🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 – 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋

文章目录
在第 1 章“神经网络的基本要素”和第 2 章“理解卷积网络”中,我们深入研究了一般前馈网络及其专门化身卷积神经网络( CNN ) 的属性。在本章中,我们将使用循环神经网络(RNNs)。我们在前几章中讨论的 NN 架构接受固定大小的输入并提供固定大小的输出。RNN 通过定义这些序列上的循环关系(因此得名)来处理可变长度的输入序列的能力,从而解除了这一限制。如果您熟悉本章将讨论的一些主题,则可以跳过它们。
在本章中,我们将介绍以下主题:
- RNN 简介
- 引入长短期记忆
- 引入门控循环单元
- 实现文本分类
RNN 简介
RNN 是 可以 处理具有可变长度的序列数据的神经网络。此类数据的示例包括句子中的单词或不同时间点的股票价格。通过使用序列这个词,我们暗示序列的元素彼此相关并且它们的顺序很重要。例如,如果我们拿一本书随机打乱其中的所有单词,即使我们仍然知道单个单词,文本也会失去意义。自然地,我们可以使用 RNN 来解决与序列数据相关的任务。此类任务的示例包括语言翻译、语音识别、预测时间序列的下一个元素等。
RNN 之所以得名,是因为它们在序列上反复应用相同的函数。我们可以将 RNN 定义为递归关系:
![]()
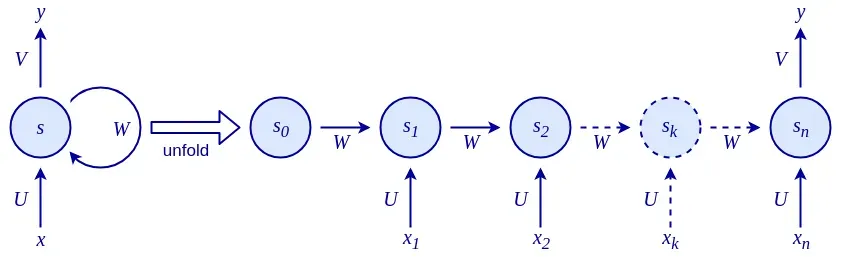
这里,f 是一个可微函数,s t 是称为内部网络状态(在步骤t处)的值向量,x t是在步骤t处的网络输入。与状态仅取决于当前输入(和网络权重)的常规网络不同,这里的 s t是当前输入和先前状态s t-1的函数。你可以想到s t-1 作为网络对所有先前输入的总结。这与仅将当前输入样本作为输入的常规前馈网络(包括 CNN)不同。递归关系定义了状态如何通过对先前状态的反馈循环在序列中逐步演化,如下图所示: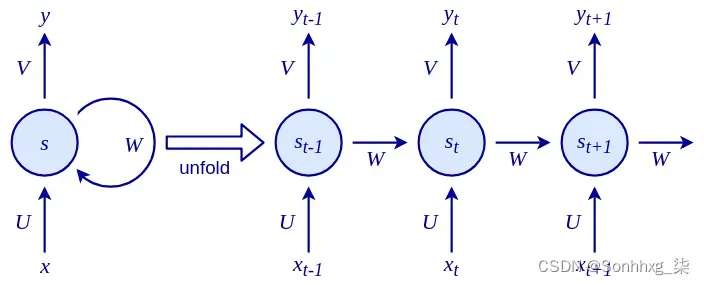
RNN 具有三组参数(或权重):
- U将输入x t转换为状态s t 。
- W将先前状态s t-1转换为当前状态s t 。
- V将新计算的内部状态s t 映射到输出y t 。
U、V和W对各自的输入应用线性变换。这种转换的最基本情况是我们熟悉和喜爱的加权和。我们现在可以定义内部状态和网络输出如下:
![]()
![]()
这里,f是非线性激活函数(例如 tanh、sigmoid 或 ReLU)。
例如,在单词级语言模型中,输入x将是在输入向量( x 1 … x t …)中编码的单词序列。状态s将是一系列状态向量( s 1 … s t … )。最后,输出y将是序列中下一个单词的概率向量序列( y 1 … y t … )。
请注意,在 RNN 中,每个状态都依赖于通过此递归关系进行的所有先前计算。一个重要的含义是,RNN 会随着时间的推移而具有记忆力,因为状态s包含基于前面步骤的信息。理论上,RNN 可以在任意长的时间内记住信息,但在实践中,它们仅限于回顾几步。我们将在消失和爆炸梯度部分更详细地解决这个问题。
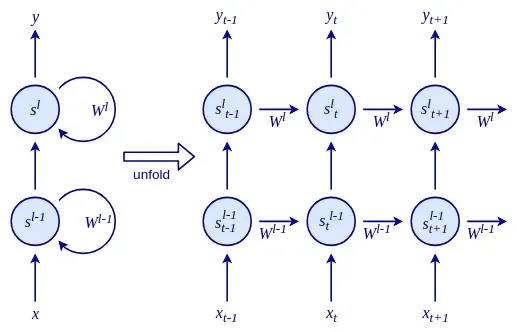
我们这里描述的 RNN 有点等价于单层常规神经网络(具有额外的递归关系)。正如我们现在从第 1 章“神经网络的基本要素”中了解到的那样,单层网络有一些严重的局限性。不要害怕!与常规网络一样,我们可以堆叠多个 RNN 以形成堆叠 RNN。在时间t的层l的 RNN 单元的单元状态s l t将采用来自层l-1的RNN单元的输出y t l- 1和前一个单元状态s l t-1 ,在同一级别的单元格中,l ,作为输入:
![]()
在下图中,我们 可以 看到一个展开的堆叠 RNN:
到目前为止,我们讨论的 RNN 采用序列的前面元素来产生输出。这对于诸如时间序列预测之类的任务是有意义的,我们希望根据之前的元素来预测序列的下一个元素。但它也对其他任务施加了不必要的限制,例如来自 NLP 领域的任务。正如我们在第 6 章,语言建模中看到的,我们可以通过上下文获得关于一个单词的大量信息,并且从前面和后面的单词中提取上下文是有意义的。
我们可以将常规 RNN 扩展到所谓的双向 RNN来覆盖这种场景,如下图所示: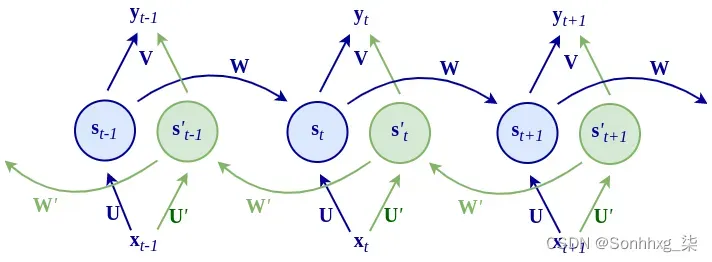
该网络有两个双向传播循环,即从步骤t到t+1从左到右,从步骤t+1到t从右到左。我们将用 prim 符号表示从右到左传播相关的符号(不要与导数混淆)。在每个时间步t ,网络维护两个内部状态向量:s t用于从左到右的传播,s ‘ t用于从右到左的传播。从右到左的阶段有自己的一组输入权重U’和W’,镜像权重U和W,用于从左到右的相位。从右到左隐藏状态向量的公式如下:
![]()
网络的输出y t是内部状态s t和s t+1的组合。组合它们的一种方法是连接。在这种情况下,我们将用V表示连接状态到输出的权重矩阵。这里,输出的公式如下:
