写在前面
本篇文章是对笔者前几天学习过程的一个记录,鉴于这类文章较少,写出来方便后来者。
本文侧重于yolov5的快速使用,原理部分概括较少,希望你看完本文章后也能成功进行目标检测。
GPU租赁平台:https://www.autodl.com/home
yolov5官方代码:https://github.com/ultralytics/yolov5
作者更改后代码:链接:https://pan.baidu.com/s/1oZWhHjAy_Wp4mg6doaSrkQ 提取码:f7re
数据集:链接:https://pan.baidu.com/s/1Ra7bf5JQavIA69kNLiUnXA 提取码:6z0j
filezilla下载地址:客户端 – FileZilla中文网
前文部分篇幅涉及到yolov5的配置,租赁GPU请直接跳转第三部分。
正文
一、下载yolov5代码文件
yolov5的环境配置你可以查看其它博客或者某宝寻求帮助,此处不再赘述,主要是要安装好pycharm专业版和pytorch环境。
在环境准备好之后,你可以对yolov5进行下载(文首第二个链接),按照下面操作你就可以得到一个压缩包。
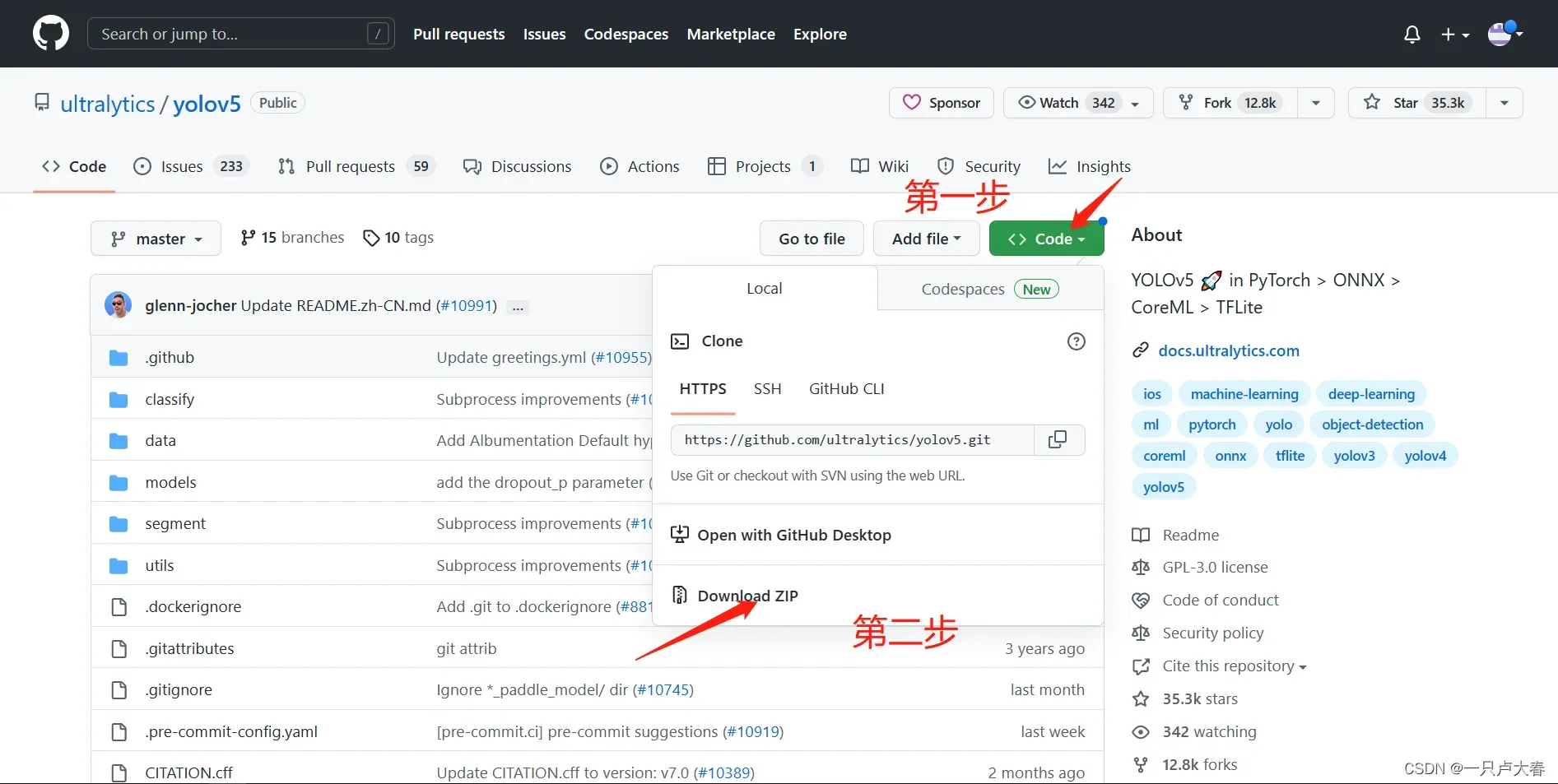
将压缩包解压到你准备的代码路径中,打开pycharm。注意,本文是使用租赁的GPU平台跑yolov5,只能使用pycharm专业版,如果不是专业版可求助其他帖子或者某宝。分辨是不是专业版,可在软件启动页查看,带有(Professional)的字样是专业版。

来到初始界面,选择你刚解压的压缩包,选择该文件夹并打开,打开之后就是这个界面了,刚打开是一个readme的文件。

二、对yolov5文件进行更改
使用yolov5训练目标检测模型,主要涉及到的更改是数据集与训练的文件一些参数、路径。下面首先给出数据集的配置,教程对公开数据集或者私有数据集均适用。
1.建立数据集路径
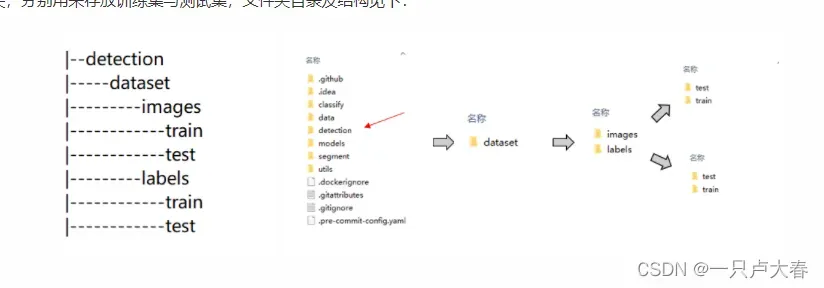
打开yolov5-master文件,在train.py同级目录下建立detection(可不同,但需要英文)文件夹,然后在detection文件夹中建立dataset文件夹,继续在dataset文件夹中分别建立images和labels两个文件夹,最后分别在这两个文件夹中建立train与test文件夹,分别用来存放训练集与测试集,文件夹目录及结构见下:
2.添加数据集文件
在yolov5-master/data文件夹中复制coco128.yaml文件到yolov5-master/detection文件夹下,更改此文件夹名字为detection.yaml。这里的coco128.yaml是一个小型数据集,由COCO train2017 中的前128张图像组成,文件中包含的设置分别有图像列表路径、训练集验证集路径以及类的数目及名称。
我们需要根据刚才建立的数据集路径以及数据集中类别进行更改,更改后如下:

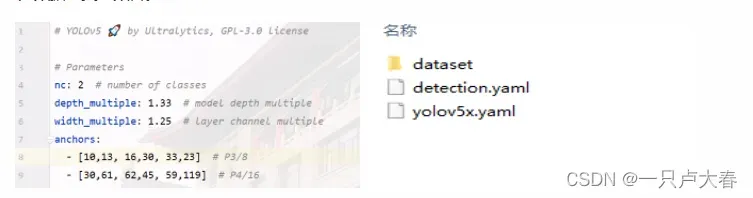
然后将yolov5-master/models文件夹中yolov5x.yaml文件复制到yolov5-master/detection文件夹下,当然s、n、m、l几个模型也可以使用,此处仅以yolov5x.yaml模型为例,此文件主要包含参数配置、anchors配置以及网络结构几部分,我们只需要对nc值进行更改,更改为数据集类别数目。
我们选用的数据集是一个猫狗的数据集,数据集链接可在文首下载。现在我们手里拿到了500张猫狗的图片,需要先对图片进行标签处理。关于标注软件的使用可查看其它博客,文首提供的数据集链接已完成标注,可直接使用。
完成数据集下载后,由于yolov5只认txt文件,不认xml,因此需要完成xml到txt文件的转换,转换程序如下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
def convert(size, box):
# size=(width, height) b=(xmin, xmax, ymin, ymax)
# x_center = (xmax+xmin)/2 y_center = (ymax+ymin)/2
# x = x_center / width y = y_center / height
# w = (xmax-xmin) / width h = (ymax-ymin) / height
x_center = (box[0] + box[1]) / 2.0
