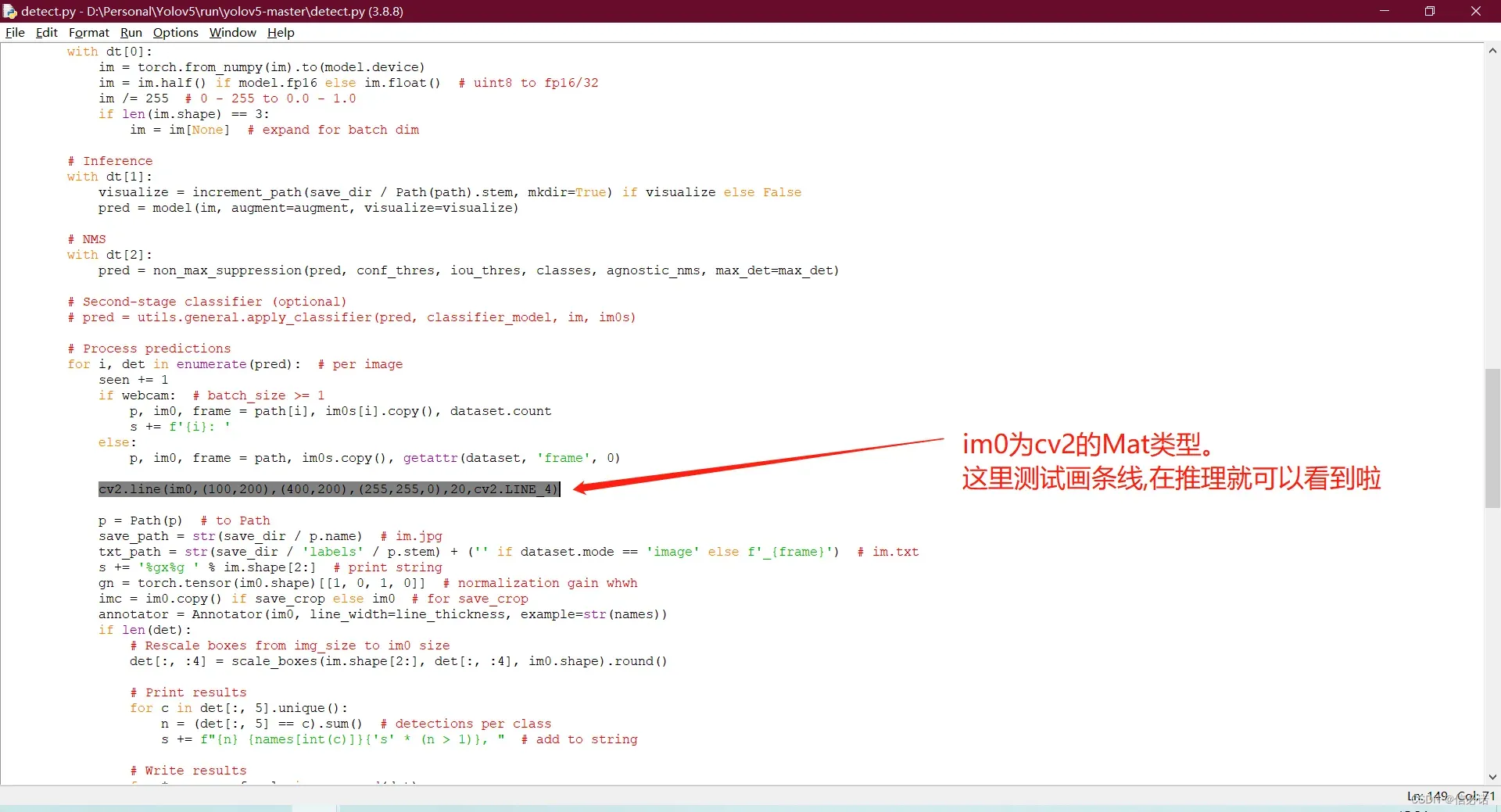
Yolov5自带detect.py加入cv2简单操作
说明:im0为mat的原图
detect.py参数解析
1、运行detect.py的两种方式:
(1)、使用命令:
python detect.py –source ./testfiles/img1.jpg –weights runs/train/base/weights/best.pt –conf 0.4
(2)、在ide或无参命令运行detect.py文件
该方式将方式一的命令参数直接在detect.py中修改后执行
2、参数解析
parser = argparse.ArgumentParser()
# 指定需要推理的.pt模型
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'weights/yolov5s.pt', help='model path or triton URL')
# 输入源(文件/目录/url/glob/screen/摄像头(0/webcam)),通常输入mp4或摄像头
parser.add_argument('--source', type=str, default=ROOT / '0', help='file/dir/URL/glob/screen/0(webcam)')
##举例1 - 本地mp4作为输入视频:
parser.add_argument('--source', type=str, default=ROOT / 'test.mp4', help='file/dir/URL/glob/screen/0(webcam)')
##举例2 - 将桌面xy从100,100位置起、宽高均为400作为输入视频:
parser.add_argument('--source', type=str, default=ROOT / 'screen 100 100 400 400', help='file/dir/URL/glob/screen/0(webcam)')
##举例3 - 将usb摄像头作为输入视频:(注:多屏时百度搜索LoadScreenshots查看解决方案)
parser.add_argument('--source', type=str, default=ROOT / '0', help='file/dir/URL/glob/screen/0(webcam)')
# 配置文件的一个路径,配置文件里面包含了下载路径和一些数据集基本信息。
# 训练模型时编写的data/yaml文件;默认也可以
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
# 模型在推理图片前会把图片resize成640的size,之后再扔进网络里。并非最终得到尺寸结果。
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
# 置信度阈值(根据数据集情况自行调整)
# 网络对检测目标相信的程度,若设置“0”则网络只要认为预测的目标有一点点概率是正确的目标都会给框出来。
parser.add_argument('--conf-thres', type=float, default=0.5, help='confidence threshold')
# 调节IoU阈值:IoU可以理解预测框和真实框的交并比。
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
# 最大检测数量。
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
# 指定使用cpu或gpu进行推理,并可指定GPU数量。
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
# 推理过程中是否实时显示检测结果。[store_true隐藏、store_false显示]
parser.add_argument('--view-img', action='store_false', help='show results')
# 推理结果是否保存成一个.txt格式文件。[store_true不保存、store_false保存]
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