![]()
或者,我们可以简单地将两个状态向量相加:
![]()
因为 RNN 不仅限于处理固定大小的输入,它们确实扩展了我们可以用神经网络计算的可能性,例如不同长度的序列或不同大小的图像。
让我们来看看一些不同的组合:
- 一对一:这是非顺序处理,例如前馈神经网络和CNN。请注意,前馈网络和将 RNN 应用于单个时间步长之间没有太大区别。一对一处理的一个例子是图像分类,我们在第 2 章,理解卷积网络和第 3 章,高级卷积网络中看到。
- 一对多:此处理基于单个输入生成序列,例如,从图像生成标题(Show and Tell: A Neural Image Caption Generator,https://arxiv.org/abs/1411.4555 )。
- 多对一:此处理基于序列输出单个结果,例如文本的情感分类。
- 多对多间接:一个序列被编码成一个状态向量,然后这个状态向量被解码成一个新的 序列,例如语言翻译(Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation,https:// /arxiv.org/abs/1406.1078和使用神经网络进行序列到序列学习,http ://papers.nips.cc/paper/5346-sequence-to-sequence-learning-with-neural-networks.pdf )。
- 多对多直接:这为 每个输入步骤输出一个结果,例如,语音识别中的帧 音素 标记。
以下是上述输入输出组合的图形表示: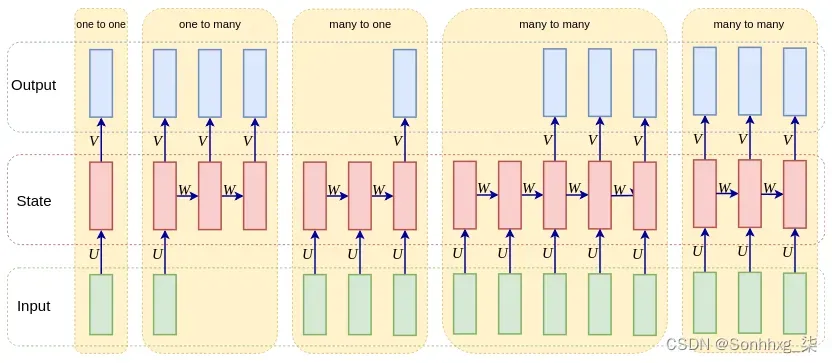
现在我们已经介绍了 RNN,在下一节中,我们将从头开始实现一个简单的 RNN 示例以提高我们的知识。
RNN 实施与训练
在上一节中,我们简要讨论了 RNN 是什么以及它们 可以 解决哪些问题。让我们通过一个非常简单的玩具示例来深入了解 RNN 的细节以及如何训练它:按序列计数。
在这个问题中,我们将教一个基本的 RNN 如何 计算 输入中 1 的数量,然后在序列末尾输出结果。这是我们在上一节中定义的多对一关系的示例。
我们将使用 Python(无 DL 库)和 NumPy 来实现这个示例。输入输出示例如下:
In: (0, 0, 0, 0, 1, 0, 1, 0, 1, 0)
Out: 3我们将使用的 RNN 如下图所示:
该网络将只有两个参数:输入权重U和递归权重W。输出权重V设置为 1 ,因此我们只需读出最后一个状态作为输出y。
在继续之前,让我们添加一些代码以便我们的示例可以执行。我们将导入并定义我们的训练和数据,和标签,。是二维的,因为第一维代表小批量中的样本。为简单起见,我们将使用带有单个样本的小批量: numpy xy x
import numpy as np
# The first dimension represents the mini-batch
x = np.array([[0, 0, 0, 0, 1, 0, 1, 0, 1, 0]])
y = np.array([3])这个网络定义的递归关系是![]() 。请注意,这是一个线性模型,因为我们在这个公式中没有应用非线性函数。我们可以如下实现一个递归关系 :
。请注意,这是一个线性模型,因为我们在这个公式中没有应用非线性函数。我们可以如下实现一个递归关系 :
def step(s, x, U, W):
return x * U + s * W状态s t和权重W和U是单个标量值。一个很好的解决方案是只获得整个序列的输入 总和 。如果我们设置U=1,那么无论何时收到输入,我们都会得到它的完整值。如果我们设置W=1,那么我们将累积的值将永远不会衰减。因此,对于此示例,我们将获得所需的输出:3。
尽管如此,让我们使用这个简单的例子来网络化这个神经网络的训练和实现。正如我们将在本节的其余部分中看到的那样,这将很有趣。首先,让我们看看如何通过反向传播得到这个结果。
时间反向传播
时间反向传播是我们用来 训练 循环网络的典型算法(时间反向传播:它的作用和方法,http://axon.cs.byu.edu/~martinez/classes/678/Papers/Werbos_BPTT。 .pdf )。顾名思义,它基于我们在第 1 章“神经网络的基本要素”中讨论的反向传播算法。
常规反向传播和随时间反向传播的主要区别在于,循环网络是随时间展开一定数量的时间步长(如上图所示)。一旦展开完成,我们最终会得到一个与常规多层前馈网络非常相似的模型,也就是说,该网络的一个隐藏层代表时间的一个步骤。唯一的区别是每一层都有多个输入:前一个状态s t-1和当前输入x t。参数U和W在所有隐藏层之间共享。
前向传递沿序列展开 RNN,并为每个步骤构建一个状态堆栈。在下面的代码块中,我们可以看到前向传递的实现,它为每个循环步骤和批处理中的每个样本返回激活值s:
def forward(x, U, W):