y_center = (box[2] + box[3]) / 2.0
x = x_center / size[0]
y = y_center / size[1]
w = (box[1] - box[0]) / size[0]
h = (box[3] - box[2]) / size[1]
# print(x, y, w, h)
return (x, y, w, h)
def convert_annotation(xml_files_path, save_txt_files_path, classes):
xml_files = os.listdir(xml_files_path)
# print(xml_files)
for xml_name in xml_files:
# print(xml_name)
xml_file = os.path.join(xml_files_path, xml_name)
out_txt_path = os.path.join(save_txt_files_path, xml_name.split('.')[0]+'.txt')
out_txt_f = open(out_txt_path, 'w')
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('item'):
# difficult = obj.find('difficult').text
cls = obj.find('name').text
# if cls not in classes or int(difficult) == 1:
# continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
# b=(xmin, xmax, ymin, ymax)
# print(w, h, b)
bb = convert((w, h), b)
out_txt_f.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == "__main__":
# 把forklift_pallet的voc的xml标签文件转化为yolo的txt标签文件
# 1、需要转化的类别
classes = ['cat', 'dog']
# 2、voc格式的xml标签文件路径
xml_files1 = r'***'
# 3、转化为yolo格式的txt标签文件存储路径
save_txt_files1 = r'***'
convert_annotation(xml_files1, save_txt_files1, classes)
转换为txt文件后,可以手动或者使用程序对数据集划分。鉴于本次数据集不大,我选择手动划分,训练集与测试集为4:1的比例,即随机选取各50张猫狗照片放于test文件夹中,剩余400张图片放于train文件夹中,注意标签也如此操作,同时保证标签名字与图片名字对应。
3.更改训练参数
训练参数主要是对train.py与detect.py部分进行更改,其中train.py的更改用于训练模型,detect.py的更改用于检测训练结果。
打开train.py文件,来到第435行,部分参数说明及更改如下:
第437行,weights部分,我们本次使用yolov5x.pt,故将default后ROOT / ‘yolov5s.pt’改为ROOT / ‘yolov5x.pt’
第438行,配置网络结构部分,对应yolov5x.yaml,故将default后填ROOT / ‘detection/yolov5x.yaml’
第439行,数据集配置文件,对应detection.yaml,故将default后填ROOT / ‘detection/detection.yaml’
第441行,训练轮次,根据数据集训练结果来确定训练轮次
第454行,训练设备,一般使用GPU0,所以default后填0
其他参数如果是小白初次训练不需要更改,可在熟悉后再按需更改。
更改后参数代码如下:
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5x.pt', help='initial weights path') #weight权重路径,需更改
parser.add_argument('--cfg', type=str, default=ROOT / 'detection/yolov5x.yaml', help='model.yaml path') #cfg配置文件(网络结构),需更改
