(2022 CVPR) U2PL
Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
Motivation:
半监督语义分割的关键是为未标记图像的像素分配足够的伪标签。
即使是不可靠的预测结果,虽然无法打上确定的伪标签,但仍可以作为部分类别的负样本,从而参与到模型的训练,从而让所有的无标签样本都能在训练过程中发挥作用。
Method:
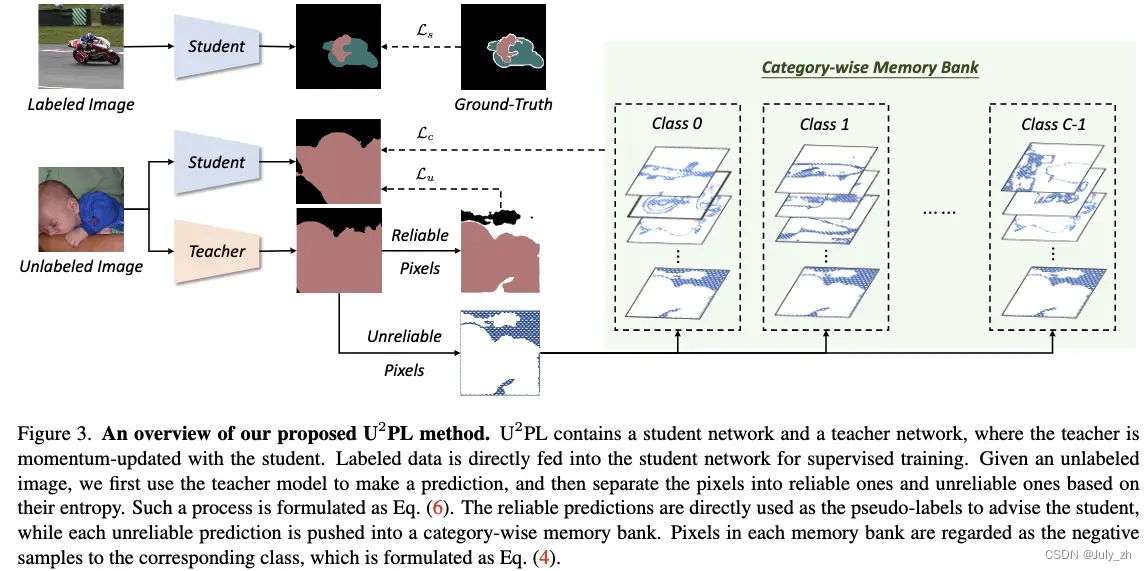
教师网络和学生网络:学生网络权重更新和一般网络更新过程相同,教师网络用EMA更新网络权重。
通过预测熵来分离可靠和不可靠像素,将每个不可靠像素推送到由负样本组成的类别队列中
在训练过程中,等量地选取B张labeled images和B张unlabeled images,对于每张带标签的图像目的是减小cross entropy loss;对于每张unlabeled image,teacher model进行预测,根据 pixel-level entropy 将预测结果分成 reliable pixels 和 unreliable pixels 两大部分, 然后选择reliable的伪标签计算upervised loss;对于剩余的unreliable的标签将通过contrastive loss. [InfoNCE Loss]
Pseudo-Labeling
无标签样本中可靠预测结果的利用方式,即损失函数中的Lu部分,通过熵
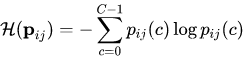
对预测结果的可靠性进行衡量,将最可靠的部分筛选出来,再通过常规方式打上伪标签
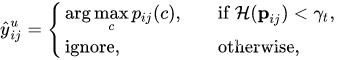
随着训练过程的推进,模型的性能在不断攀升,不可靠预测结果的比例相适应地也在不断下降,因此在不同的训练时刻对可靠部分的定义是不断变化的,这里简单采用了线性变化策略,
![]()
Using Unreliable Pseudo-Labes
无标签样本中不可靠预测结果的利用方式,即损失函数中的 Lc部分
- anchor pixels(queries)
- positive samples for each anchor
每一个类别都算一个特征中心,同一类的 anchor pixel 会 share 共同的特征中心作为 postive sample。 - negative samples for each anchor
对于有标签样本,每个类别对应的负样本是该类别的易混样本:
1)不属于类别c;(2)难以区分是c类别还是其Ground Truth
对于无标签样本,由于伪标签可能存在错误,将预测概率最高的几个类别过滤掉,将该像素认作为剩下几个类别的负样本。
1)伪标签是unreliable的;(2)可能不属于c类别;(3)不属于大部分不可能的类别
由于数据集中存在长尾问题,如果只使用一个 batch 的样本作为对比学习的负样本可能会非常受限,因此我们采用 MemoryBank 来维护一个类别相关的负样本库,存入的是由 teacher 生成的断梯度特征,以先进先出的队列结构维护。

Experiments
训练时间长,
文章出处登录后可见!