# Number of samples in the mini-batch
number_of_samples = len(x)
# Length of each sample
sequence_length = len(x[0])
# Initialize the state activation for each sample along the sequence
s = np.zeros((number_of_samples, sequence_length + 1))
# Update the states over the sequence
for t in range(0, sequence_length):
s[:, t + 1] = step(s[:, t], x[:, t], U, W) # step function
return s现在我们有了前向步骤和损失函数,我们可以定义梯度如何向后传播。由于展开的 RNN 相当于一个常规的前馈网络,我们可以使用我们在第 1 章“神经网络的基本要素”中介绍的反向传播链式法则。
因为权重W 和U是跨层共享的,所以我们将累积每个循环步骤的误差导数,最后,我们将使用累积值更新权重。
首先,我们需要得到输出相对于损失函数 ( ∂J/∂s )的梯度s t 。一旦我们拥有它,我们将通过我们在向前步骤中构建的活动堆栈向后传播它。这种向后传递将活动从堆栈中弹出,以在每个时间步累积它们的误差导数。通过网络传播这个梯度的递归关系可以写成如下(链式法则):
![]()
这里,J 是损失函数。
权重U和W的梯度累积如下:
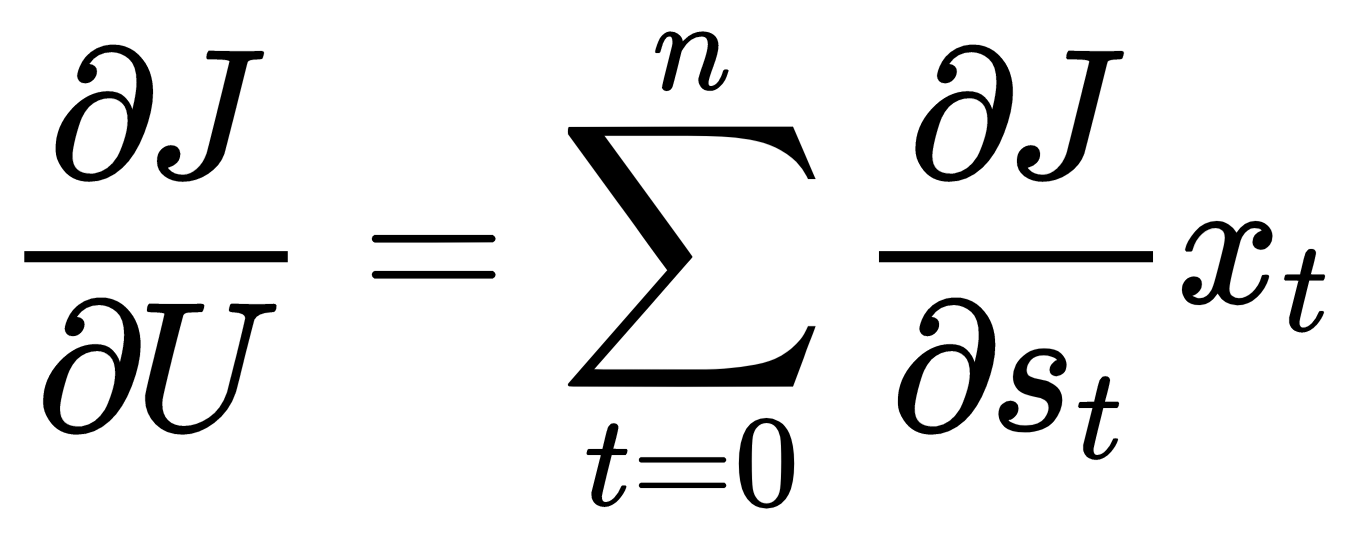
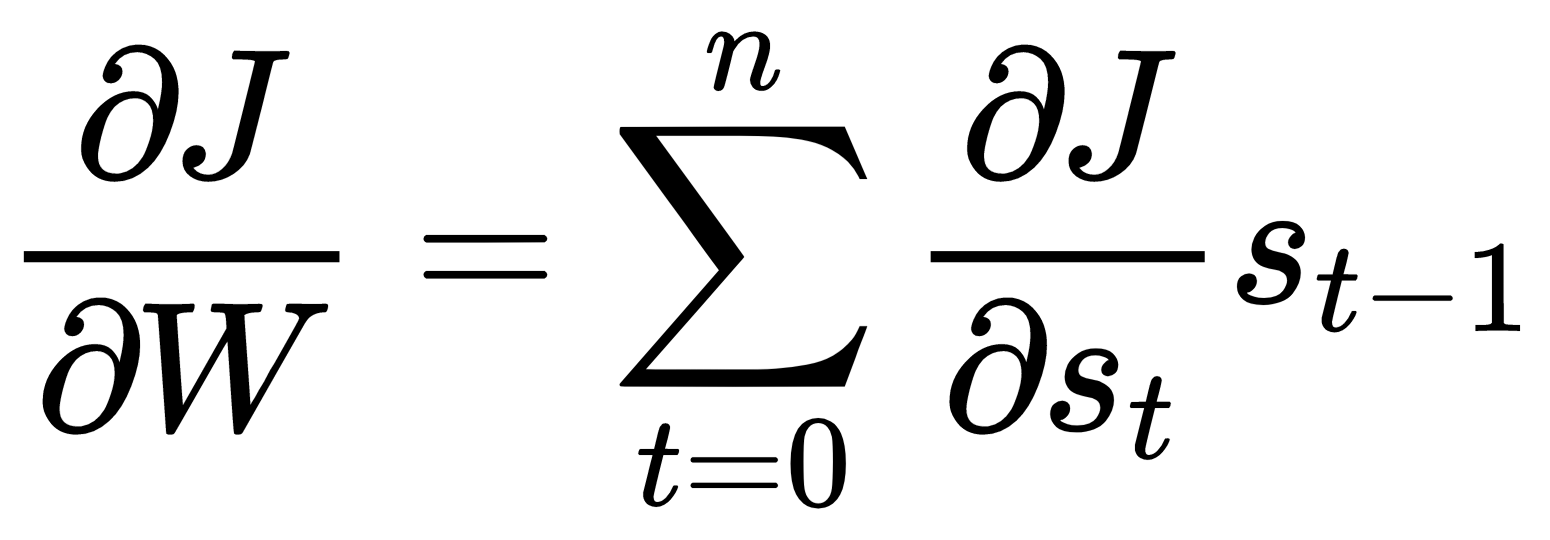
以下是反向传递的实现:
1.和的梯度分别在和中累积: U W gU gW
def backward(x, s, y, W):
sequence_length = len(x[0])
# The network output is just the last activation of sequence
s_t = s[:, -1]
# Compute the gradient of the output w.r.t. MSE loss function
at final state
gS = 2 * (s_t - y)
# Set the gradient accumulations to 0
gU, gW = 0, 0
# Accumulate gradients backwards
for k in range(sequence_length, 0, -1):
# Compute the parameter gradients and accumulate the
results
gU += np.sum(gS * x[:, k - 1])
gW += np.sum(gS * s[:, k - 1])
# Compute the gradient at the output of the previous layer
gS = gS * W
return gU, gW2.我们现在可以尝试使用梯度下降来 优化 我们的网络。我们在函数的帮助下计算gradients(使用均方误差)backward并使用它们来更新weights值:
def train(x, y, epochs, learning_rate=0.0005):
"""Train the network"""
# Set initial parameters
weights = (-2, 0) # (U, W)
# Accumulate the losses and their respective weights
losses = list()
gradients_u = list()
gradients_w = list()
# Perform iterative gradient descent
for i in range(epochs):
# Perform forward and backward pass to get the gradients
s = forward(x, weights[0], weights[1])
# Compute the loss
loss = (y[0] - s[-1, -1]) ** 2
# Store the loss and weights values for later display
losses.append(loss)
gradients = backward(x, s, y, weights[1])
gradients_u.append(gradients[0])
gradients_w.append(gradients[1])
# Update each parameter `p` by p = p - (gradient *
learning_rate).