parser.add_argument('--data', type=str, default=ROOT / 'detection/detection.yaml', help='dataset.yaml path') #数据集配置文件(路径),需更改
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path') #hyp超参数文件,根据需要更改
parser.add_argument('--epochs', type=int, default=100, help='total training epochs') #训练轮次,根据需要更改
parser.add_argument('--batch-size', type=int, default=2, help='total batch size for all GPUs, -1 for autobatch') #训练批次,根据需要更改,配置较低时设置小一些
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)') #设置图片大小,根据需要更改
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training') #是否接着上次训练结果,继续训练
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch') #最后进行测试
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--noplots', action='store_true', help='save no plot files')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='image --cache ram/disk') #是否提前缓存图片到内存,以加快训练速度
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') #选择训练设备,一般用GPU0
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name') #保存路径
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)') #早停止忍耐次数,100次不更新就停止训练
注:detect部分建议在训练模型完成之后再观看
打开detect.py文件,来到第221行,在训练完成后,我们只需要weights source data三部分进行更改就可以进行识别,其他参数可按需要自行更改。

第221行,weights部分,对于训练好的权重文件,比如 ‘runs/train/exp4/weights/best.pt’
第222行,需检测的图片,自行填写路径
第223行,数据集配置文件,对应detection.yaml,故将default后填ROOT / ‘detection/detection.yaml’
三、租赁GPU
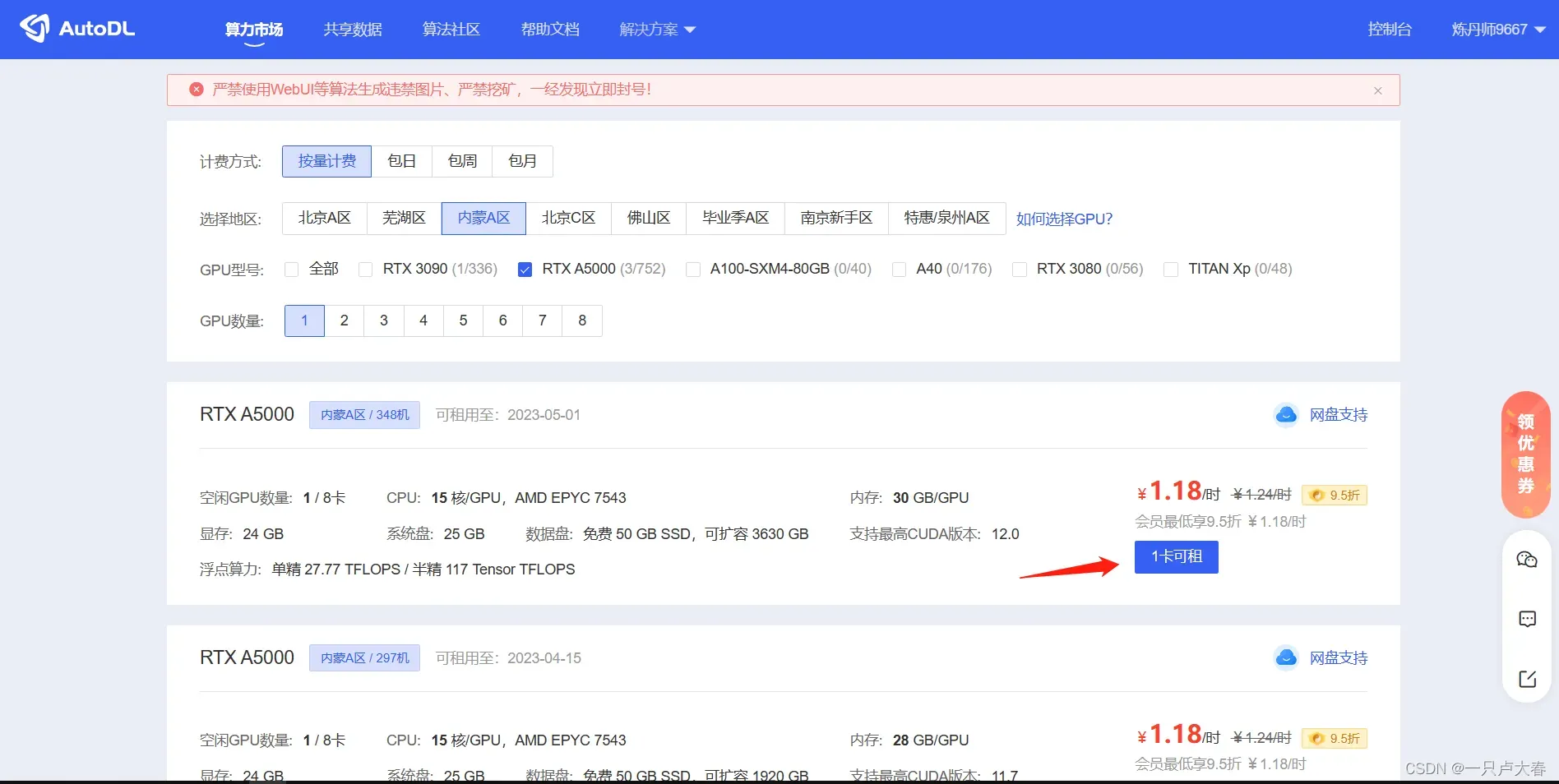
打开文首GPU租赁平台,注册一个账号。如果你是学生身份,可以申请学生认证,这样租赁GPU就可以是9.5折。
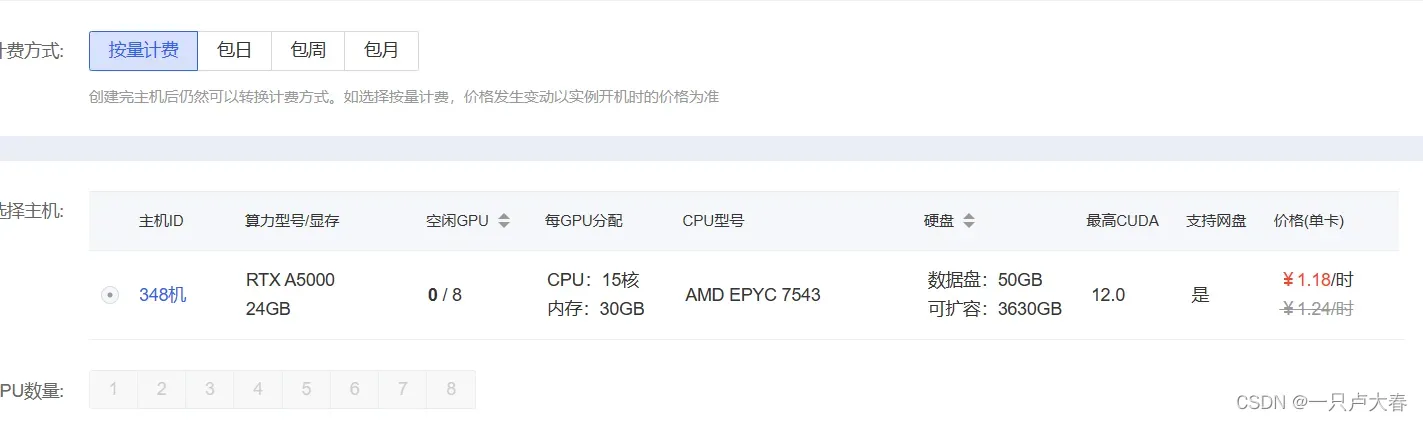
来到主界面,选择一个可用的GPU,进行租赁,比如下图就是点击“一卡可租”
然后计费方式,你可以选择按量计费,包日,包周或者包月,我一般使用按量计费,经济一些。
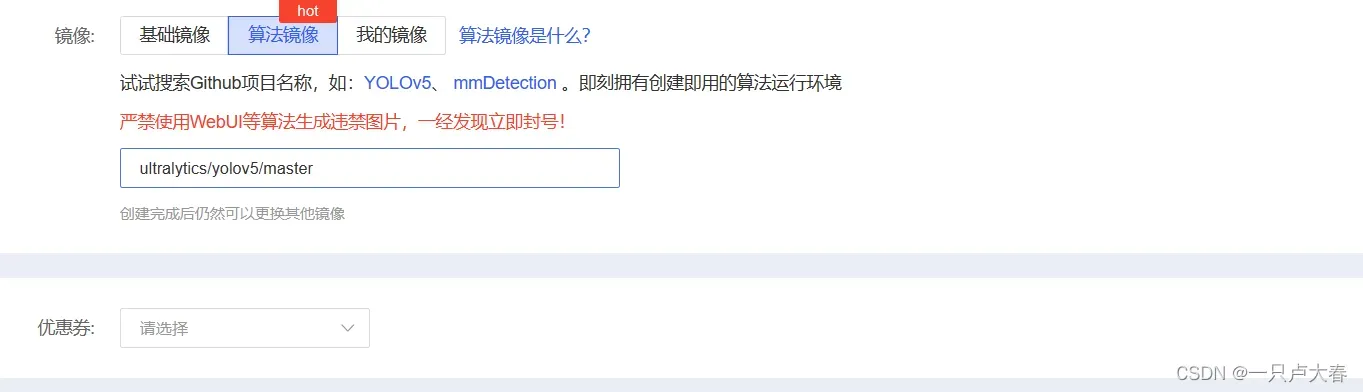
然后镜像部分,你可以选择算法镜像,然后在里面搜索yolov5,我理解算法镜像就是提供好该算法所需环境。
这些都设置完成之后,进行租赁就可以了。
注意:如果像上传资源,改代码这种操作可以使用无卡模式开机,计费会少很多,当训练模型的时候再使用GPU。
四、使用租赁GPU跑yolov5
1.filezilla的使用
在文首下载filezilla软件后,进行安装,来到主界面:
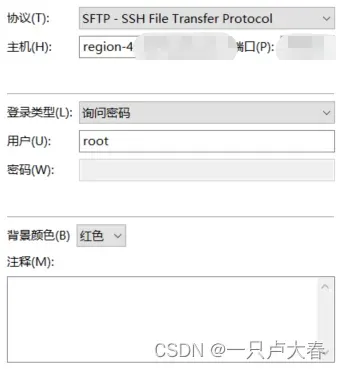
然后选择左上角文件->站点管理器,进入,先新建立站点,然后其他信息按你租赁的服务器信息填写,协议部分要填写SFTP
然后点击连接就行了,就可以连接到你租赁的GPU主机了。如果还有不懂,可以看这篇官方教学:
AutoDL帮助文档
连接之后主界面就是这个样子,我们可以将本地的yolov5文件夹上传到root的子文件夹下(选中本地文件夹右键即可选择上传):
2.pycharm连接AutoDL
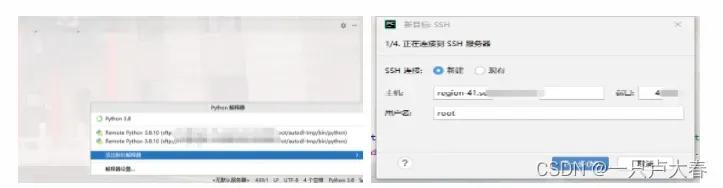
选择pycharm右下方解释器部分,选择添加新的解释器,然后选择SSH添加,按步骤输入用户名密码等内容:
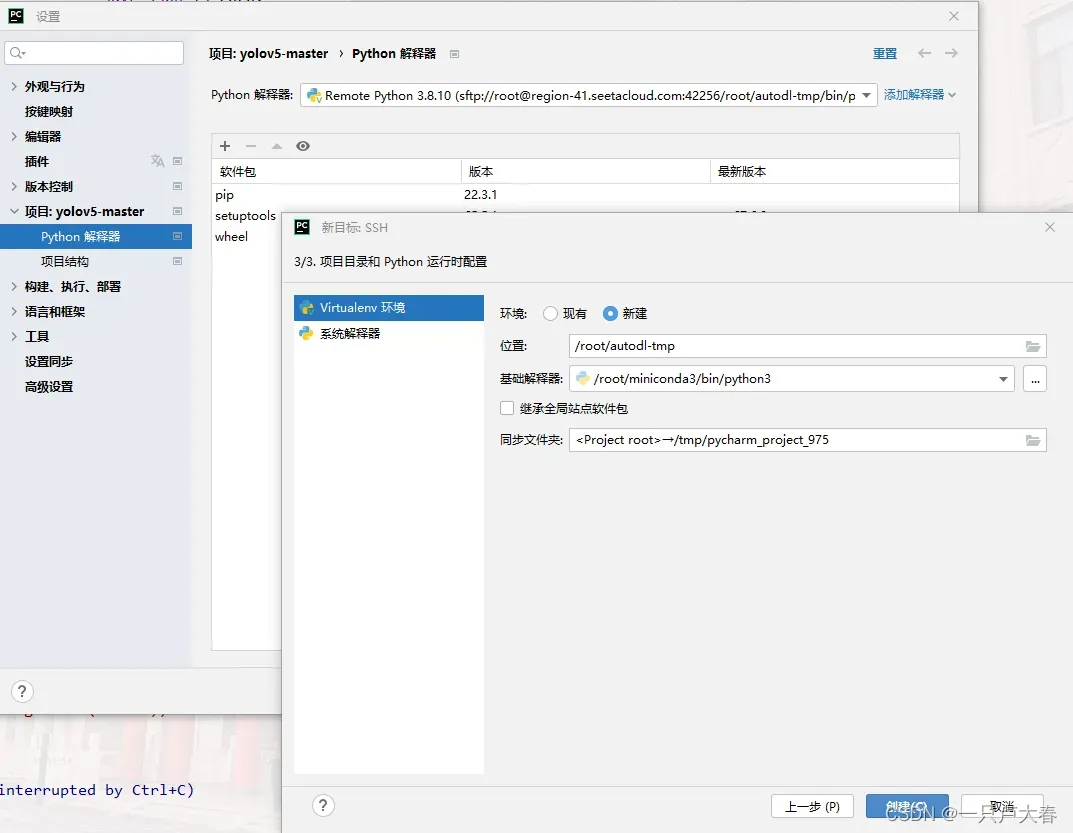
到达最后一步创建虚拟环境时,按下图进行配置即可:
完成以上步骤之后,你就能成功使用pycharm连接上远程GPU了。在连上初始化时,pycharm会对解释器更新,上传资源等操作。由于我们刚刚已经使用filezilla上传过程序了,这时把进程中上传资源的进程取消掉即可。
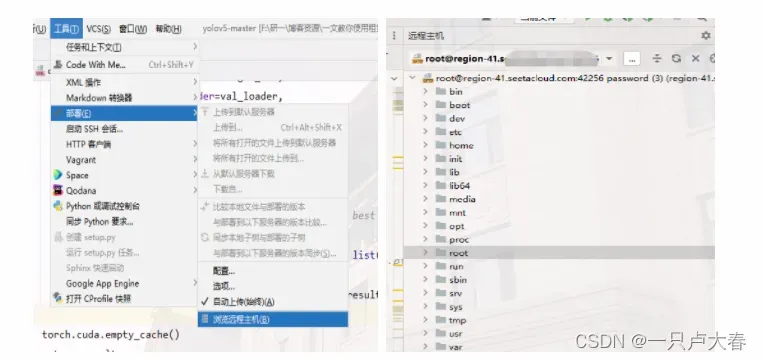
然后,我们选择工具->部署->浏览远程主机就可以在pycharm中右侧查看自己的远程主机了。
3.训练模型
在pycharm中选择终端处,然后选择我们本次租赁的GPU,输入指令(python后是train.py的绝对路径):
python /root/yolov5-master/train.py
这样就可以进行训练了。另外需要注意的是,在pycharm中进行远程文件的修改时,修改完需要上传,保证与远程文件一致。
训练完成的权重文件在runs/train/exp/weights文件夹下,你可以选择best.pt或者last.pt,通过filezilla进行下载。如果对本次训练结果不满意,可以增加训练轮数或者更改其他参数,要记得train.py中第437行weights部分的权重进行更改,如:
'runs/train/exp4/weights/best.pt'
训练完成后,可以看到我们本次训练的结果还是可以的:

参考资源
【Yolov5】1.认真总结6000字Yolov5保姆级教程(2022.06.28全新版本v6.1)_yolov5教学_若oo尘的博客-CSDN博客
yolov5——train.py代码【注释、详解、使用教程】_Charms@的博客-CSDN博客
autoDL租用服务器运行程序全过程-CSDN博客
文章出处登录后可见!