# 推理结果是否以.txt格式保存目标置信度。[store_true不保存、store_false保存]
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
# 是否把模型推理到的物体裁剪到crops文件夹。[store_true不裁剪、store_false裁剪]
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
# 是否不保存推理结果文件,输出为图片或视频文件。[store_true保存、store_false不保存]
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
# 推理类别,默认为所有类别。该类别为训练模型时设置的data/xx.yaml中的names类别。
parser.add_argument('--classes', nargs='+',type=int, help='filter by class: --classes 0, or --classes 0 2 3')
# 增强版的nms
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
# 也是一种增强方式
parser.add_argument('--augment', action='store_true', help='augmented inference')
# 是否将特征图可视化,若开启则exp文件夹下又多一些文件
parser.add_argument('--visualize', action='store_true', help='visualize features')
# 若开启则对所有模型进行strip_optimizer操作,去除pt文件中的优化器等信息。[store_true不开启、store_false开启]
parser.add_argument('--update', action='store_true', help='update all models')
# 设置推理结果保存的路径
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
# 设置推理结果保存的文件夹名称
parser.add_argument('--name', default='exp', help='save results to project/name')
# 设置每次预测模型的结果是否保存在原来的文件夹。[store_true不指定、store_false指定]
# 若指定则本次推理结果还是保存在上一次保存的文件夹中;若不指定就是每次预测结果保存一个新的文件夹下
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
# 调节预测框线条粗细
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
# 推理结果是否隐藏标签
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
# 推理结果是否隐藏置信度
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
# 否使用FP16半精度推理。[store_true不使用、store_false使用]
# 低精度技术 (high speed reduced precision)。在training阶段,梯度的更新往往是很微小的,需要相对较高的精度,一般要用到FP32以上。在inference的时候,精度要求没有那么高,一般F16(半精度)就可以,甚至可以用INT8(8位整型),精度影响不会很大。同时低精度的模型占用空间更小了,有利于部署在嵌入式模型里面。
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
# 是否使用OpenCV DNN进行ONNX推理。[store_true禁用、store_false开启]
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
# 输入视频帧率步长,1为正常速度
parser.add_argument('--vid-stride', type=int, default=1, help='video frame-rate stride')
笔者
笔者 – jxd
文章出处登录后可见!
已经登录?立即刷新