# `gp` is the gradient of parameter `p`
weights = tuple((p - gp * learning_rate) for p, gp in
zip(weights, gradients))
print(weights)
return np.array(losses), np.array(gradients_u),
np.array(gradients_w)3.接下来,我们将实现相关的plot_training函数,它显示loss函数和每个权重在 epoch 上的梯度:
def plot_training(losses, gradients_u, gradients_w):
import matplotlib.pyplot as plt
# remove nan and inf values
losses = losses[~np.isnan(losses)][:-1]
gradients_u = gradients_u[~np.isnan(gradients_u)][:-1]
gradients_w = gradients_w[~np.isnan(gradients_w)][:-1]
# plot the weights U and W
fig, ax1 = plt.subplots(figsize=(5, 3.4))
ax1.set_ylim(-3, 20)
ax1.set_xlabel('epochs')
ax1.plot(gradients_u, label='grad U', color='blue',
linestyle=':')
ax1.plot(gradients_w, label='grad W', color='red', linestyle='--
')
ax1.legend(loc='upper left')
# instantiate a second axis that shares the same x-axis
# plot the loss on the second axis
ax2 = ax1.twinx()
# uncomment to plot exploding gradients
ax2.set_ylim(-3, 10)
ax2.plot(losses, label='Loss', color='green')
ax2.tick_params(axis='y', labelcolor='green')
ax2.legend(loc='upper right')
fig.tight_layout()
plt.show()4.最后,我们可以 运行 这段代码:
losses, gradients_u, gradients_w = train(x, y, epochs=150)
plot_training(losses, gradients_u, gradients_w)前面的代码生成下 图:
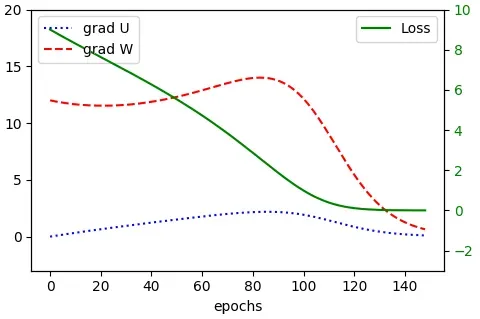
现在我们已经了解了反向传播,让我们讨论熟悉的梯度消失和爆炸问题如何影响它。
消失和爆炸梯度
但是,前面的示例 有 一个问题。让我们以更长的序列运行训练过程:
x = np.array([[0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0]])
y = np.array([12])
losses, gradients_u, gradients_w = train(x, y, epochs=150)
plot_training(losses, gradients_u, gradients_w)输出如下:
Sum of ones RNN from scratch
chapter07-rnn/simple_rnn.py:5: RuntimeWarning: overflow encountered in multiply
return x * U + s * W
chapter07-rnn/simple_rnn.py:40: RuntimeWarning: invalid value encountered in multiply
gU += np.sum(gS * x[:, k - 1])
chapter07-rnn/simple_rnn.py:41: RuntimeWarning: invalid value encountered in multiply
gW += np.sum(gS * s[:, k - 1])
(nan, nan)这些警告的原因是最终参数U和W以非数字( NaN )结尾。为了正确显示梯度,我们需要将函数中梯度轴的比例从更改为,以及将损失轴的比例从更改为。 plot_trainingax1.set_ylim(-3, 20)ax1.set_ylim(-3, 600)ax2.set_ylim(-3, 10)ax2.set_ylim(-3, 200)
现在,程序将生成新的损失和梯度的下图:
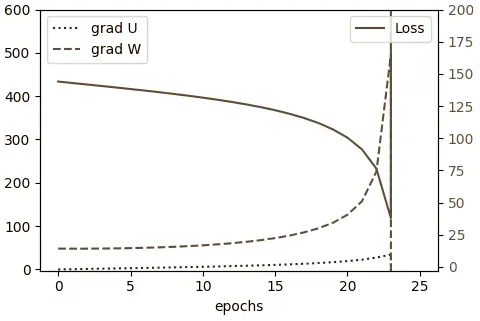
在初始时期,梯度缓慢增加,类似于它们在较短序列中增加的方式。然而,当它们到达 epoch 23(确切的 epoch 并不重要)时,梯度变得如此之大,以至于超出了float变量的范围并变为 NaN(如图中的跳跃所示)。这个问题被称为梯度爆炸。我们可以在常规前馈神经网络中偶然发现爆炸梯度,但在 RNN 中尤其明显。为了理解为什么,让我们回顾一下我们在通过时间的反向传播部分定义的两个连续序列步骤的循环梯度传播链规则:
![]()
根据序列的长度,展开的 RNN 可以比常规网络更深。同时, RNN的权重W在所有步骤中共享。因此,我们可以推广这个公式来计算序列的两个非连续步骤之间的梯度。因为W是共享的,所以方程形成一个几何级数:
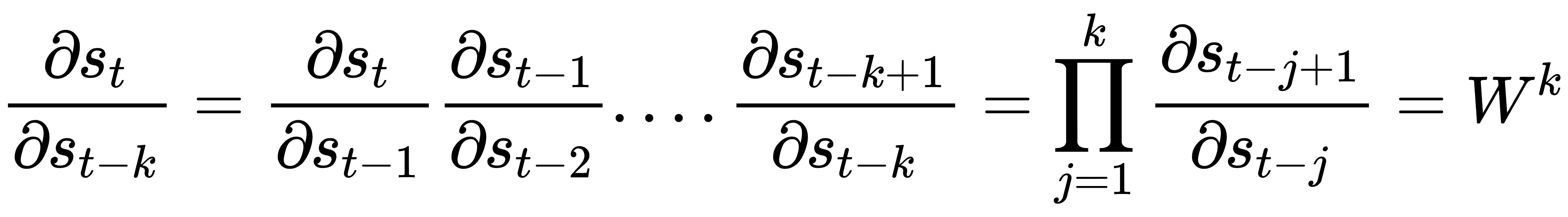
在我们简单的线性 RNN 中,如果|W| ,梯度呈指数增长。> 1(爆炸梯度),其中W是单个标量权重,例如,W=1.5 上的 50 个时间步是W 50 ≈ 637621500。如果|W|则梯度呈指数收缩 <1(梯度消失),例如,W=0.6上的 10 个时间步是W 20 = 0.00097 。如果权重参数W是矩阵而不是标量,则此爆炸或消失梯度与W的最大特征值 ( ρ ) 有关 (也称为光谱半径)。ρ < 1足以使梯度消失,而ρ > 1则它们必须爆炸。
我们在第 1 章“神经网络的基本要素”中首次提到的梯度消失问题在 RNN 中还有另一个更微妙的影响。梯度随着步数呈指数衰减,直到在早期状态下变得非常小。实际上,它们被最近时间步的更大梯度所掩盖,并且网络保留这些早期状态历史的能力消失了。这个问题更难检测,因为训练仍然有效并且网络将产生有效的输出(与爆炸梯度不同)。它只是无法学习长期依赖关系。
现在,我们熟悉了 RNN 的一些问题。这些知识对我们很有帮助,因为在下一节中,我们将讨论如何在特殊类型的 RNN 的帮助下解决这些问题。
引入长短期记忆
