt.title('高钾:层次聚类结果图',fontsize = 15)
plt.legend()
plt.show()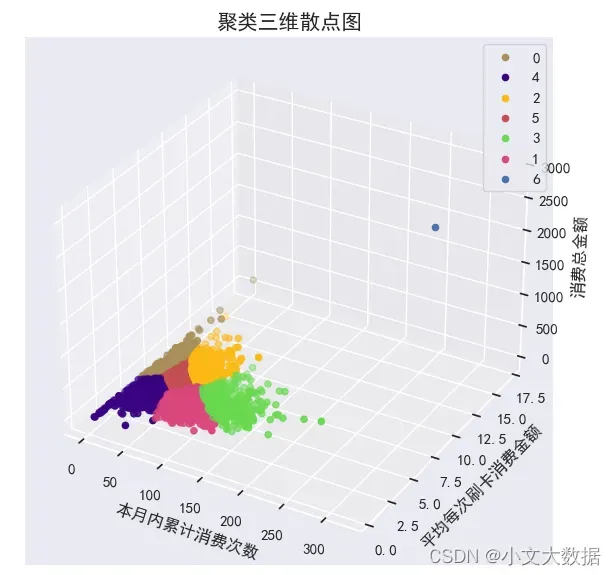
任务 3.3 通过对低消费学生群体的行为进行分析,探讨是否存在某些特征, 能为学校助学金评定提供参考。
分析并探讨低消费群体的特征为助学金评定提供建议:
基于任务3.2的聚类图并结合现实情况,低消费群体应为具有中等消费次数,低平均消费金额以及低消费总额的特点,因为消费次数太低说明可能很少在食堂消费,可能多为在校外饭馆等消费,不能判定为贫困学生,而消费次数高即使平均消费低也会导致高消费总额,也不能判定为贫困学生,据此分析,我们判定1号群体满足低消费贫困学生的特点,并且2号群体消费次数分布在100左右,符合一个月内正常的每天三餐的消费次数,所以若学校需要对贫困学生执行助学金政策,可在1号群体学生中从左下角开始选择(越靠近左下角代表消费总额越低)。
其他自主分析可视化图:
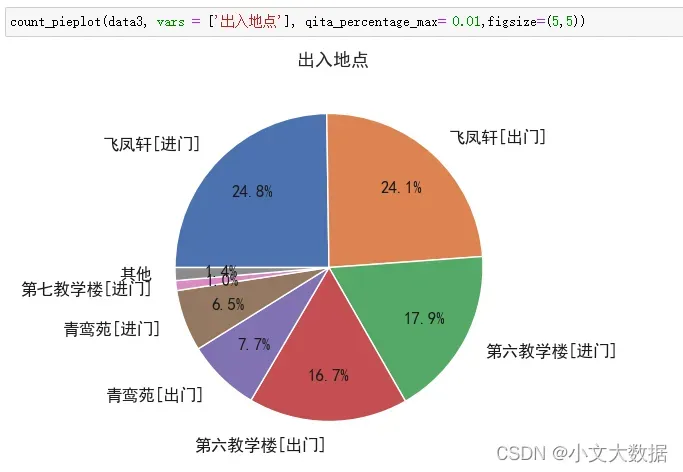
文章出处登录后可见!