Hochreiter 和 Schmidhuber 广泛研究了梯度消失和爆炸的问题,并提出了一种称为长短期记忆(LSTM,https: //www.bioinf.jku.at/publications/older/2604.pdf )的解决方案。由于特制的记忆单元,LSTM 可以处理长期依赖关系。事实上,它们工作得非常好,以至于目前在各种问题上训练 RNN 的大部分成就都归功于 LSTM 的使用。在本节中,我们将探讨此存储单元的工作原理以及它如何解决梯度消失问题。
LSTM 的关键思想是单元状态c t(除了隐藏的 RNN 状态h t),其中信息只能显式写入或删除,以便在没有外部干扰的情况下保持状态不变。细胞状态只能通过特定的门来修改,这是让信息通过的一种方式。这些门由 sigmoid 函数和元素乘法组成。因为 sigmoid 只输出 0 和 1 之间的值,所以乘法只能减少通过门的值。典型的 LSTM 由三个门组成:遗忘门、输入门和输出门。单元状态、输入和输出都是向量,因此 LSTM 可以在每个时间步保存不同信息块的组合。
下面是一个 LSTM 单元的示意图: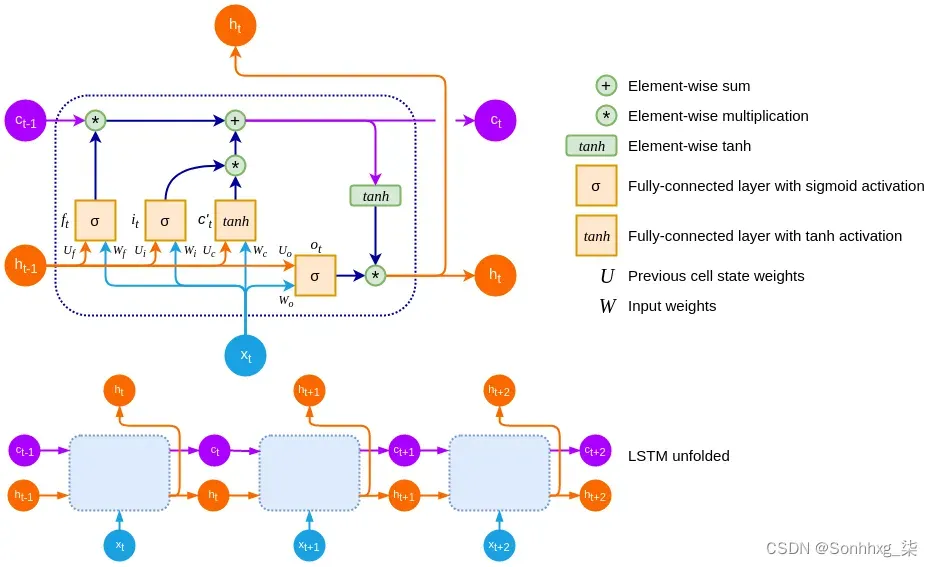
在继续之前,让我们介绍一些符号。x t、c t和h t是 LSTM 在时刻t的输入、单元记忆状态和输出(或隐藏状态)向量。c ‘ t是候选细胞状态向量(稍后会详细介绍)。输入x t和前一个单元输出h t-分别通过全连接权重集W和U连接到每个门和候选单元向量。f t、i t和 o t是 LSTM 单元的遗忘门、输入门和输出门。这些门是具有 sigmoid 激活的全连接层。
让我们从遗忘门f t开始。顾名思义,它决定了我们是否要删除现有单元状态的一部分。它的决策基于前一个单元格的输出h t-1和当前输入x t的加权向量和:
![]()
从上图中,我们可以看到遗忘门对前一个状态向量c t-1 : f t * c t -1的每个元素应用了元素级 sigmoid 激活。再次注意,由于操作是逐元素的,因此该向量的值被压缩在 [0, 1] 范围内。输出 0 完全擦除特定的c t-1 单元块,输出 1 允许该单元块中的信息通过。这意味着 LSTM 可以摆脱其细胞状态向量中的不相关信息。
输入门i t决定在多步骤过程中将哪些新信息添加到存储单元中。第一步确定是否要添加任何信息。与遗忘门一样,它的决策基于h t-1和x t:它通过 sigmoid 函数为候选状态向量的每个单元输出 0 或 1。输出 0 意味着没有信息被添加到该单元块的内存中。因此,LSTM 可以在其单元状态向量中存储特定的信息:
![]()
在下一步中,我们计算新的候选单元状态c’t。它基于先前的输出h t-1和当前输入x t,并通过 tanh 函数进行转换:
![]()
接下来,通过逐元素乘法将c’t与输入门的 sigmoid 输出相结合![]() 。
。
回顾一下,遗忘门和输入门分别从先前的和候选的细胞状态中决定要忘记和包含哪些信息。新单元状态的最终版本c t只是这两个组件之间的元素总和:
![]()
接下来,让我们关注输出门,它决定了单元格的总输出。它将h t-1和x t作为输入和输出,即 0 或 1(通过 sigmoid 函数),用于单元内存的每个块。和之前一样,0 表示块不输出任何信息,1 表示块可以作为单元格的输出通过。因此,LSTM 可以从其单元状态向量中输出特定的信息块:
![]()
最后,LSTM 单元输出由 tanh 函数传输:
![]()
因为所有这些公式都是可推导的,所以我们可以将 LSTM 单元链接在一起,就像我们将简单的 RNN 状态链接在一起并通过时间反向传播训练网络一样。
但是 LSTM 如何保护我们免受梯度消失的影响呢?让我们从前进阶段开始。请注意,如果忘记门为 1 且输入门为 0,则每个步骤的单元状态复制相同![]() :只有遗忘门才能完全抹去细胞的记忆。结果,内存可以在很长一段时间内保持不变。另外,请注意,输入是 已添加到当前单元格内存中的 tanh 激活。这意味着单元的内存不会爆炸并且非常稳定。
:只有遗忘门才能完全抹去细胞的记忆。结果,内存可以在很长一段时间内保持不变。另外,请注意,输入是 已添加到当前单元格内存中的 tanh 激活。这意味着单元的内存不会爆炸并且非常稳定。
让我们用一个例子来演示一个 LSTM 单元是如何展开的。为简单起见,我们假设它具有一维(单标量值)输入、状态和输出向量。因为这些值是标量,所以我们不会在此示例的其余部分使用向量表示法:
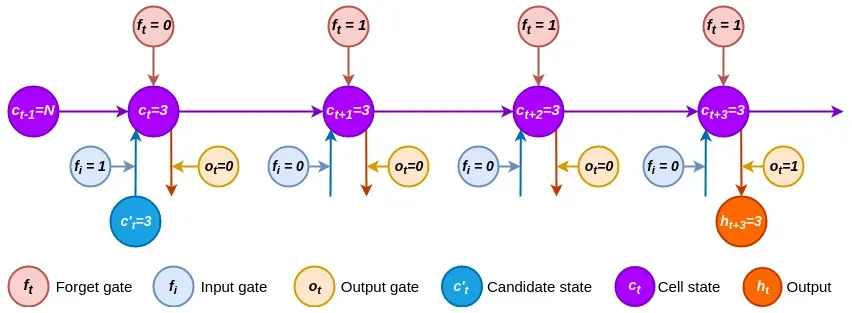
过程如下:
- 首先,我们将值 3 作为候选状态。输入门设置为f i = 1,遗忘门设置为f t = 0。这意味着先前的状态c t-1 = N被擦除并被新状态 替换
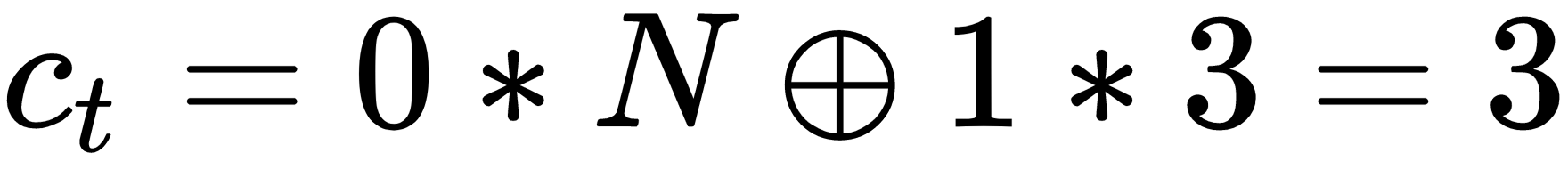 。
。 - 对于接下来的两个时间步,遗忘门设置为 1,而输入门设置为 0。这样做,所有信息都保留在这些步骤中,并且不会添加新信息,因为输入门设置为0
 :。
:。 - 最后,输出门设置为o t = 1,输出 3 并保持不变。我们已经成功演示了如何跨多个步骤存储内部状态。
接下来,让我们关注落后阶段。单元状态c t也可以在遗忘门f t的帮助下减轻消失/爆炸梯度。与常规 RNN 一样,我们可以使用链式法则计算![]() 两个连续步骤的偏导数 。根据
两个连续步骤的偏导数 。根据![]() 公式,不再赘述,其偏导数如下:
公式,不再赘述,其偏导数如下:
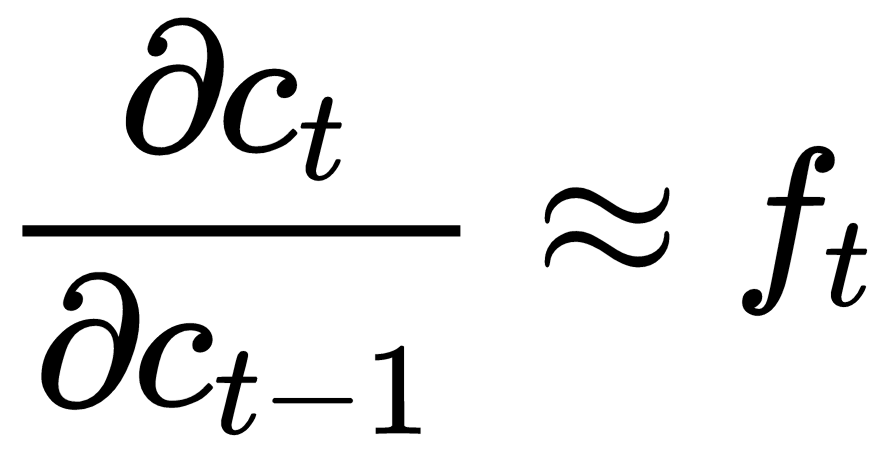
我们也可以将其推广到非连续步骤:
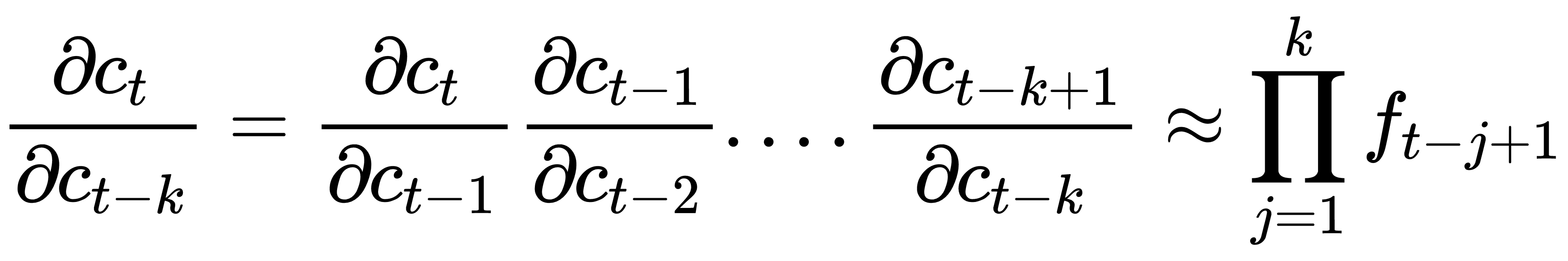
如果遗忘门值接近 1,梯度信息可以几乎不变地通过网络状态传回。这是因为ft使用sigmoid激活,并且信息流仍然受制于 sigmoid 激活特有的消失梯度(第 1 章,神经网络的基本要素)。但与常规 RNN 中的梯度不同,f t在每个时间步都有不同的值。因此,这不是几何级数,梯度消失效应不太明显。
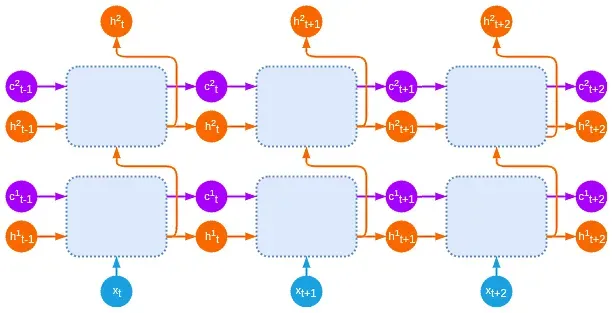
我们可以以与堆叠常规 RNN 相同的方式堆叠 LSTM 单元,不同之处在于在一个级别的步骤t的单元状态用作步骤t+1的同一级别的单元状态的输入。下图显示了展开的堆叠 LSTM:
现在我们已经介绍了 LSTM,让我们通过在下一节中实现它来巩固我们的知识。
实现 LSTM
在本节中,我们将使用 PyTorch 1.3.1 实现一个 LSTM 单元。首先,让我们注意 PyTorch 已经有一个 LSTM 实现,可以在torch.nn.LSTM. 但是,我们的目标是了解 LSTM 单元的工作原理,因此我们将从头开始实现我们自己的版本。该单元将是的子类,torch.nn.Module我们将使用它作为更大模型的构建块。此示例的源代码可在Advanced-Deep-Learning-with-Python/lstm_cell.py at master · PacktPublishing/Advanced-Deep-Learning-with-Python · GitHub获得。让我们开始吧:
1.首先,我们将进行导入:
import math
import typing
import torch2.接下来,我们将实现类和__init__方法:
class LSTMCell(torch.nn.Module):
def __init__(self, input_size: int, hidden_size: int):
"""
:param input_size: input vector size
:param hidden_size: cell state vector size
"""
super(LSTMCell, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# combine all gates in a single matrix multiplication
self.x_fc = torch.nn.Linear(input_size, 4 * hidden_size)
self.h_fc = torch.nn.Linear(hidden_size, 4 * hidden_size)
self.reset_parameters()为了理解全连接层self.x_fc和self.h_fc的作用,让我们回想一下,候选单元状态以及输入、遗忘和输出门都依赖于输入xt 和前一个单元输出ht-1 self.h_fc的加权向量和。因此,我们可以将它们组合起来并制作两个大的全连接层,而不是每个单元格有八个单独的![]() 和
和![]() 操作,并且每个输出大小为4 * hidden_size。一旦我们需要特定门的输出,我们可以从全连接层的两个张量输出中的任何一个中提取必要的切片(我们将在forward方法的实现中看到如何做到这一点)。
操作,并且每个输出大小为4 * hidden_size。一旦我们需要特定门的输出,我们可以从全连接层的两个张量输出中的任何一个中提取必要的切片(我们将在forward方法的实现中看到如何做到这一点)。
3.让我们继续这个reset_parameters方法,它使用 LSTM 特定的 Xavier 初始化器初始化网络的所有权重(如果直接复制并粘贴此代码,您可能需要检查缩进):
def reset_parameters(self):
"""Xavier initialization """
size = math.sqrt(3.0 / self.hidden_size)
for weight in self.parameters():
weight.data.uniform_(-size, size)4.接下来,我们将开始实现该方法,其中包含我们在介绍长短期记忆部分forward中描述的所有 LSTM 执行逻辑。它将步骤t的当前小批量以及包含步骤t-1的单元输出和单元状态的元组作为输入:
def forward(self,
x_t: torch.Tensor,
hidden: typing.Tuple[torch.Tensor, torch.Tensor] = (None, None)) \
-> typing.Tuple[torch.Tensor, torch.Tensor]:
h_t_1, c_t_1 = hidden # t_1 is equivalent to t-1
# in case of more than 2-dimensional input
# flatten the tensor (similar to numpy.reshape)
x_t = x_t.view(-1, x_t.size(1))
h_t_1 = h_t_1.view(-1, h_t_1.size(1))
c_t_1 = c_t_1.view(-1, c_t_1.size(1))5.我们将继续同时计算所有三个门和候选状态的激活。就像执行以下操作一样简单:
gates = self.x_fc(x_t) + self.h_fc(h_t_1)6.接下来,我们将拆分每个门的输出:
i_t, f_t, candidate_c_t, o_t = gates.chunk(4, 1)7.然后,我们将对activation它们应用函数:
i_t, f_t, candidate_c_t, o_t = \
i_t.sigmoid(), f_t.sigmoid(), candidate_c_t.tanh(), o_t.sigmoid()8.接下来,我们将计算新的单元状态c t:
c_t = torch.mul(f_t, c_t_1) + torch.mul(i_t, candidate_c_t)9.最后,我们将计算单元输出 ,ht并将其与新的单元状态c t一起返回:
h_t = torch.mul(o_t, torch.tanh(c_t))
return h_t, c_t一旦我们有了 LSTM 单元,我们就可以将它应用到对序列中的单元进行计数的相同任务中,就像我们对常规 RNN 所做的那样。我们只会包含源代码中最相关的部分,但完整的示例可在Advanced-Deep-Learning-with-Python/lstm_gru_count_1s.py at master · PacktPublishing/Advanced-Deep-Learning-with-Python · GitHub获得. 这一次,我们将使用 10,000 个长度为 20(这些是任意数字)的二进制序列的完整训练集。实现的前提类似于 RNN 示例:我们以循环方式将二进制序列馈送到 LSTM,并且单元将预测计数作为单个标量值输出(回归任务)。但是,我们的LSTMCell实现有两个限制:
- 它仅涵盖序列的一个步骤。
- 它输出细胞状态和网络输出向量。这是一个回归任务,我们只有一个输出值,但细胞状态和网络输出有更多维度。
为了解决这些问题,我们将实现一个自定义LSTMModel类,它扩展了LSTMCell. 它为LSTMCell实例提供序列的所有元素,并处理单元状态和网络输出从序列的一个元素到下一个元素的转换。
一旦产生了最终输出,它就会被馈送到一个全连接层,该层将其转换为一个单一的标量值,该值表示网络对个数的预测。下面是这个的实现:
class LSTMModel(torch.nn.Module):
def __init__(self, input_dim, hidden_size, output_dim):
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
# Our own LSTM implementation
self.lstm = LSTMCell(input_dim, hidden_size)
# Fully connected output layer
self.fc = torch.nn.Linear(hidden_size, output_dim)
def forward(self, x):
# Start with empty network output and cell state to initialize the sequence
c_t = torch.zeros((x.size(0), self.hidden_size)).to(x.device)
h_t = torch.zeros((x.size(0), self.hidden_size)).to(x.device)
# Iterate over all sequence elements across all sequences of the mini-batch
for seq in range(x.size(1)):
h_t, c_t = self.lstm(x[:, seq, :], (h_t, c_t))
# Final output layer
return self.fc(h_t)现在,我们将直接跳到训练/测试设置阶段(回想一下,这只是完整源代码的一个片段):
1.首先,我们将生成训练和测试数据集。该generate_dataset函数返回一个实例torch.utils.data.TensorDataset。它包含TRAINING_SAMPLES = 10000二进制序列的二维张量,长度为SEQUENCE_LENGTH = 20,标量值标签表示每个序列中的 1 的数量:
train = generate_dataset(SEQUENCE_LENGTH, TRAINING_SAMPLES)
train_loader = torch.utils.data.DataLoader(train, batch_size=BATCH_SIZE, shuffle=True)
test = generate_dataset(SEQUENCE_LENGTH, TEST_SAMPLES)
test_loader = torch.utils.data.DataLoader(test, batch_size=BATCH_SIZE, shuffle=True)2.我们将使用 实例化模型HIDDEN_UNITS = 20。该模型采用单个输入(每个序列元素)并输出单个值(个数):
model = LSTMModel(input_size=1, hidden_size=HIDDEN_UNITS, output_size=1)3.接下来,我们将实例化MSELoss函数(因为回归)和 Adam 优化器:
loss_function = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters())4.最后,我们可以运行EPOCHS = 10. train_model和功能与我们在第 2 章“理解卷积网络”的使用 PyTorch 实现迁移学习部分中实现的test_model功能相同:
for epoch in range(EPOCHS):
print('Epoch {}/{}'.format(epoch + 1, EPOCHS))
train_model(model, loss_function, optimizer, train_loader)
test_model(model, loss_function, test_loader)如果我们运行这个例子,网络将在 5-6 个 epoch 内达到 100% 的测试准确率。
现在我们已经了解了 LSTM,让我们将注意力转移到门控循环单元上。这是另一种类型的循环块,它试图复制 LSTM 的属性,但具有简化的结构。
引入门控循环单元
门控循环单元( GRU )是 2014 年引入的一种循环块(Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation,https: //arxiv.org/abs/1406.1078和门控循环神经网络的实证评估)序列建模网络,https: //arxiv.org/abs/1412.3555)作为对 LSTM 的改进。GRU 单元通常具有与 LSTM 相似或更好的性能,但它使用更少的参数和操作来做到这一点:
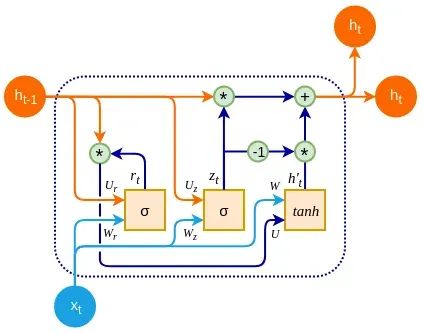
与经典的RNN 类似,GRU 单元具有单个隐藏状态h t。您可以将其视为 LSTM 的隐藏状态和单元状态的组合。GRU 单元有两个门:
- 一个更新门z t,它结合了输入和忘记 LSTM 门。它根据网络输入x t和先前的单元隐藏状态h t-1决定丢弃哪些信息以及在其位置包含哪些新信息。通过结合这两个门,我们可以确保单元格会忘记信息,但前提是我们要在其位置包含新信息:
![]()
- 重置门r t,它使用先前的单元状态h t-1和网络输入x t来决定要通过多少先前的状态:
![]()
接下来,我们有候选状态h ‘ t:
![]()
最后,在时间t的 GRU 输出h t是前一个输出h t−1和候选输出h ‘ t之间的元素总和:
![]()
由于更新门允许我们忘记和存储数据,因此它直接应用于先前的输出h t -1,并应用于候选输出h ‘ t。
实施 GRU
在本节中,我们将按照实施 LSTM部分的蓝图,使用 PyTorch 1.3.1 实施 GRU 单元。让我们开始吧:
1.首先,我们将进行导入:
import math
import torch2.接下来,我们将编写类定义和init方法。在 LSTM 中,我们能够为所有门创建一个共享的全连接层,因为每个门都需要x t和h t-1的相同输入组合。GRU 门使用不同的输入,因此我们将为每个 GRU 门创建单独的全连接操作:
class GRUCell(torch.nn.Module):
def __init__(self, input_size: int, hidden_size: int):
"""
:param input_size: 输入向量大小
:param hidden_size: 单元状态向量大小
"""
super(GRUCell, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# x 重置门 r
self.x_r_fc = torch.nn.Linear(input_size, hidden_size)
# x 更新门 z
self.x_z_fc = torch.nn.Linear(input_size, hidden_size)
# x 到候选状态 h'(t)
self.x_h_fc = torch.nn.Linear(input_size, hidden_size)
# 网络输出/状态 h(t-1) 重置门 r
self.h_r_fc = torch.nn.Linear(hidden_size, hidden_size)
# 网络输出/状态 h(t-1) 更新门 z
self.h_z_fc = torch.nn.Linear(hidden_size, hidden_size)
# 网络状态 h(t- 1) 通过复位门 r 向候选状态 h(t)
self.hr_h_fc = torch.nn.Linear(hidden_size, hidden_size)
我们将省略 的定义,reset_parameters因为它与LSTMCell.
3.然后,我们将按照我们在门控循环单元部分forward中描述的步骤来使用单元实现该方法。该方法将当前输入向量x t和先前的单元状态/输出h t-1作为输入。首先,我们将计算遗忘门和更新门,类似于我们在 LSTM 单元中计算门的方式:
def forward(self,
x_t: torch.Tensor,
h_t_1: torch.Tensor = None) \
-> torch.Tensor:
# 计算更新门向量
z_t = torch.sigmoid(self.x_z_fc(x_t) + self.h_z_fc(h_t_1))
# 计算复位门向量
r_t = torch.sigmoid(self.x_r_fc(x_t) + self.h_r_fc(h_t_1))4.接下来,我们将使用重置门计算新的候选状态/输出:
candidate_h_t = torch.tanh(self.x_h_fc(x_t) + self.hr_h_fc(torch.mul(r_t, h_t_1)))5.最后,我们将根据候选状态和更新门计算新输出:
h_t = torch.mul(z_t, h_t_1) + torch.mul(1 - z_t, candidate_h_t)我们可以使用与 LSTM 相同的方式使用 GRU 单元来实现任务计数。为避免重复,我们不会在此处包含实现,但它可以在Advanced-Deep-Learning-with-Python/lstm_gru_count_1s.py at master · PacktPublishing/Advanced-Deep-Learning-with-Python · GitHub获得。
我们对各种类型的 RNN 的讨论到此结束。接下来,我们将通过实施文本情感分析示例来引导这些知识。
实现文本分类
让我们回顾一下到目前为止的这一章。我们首先使用仅实现 RNN numpy。然后,我们继续使用原始 PyTorch 操作实现 LSTM。我们将通过针对文本分类问题训练默认的 PyTorch 1.3.1 LSTM 实现来结束此弧。此示例还需要torchtext0.4.0 包。文本分类(或分类)是指根据其内容分配类别(或标签)的任务。文本分类任务包括垃圾邮件检测、主题标记和情绪分析。这类问题是多对一 关系的一个例子,我们在RNN 简介部分定义了这种关系。
在本节中,我们将在大型电影评论数据集 ( Sentiment Analysis ) 上实现一个情感分析示例,该数据集包含 25,000 条流行电影的训练评论和 25,000 条测试评论. 每条评论都有一个二进制标签,表明它是正面的还是负面的。除了 PyTorch,我们还将使用该torchtext包(torchtext — torchtext 0.4.0 documentation)。它由数据处理实用程序和流行的自然语言数据集组成。您还需要为高级 NLP 安装spacy 开源软件库( https://spacy.io ),我们将使用它来标记数据集。
情感分析算法如下图所示:
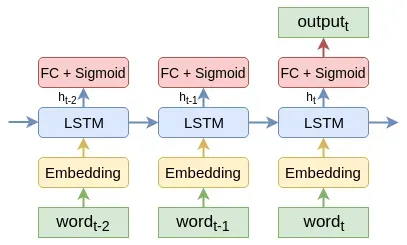
让我们描述一下算法步骤(这些对任何文本分类算法都有效):
- 序列中的每个单词都替换为其嵌入向量(第 6 章,语言建模)。这些嵌入可以使用 word2vec、fastText、GloVe 等生成。
- 词嵌入作为输入提供给 LSTM 单元。
- 单元输出h t用作具有单个输出单元的全连接层的输入。该单元使用 sigmoid 激活,它表示评论为正面 (1) 或负面 (0) 的概率。如果问题是多项式(而不是二进制),我们可以用 softmax 替换 sigmoid。
- 序列最后一个元素的网络输出作为整个序列的结果。
现在我们已经提供了算法的概述,让我们来实现它。我们只会包含代码中有趣的部分,但完整的实现可在https://github.com/PacktPublishing/Advanced-Deep-Learning-with-Python/tree/master/Chapter07/sentiment_analysis.py获得。
让我们开始吧:
1.首先,我们将添加导入:
import torch
import torchtext2.接下来,我们将实例化一个torchtext.data.Field对象:
TEXT = torchtext.data.Field(
tokenize='spacy', # 使用 SpaCy 分词器
lower=True, # 将所有字母转换为小写
include_lengths=True, # 包括电影评论的长度
)该对象声明了一个文本处理管道,它从原始文本开始并输出文本的张量表示。更具体地说,它使用分spacy词器,将所有字母转换为小写,并包括每个电影评论的长度(以单词为单位)。
3.然后,我们将对标签(正面或负面)做同样的事情:
LABEL = torchtext.data.LabelField(dtype =torch.float)4.接下来,我们将实例化训练和测试数据集拆分:
train, test = torchtext.datasets.IMDB.splits(TEXT, LABEL)电影评论数据集包含在其中torchtext,我们不需要做任何额外的工作。该splits方法将TEXT和LABEL字段作为参数。通过这样做,指定的管道将应用于选定的数据集。
5.然后,我们将实例化词汇表:
TEXT.build_vocab(train, vectors=torchtext.vocab.GloVe(name='6B', dim=100))
LABEL.build_vocab(train)词汇表为单词的数字表示提供了一种机制。在这种情况下,该TEXT字段的数值表示是一个预训练的 100d GloVe 向量。另一方面,数据集中的标签的字符串值为pos或neg。这里词汇表的作用是为这两个标签分配数字(0 和 1)。
6.接下来,我们将为训练和测试数据集定义迭代器,其中device代表 GPU 或 CPU。迭代器将在每次调用时返回一个小批量:
train_iter, test_iter = torchtext.data.BucketIterator.splits(
(train, test), sort_within_batch=True, batch_size=64, device=device)7.我们将继续实现和实例化LSTMModel该类。这是程序的核心,它实现了我们在本节开头的图中定义的算法步骤:
class LSTMModel(torch.nn.Module):
def __init__(self, vocab_size, embedding_size, hidden_size, output_size, pad_idx):
super().__init__()
# 嵌入字段
self.embedding=torch.nn.Embedding(num_embeddings=vocab_size,
embedding_dim=embedding_size,padding_idx=pad_idx)
# LSTM cell
self.rnn = torch.nn.LSTM(input_size=embedding_size,
hidden_size=hidden_size)
# 全连接输出
self.fc = torch.nn.Linear(hidden_size, output_size)
def forward(self, text_sequence, text_lengths):
# 提取嵌入向量
embeddings = self.embedding(text_sequence)
# 将序列填充为相等长度
packed_sequence =torch.nn.utils.rnn.pack_padded_sequence
(embeddings, text_lengths)
packed_output, (hidden, cell) = self.rnn(packed_sequence)
return self.fc(hidden)
model = LSTMModel(vocab_size=len(TEXT.vocab),
embedding_size=EMBEDDING_SIZE,
hidden_size=HIDDEN_SIZE,
output_size=1,
pad_idx=TEXT.vocab.stoi[TEXT.pad_token])LSTMModel处理具有不同长度的小批量序列(在本例中为电影评论)。然而,小批量是一个张量,它为每个序列分配相同长度的切片。正因为如此,所有的序列都预先用特殊符号填充,以达到批次中最长序列的长度。构造函数中的参数表示填充符号在词汇表中的padding_idx索引。torch.nn.Embedding但是使用带填充的序列会导致对填充部分进行不必要的计算。正因为如此,模型的前向传播将text小批量和text_lengths每个序列都作为参数。它们被输入到pack_padded_sequence函数中,函数将它们转换为packed_sequence目的。我们这样做是因为self.rnn对象( 的实例torch.nn.LSTM)有一个特殊的例程来处理打包序列,它优化了关于填充的计算。
8.接下来,我们将 GloVe 词嵌入向量复制到模型的嵌入层:
model.embedding.weight.data.copy_(TEXT.vocab.vectors)9.然后,我们将填充和未知标记的嵌入条目设置为零,这样它们就不会影响传播:
model.embedding.weight.data[TEXT.vocab.stoi[TEXT.unk_token]] = torch.zeros(EMBEDDING_SIZE)
model.embedding.weight.data[TEXT.vocab.stoi[TEXT.pad_token]] = torch.zeros( EMBEDDING_SIZE)10.最后,我们可以使用以下代码运行整个程序(train_model和test_model函数与之前相同):
optimizer = torch.optim.Adam(model.parameters())
loss_function = torch.nn.BCEWithLogitsLoss().to(device)
model = model.to(device)
for epoch in range(5):
print(f"Epoch {epoch + 1}/5")
train_model(model, loss_function, optimizer, train_iter)
test_model(model, loss_function, test_iter)如果一切按预期工作,该模型将达到 88% 左右的测试准确率。
概括
在本章中,我们讨论了 RNN。首先,我们从 RNN 和通过时间理论的反向传播开始。然后,我们从头开始实施 RNN 以巩固我们对该主题的知识。接下来,我们使用相同的模式转向更复杂的 LSTM 和 GRU 单元:理论解释,然后是实际的 PyTorch 实现。最后,我们将第 6 章语言建模的知识与本章的新材料结合起来,实现了一个全功能的情感分析任务实现。
文章出处登录后可见!